Stanislav Pidhorskyi Donald A. Adjeroh Gianfranco Doretto
Lane Department of Computer Science and Electrical Engineering
GANは絵が綺麗だけど、絵の制御ができない。AE系は絵の制御はできるけど、絵がボケる、という従来の問題をAEとGANのいいとこ取りでうまくやりました、という話。確かに画期的にきれいな絵がでているように見える。
概要
- ALAE - Adversarial Latent Autoencoder を提案
- 単純なMPLをEncoder Decoderに用いるものと、StyleGANのGeneratorを用いるものの2つを提案
- latent codeが disentangle できていることを確認
- 1024x1024できれいな絵が出た。
イントロ
通常のVAEでは隠れ変数空間を固定した事前確率分布に寄せていた。
一方、GANの研究では入力から十分離れた中間層がよくdisentangleされていることが確認されている。
A) 隠れ空間の分布はデータから学習することでdisentangle できるようにする。
B) 出力分布はadversarialに訓練する。
C) AE互恵性をもつようにする。
Cの意味がわからないけど、x->z->x が成り立つようにするという意味のようだ。
手法
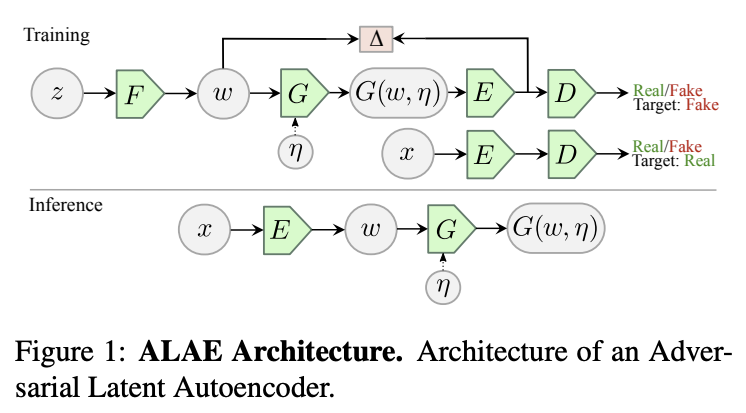
やっていることは意外に簡単で、訓練は基本的にGANで行い、その際に用いたエンコーダとデコーダを用いて画像の再構成などを行う。
図中一番上のの F->w-> G がGANで言うところの生成ネットワーク。右のE->Dの部分がDiscriminator ネットワークに相当する。ポイントは
- 生成ネットワーク、Discriminatorネットワークをそれぞれ2つに分けて、その一部がエンコーダ(E)、デコーダ(G)として使えるようにしていること。
- FとGの間のwとEとDの間がrepresentation に当たるのだが、この2つがおなじになるように最適化すること。
評価
-
7.1 の評価では、MNISTを1次元配列にしたものを利用。CNNでなくMLP。
-
long feature -1024 bit, E, G の中間層
-
short feature -50 bit Wの空間
-
dw, sw はわりにどうでもいい感じ。
-
学習した表現に対して、簡単なクラス識別が簡単に学習できるか、をみている。disentangleできてれば、簡単に識別できるはず、ということだがこれはダウト。というかdisentangleできていれば簡単に識別できるのは本当だが、簡単に識別できるからと言ってdisentangleできているとは限らない。
-
線形SVM での結果と1NNの結果を比較している。線形SVMはdisentangleできていないと識別できない、ということらしい。disentanglementと線形分離可能は違うはずだが。この2つで性能が大差ないALAEはdisengangleできていると主張。
-
xからx'の再構成は今ひとつに見える。これはある意味当たり前で、zのレイヤでの再構成ロスを最小化しているだけでxのレイヤではしていないから。そう考えるとこの再構成は逆にすごい。
-
7.2 StyleALAE をStyleGANと比較。
-
https://arxiv.org/abs/1812.04948 - StyleGANの論文で提案されているPPL Perceptual path lengthで比較