この記事は、JAWS-UG DEIにて2024/5/11に開催した、AWS AppFlow と Amazon Bedrockを使ったオリジナルなAIチャットを作ろう!ワークショップ資料です。
利用するAWSサービスの一部に、課金の発生するものが存在します。ワークショップではAWSクーポンを配布しますが、個人的に挑戦される方は、ご利用予定のAWSアカウントについて、無料枠やトライアルの有無について事前にご確認をお願いします。
また、AWSマネージメントコンソールのスクリーンショットは、2024/05時点で撮影されたものを利用しています。今後のAWSアップデートによって、UIやフローが変更される場合もありますので、ご了承ください。
ワークショップのゴール
Amazon Bedrockを利用して、LLM(大規模言語モデル)ベースのRAG(検索拡張生成)アプリの作り方を学びます。
コードを書かずに独自のデータを利用して回答を生成する仕組みを知ることで、業務で携わるサービスやプロジェクトへの提案やPoC・デモ構築などを迅速に行うことができるようになります。
準備するもの
ワークショップには、AWSアカウントが必要です。
AWSコンソール(https://aws.amazon.com/jp/console/ )にログインし、Amazon Bedrock コンソールにアクセスできることを確認しましょう。
もしAmazon Bedrockコンソールの操作ができない場合、ログイン中のAWSユーザーの権限が不足している可能性があります。IAMコンソールでユーザーのロールやポリシーを確認するか、アカウント管理者にご相談ください。
ワークショップの流れ
イベントでは、2つのRAGを作成します。このワークショップ資料では、Amazon Bedrock ナレッジベースの使い方や機能を体験します。
作業の流れは、おおよそ次のとおりです。
- Step1: Amazon Bedrockで利用するモデルの有効化
- Step2: AIチャットが参照するデータを保存するための、S3バケットの作成
- Step3: PDFファイルなどのデータをS3バケットにアップロード
- Step4: Amazon Bedrock ナレッジベースを作成
- Step5: ナレッジベースへのS3バケットのデータを取り込み
- Step6: ナレッジベース管理画面で、RAG( AI チャット )の動作をテスト
Step1: Amazon Bedrockで利用するモデルの有効化
Amazon Bedrockでは、AmazonやAnthoropicなど、様々な会社が提供するLLMを利用できます。利用できるモデルの一覧は、Bedrock管理画面の [モデルアクセス] から確認できます。
まずは検索フォームに bedrockと入力し、Amazon Bedrock管理画面に移動しましょう。
左側のメニューを下にスクロールすると、 [モデルアクセス] メニューがあります。これをクリックすると、そのAWSアカウントで利用できるモデルと、利用申請が可能なモデルの一覧が表示されます。
