0.この記事でわかること
・スクレイピング
・目的のデータをデータフレームに格納し、後で集計や加工しやすくする
・クローリング(おまけとして、簡素な)
目次
1.はじめに
2.使用環境(2019/06/24:現在)
3.弊社の会社概要
4.必要な外部モジュール
5.スクレイピングで会社概要を取得
6.クローリングの場合
7.まとめ
8.参考・引用URL
1.はじめに
今記事は、スクレイピング・クローリングを扱ったことない人や、これから扱うぞという人に少しでも、手助けとなればと思います。
私は、Pythonを業務で扱ったことはないですが、スクレイピングでデータを取得できるかつPythonの基礎的な動作を覚えるということで、今は、色々と勉強中な状態です。なので、無駄な動作もあると思いますが、その辺は指摘などしてくだされば、幸いです。
それでは、スクレイピング・クローリングの例として、勉強として、弊社の会社情報(コグラフ株式会社)を取得してみましょうー
2.使用環境(2019/06/24:現在)
python3 3.6.3
jupyterlab 0.27.0
beautifulsoup4 4.6.0
requests 2.21.0
pandas 0.20.3
XlsxWriter 1.0.2
3.弊社の会社概要
弊社コグラフ株式会社の概要ページから、必要項目を取得していきます。
URL http://co-graph.com/about からスクレイピングしていきます。
そもそもスクレイピング とは、
ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
※[ウェブスクレイピング:Wikipediaから引用]
(https://ja.wikipedia.org/wiki/%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0)
スクレイピング、クローリング(後に行います)の注意点は以下のサイトを参照です。
https://docs.pyq.jp/column/crawler.html
今回は、そのスクレイピングで、下記キャプチャの赤枠で囲んだ情報をデータとして取得していきたいと思います。
項目として、『社名』、『本社所在地』、『電話番号』、『代表者』、『設立』、『資本金』、『従業員』、『加入団体』、『パートナー』、『顧問』、『資格等』、『許認可』の12項目です。
※キャプチャは、2019/06/24(現在)

4.必要な外部モジュール
まず、準備として、外部モジュールをインストールしておきます。
ある場合は、無視してください。
$ pip install requests
$ pip install beautifulsoup4
$ pip install xlsxwriter
5.スクレイピングで会社概要を取得
5-1.本番
とりあえず、スクレイピングを経験してみたい方は下記のコードを実行してみてください。
スクレイピング後、Excelファイルに出力されていると思います。
以降の#5-2.で、流れを説明していきたいと思います。
# スクレイピング用
import requests #HTTPライブラリ
from bs4 import BeautifulSoup #HTMLやXMLを解析するライブラリ
import pandas as pd #データフレーム化用
import xlsxwriter #Excelに出力用
# 弊社の会社概要
url = "http://co-graph.com/about"
# HTML解析用
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 会社情報がある箇所を検索
kaishya_info = soup.find_all('dl', class_ = "dl-horizontal style-2")
# 文字列にして、必要な情報を取得する準備
list_hp= []
for i in kaishya_info:
info_txt = i.text.replace('\u3000','') \
.replace(' 社名','社名:').replace('本社所在地','■本社所在地:') \
.replace('代表者','■代表者:').replace('設立','■設立:').replace('資本金','■資本金:') \
.replace('従業員','■従業員:').replace('電話番号','■電話番号:') \
.replace('加入団体','■加入団体:').replace('パートナーI','■パートナー:I') \
.replace('顧問','■顧問:').replace('資格等','■資格等:').replace('許認可','■許認可:')
list_hp.append(info_txt.split('■'))
# 不要な文字の除外
list_hp2 = []
for j in list_hp:
for j2 in j:
if j2 == ' ':
pass
else:
list_hp2.append(j2)
# split()で列名にするものとデータを区切る
list_hp3 = []
for i3 in list_hp2:
list_hp3.append(i3.split(':'))
# データフレーム化に、列名の指定も
HP = pd.DataFrame(data = list_hp3).T
HP.columns = HP.iloc[0]
# 列名の指定後に、不要な行を削除
HP_main = HP.drop(0)
# Excelに出力
HP_main.to_excel('cograph.xlsx', sheet_name='cograph')
セルごとに区切られて、大変見やすくなっております。

