Lesson1: 「Webアプリケーション」とは何か
アプリケーションはデスクトップアプリケーションとWebアプリケーションの2つに大別される。
デスクトップアプリケーション
-
主な処理は手元のPC上で行われる。
-
画面は、OSの昨日を利用して表示されている。
-
アプリケーションをPCにインストールする必要がある。
Microsoft Officeなどはデスクトップアプリケーション。
Webアプリケーション
-
主な処理はサーバー上で行われる。
-
画面はHTMLで表示され、Webブラウザ上に表示されている。
-
アプリケーションをPCへインストールする必要なし。
Lesson2: Webはどのように発展したか
Webを支える技術の発明
World wide webによるハイパーテキストの公開と閲覧は、「Webサーバー」と「Webクライアント」というソフトウェアによって実現されている。
クライアントがHTMLのrequestをサーバーに送ると、サーバーがresponseという形で要求されたHTMLをクライアントに投げ返すという仕組み。
コンテンツ(HTML)をサーバー上に一括管理することで、コンテンツの更新を簡単にしている。また、インターネットを利用することで、不特定多数の人がリモートでコンテンツにアクセスすることを実現している。
インターネット上のコンテンツを一意に定めるために利用されているのがURL(Uniform Resource Locator)。
上記のURLは3つの部分から構成されている。
-
スキーム: リソースを取得するための方法。(ex: httpsは暗号化されたhttp通信)
-
ホスト名: リソースが存在するホスト(コンピュータ)名。ローカル名と親ドメイン名に分かれる。
-
パス名:指定されたホスト上のリソースの位置を示している。
CGIの登場
Webサーバー上で動作するプログラムが生成したHTMLを動的コンテンツ。もとから用意されていたHTMLを静的コンテンツと呼ぶ。
動的コンテンツを扱うCGIでは、Webサーバーがクライアントから受け取ったリスエストをWebサーバー上で動作するプログラムに渡し、HTMLを作成していた。
しかし、CGIでは大量のアクセスをさばききれなかった。
そこで使われるようになったのがJAVA/サーブレット。オブジェクト指向のJAVAは大規模開発に向いており、かつWebサーバーと同じプロセスの中でコンテンツを生成するプログラムが動作するため、CGIのように新たなプロセスを毎回起動する必要がなく、高速に動作した。
また、JAVAは仮想環境であるJVMの上で動作するため、特定のOSやハードウェアに依存すること無く動作したため、扱いやすかった。
しかし、そんなサーブレットも、JAVAの中にHTMLを埋め込むような形式をとっていたため、デザイナーとエンジニアのコミュニケーションが取りにくいという問題を抱えていた。
JSPはHTMLの中で動的に動かしたい部分のみJAVAで記述するという方式を取り、その問題を解決した。
現代では、Webアプリケーションがより大規模化してきたため、JSPではなくWebアプリケーションフレームワークという概念が主流になってきている(Lesson6参照)。
Lesson3: HTTPを知る
HTTPリクエストの構造
GET http://www.littleforest.jp/webtext/http/index.html HTTP/1.1
-
メソッド:リクエストの種類を表す。GETはURLで指定した情報を送ってくださいという意味になる。
-
URI:URLとURNをあわせたもの。
-
HTTPバージョン:HTTPのバージョンを表す。
メッセージヘッダーはリクエストの付加的な情報を表している。
Accept: */*
Accept-Language: ja-JP
User-Agent: Mozilla/4.0
Accept-Encoding: gzip, default
Proxy-Connection: Keep-Alive