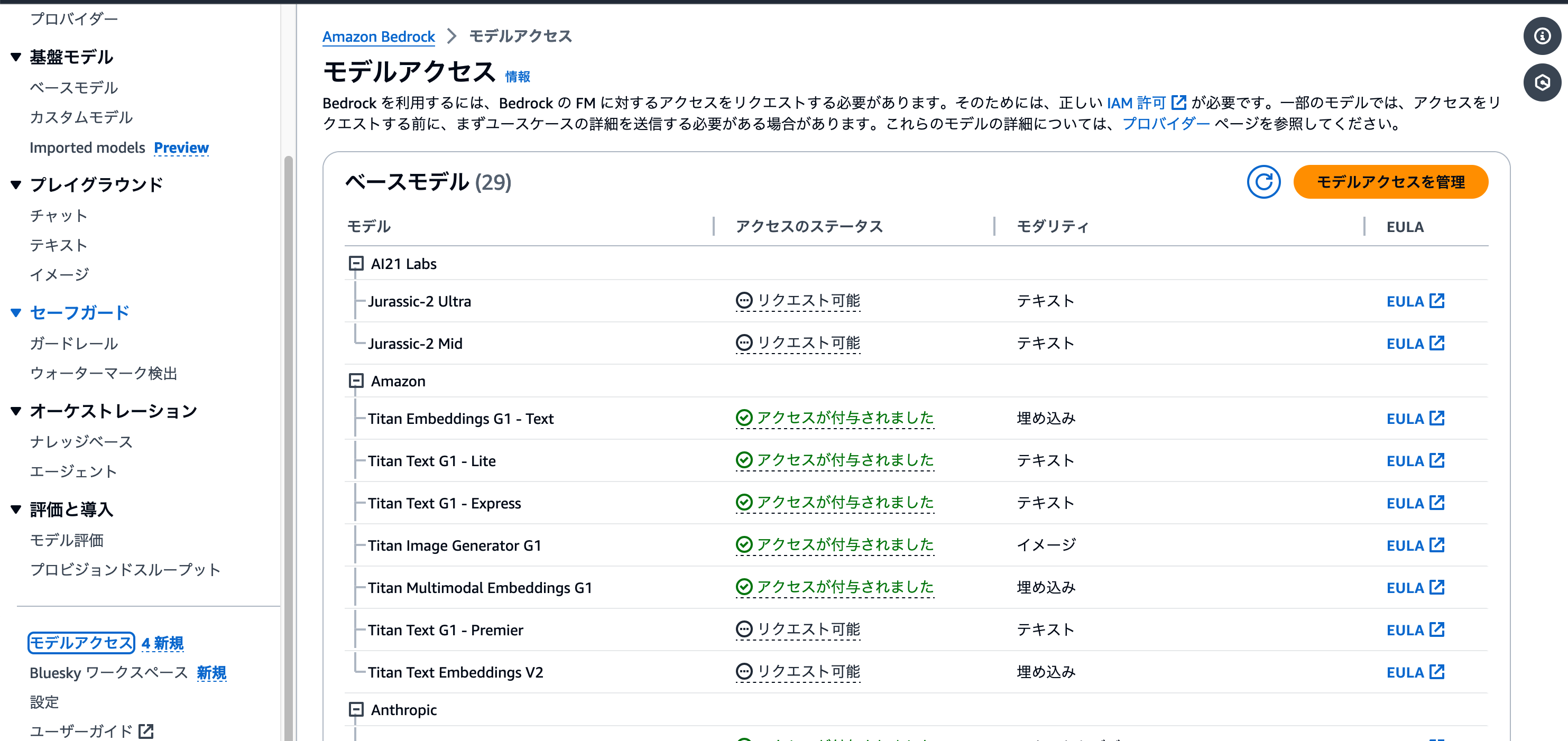
モデルのアクセスステータスが [アクセスが付与されました] になっているモデルが、現在そのAWSアカウントで利用できるモデルです。もし[リクエスト可能]になっている場合は、この後に紹介するモデルアクセスのリクエストを行いましょう。
モデルアクセスを行う方法
利用したいモデルへのリクエストは [モデルアクセス] 画面から操作します。ページ上部に [モデルアクセスを管理] ボタンがありますので、クリックしましょう。
モデル一覧の左側にチェックボックスが表示されます。ここで利用したいモデルにチェックを入れましょう。最後にページ下部にある [変更を保存] ボタンをクリックして、アクセスリクエストを行います。
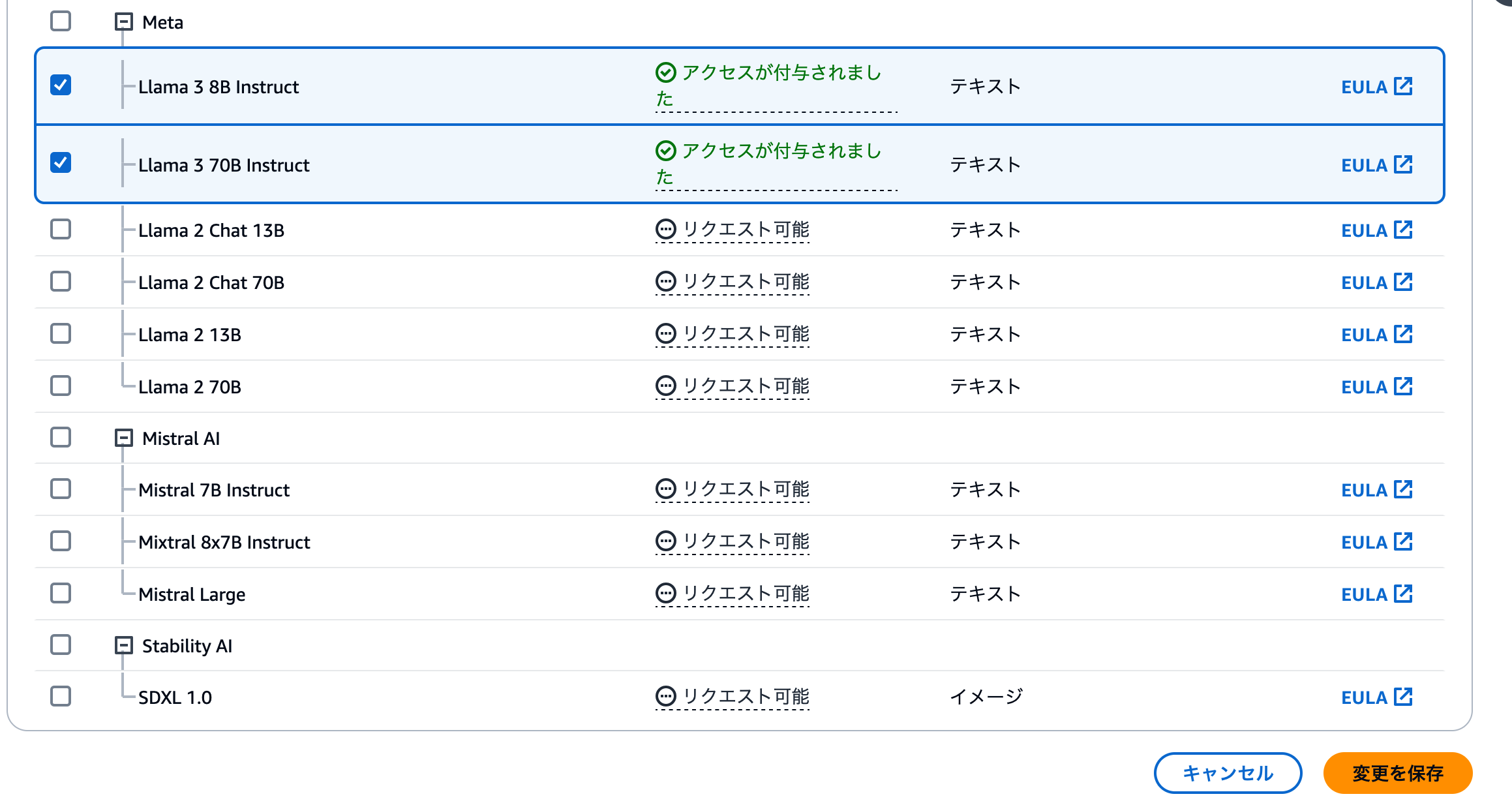
モデルアクセスをリクエストすると、数分の間ステータスが[進行中]に変わります。
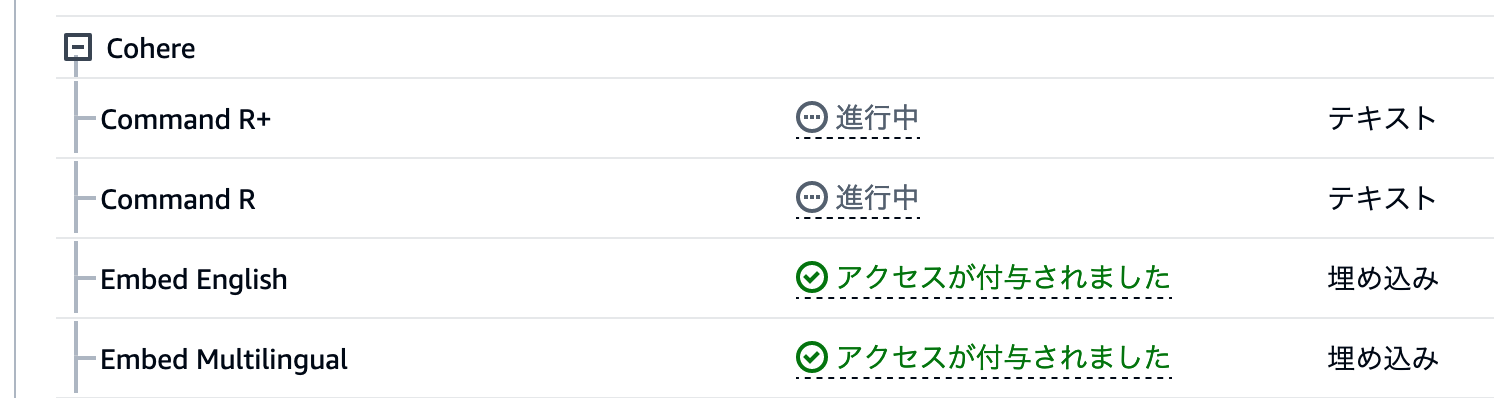
Anthropicなど、一部のモデルでは、「どのようなユースケースでモデルを使うのか」を申請する必要があります。ユースケースを申請するまで、モデルアクセスのリクエストが行えませんので、ご注意ください。
Step2: AIチャットが参照するデータを保存するための、S3バケットの作成
Amazon Bedrockナレッジベースは、Amazon S3に保存されたデータを取り込んで独自のデータソースとします。
Amazon S3とは
Amazon S3はAWSが提供するオブジェクトストレージサービスです。これを利用することで、PDFやテキストファイル、JSON / CSVファイルなどの様々なデータをAWS上に保存し、他のAWSサービスと連携ささせてデータの加工や利活用が可能になります。
Bedrockナレッジベースでは、S3にファイルを保存することで、その内容を参照した回答文をLLMが作成してくれるようになります。
S3バケットの作成方法
早速今回のワークショップで作成するナレッジベースの、データソースに利用するS3バケットを作成しましょう。AWSマネージメントコンソールの検索フォームに [S3] と入力しましょう。[S3]が検索結果に出てきますので、これをクリックします。
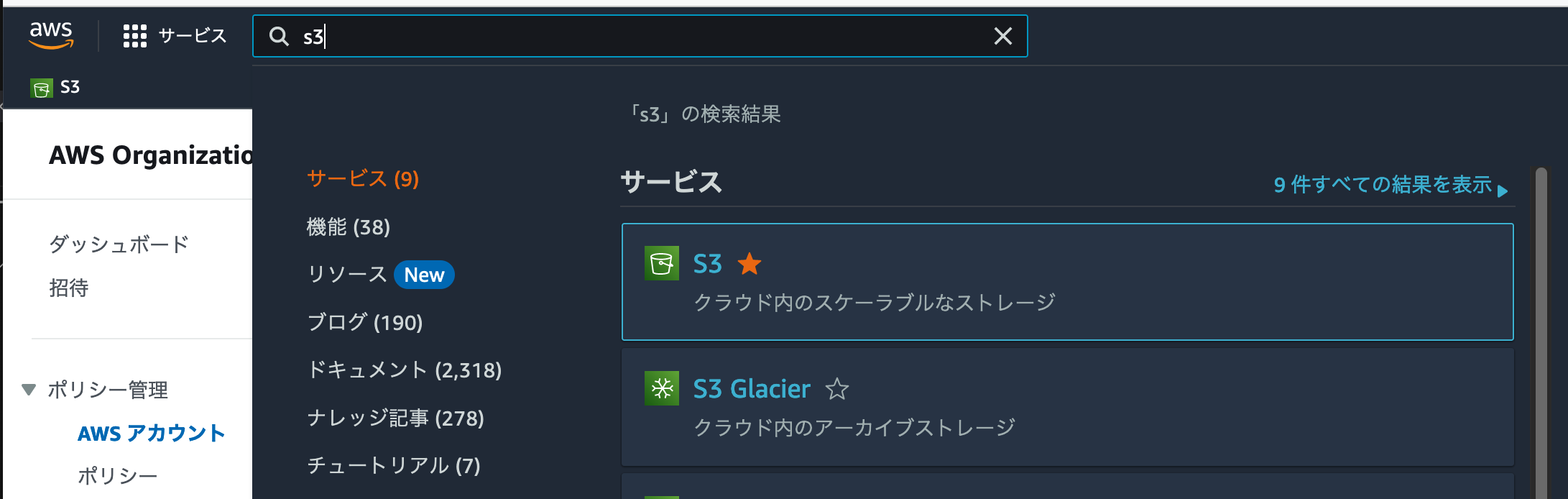
Amazon S3の管理画面に移動しました。[バケットを作成]ボタンを探して、クリックしましょう。
バケット作成画面では、ユースケースに合わせてS3バケットの設定をカスタマイズすることができます。今回は使い方の体験が目的ですので、[バケットタイプ]はデフォルト設定の汎用を選びましょう。バケット名については、今回のワークショップ用であることがわかりやすいように、workshop-bedrock-knowledge-base-あなたの名前を英語で入力のような名前を設定しましょう。