5-2.補足:流れについて
# スクレイピング用
import requests #HTTPライブラリ
from bs4 import BeautifulSoup #HTMLやXMLを解析するライブラリ
import pandas as pd #データフレーム化用
import xlsxwriter #Excelに出力用
# 弊社の会社概要ページ
url = "http://co-graph.com/about"
# こちらは、まだ準備段階なので、responseをprint()で出力しても、[<response[200]>]としか表示されない
response = requests.get(url)
# HTML出力
html = response.text
print(html)
HTMLとして取得します。

soup = BeautifulSoup(html, "html.parser")
print(soup)
HTMLとして解析していきます。これで、必要な情報を取得する準備が出来ました。

ここは、蛇足なのですが、より見やすい方法で、prettify()関数があります。HTMLが、ツリー上に表示されるので、次に使う必要な情報のタグやクラスの位置の参考になると思います。
soup = BeautifulSoup(html, "html.parser")
# prettify()関数でHTMLをみやすく
print(soup.prettify())

kaishya_info = soup.find_all('dl', class_ = "dl-horizontal style-2")
print(kaishya_info)
find_all()関数で、検索したいタグとクラスに一致するものを全て検索します。
また検索後、勝手にリスト化されますので注意です。
この時、なるべく、必要な情報以外の余計な情報を入れたくないので、適当な検索するタグやクラスを見つけるのが、ポイントです。今回は、タグ:dlで、クラス:dl-horizontal style-2にしました。
赤枠が今回の必要な項目の列名として使用するのですが、12項目すべてありそうですね。
それ以外の、『コグラフ株式会社(Co-graph Inc.)』や『〒141-0031』などは、別途データとして取得していきます。

※タグやクラスについて詳しく知りたい場合は、下記サイトが参考になりました。
タグ: https://www.tagindex.com/html_tag/basic/basic.html
クラス: https://www.tagindex.com/html_tag/attribute/class.html
タグや検索の方法は色々あると思いますが、私は、2パターンで行いました。
①先ほどのprettify()で行うのと、②ブラウザ上で、デベロッパーツールを表示させること(Google Chromeでは、WindowsでF12キー,Macの場合はCommand+Option+Iキー)です。
①prettify()で表示させて、スクロールしていき、適当な箇所を探す。赤枠でタグやクラスを自分で見つける。

②ブラウザ上で、デベロッパーツールを表示させて、適当な箇所を探す。むしろこちらがメインで、①で確認するイメージ。必要な箇所が青くハイライトされるので、タグやクラスを見つけやすい。今回は2キャプチャで、タグやクラスを確認しています。
キャプチャ1(上)とキャプチャ2(下)


以降、HTMLを文字列にして、結構無理強いに目的のデータフレーム化にしていきます。
# replace()前
for i in kaishya_info:
info_txt = i.text
print(info_txt)
.textとして、文字列にすることで、タグやクラスが除外されて、必要な文字のみが残ります。

見た目上では、特に問題ないと思いますが、実際は、余計な文字なのも含まれているので、それらを**replace()**で置換したいと思います。他にも、今の状態だと、必要な項目名(例:社名)とデータ(例:コグラフ株式会社)が区切られているわけではないので、それらも区切りたいので、その準備をします。
下記は、紹介用で、split('■')する前の状態です。
# 項目名とデータは':'で区切り、データと項目名は■で区切っています。
for i in kaishya_info:
info_txt = i.text.replace('\u3000','') \
.replace(' 社名','社名:').replace('本社所在地','■本社所在地:') \
.replace('代表者','■代表者:').replace('設立','■設立:').replace('資本金','■資本金:') \
.replace('従業員','■従業員:').replace('電話番号','■電話番号:') \
.replace('加入団体','■加入団体:').replace('パートナーI','■パートナー:I') \
.replace('顧問','■顧問:').replace('資格等','■資格等:').replace('許認可','■許認可:')
list_hp.append(info_txt)
list_hp #見やすくするためにprint()は省力

実際はこちらで実行しています。
list_hp = []
# データと項目名は■で区切っています。
for i in kaishya_info:
info_txt = i.text.replace('\u3000','') \
.replace(' 社名','社名:').replace('本社所在地','■本社所在地:') \
.replace('代表者','■代表者:').replace('設立','■設立:').replace('資本金','■資本金:') \
.replace('従業員','■従業員:').replace('電話番号','■電話番号:') \
.replace('加入団体','■加入団体:').replace('パートナーI','■パートナー:I') \
.replace('顧問','■顧問:').replace('資格等','■資格等:').replace('許認可','■許認可:')
list_hp.append(info_txt.split('■'))
list_hp #見やすくするためにprint()は省力