Host: www.littleforest.jp
Pragma: no-cache
-
Accept: Webクライアントが受け取ることができるデータの種類(Content-Type)を表している。(ex: text/plain, image/jpeg)これを参照することで、サーバーは不要な情報を送らなくて済む。
-
Accept-Language: Webクライアントが受け取ることのできる自然言語の種類。
-
User-Agent: 利用しているWebブラウザの種類やバージョンを示している。
-
Host: リクエストの送信先ホスト名やポード番号を指定する。
HTTPレスポンスの構造
HTTP/1.1 200 OK
Date:
Server: Apache/2.2.11 (Unix)
Last-Modified: Sat, 16
Accept-Ranges: bytes
Content-Length: 214
Keep-Alive: timeout=15, max=100
Proxy-Connection: Keep-Alive
Connection: Keep-Alive
Content-Type: text/html
<!DOCYPTE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html lang="ja">
<head>
<title>HTTP通信チェック</title>
</head>
<body>
</body>
</html>
-
ステータスライン:HTTPバージョン、ステータスコード、レスポンスフレーズで構成されている。(ex: 200 OK, 302 Found, 401 Unauthorized, 403 Forbidden, 404 Not Found, 505 Internal Sever Error)
-
メッセージヘッダー:レスポンスに対する付加的な情報が入っている。
-
メッセージボディ:HTMLフィルの内容がそのまま入っている。
IPアドレスとTCP/IP、DNS、Port
TCP/IPはブラウザなどから受け取ったHTTPリクエストなどの情報を、パケットと呼ばれる小さな単位に分割して送信し、受け取った側でそれらをのとのように組み立ててから受け手となるWebサーバーはなどのアプリケーションに渡している。
グローバルIPアドレスISPによって割り振られるが、プライベートネットワークにおいてはプライベートIPアドレス(ある一定範囲のIPアドレス)を自由に利用できる。
DNSはドメイン名とIPアドレスの対応表を乗ったコンピュータであり、DNSサーバに問い合わせればドメイン名の対応するIPアドレスを教えてもらうことができる。
> nslookup husky-tech.hatenablog.com
インターネット上には各階層に対応するDNSサーバが用意されている。jp、com、net、orgといったトップレベルドメインはルートサーバーによって管理されている(世界で13個)。
以上の技術を利用して、URLに含まれるホスト名から宛先のIPアドレスを探し出している。しかし、受信した情報がどのプロトコルのものであり、どのようなアプリケーションが処理するべきなのかTCP/IPはわからない。
そこで利用されるのがPortの概念である。HTTPプロトコルの場合は80番と決まっている。(443: HTTPS, 53: DNS, 20 or 21: FTP, 22: SSH, 23: Telnet, 25: SMTP)
Webサーバーへの要求をどのように伝えるか
/do_calc_get.php?arg1=123&arg2=456
Get methodによってパラメーターをサーバーへ受け渡しする際には、以上のように、?以降に現れるクエリ文字列として受け渡される。しかし、URLの中にパラメーターが含まれるため、どのような情報をサーバーに送信したのか第三者に漏洩しやすいというリスクが存在する。