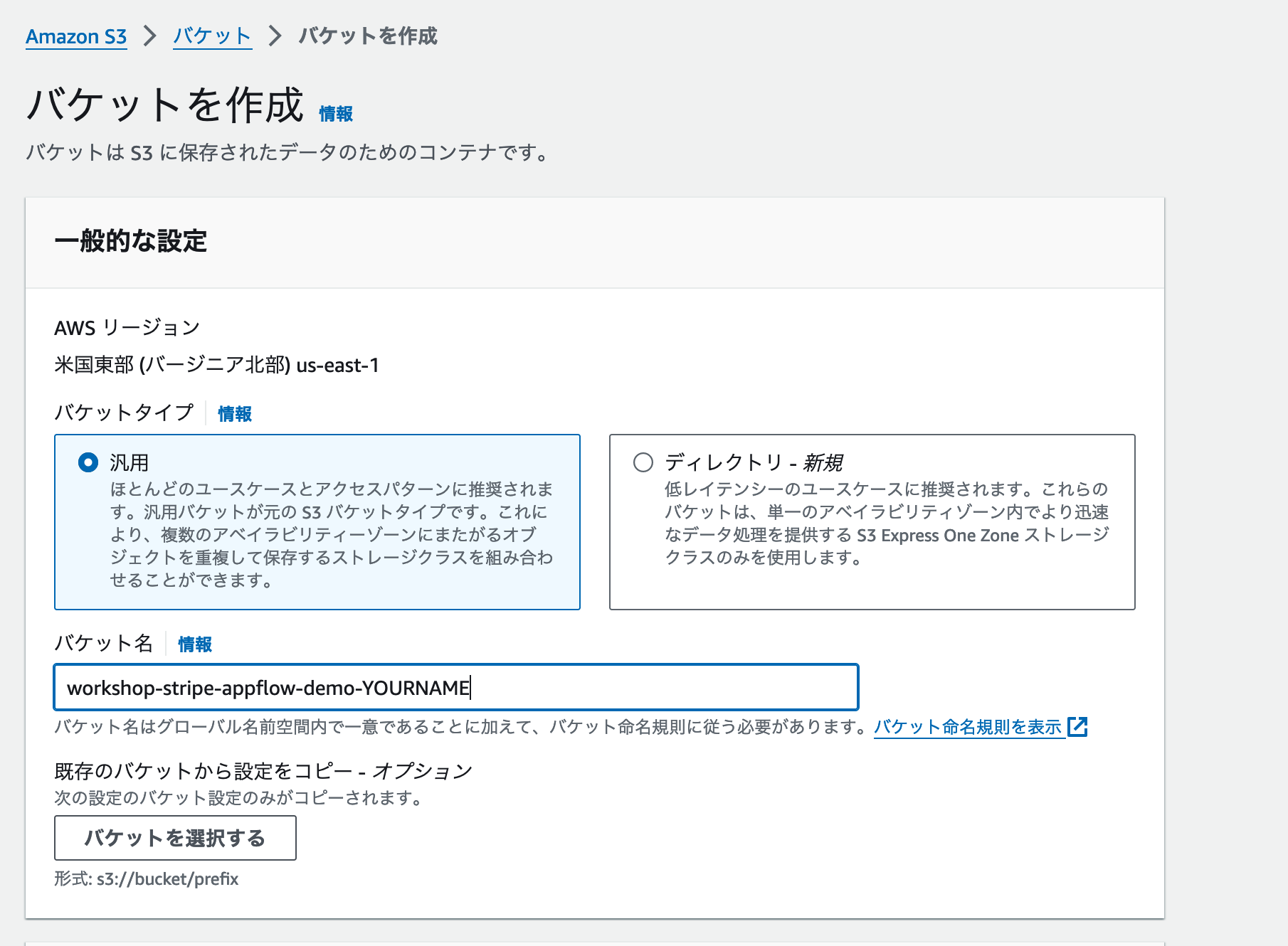
バケット名は全てのAWSアカウントでユニークである必要があります。
もし入力した名前が利用できなかった場合は、末尾に20240511のように日付やランダムな数字を追加してみましょう。
暗号化設定や詳細設定については、デフォルト設定のままで問題ありません。[バケットを作成]ボタンをクリックしましょう。
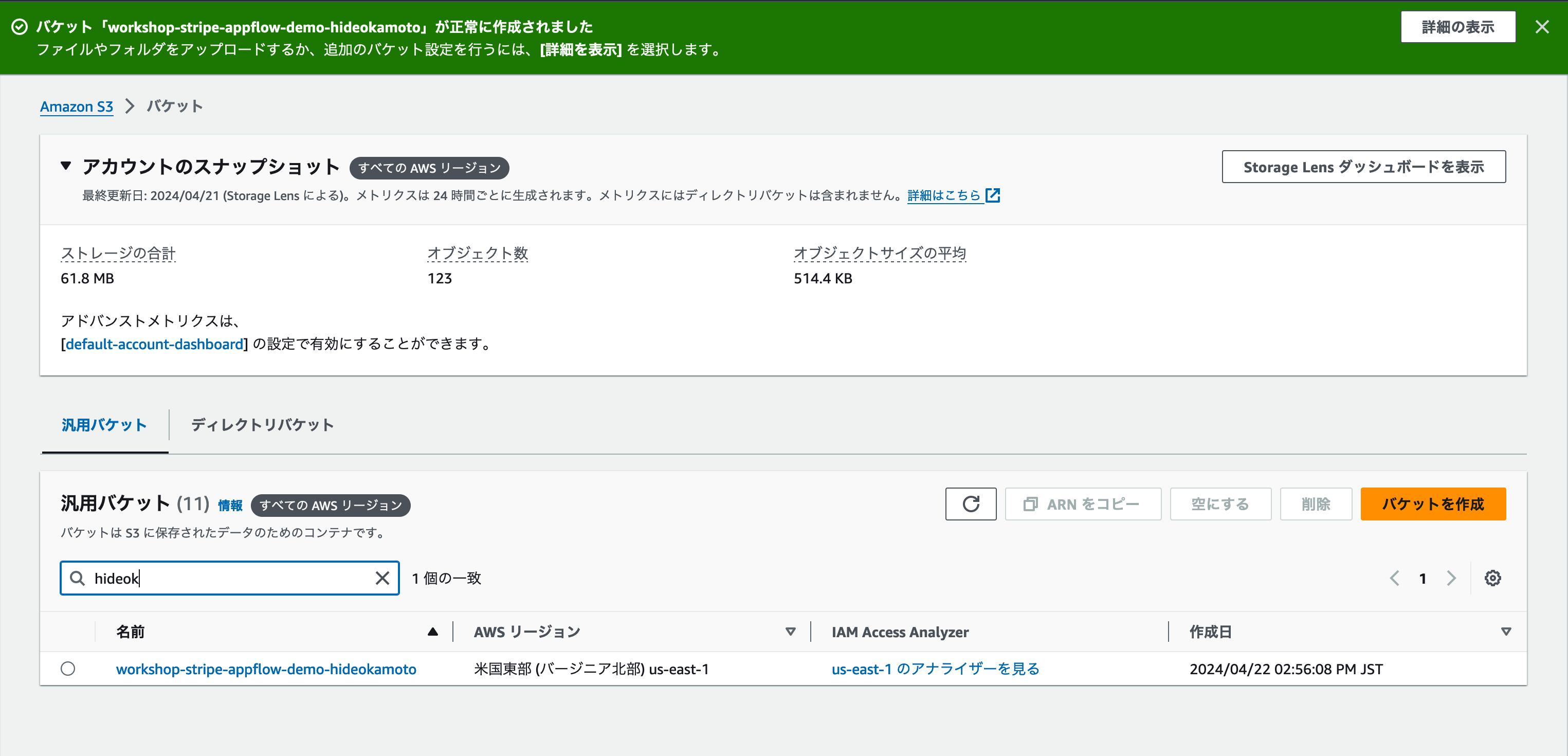
バケットの作成が成功したことを知らせるメッセージが表示されれば、作成成功です。
Step3: PDFファイルなどのデータをS3バケットにアップロード
データを保存するためのS3バケットを作成しましたので、AIチャットが参照するデータをアップロードしましょう。今回はデータの例として、大阪国税局が公開している「酒蔵ガイドマップ」を利用します。以下のリンクをクリックし、 酒蔵ガイドマップ 2府4県版(日本語)」(PDF/9,700KB) をダウンロードしましょう。
ダウンロードしたPDFファイルを利用してアプリケーションなどを開発・公開する場合は、「国税庁ホームページ利用規約
の内容を必ずご確認ください。
https://www.nta.go.jp/chuijiko/riyokiyaku.htm
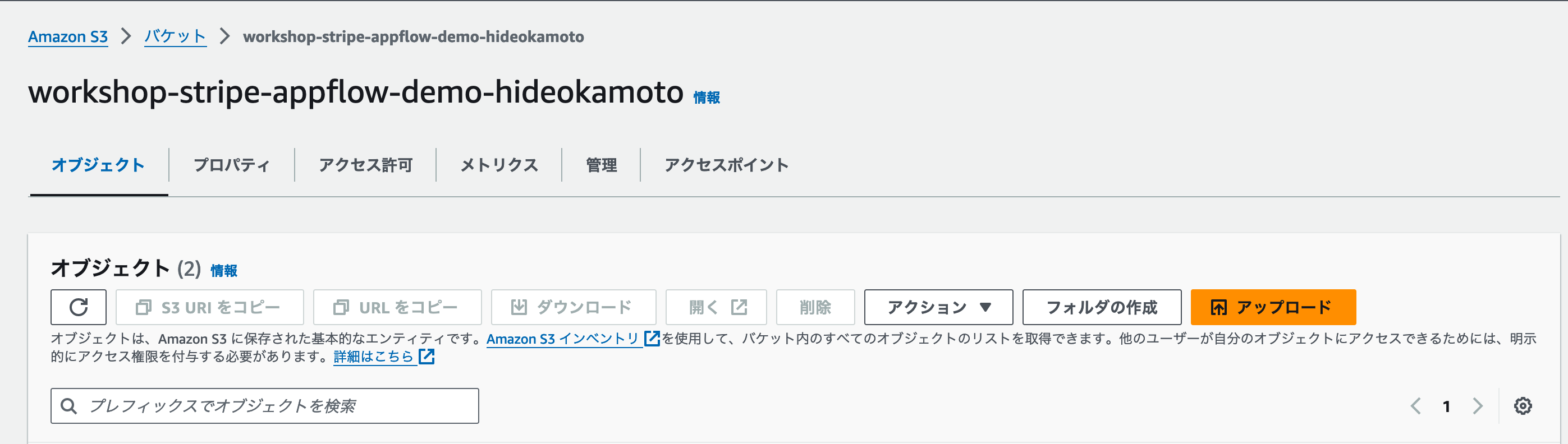
S3のバケット管理画面で、先ほど作成したS3バケットの名前をクリックし、バケットの管理画面に移動しましょう。
バケットの管理画面では、ファイルのアップロードや削除、設定の変更などが行えます。今回は先ほどダウンロードしたPDFファイルのアップロードを行いますので、 [アップロード] ボタンをクリックしましょう。
アップロード画面では、[ここにアップロードするファイル〜] と書かれているエリアに、アップロードしたいファイルをドラッグ&ドロップしましょう。アップデート準備ができたファイルは、 [ファイルとフォルダ] の中に一覧表示されます。アップロードしたいファイルの登録が完了したら、 [アップロード] ボタンをクリックしましょう。
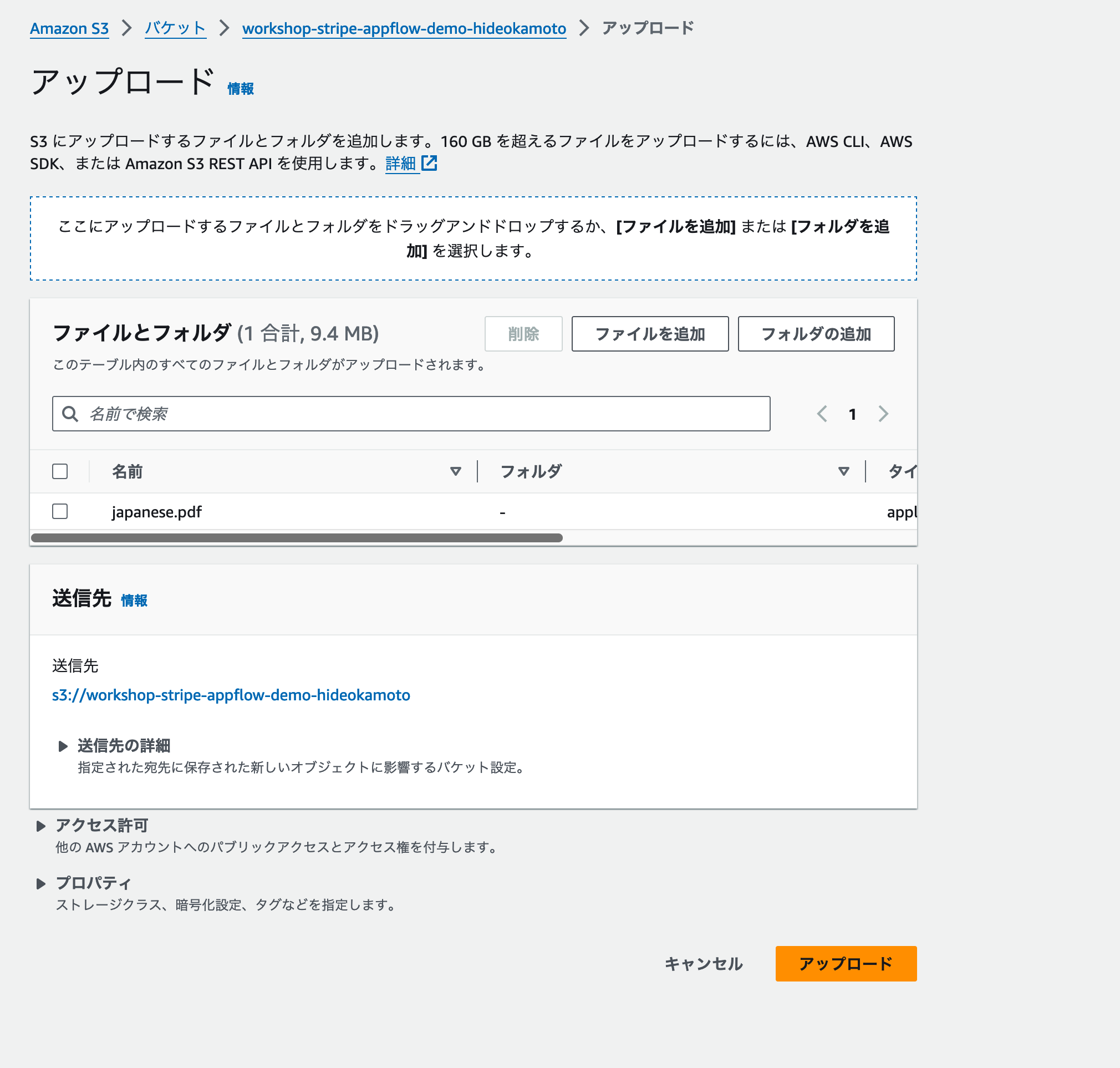
アップロードを開始すると、[アップロード: ステータス]画面に移動します。[アップロードに成功しました] メッセージが表示されれば、アップロード完了です。[閉じる] ボタンをクリックして、S3バケット管理画面に戻りましょう。
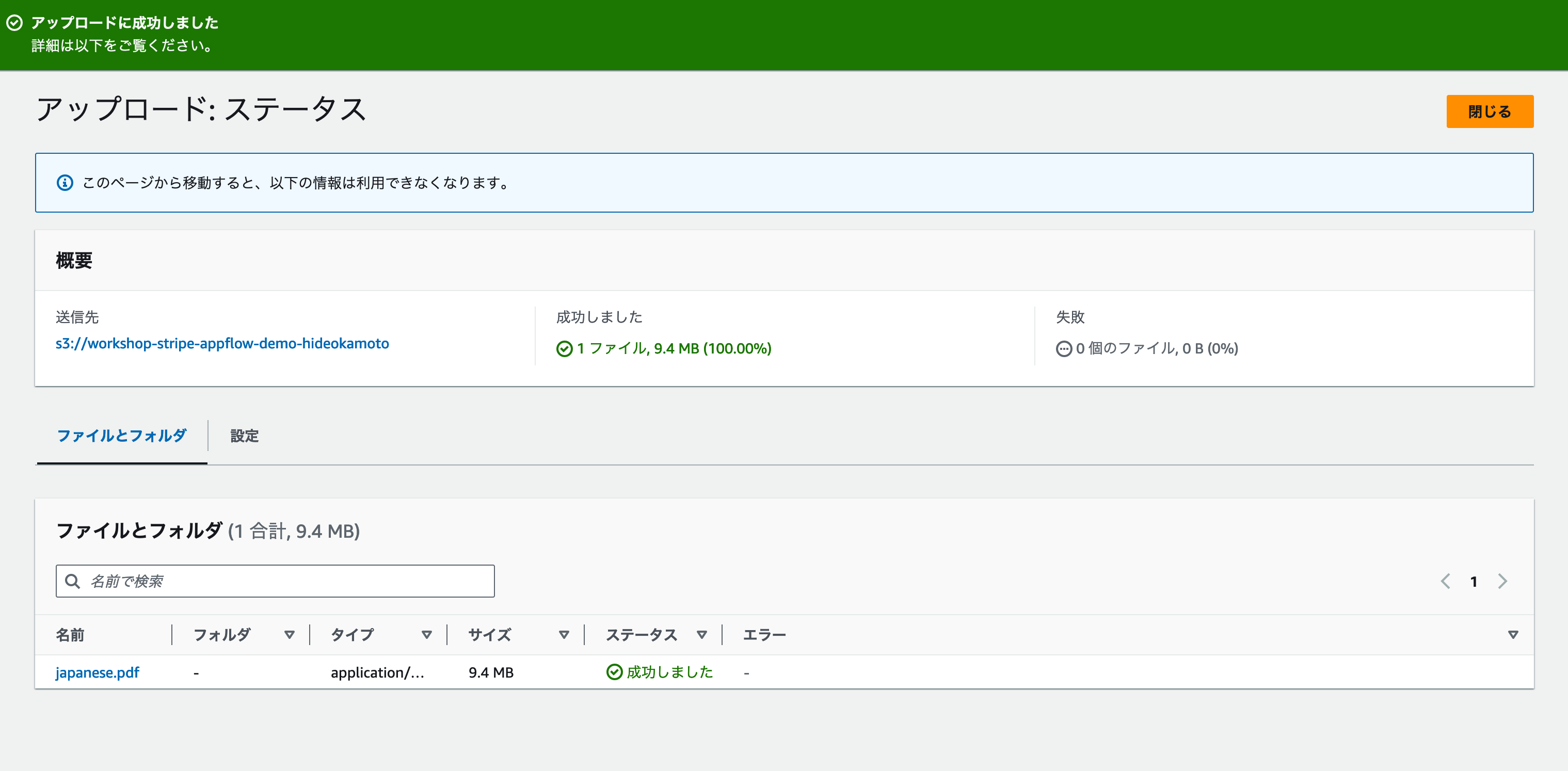
これでAIチャットのデータソースに利用するファイルの準備ができました。次のステップでは、いよいよAmazon Bedrockを使ってナレッジベースを作成します。
Step4: Amazon Bedrock ナレッジベースを作成