少し、**' 'などがありますが、それぞれの項目名とデータが良い感じに分かれています。この時、replace()で'パートナー'は、データに、複数存在しているので、必ず一つしかないもの'パートナーI'**を見つけ、無理やり感があります。
以降は、文字列の処理と、列名とデータを区切っています。
# 不要な文字の除外
list_hp2 = []
for j in list_hp:
for j2 in j:
if j2 == ' ':
pass
else:
list_hp2.append(j2)
# split()で列名にするものとデータを区切る
list_hp3 = []
for i3 in list_hp2:
list_hp3.append(i3.split(':'))
list_hp3 #見やすくするためにprint()は省力

より、データが整形されました。最後に、これらをデータフレーム化して、Excelに出力しています。
# データフレーム化に、列名の指定も
HP = pd.DataFrame(data = list_hp3).T
HP.columns = HP.iloc[0]
# 列名の指定後に、不要な行を削除
HP_main = HP.drop(0)
# Excelに出力
HP_main.to_excel('cograph.xlsx', sheet_name='cograph')
HP_main #見やすくするためにprint()は省力
紹介用に、データフレームを出力しています。

上記の状態で、Excelで出力されてものは、セルごとに項目名が分かれて格納されます。
6.クローリングの場合
クローリングとは
ロボット型検索エンジンにおいて、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存することである。 クローリングを行うためのプログラムは特に「クローラ」あるいは>「スパイダー」と呼ばれている。
※[クローリング:weblioから引用]
(https://www.weblio.jp/content/%E3%82%AF%E3%83%AD%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0)
外部モジュールSpyderが有名ですが、今回はそれを使わずにクローリングをしたいと思います。
会社のHOME画面**"http://co-graph.com/"**から、会社概要ページ**"http://co-graph.com/about"**にアクセスして、そこから、会社概要の情報を取得するという流れです。
先に、クローリングしたい場合の人は、下記コードを実行してみて下さい。結果は、#5-1.と変わりません。
#6-2.で、流れを説明いたします。
6-1.本番
# スクレイピング用
import requests #HTTPライブラリ
from bs4 import BeautifulSoup #HTMLやXMLを解析するライブラリ
import time #DoS攻撃防止用
import pandas as pd #データフレーム化用
import xlsxwriter #Excelに出力用
# 公式homeより
main_hp = "http://co-graph.com/"
response = requests.get(main_hp)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
soup_f = soup.find_all('ul','li',class_='dropdown-menu')
listurl = []
for url in soup_f:
try:
menu = url.a.get('href')
if menu == '#':
pass
else:
listurl.append(main_hp+menu)
except TypeError:
pass
except AttributeError:
pass
# 今回は1個目のURLを取得する
url = listurl[0]
# timeで、アクセス間隔を2秒あける
time.sleep(2)
# 以降、同様なので、見づらくなっていますm(_ _ )m
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
kaishya_info = soup.find_all('dl', class_ = "dl-horizontal style-2")
list_hp= []
for i in kaishya_info:
info_txt = i.text.replace('\u3000','') \
.replace(' 社名','社名:').replace('本社所在地','■本社所在地:') \
.replace('代表者','■代表者:').replace('設立','■設立:').replace('資本金','■資本金:') \
.replace('従業員','■従業員:').replace('電話番号','■電話番号:') \
.replace('加入団体','■加入団体:').replace('パートナーI','■パートナー:I') \
.replace('顧問','■顧問:').replace('資格等','■資格等:').replace('許認可','■許認可:')
list_hp.append(info_txt.split('■'))
list_hp2 = []
for j in list_hp:
for j2 in j:
if j2 == ' ':
pass
else:
list_hp2.append(j2)
list_hp3 = []
for i3 in list_hp2:
list_hp3.append(i3.split(':'))
HP = pd.DataFrame(data = list_hp3).T
HP.columns = HP.iloc[0]
HP_main = HP.drop(0)
HP_main.to_excel('cograph.xlsx', sheet_name='cograph')
6-2.補足:流れについて
弊社のHOME画面http://co-graph.com**では、下記のようになっています。