その問題を解決するPost methodでは、パラメーターをメッセージボディに格納して、サーバーに渡している。同時に、Webサーバーのログに記録される確率も低くなる。
以上を踏まえると、GETメソッドはセキュリティが低くパラメーターの長さが255文字以内に制限される可能性があるが、パラメーターの保存・再現がしやすく副作用が発生しないことも期待される。一方で、POSTメソッドはセキュリティが高くパラメーターの長さに制限がないが、保存・再現性は低く、副作用が発生する可能性がある。
日本語をクエリ文字列として渡した際には、ブラウザがパーセントエンコーディングを行う。
Lesson4: CGIからWebアプリケーションへ
アプリケーション開発の流れ
-
HTMLでモック画面を作成する。クライアントの要件に合わせて仕様変更も行う。
-
ログイン認証機能を作成する。→ログイン成功時と失敗時で違う画面に遷移するようにLocationヘッダを設定する。この場合リダイレクトを挟むので、GET→200 OK→POST→302 Found→GET→200 OKという流れになる。
-
クッキーをもたせる仕組みを作る。ログアウトの際はクッキーを削除するような仕様にする。
-
セッションを発行する仕組みを作る。
クッキーの役割
FTPサーバーは、リクエストに伴って状態が変化するStateful Protocolであるため、オーバーヘッドが大きくなってしまう一方で、HTTPのような状態をもたないStateless Protocolは手順が少ないが、情報の保持が難しい。
そこで用いられるのが、Webブラウザに情報をもたせるCookieという技術である。WebサーバーからHTTPレスポンスのヘッダを利用して送られてきた情報をWebブラウザは保存し、次回同じWebサーバーにアクセスする際に受け取ったCookieをそのままHTTPリクエストのヘッダに入れて送信する。
Cookieを受け取ったサーバとは異なるWebサーバーに対して、Cookieを送ることが無いので、意図しない情報が他のWebサーバーに送られてしまうことはない。
セッションの役割
Cookieにユーザー名とパスワードをもたせることで、ログインの手順を簡略化することができるが、Cookieは簡単に見ることができるため、依然としてセキュリティに問題がある。
そこで使われるのがセッションである。ユーザーがログインすると、サーバーでセッションIDが発行され、それがCookieに格納される。そのため、リダイレクトの際にユーザーのセッションに基づいた情報を復元することができる。また、異なるブラウザで開いた場合には、セッションIDがCookieに存在しないため、新しいセッションIDが発行され、Cookieに格納される。
ログアウトした際には、セッションは破棄されるので、再び復元することはできない。
Lesson5: Webアプリケーションの構成要素
データベースサーバの登場
膨大な情報を管理するために、Webアプリケーションではデータベースを活用する。データベースの操作はCRUD(Create, Read, Update, Delete)と呼ばれる。リレーショナルデータベースと呼ばれる、複数の表とそれらを定義することで情報を管理する方法が主流。Webアプリケーションにおいては、WebサーバーがSQLを発行し、データベースの更新を行う。また、クエリ結果に基づいてHTMLを生成する。
データベースは、一枚の大きな表に全てのデータを保存すればよいということはなく、できる丈重複した情報を排除し(正規化し)データの更新が行いやすい状態にする必要がある(データベース設計)。
データベースサーバの分離
小規模なアプリケーションでは、Webサーバー上にデータベースを保持している場合もあるが、データベースが大きくなった際に、ディスク領域を圧迫したり、多くの利用者がアクセスしCPUの負荷が高くなったりすると、システムダウンの危険性がある。
そのため、データベースサーバーを分離させることで、負荷を下げる。また、既存システムを壊さないというメリットも存在する。