いよいよナレッジベースを作成しましょう。検索フォームに bedrockと入力し、Amazon Bedrock管理画面に移動します。
Bedrockのトップページが表示されました。 [使用を開始する] ボタンをクリックして、管理画面に移動しましょう。

管理画面トップページに移動しました。このワークショップでは、Bedrockのナレッジベース機能を利用します。ページ左側にある [ナレッジベース] メニューをクリックしましょう。
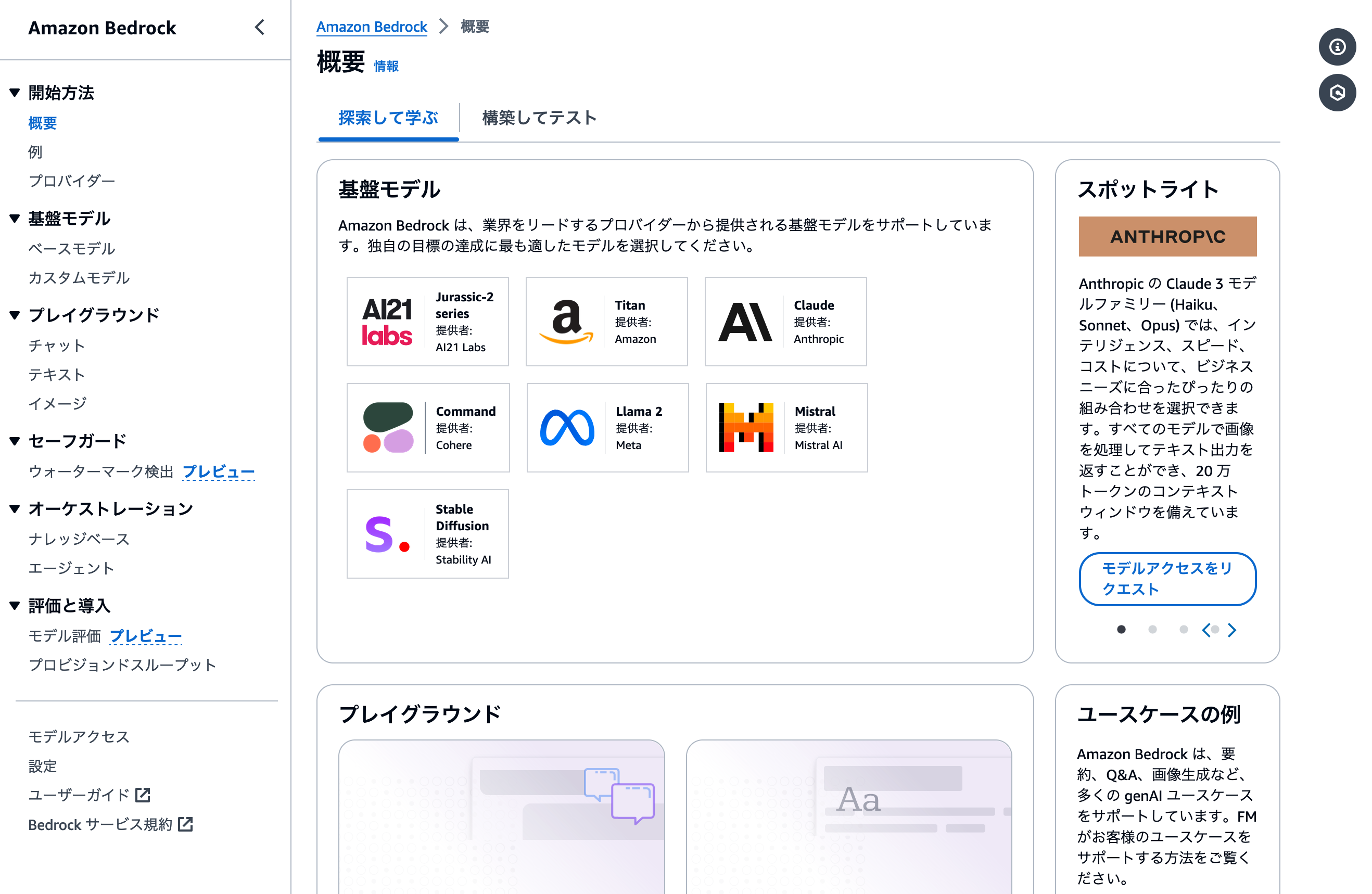
ナレッジベース管理画面がこちらです。作成済みのナレッジベースを編集する場合などにも、この画面を利用します。新しくナレッジベースを作成するには、 [ナレッジベースを作成] ボタンをクリックしましょう。
ナレッジベース作成フォームは4ステップに別れています。これはナレッジベースが参照するデータソースや、検索できるようにするためのDBやモデルの設定などを行う必要があるからです。
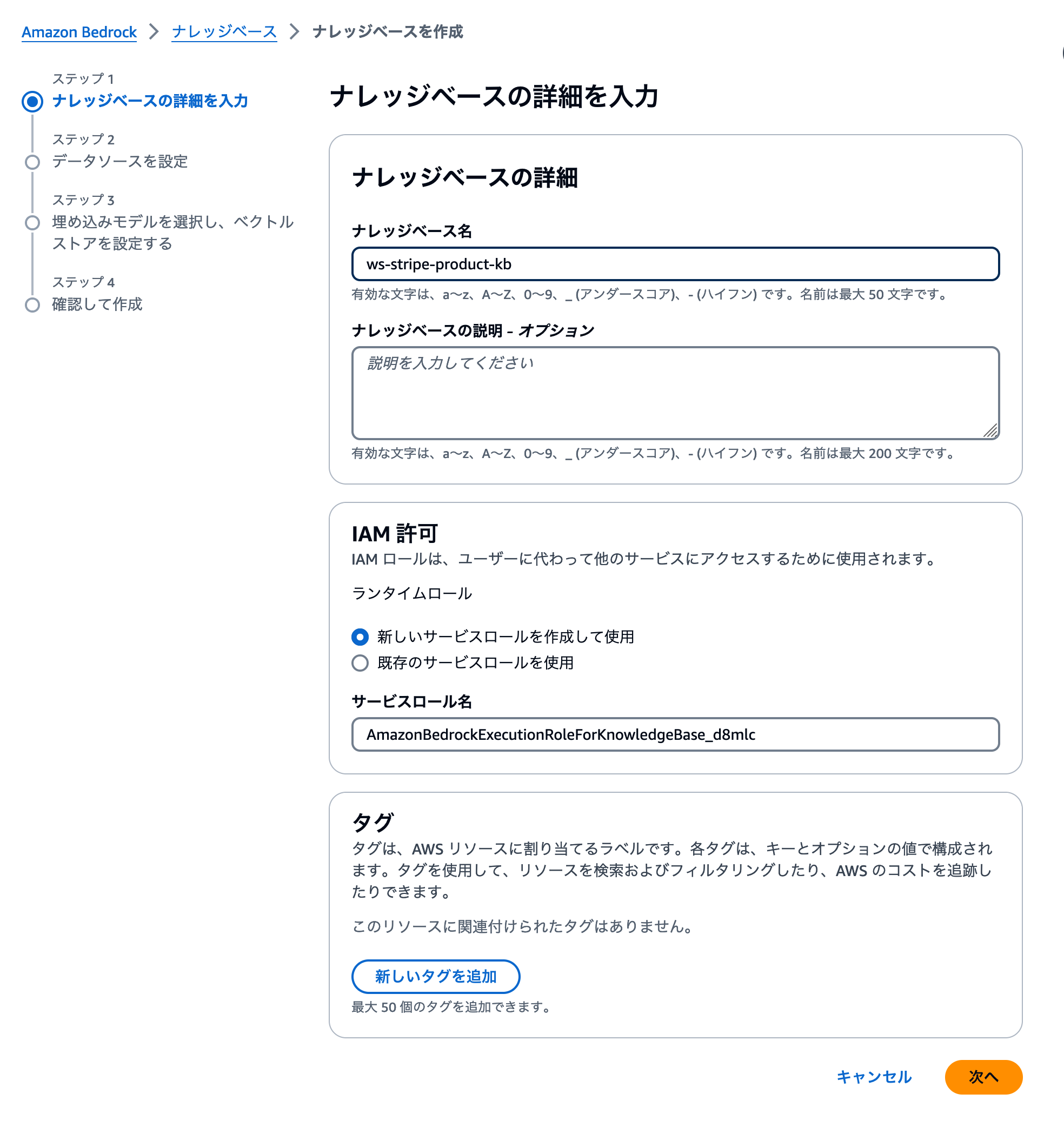
ナレッジベースの名前とIAMロールを設定する
まずナレッジベースの名前とIAMロールを設定しましょう。ここではナレッジベース名をjaws-workshopのようなワークショップ用であることがわかりやすい形にしましょう。IAMロールは最適化された設定でAWSが生成してくれますので、デフォルト設定のまま、次のステップに進みましょう。
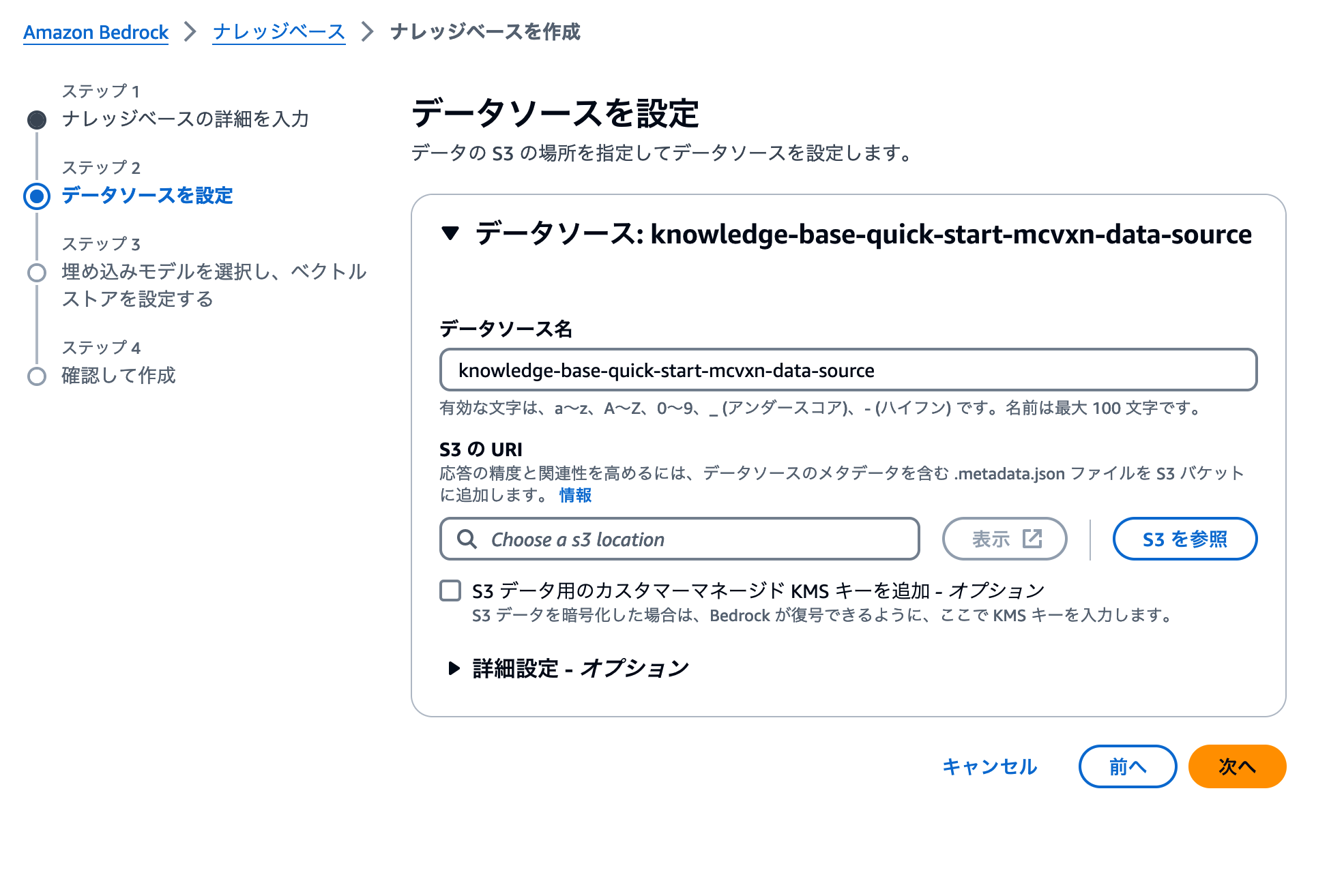
データソースにするS3バケットを指定する
続いてナレッジベースが参照するデータソースを設定します。取り込むデータを保存しているS3バケットを指定する必要がありますので、Step2で作成したS3バケットを指定しましょう。
[S3を参照] ボタンをクリックすると、そのAWSアカウントにあるS3バケットの一覧が表示されます。検索フォームがありますので、ここでバケット名を検索して選択し、[選択] ボタンをクリックしましょう。
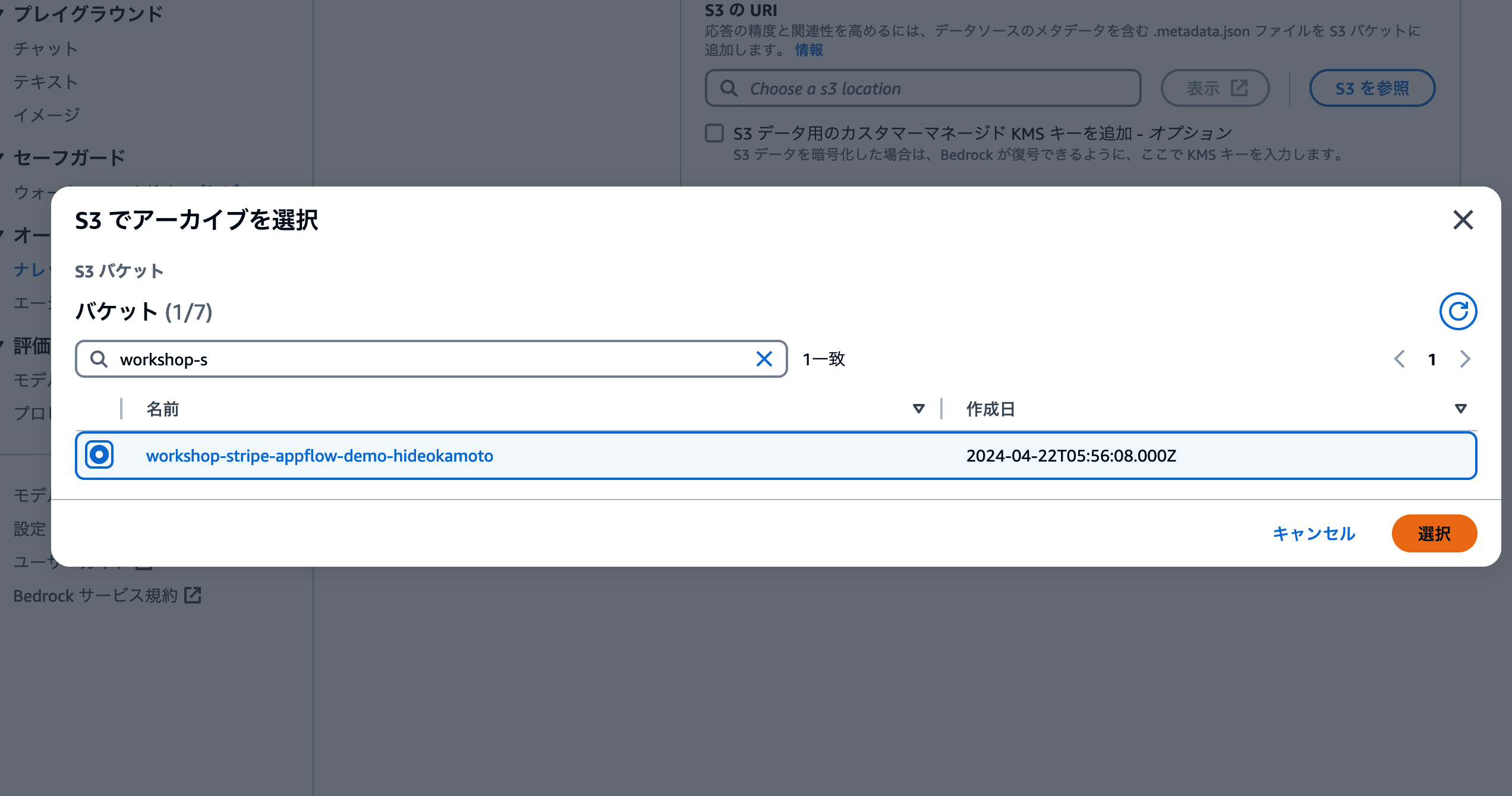
これでデータソースの設定が完了しました。
ベクトルデータへの変換に利用するモデルと、保存するリソースを指定する
S3に保存されたデータは、ナレッジベースがベクトルデータに変換し、Amazon OpenSearch Serverlessなどのベクターデーターベースに保存します。ベクターデーターベースについては、AWSの記事をご覧ください。
このステップでは、「S3にあるデータを、ベクトルデータに変換するモデル」 と 「変換されたベクトルデータを保存するサービス」 の2つを指定します。まずはベクトルデータに変換するモデルを指定しましょう。ここでは事前にモデルアクセスのリクエストが完了している埋め込みモデルが表示されます。 [Titan Embedding] から始まるモデルか、 [Embed Multilingual] を選択しましょう。