赤枠で囲んだ箇所が、遷移したい会社概要ページのURL**です。
それと、そのURLを取得するために、デベロッパーツールで調べています。

赤枠より、今回は、find_all('ul','li',class_='dropdown-menu')で取得しています。※find()でもいけましたが、今回は、引き続きfind_all()で実行しています。
# スクレイピング用
import requests #HTTPライブラリ
from bs4 import BeautifulSoup #HTMLやXMLを解析するライブラリ
import time #DoS攻撃防止用
import pandas as pd #データフレーム化用
import xlsxwriter #Excelに出力用
# 公式HOMEより
main_hp = "http://co-graph.com"
response = requests.get(main_hp)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
soup_f = soup.find_all('ul','li',class_='dropdown-menu')
print(soup_f)
以下のように出力されます。

この、赤枠で囲んだ会社概要ページに必要な**"/about"を取得します。
※サイトの性質上、"http://co-graph.com"**は、省力されていますので、後で、自分で付与しないといけません。
for url in soup_f:
menu = url.a.get('href')
print(menu)

**a.get('href')**を行うことで、URLを取得することができ、'/about'や'/service'などが取得されます。また、エラー(AttributeError)も出ています。
ポイントは、**get('href')**ではなく、**a.get('href')**とすることで取得できます。
aタグオブジェクト.get(href属性)を取得するというメソッドがあります。
詳しくはこちらを参照してください。
getメソッドでTagオブジェクトから属性値を取り出す
Beautiful Soupモジュールには、Tagオブジェクトからその要素の指定の属性値を取得するgetメソッドがあります。
Tagオブジェクト.get(属性)
https://tonari-it.com/python-html-get-text-attr/
もちろん、textをすることで、文字列(会社概要、事業内容、等)を取得することができますが、今回は必要ないのでしません。
実際は、下記コードを実行して、エラーを無視したり、**"http://co-graph.com"**を付与しました。ここでも、無理強い感がありますが。
listurl = []
# 色々なエラーが出てしまうので、それらを無視する
for url in soup_f:
try:
menu = url.a.get('href')
if menu == '#':
pass
else:
listurl.append(main_hp + menu)
except TypeError:
pass
except AttributeError:
pass
listurl #見やすくするためにprint()は省力

必要としないURLと、目的のURLがそれぞれ取得されました。
# 今回は1個目のURLを取得する
url = listurl[0]
# timeでアクセス間隔を2秒あける
time.sleep(2)
url #見やすくするためにprint()は省力