アプリケーションサーバの登場
CGIはWebサーバへリクエストが届くたびに新しいプロセスの起動と終了を行っていたが、アプリケーションサーバは常にプロセスが実行されている。
通常、Webサーバとアプリケーションサーバは、WebサーバがクライアントからのHTTPリクエストを全て受け入れ、URLによってアプリケーションサーバが処理すべきリクエストだけをアプリケーションサーバに転送している(ex: ApacheとTomcatの関係)。
Webサーバとアプリケーションサーバを異なるノードに配置すると、軽い処理で回数の多い静的コンテンツへのリクエストはWebサーバに、回数が少なく処理の重い動的コンテンツへのリクエストはアプリケーションサーバへと、異なる性格のリクエストをうまく分担することができる。
worker.list=worker1, worker2
worker.worker1.host=192.168.1.2
worker.worker1.port=8009
worker.worker1.type=ajp13
worker.worker1.host=192.168.1.3
worker.worker1.port=8009
worker.worker1.type=ajp13
JkWorkersFile /usr/local/apache2/conf/workers.properties
JkLogFile /usr/local/apache2/logs/mod_jk.log
JkLogLevel info
JkMount /webtext/* worker1
JkMount /nazejava/* worker2
アプリケーションサーバが提供する機能
-
セッション管理
-
トランザクション管理(& ロールバック)
-
データベース接続の管理(コネクションプーリング)
-
Webアプリケーションの管理とシステムの可用性・性能の向上(セッションレプリケーション→アプリケーションサーバ同士が連携してセッションの状態を共有する。)
Webシステムの3層構造
-
APサーバとDBサーバを同じサーバに持つ(最小単位)。
-
Webサーバ、APサーバとDBサーバを分離させる。(中〜大規模)
-
WebサーバとAPサーバを同じノード(コンピュータ)に配置し、DBサーバを分離させる。(業務システムのように利用者は少ないが、データは膨大なもの。)
OSSとライセンス
-
コピーレフト型(GL)→公開必須。
-
準コピーレフト型(LGPL, MPL)→改変した部分のみ公開必須。
-
非コピーレフト型(BSD, Apache License)→改変した部分も公開の必要なし。
Lesson6: Webアプリケーションを効率よく開発するための仕組み
リダイレクトとフォワードの違い
リダイレクトは、サーバーからクライアントにステータス302を返すことで遷移先のURLを伝え、クライアントからサーバーに改めてHTTPリクエストを発行している。
一方で、フォワードはアプリケーションサーバー内で遷移処理が行われる。処理結果に応じて異なるJSPを表示する場合にフォワードを利用することが推奨されている。
リクエストスコープとセッション
読み込みのみが可能なリクエストパラメータ(文字列のみ)とは異なり、リクエストスコープはアプリケーションサーバー(JSPやサーブレット)が読み書き(文字列のみ)可能である。
画面遷移における情報のやり取りでリクエストスコープを使うことで、セッションを利用したメモリ不足(セッションはタイムアウトされるまで残り続けるため)を防ぐことが可能になる。
したがって、ユーザー情報を保持する際にはセッションが用いられ、ページ遷移の際の情報はリクエストスコープが用いられる。
Webアプリケーションのアーキテクチャ
MVCモデル
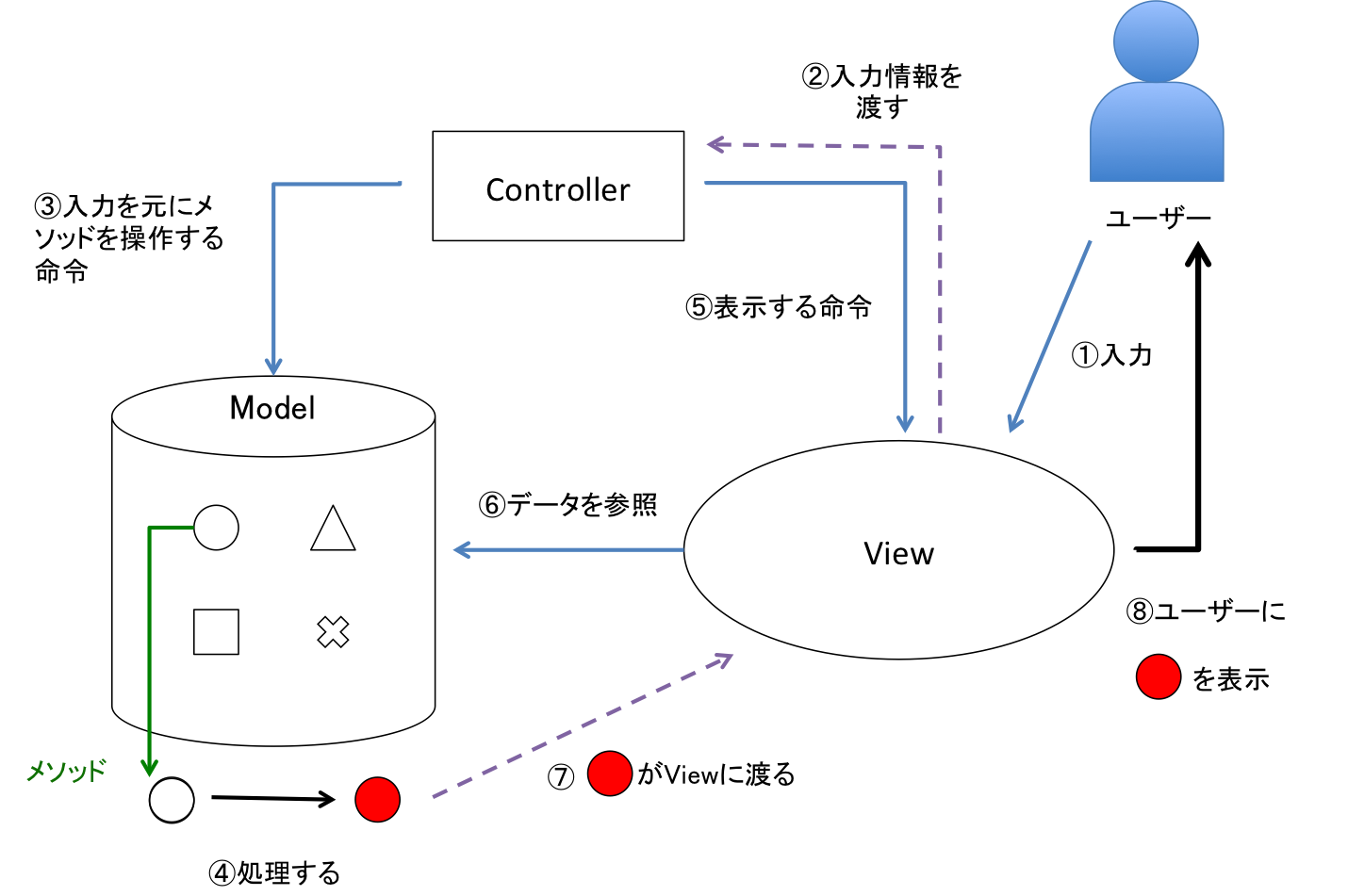
引用: MVCモデルについて