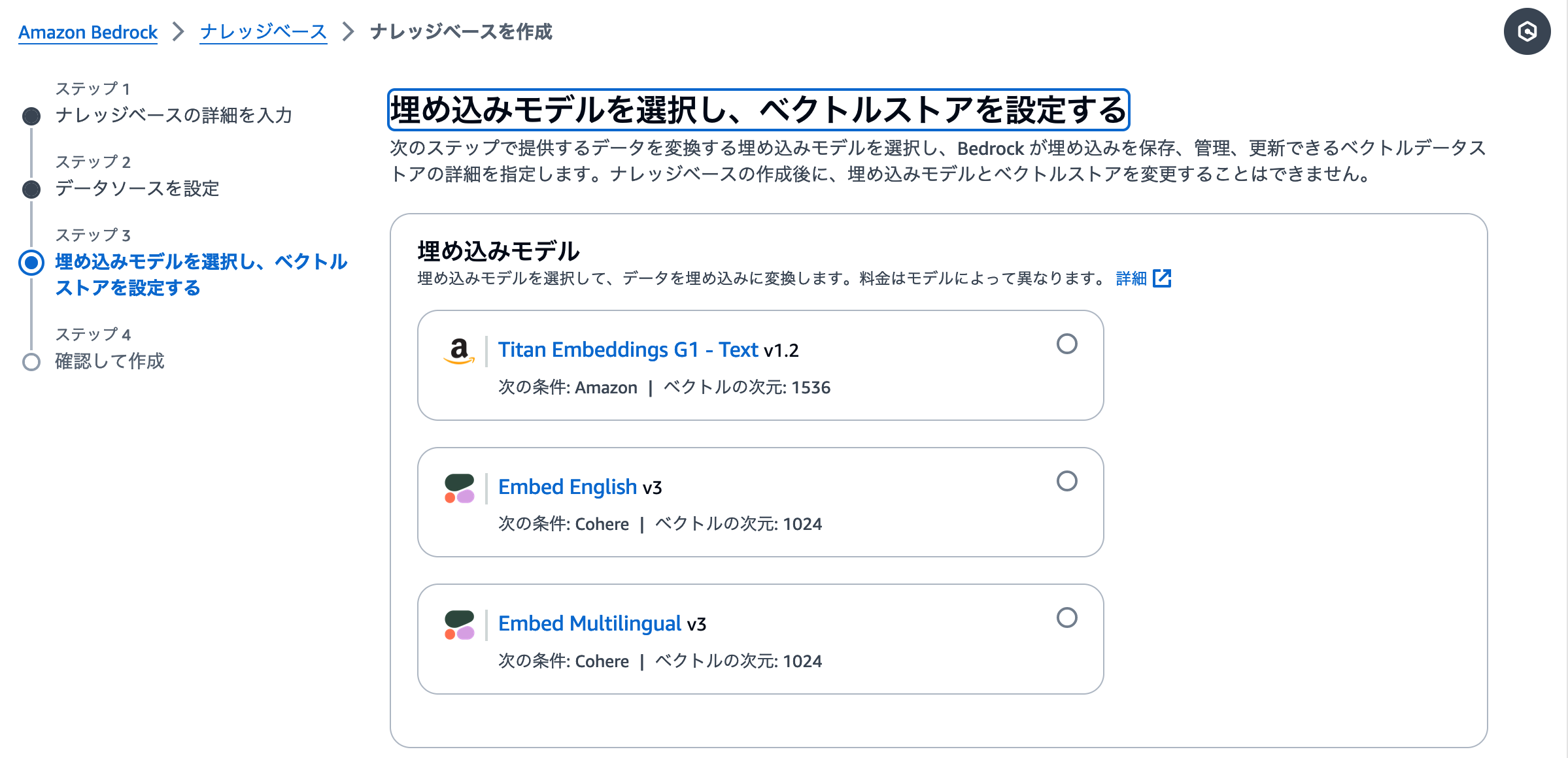
続いてベクトルデータを保存するサービスを指定します。デフォルトではOpenSearch Serverlessを新しく作成する設定になっています。Pineconeなどの外部サービスを利用することも可能ですが、今回は手順をシンプルにするため、デフォルト設定で進みましょう。
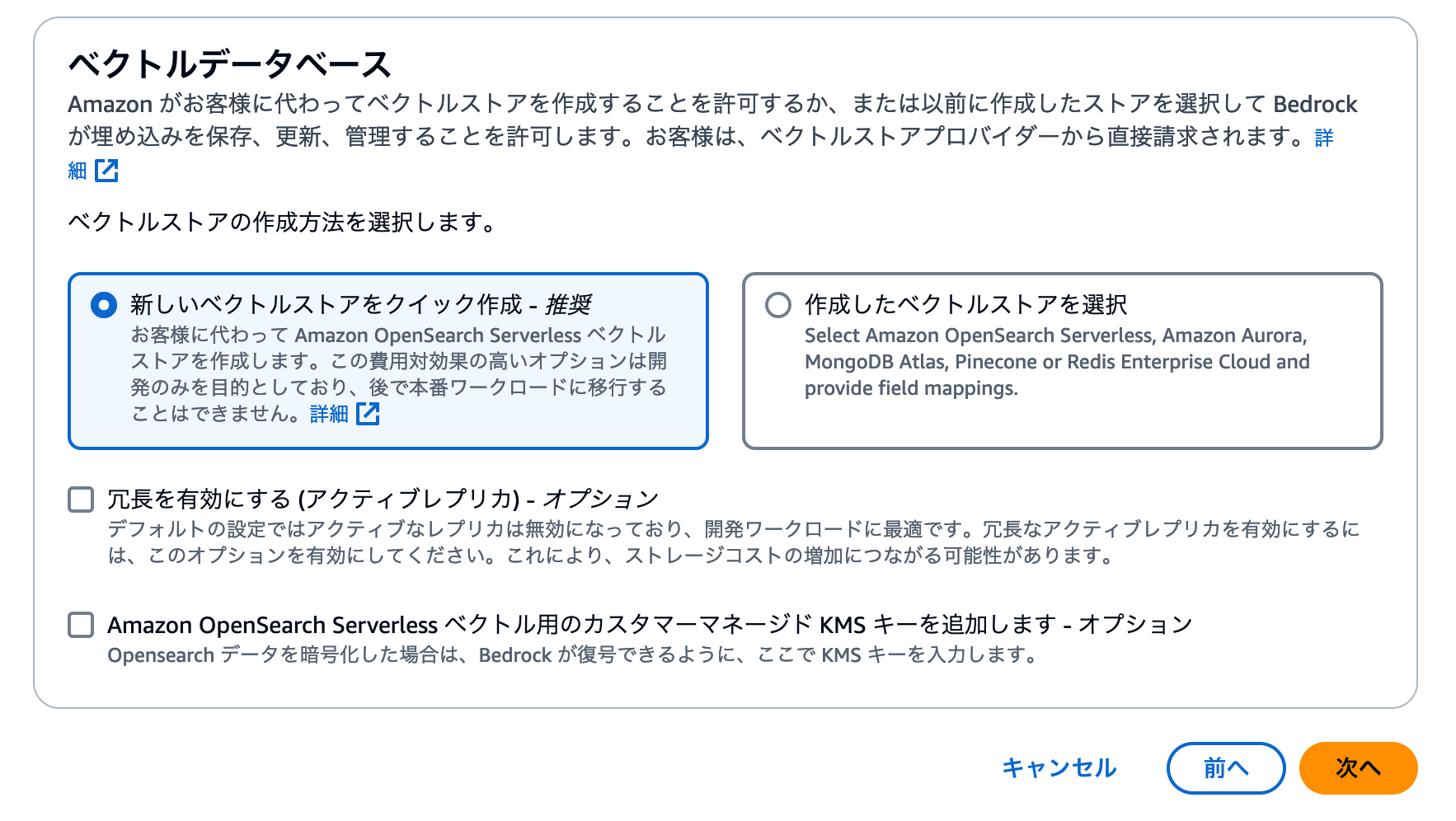
設定のレビューと作成
最後に設定した内容のレビュー画面が表示されます。データソースやベクターストアの設定などに抜け漏れがないかを確認しましょう。
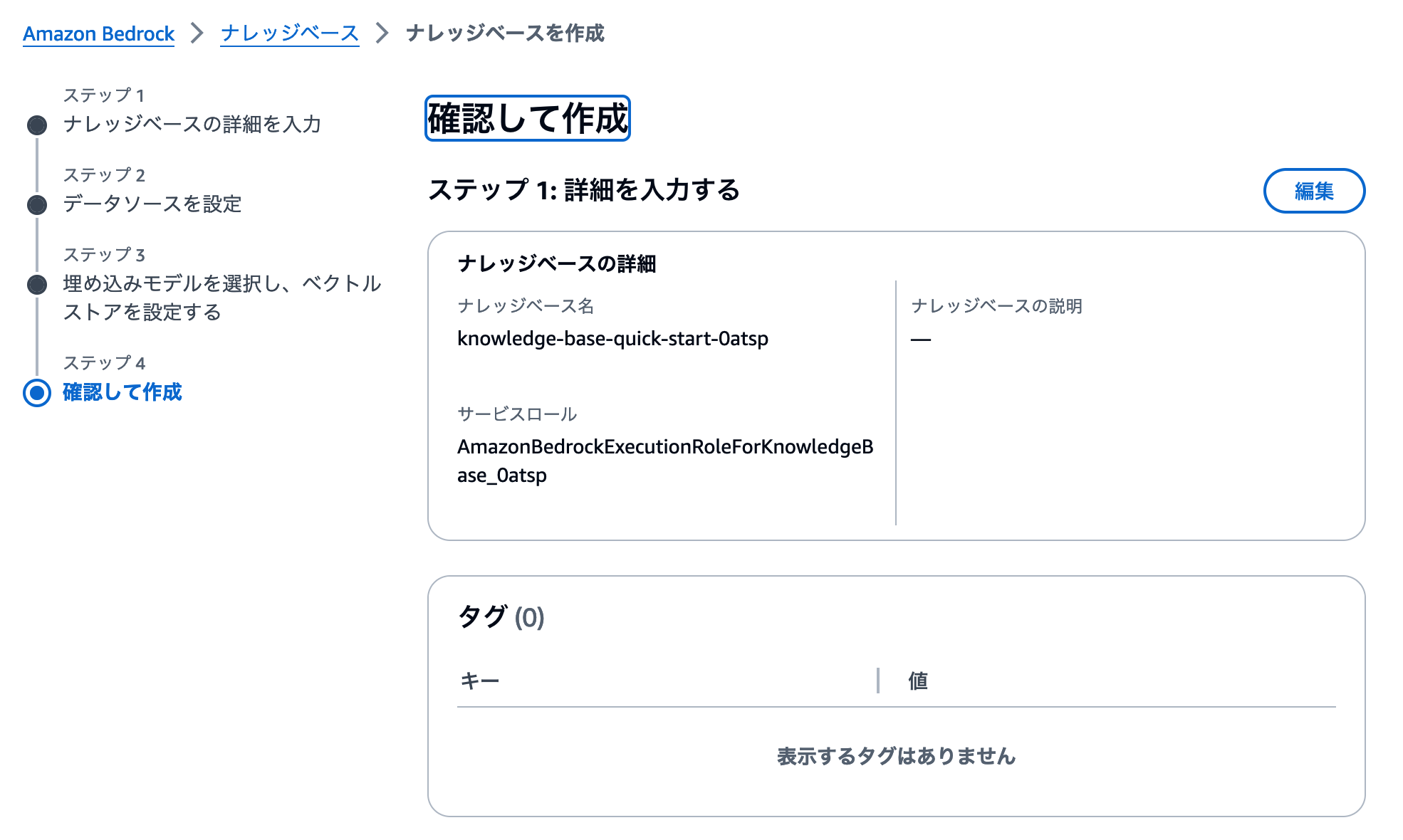
問題ない様子であれば、 ナレッジベースを作成 ボタンをクリックします。

作成が始まると、ナレッジベース一覧画面に移動します。ページ上部に[ナレッジベースが正常に作成されました]と表示されれば、作成成功です。
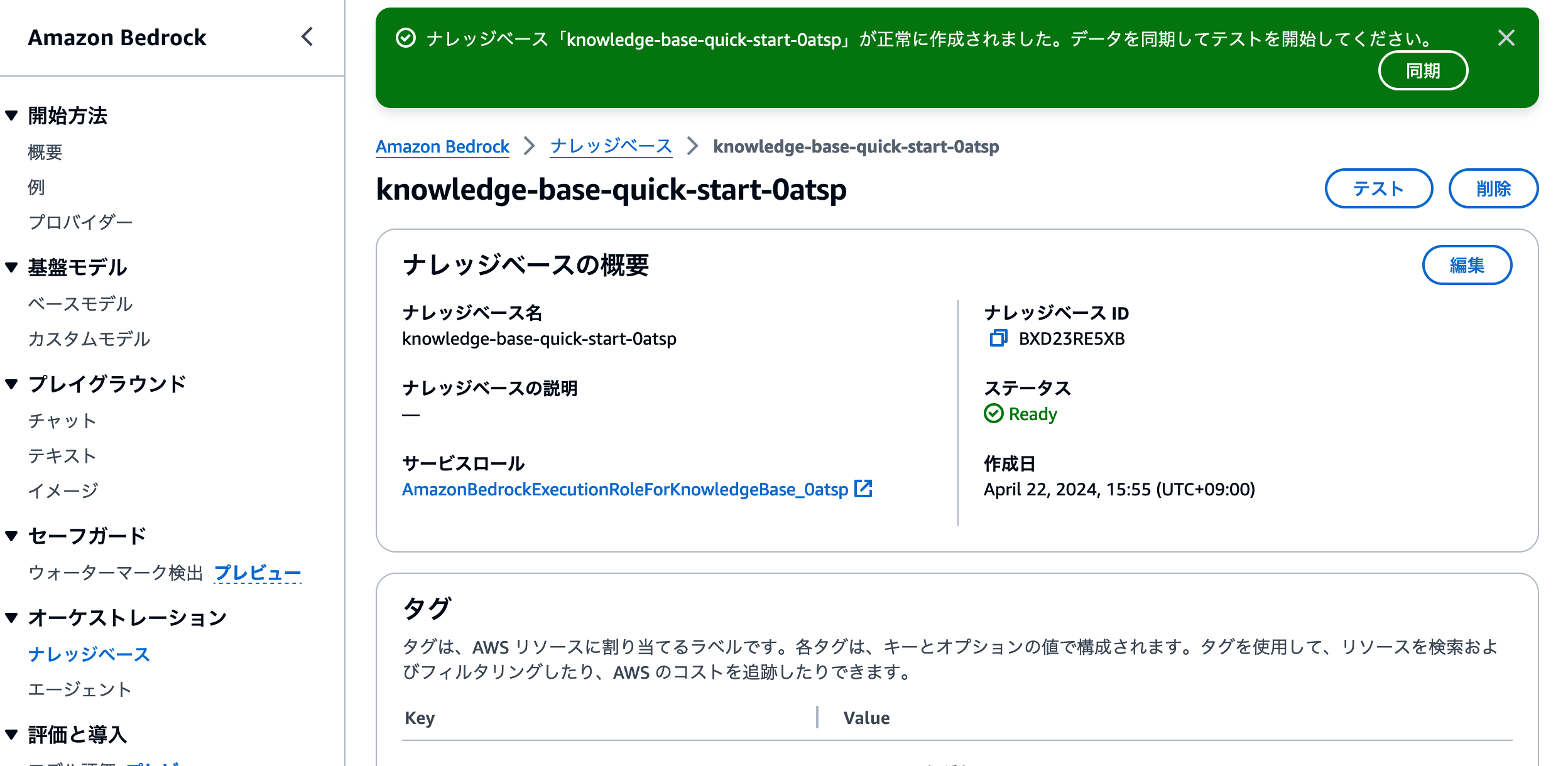
Step5: ナレッジベースへのS3バケットのデータを取り込み
作成した直後にナレッジベースは、まだ検索可能なデータがなにもありません。S3に保存したデータを利用できるように、データの同期を行いましょう。作成後に移動したナレッジベース詳細画面でページをスクロールしましょう。
ページ中段に[データソース]セクションがあります。ここではナレッジベースに設定したデータソースの追加や削除と、データ同期が行えます。同期したいデータソースを選択し、 [同期] ボタンをクリックしましょう。
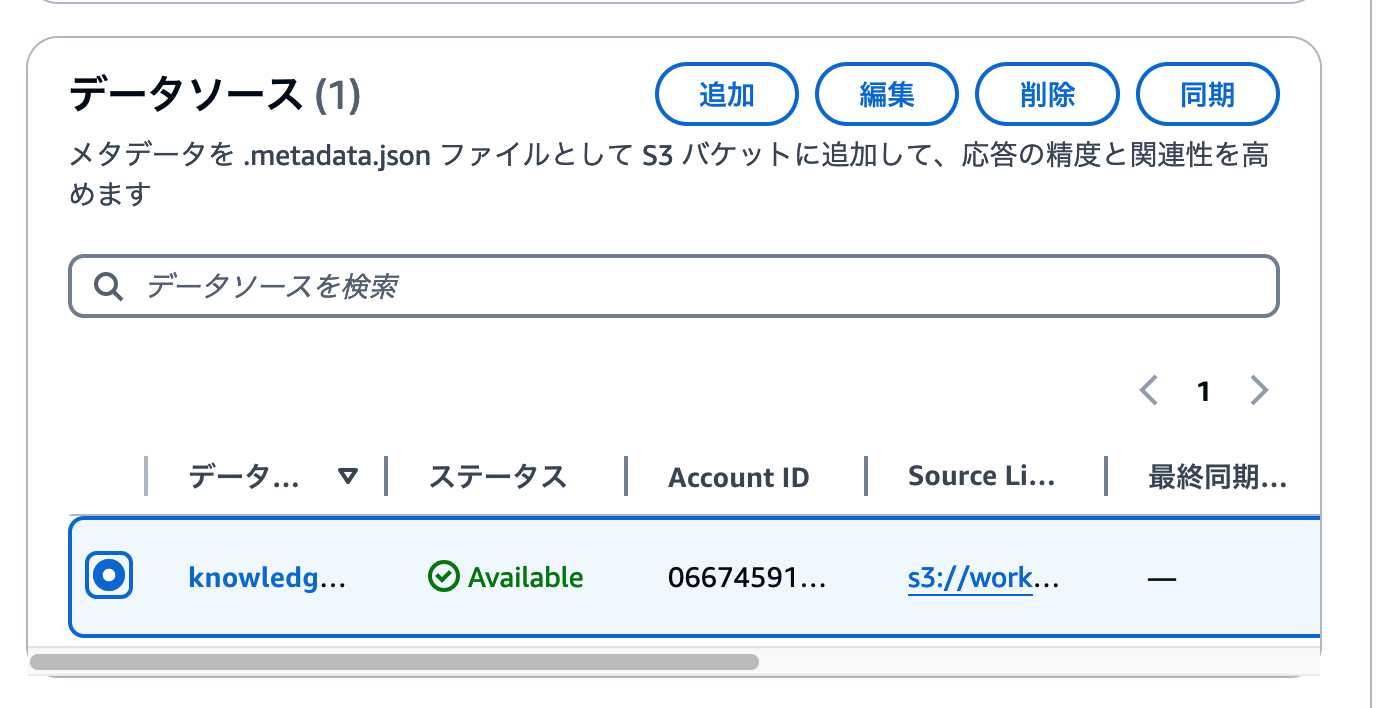
ページ上部に同期を開始したメッセージが表示されます。1・2分程度で同期が完了しますので、ここで一息いれましょう。

同期に成功したメッセージが表示されればOKです。
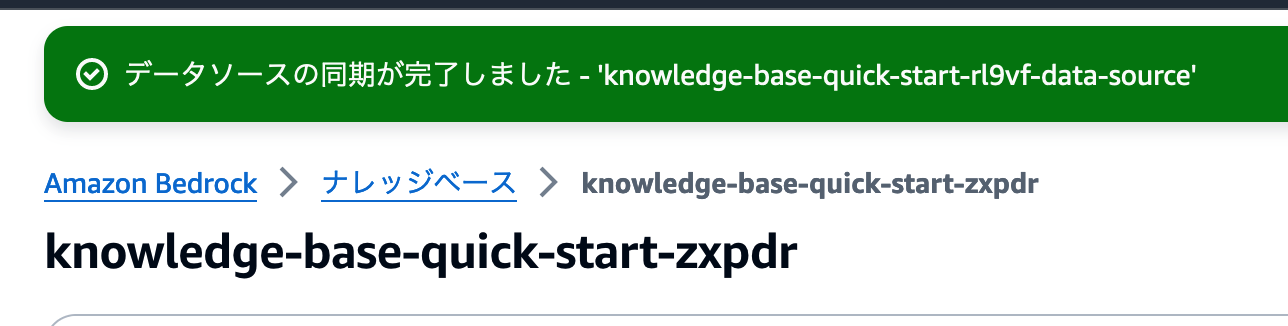
[データソース]セクションを見ると、[最終同期時刻]が表示されています。

これで独自のデータソースを利用したRAGアプリの準備ができました。
Step6: ナレッジベース管理画面で、RAG( AI チャット )の動作をテスト
ナレッジベースの準備ができました。これであとはAWS SDKを利用してナレッジベースを呼び出すコードを実装することで、アプリケーションにAIチャット機能を追加することができます。
しかしLLMを利用したRAGアプリでは、UIの組み込みの前に「検索や回答文生成の精度」をテストする必要があります。
- ナレッジベースは、質問文に関連したデータを検索・取得できているか?
- どのモデルを利用すると、期待しているような回答文章が生成できるか?
- データソースが不足しているか、事前処理を行う必要があるか?