目的のURLのみを取得したことと、**time.sleep(2)**を入れることで、目的のURLに遷移する時に、間隔をあけることで、DoS攻撃とみなすことを防いでいます。
DoS攻撃は、情報セキュリティにおける可用性を侵害する攻撃手法のひとつ。
※[DoS攻撃:Wikipediaから引用]
(https://ja.wikipedia.org/wiki/DoS%E6%94%BB%E6%92%83)
以降は、先ほどのスクレイピングのコードと同様です。
# 以降、同様なので、見づらくなっていますm(_ _ )m
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
kaishya_info = soup.find_all('dl', class_ = "dl-horizontal style-2")
list_hp= []
for i in kaishya_info:
info_txt = i.text.replace('\u3000','') \
.replace(' 社名','社名:').replace('本社所在地','■本社所在地:') \
.replace('代表者','■代表者:').replace('設立','■設立:').replace('資本金','■資本金:') \
.replace('従業員','■従業員:').replace('電話番号','■電話番号:') \
.replace('加入団体','■加入団体:').replace('パートナーI','■パートナー:I') \
.replace('顧問','■顧問:').replace('資格等','■資格等:').replace('許認可','■許認可:')
list_hp.append(info_txt.split('■'))
list_hp2 = []
for j in list_hp:
for j2 in j:
if j2 == ' ':
pass
else:
list_hp2.append(j2)
list_hp3 = []
for i3 in list_hp2:
list_hp3.append(i3.split(':'))
HP = pd.DataFrame(data = list_hp3).T
HP.columns = HP.iloc[0]
HP_main = HP.drop(0)
HP_main.to_excel('cograph.xlsx', sheet_name='cograph')
HP_main #見やすくするためにprint()は省力
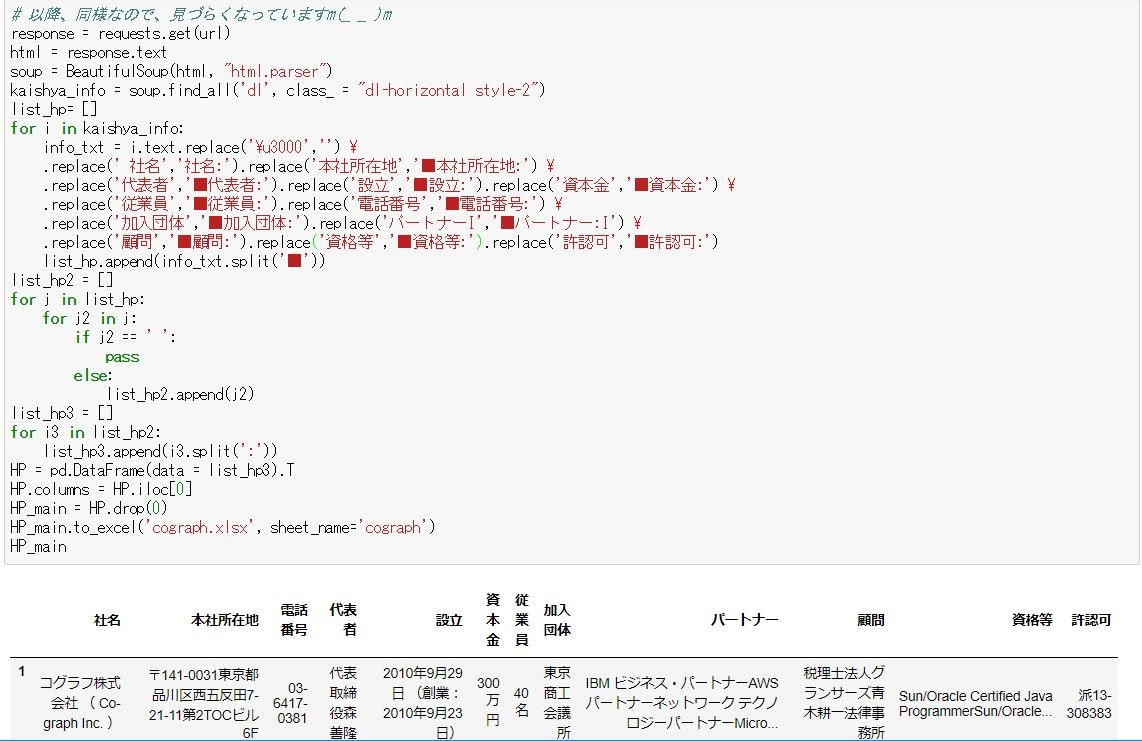 無事にクローリングされ、目的のデータが取得できました。
ほぼ一瞬で(2秒待つ)、取得できるのが便利なのと少し、怖さもあったり。便利だから、引き続き使用していきますが。。
無事にクローリングされ、目的のデータが取得できました。
ほぼ一瞬で(2秒待つ)、取得できるのが便利なのと少し、怖さもあったり。便利だから、引き続き使用していきますが。。
7.まとめ
今回は、弊社の会社情報を、クローリングからスクレイピングして、目的のデータのみを取得して、データフレームに格納して、excelに出力してみました。
実際に、スクレイピングする際の注意点は、簡単にイメージ通りにデータを取れるというわけではないということだと思います。
目的のデータは、サイトによって、HTML構造が異なるので、そこは、あらかじめ調べておかないといけないのが、意外と地味な作業です。
また、time.sleep()を設定しないと、DoS攻撃とみなされる危険性もあるので、そこも注意が必要です。
それでは、その辺りを気を付けて、データを取得していきましょう!
8.参考・引用URL
Requests
・http://jp.python-requests.org/en/latest/ ←日本語のサイト(v1.0.4.で古い:2019/06/24現在)
・https://2.python-requests.org//en/master/ ←公式document
BeautifulSoup
・http://kondou.com/BS4/ ←日本語のサイト(v4.0.2で古い:2019/06/24現在)
・https://www.crummy.com/software/BeautifulSoup/bs4/doc/#a-function ←公式document
・http://python-remrin.hatenadiary.jp/entry/2017/05/01/152455 ←日本語の使い方サイト
タグ/クラス
・https://www.tagindex.com/html_tag/basic/basic.html
・https://www.tagindex.com/html_tag/attribute/class.html
Tagオブジェクト.get(属性)
・https://tonari-it.com/python-html-get-text-attr/
Spyder公式document
・https://www.spyder-ide.org/
・スクレイピング、クローリングする時の注意点
・[ウェブスクレイピング:Wikipediaから引用]
(https://ja.wikipedia.org/wiki/%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0)
・[クローリング:weblioから引用]
(https://www.weblio.jp/content/%E3%82%AF%E3%83%AD%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0)
・[DoS攻撃:Wikipediaから引用]
(https://ja.wikipedia.org/wiki/DoS%E6%94%BB%E6%92%83)