MVCは以上の図のように、アプリケーションを「Model」「View」「Controller」の3つの役割に分けて作るアーキテクチャである。
Model部分は、アプリケーションの処理部分とそれに関する情報の保持を担当する。
Viewはモデルによる処理結果に基づいた画面表示を行う。
Controllerは画面から入力された情報に基づいたModelの呼び出しと、その結果に基づいたViewの呼び出しを担当する。
これにより、ロジックとデザインの分離を実現している。
Layers
Layersパターンはシステムを階層化し、上位レイヤが下位レイヤの提供する機能を利用することで、各レイヤの作りを単純化している。各レイヤはそのレイヤが依存する直接の下位レイヤ以外を知る必要がない。
-
プレゼンテーション層: システム利用者とのインターフェースを担当するレイヤ。ユーザーからの入力を、下位のビジネスロジック層に渡し、その処理結果をWebブラウザへ表示したり、画面遷移を制御したりといったことを担当する。
-
ビジネスロジック層: アプリケーションが実現すべき固有の処理を実行するためのレイヤ。
-
データアクセス層: ビジネスロジック層とデータベースの仲立ちを行うためのレイヤ。データベースへの細かなアクセス手順を意識せずとの利用できるようにすることが目的。
O/R マッピングフレームワーク
Relational database と Objectのインピーダンスミスマッチを解決するために利用されるフレームワーク。データベースから情報を取得し、JAVAのオブジェクトに組み立て直すというコードを書く必要がなくなる。インターフェースを利用することで、変更時の処理を簡単にする。
Lesson7: セキュリティを確保するための仕組み
代表的な攻撃手法
SQLインジェクション
Webフォームを通じて、開発者が意図しないSQLを発行し、データベースから情報を取得する攻撃手法。入力値のチェックやPrepared statementを利用することで防ぐことができる。
XSS
埋め込んだスクリプトをJSに実行させることでCookieの盗難やページの改ざんをする手法。XSSに脆弱なサイトは踏み台にされることがある。サニタイジングにより対策が可能。
セッションハイジャック
セッションを盗み取ることで、他人になりすましてアクセスする攻撃手法。XSS対策、通信経路の暗号化(SSL)、セッションタイムアウト値の変更、セッションIDのランダム化によって対策することができる。
CSRF
攻撃者が捏造したフォームから強制的に情報をサブミットすることで、意図しない書き込みや購入をさせられる。ワンタイムトークンをhiddenパラメーターに埋め込むことで対策することができる。
強制ブラウズ
URLにファイル名を入力することで意図しないページを表示させる手法。
ディレクトリトラバーサル
リクエスト上のパラメーターを使って意図しないページを表示させる手法。
設計や実装ミスに起因する誤作動やセキュリティ問題の原因と対策
戻るボタン対策
- ブラウザによるキャッシュの無効化: HTTPレスポンスのヘッダに情報を追加する
Cache-Control: no-store, no-cache, must-revalidate
-
戻るボタンの無効化
-
ワンタイムトークンの利用
ダブルサブミット対策
- JSによる対策
var isSubmitted = false;
function checkSubmit() {
if (isSubmitted) {
return false;
} else {
isSubmitted = true;
return true;
}
}
- ワンタイムトークンによる対策
グローバル変数に情報を持たせない
スレッドにより、グローバル変数の情報が上書きされる可能性があるため。
おわりに
以上が「プロになるためのWeb技術入門 ~ なぜ,あなたはWebシステムを開発できないのか ~」のまとめになります。Webの基礎を勉強したい方にとって役に立つことができたのなら幸いです。