ナレッジベースのテスト機能で、このような項目を事前に調べることができます。早い段階でテストを行い、UIの実装と回答精度の改善を同時に進行できる状況を作ることで、より顧客が満足してもらえるRAGアプリを構築することができます。
ナレッジベースをテストする方法
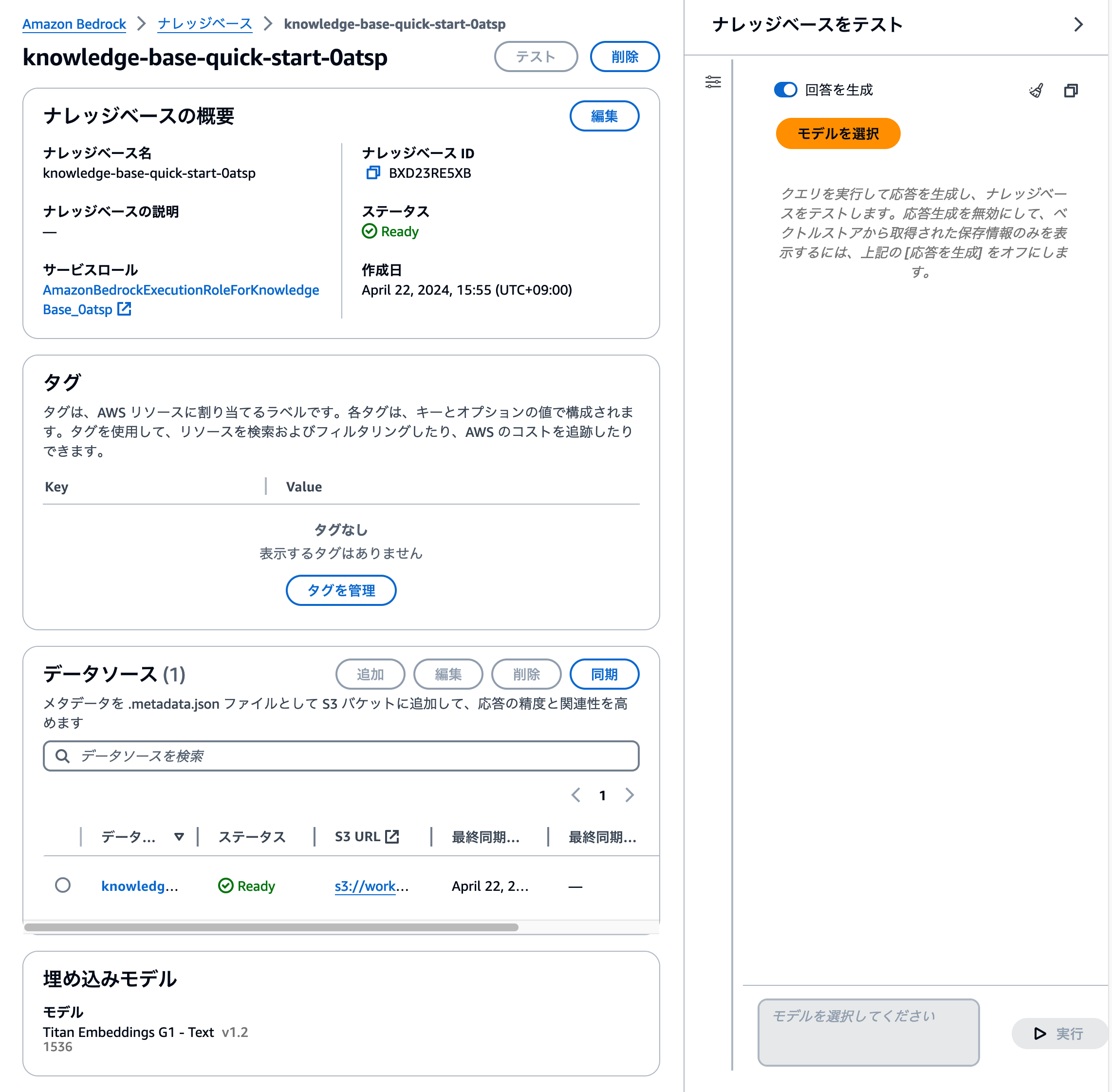
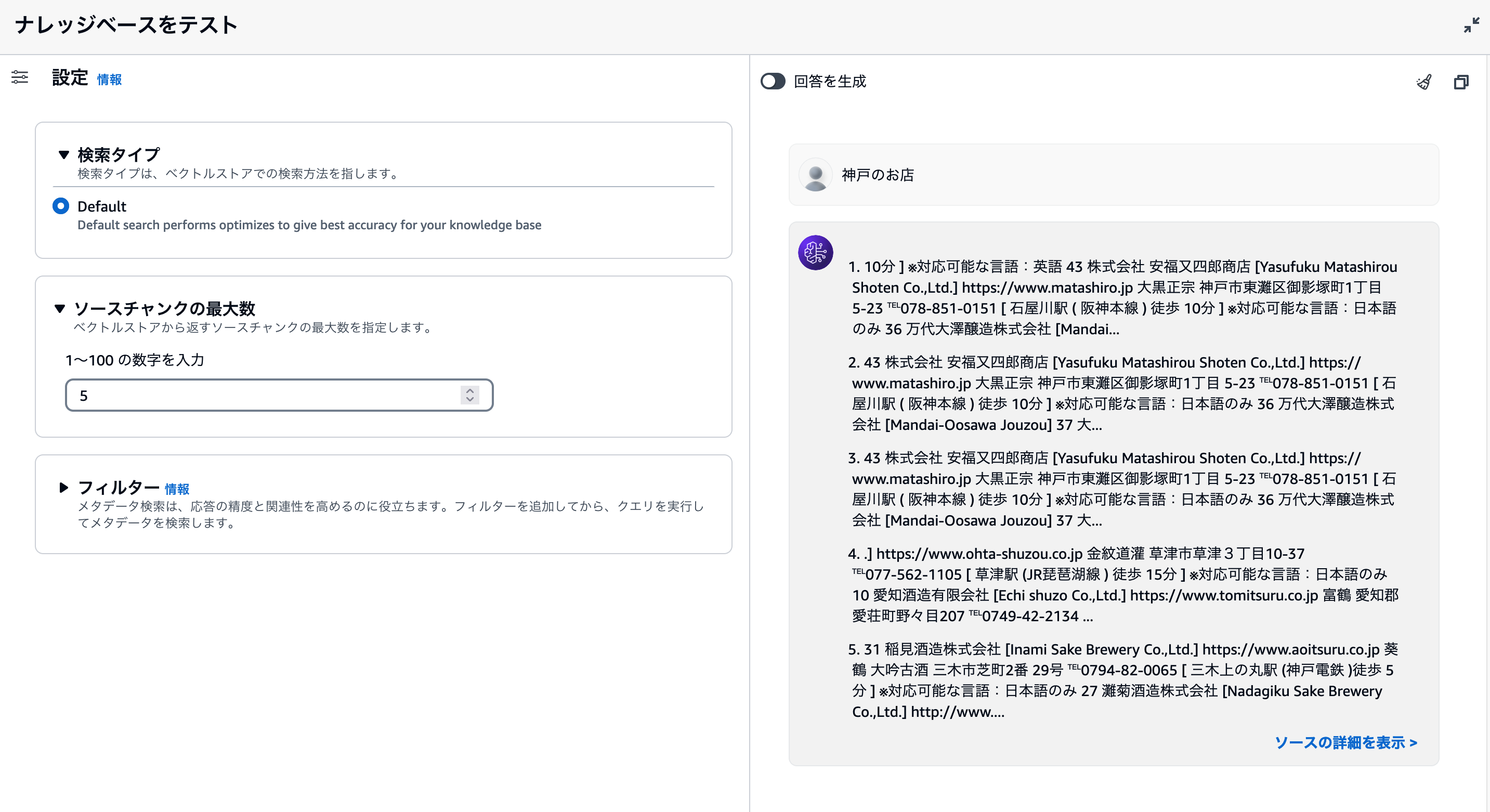
作成したナレッジベースの管理画面には、[テスト] ボタンが用意されています。このボタンをクリックすると、右側にテスト用のチャットアプリケーションが立ち上がります。

テストのチャットアプリを利用するに、まずどのモデルを回答生成に利用するかを選びましょう。検索結果を利用して、質問に対する回答文章を作成するのが、RAGアプリです。そのため、文章を生成するモデルによって回答文章の精度や長さなども変化することがあります。[モデルを選択] ボタンをクリックすると、ナレッジベースで利用できるモデルを選ぶ画面が表示されます。
モデル選択画面では、そのAWSアカウントで利用できるモデルが一覧表示されます。画像のように[アクセスがないモデル]が表示されている場合、[Step1]のモデル有効化ステップに戻って、利用したいモデルを有効化しましょう。特に使いたいモデルが決まっていない場合は、Claude 2.1やClaude 3 Sonnetを選択しましょう。
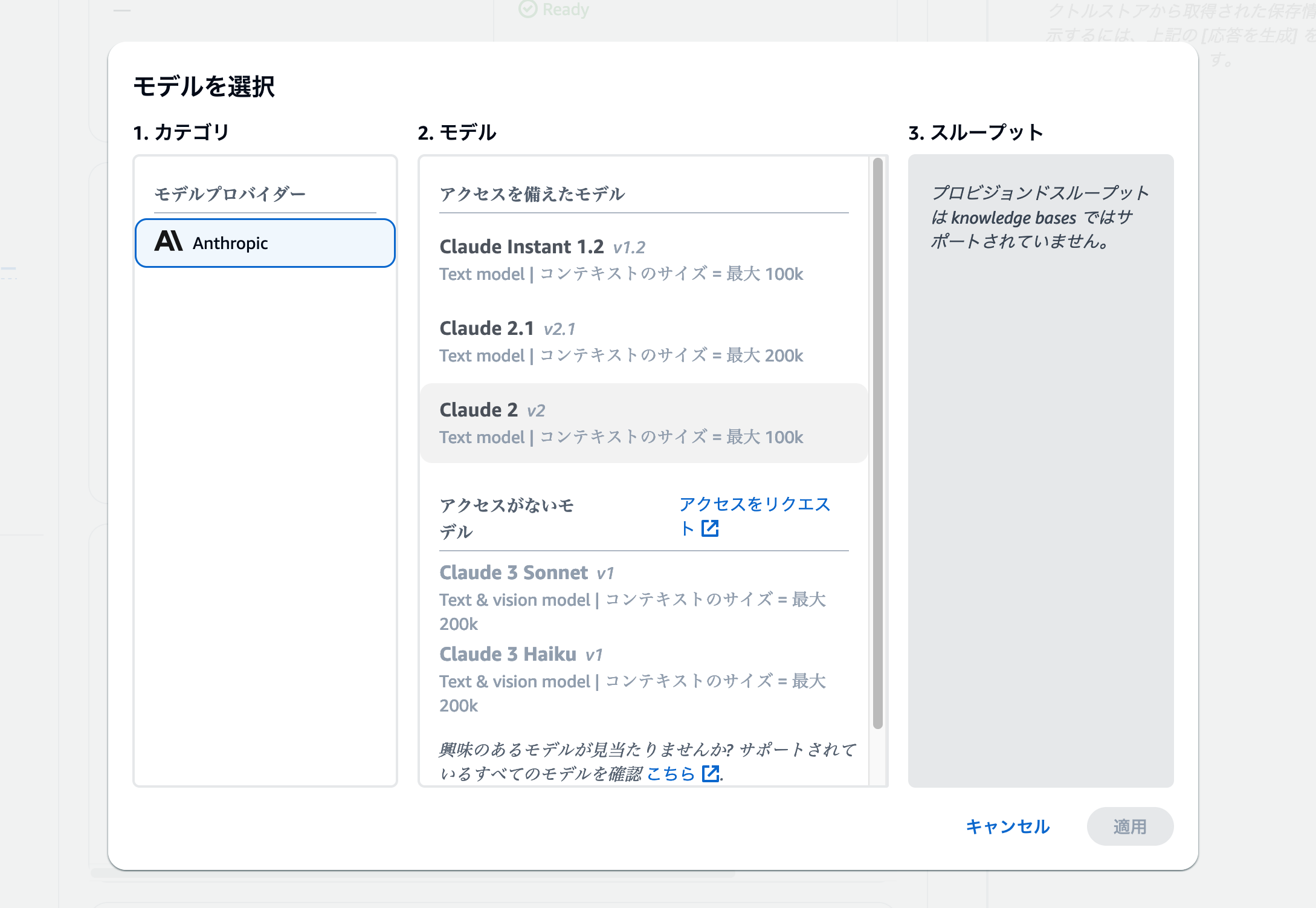
モデルを選択して [適用] ボタンをクリックすると、テスト用のチャットアプリにテキストを入力できるようになります。あとは様々な質問を送信して、アップロードしたPDFファイルの情報に基づいて回答しているかを確認しましょう。
「酒蔵ガイドマップ」を利用している場合、例えば「神戸のお店を教えて」と聞いてみましょう。Claude3 Sonnectを利用した場合、次のスクリーンショットのような回答文が生成されます。
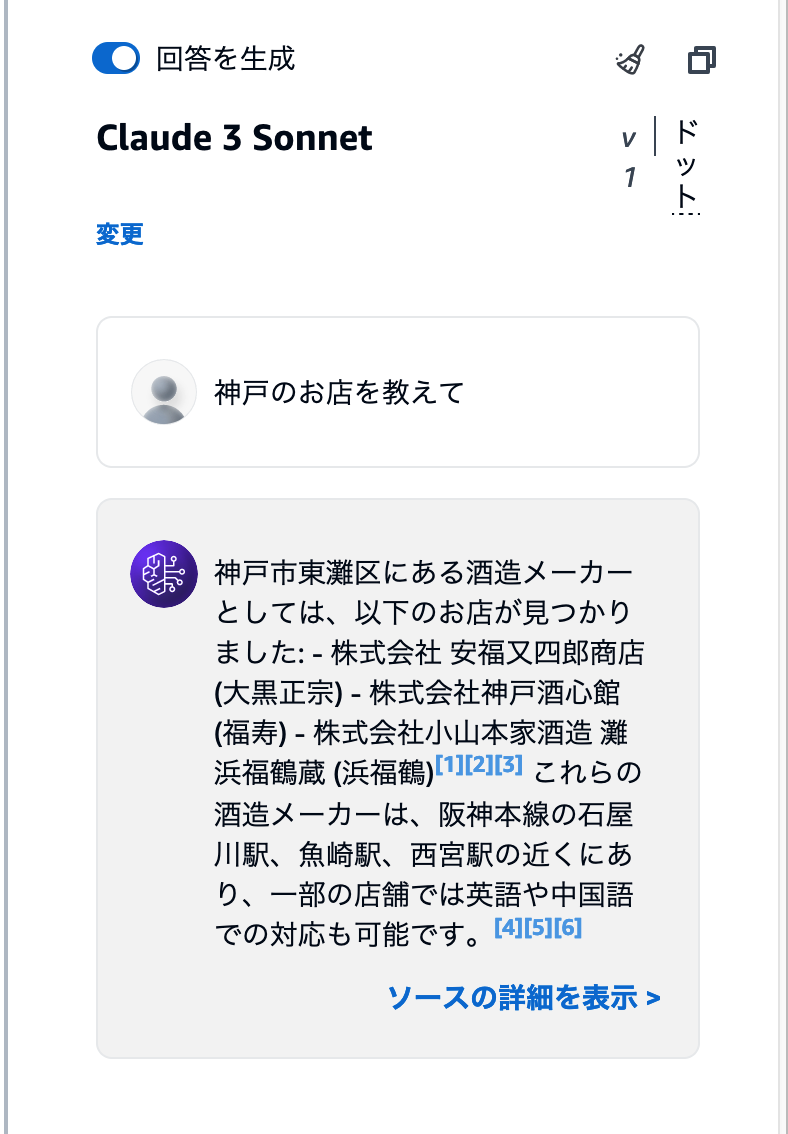
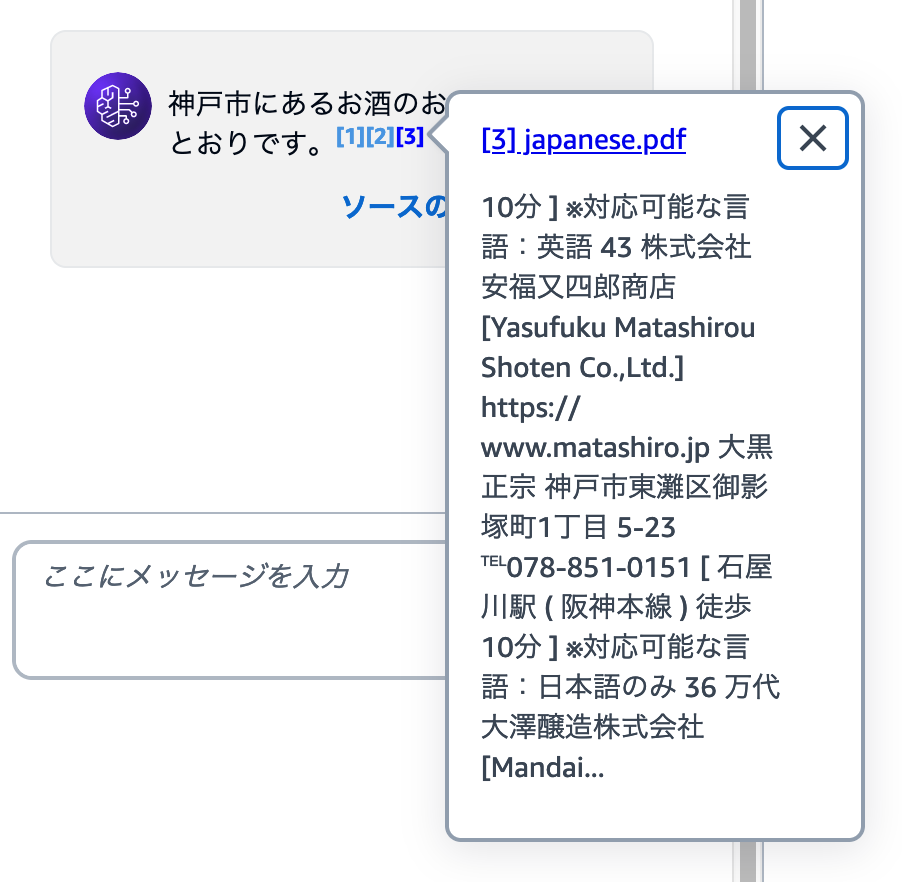
回答文章には、[1][2] のような脚注が追加されています。ここにカーソルをあわせると、参照したデータを確認できます。
どのような情報をもとに回答を生成したかをチェックする
Bedrockナレッジベースでは、S3から取り込んだデータを内部で自動的に複数のレコードに分割して変換と保存を行います。これをチャンキングやText Splitterと呼びます。
Bedrockナレッジベースのテスト機能では、[ソースの詳細を表示] をクリックすると、参照したデータについて調べることができます。
[ソースの詳細]画面では、ナレッジベースが検索・取得したチャンクデータを閲覧できます。もし質問に対する回答が意図したものではない場合、このチャンクデータを調べる必要があります。
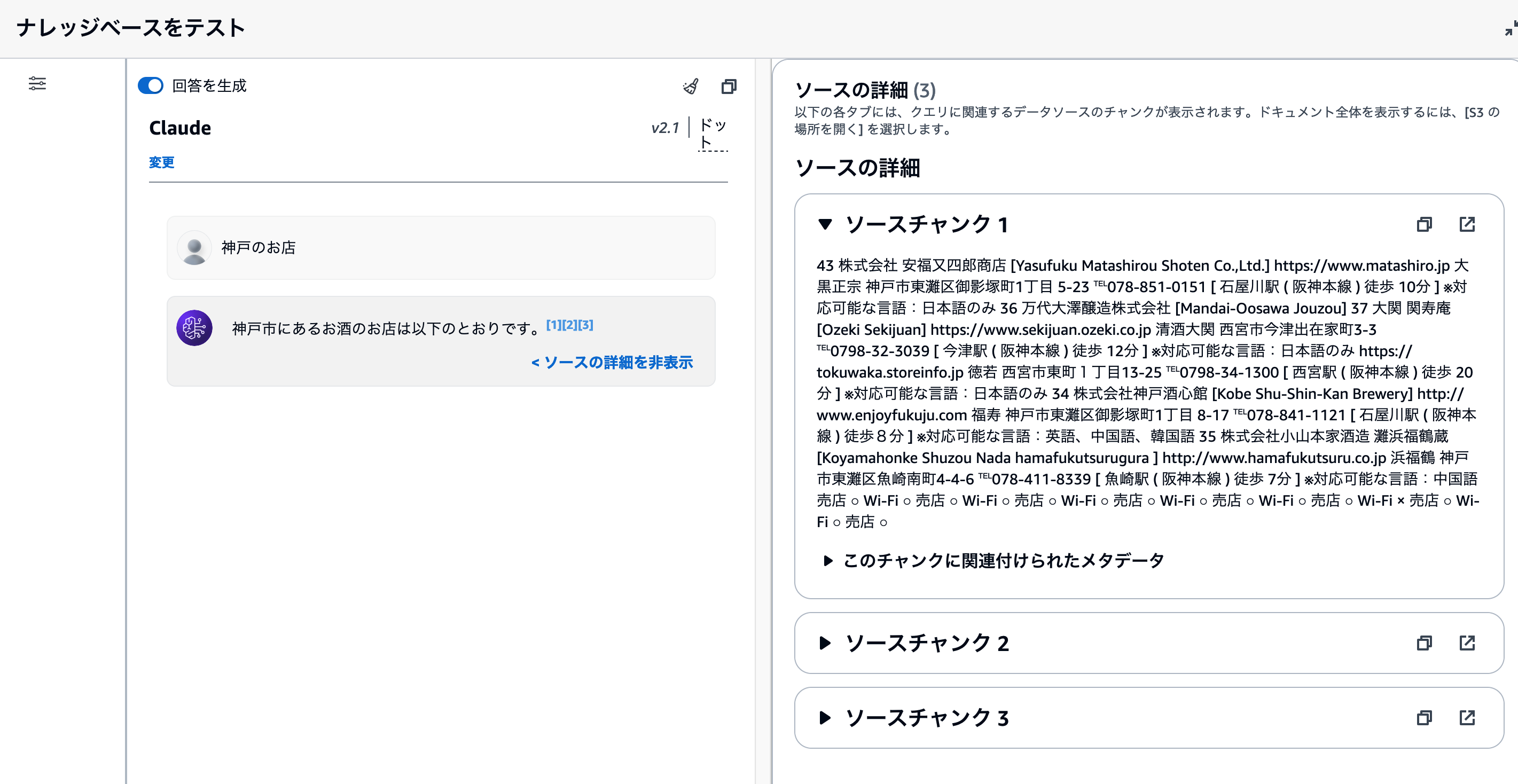
著者の経験上、ソースチャンクが次のような状況の場合、意図しない回答が高い確率で生成されます。
- ユーザーの質問意図にそぐわない検索結果である場合
例:「神戸のお店」の検索結果に「伊賀神戸」の情報が多数含まれている - 回答文章を生成するのに無関係なテキストが多い場合
例: HTMLタグや改行・スペースなどがソースチャンクの8割を占めている - イレギュラーな情報ばかり検索結果に含まれている場合
例: すでに閉店しているお店の情報が検索結果に含まれている
テスト機能でナレッジベースの動作を確認することで、「S3にどんなファイル・情報を配置すべきか?」の仮説検証が効率的に行えます。ナレッジベースを利用したデモアプリ・PoCアプリを構築・共有することで、社内でデータの利活用についても会話してみましょう。
検索をデバッグする
[回答を生成]をオフにすると、ナレッジベースの検索機能だけをテストできます。
検索結果を見ながら、元データの調整や検索タイプの変更などを試行錯誤してみましょう。
- 正しい検索結果が表示されているか?
- 不要な情報が含まれていないか?
- 件数はデフォルトの5件で問題ないか?
- chunkのサイズは適切か?(文章量が少なすぎないか?)
Q: 次のワークショップに進みますか?
1つ目のワークショップはこれで以上です。2つ目のワークショップに進む場合は、このまま次のリンクをクリックして先に進みましょう。
ここでワークショップを終了する場合は、次の**[リソースの削除]**セクションに進みましょう。
リソースの削除
最後にワークショップで利用したリソースを削除しましょう。
ナレッジベースの削除
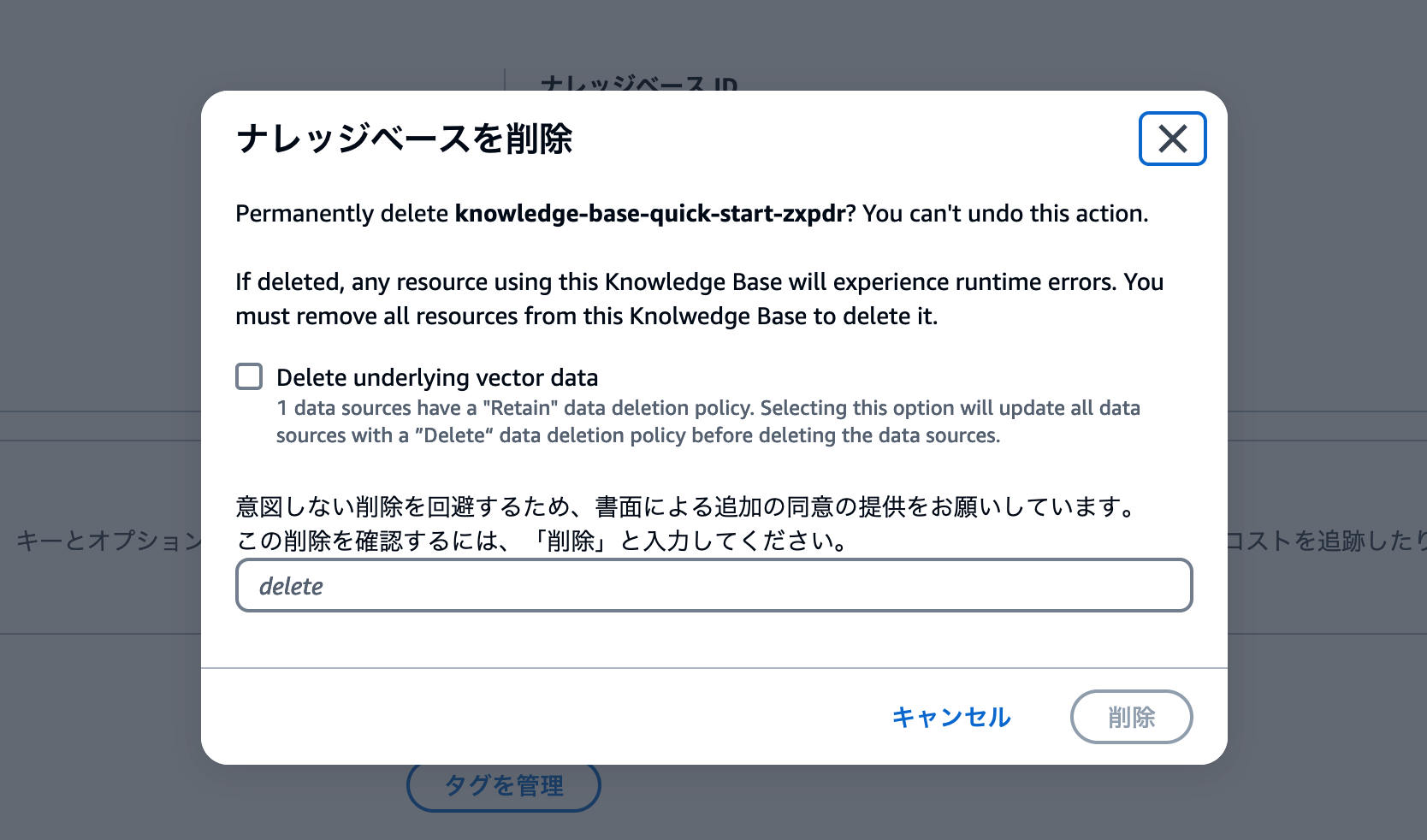
ナレッジベースの削除は、ナレッジベース詳細画面で行います。[削除] ボタンをクリックしましょう。

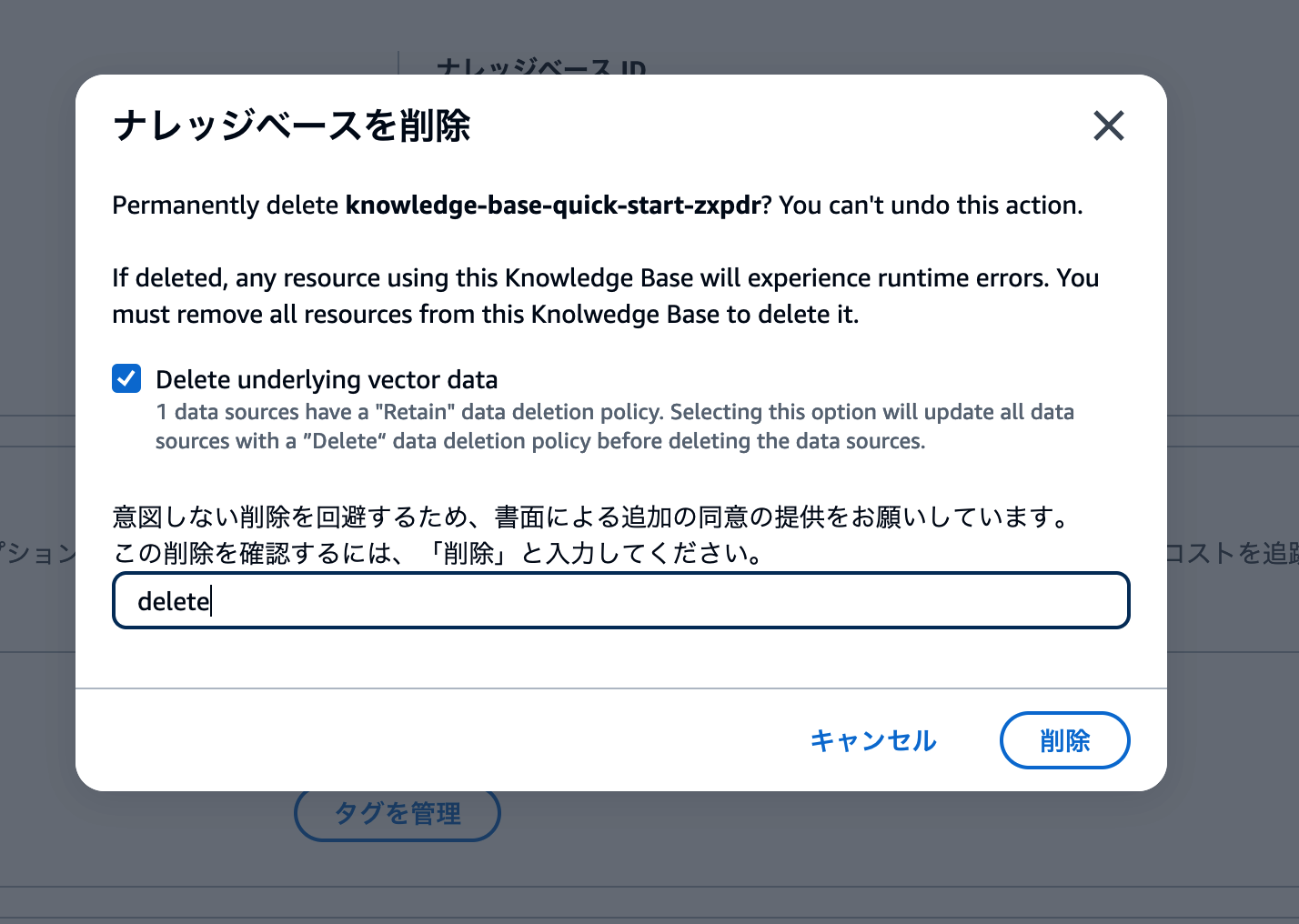
削除操作用のモーダル画面が表示されます。Delete underlying vector dataのチェックボックスをオンにして、deleteと入力しましょう。
以下のスクリーンショットと同じ状態になっていることを確認して、削除 ボタンをクリックします。
削除に成功したメッセージを確認して、削除作業終了です。
OpenSearch Serviceの削除
つづいてOpenSearch Serviceも削除しましょう。検索フォームにOpenSearchと入力して、Amazon OpenSearch Serviceに移動しましょう。
ダッシュボードに移動すると、一見リソースが何もないように見えます。しかしBedrockナレッジベースが生成するのは、サーバーレスなOpenSearch Serviceです。左側のメニューで**[サーバーレス > ダッシュボード]** をクリックしましょう。
サーバーレスのダッシュボードに移動すると、コレクションセクションにリソースが表示されました。
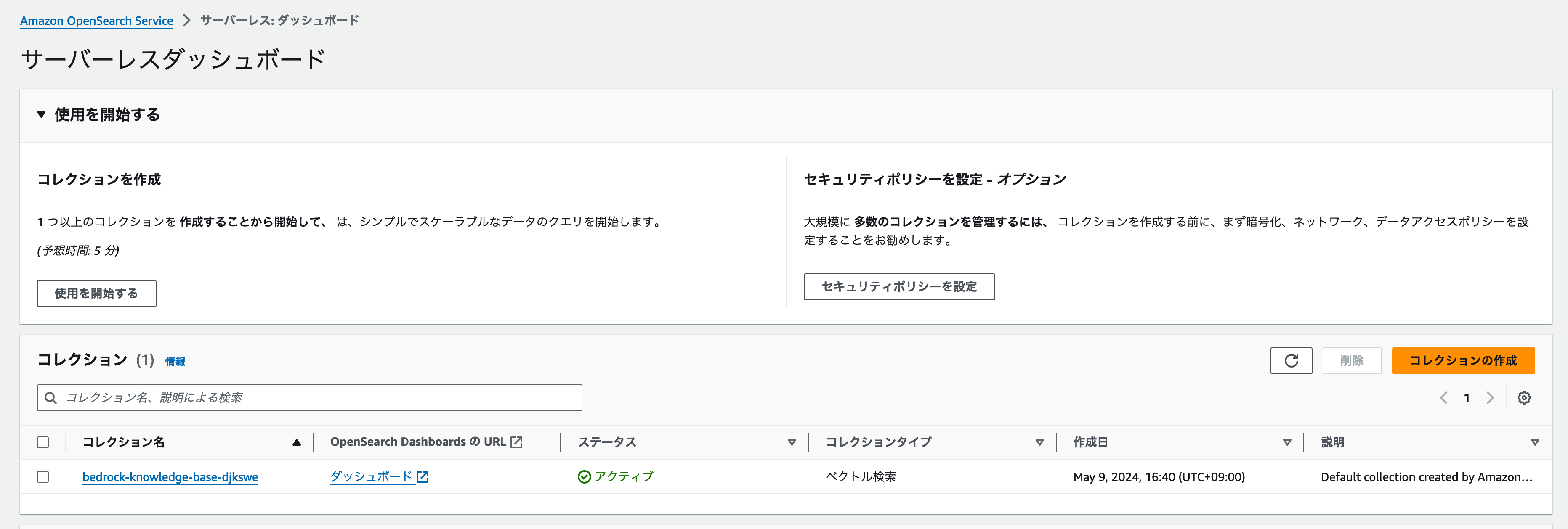
削除するコレクションにチェックを入れて、**[削除]**ボタンをクリックしましょう。

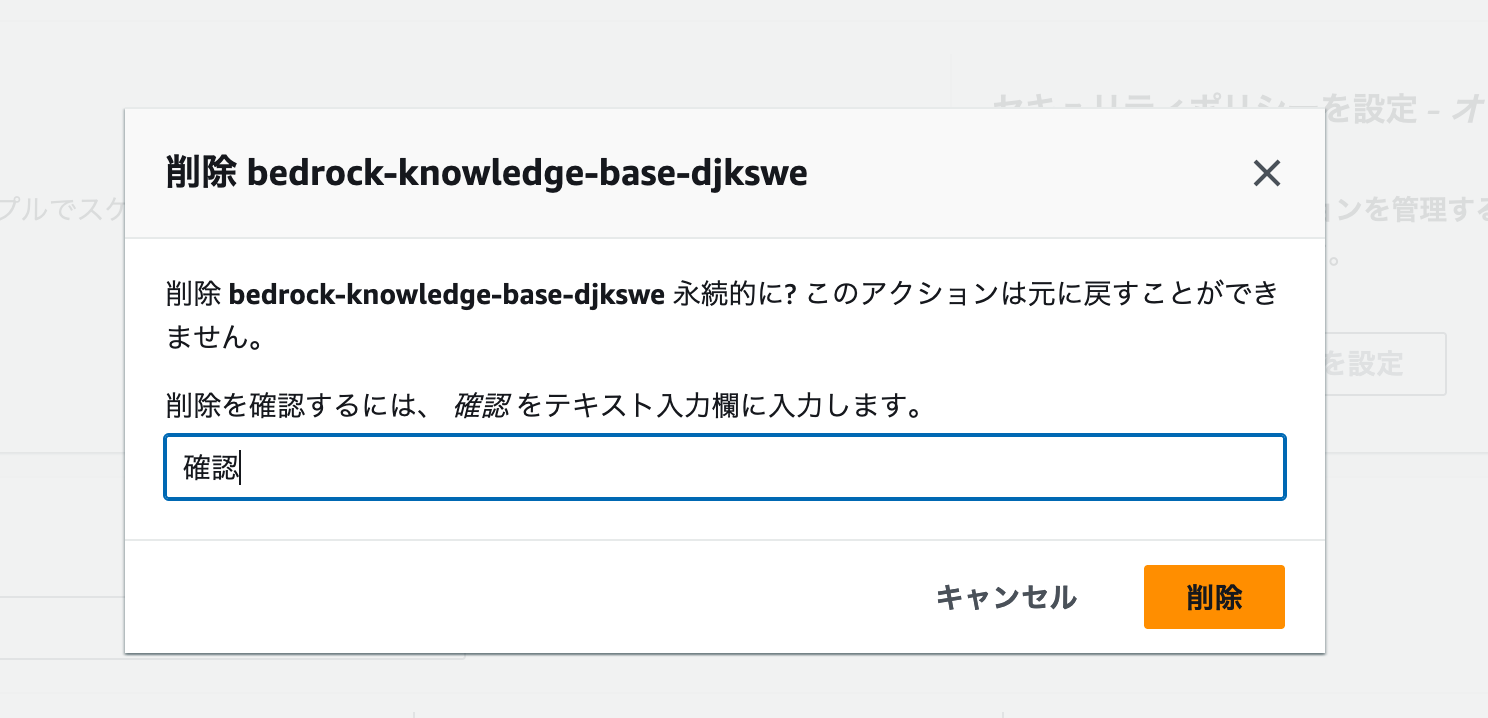
削除前の確認画面が開きます。ここでは確認 とフォームに入力します。
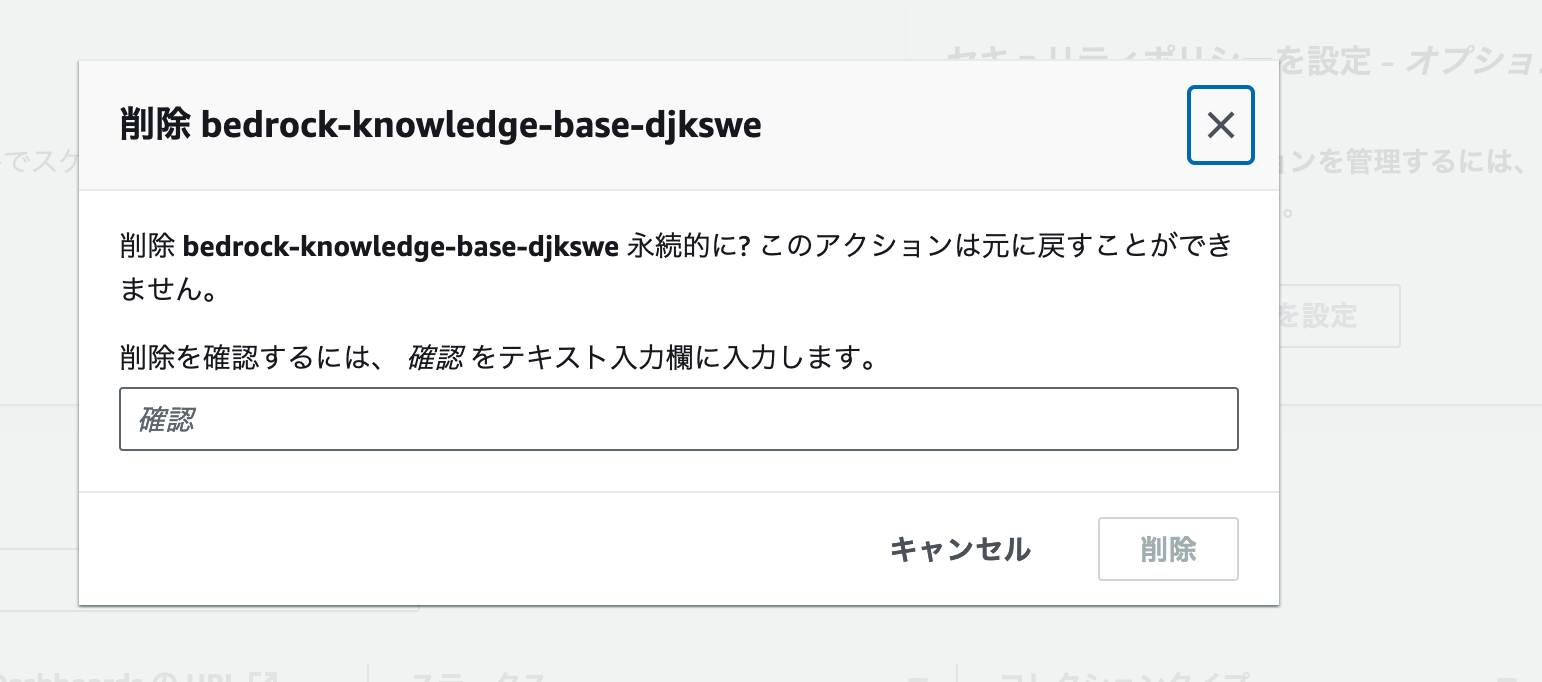
以下のスクリーンショットと同じ状態になっていることを確認して、削除 ボタンをクリックします。
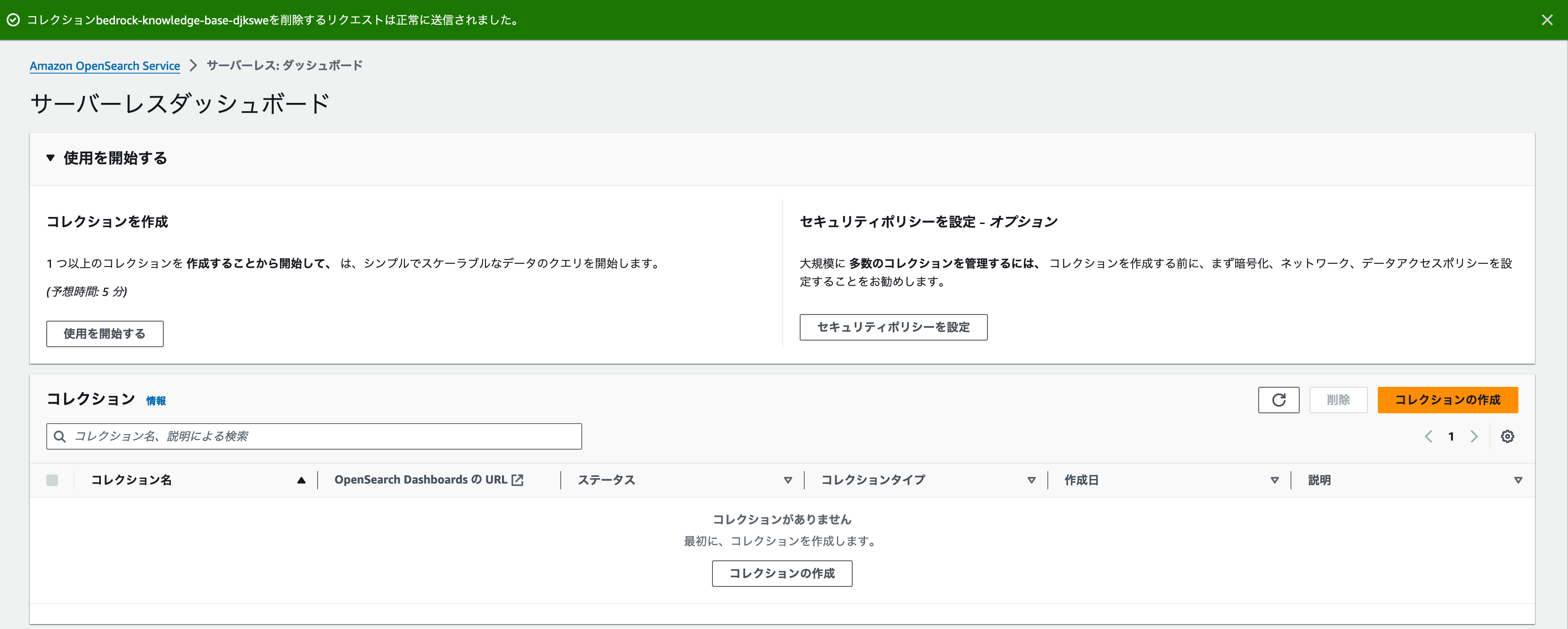
削除に成功したメッセージが表示され、コレクションセクションにリソースがなくなれば、削除成功です。
終わりに
Amazon S3とOpenSearch Service、そしてBedrockを利用することで、コードを書かずに独自の情報を参照して質問に回答するRAGアプリケーションを作れます。本番環境に投入する際は、回答の精度を高めるためにGlueやStep Functionsなども利用する必要があるかもしれません。
ですがこのワークショップで紹介している手法であれば、「とりあえず動くものを作ってみる」取り組みについては、とても簡単に実践できます。動くものを作ってチームに共有することで、「回答精度を高めるために何をすべきか?」や「別のデータセットを使ったユースケースの方が便利そうでは?」などの議論や試行錯誤をはじめてみましょう。