初めに
本記事では、11/14(金)に開催されたKDH CUP 3rdという競技プログラミングのコンテストの感想及び問題解説を記載しています。
競技プログラミングの宣伝及びKDH CUP参加者を増やすことを目的として記事にしました。
といっても、ほぼ問題解説になってしまいましたが...
問題とその(勝手な)解説を後述していますので、競技プログラミングがどのようなものなのかを感じていただき、興味を持っていただければ幸いです。
競技プログラミングとは
超簡単にいうと「データ構造とアルゴリズムを活用し、問題の制約・処理時間上限を満たしつつ適切な解を作成できるコードを実装する速度」を競うものです。
詳細については、以下に引用させていただいた素晴らしい説明記事を参照していただければと思います。
楽しみ方は人それぞれですが、私は「データ構造とアルゴリズムを活用」という考えるパートをパズル的に楽しんでいます。
謎解きやパズルが好きで、プログラミングにも興味がある方はきっとハマるのではないかと思っています。
このような楽しみ方以外にも、ぜひ自分の楽しみ方を見つけていただければと思います。
KDH CUPとは
対面とオンラインのハイブリッドで開催されるプログラミング大会です。
参加対象はKDDI/KDHグループ会社の全社員(社員・派遣社員)となります。
対面での開催を行なっており、大会終了後には懇親会も開催されます(参加できませんでしたが...)。
また、優秀な成績を収めた場合には賞品も用意していただいております。
実際に私は、商品としてボドゲをいただきましたし、他の方はタンブラーやモバイルバッテリーなどを授与されていました。
問題の難易度としては、初心者も中級者も楽しめる内容になっていると思います。
Atcoderで言うと、A~D問題までは灰~緑色ほどで、E問題は水色の難易度くらいに感じました。
懇親会で他の参加者と交流したいと言う方から、初めてだからオンラインでこそっと参加したいと言う方まで是非是非次回は参加していただき、大会を一緒に盛り上げていければ幸いです。
勝手に問題解説
ここからは、KDH CUP 3rdに実際に出題された問題の解説をします。
どのような問題が出題されるかや、問題の解き方などを感じていただけると幸いです。
(公式回答ではないので、もしかしたら正しくない部分もあると思いますが目を瞑っていただければと...)
問題A
問題文
KDHとは、KDDI Digital Divergence Holdingsの略称です。 KDHは、KDDIの中でも特にDX(デジタルトランスフォーメーション)に力を注ぎ推進しています。
この問題では、「KDH」のように、元の文字列から一部の文字を抜き出して作られる文字列を「略語」と呼びます。 与えられた英文字列について、そのうちの大文字を抜き出すことで略語を求めてください。
例えば、入力がKddiDigitaldivergenceHoldingsの場合、このうち大文字である KDH を順に抜き出したKDHが求める略語となります。
入力
N
S1
S2
...
SN
制約
Nは、与えられる文字列の数を表す、1以上100以下の整数である。
続くN行は、それぞれ略語を求めるべき文字列であり、以下の条件を満たす。
- 各文字列の長さは1以上100以下である。
- 各文字列は英大文字と英小文字のみからなる。
- 各文字列には少なくとも1つの英大文字が含まれる。
解説
問題Aらしく非常に単純な問題です。
Atcoder Beginner Contestなど難易度順に問題が並べられたコンテストでは、問題Aは問題文の通りに実装を行えば適切な解が得られるようになっています。
今回だと、与えられた文字列の中で大文字をもとの出現順序を保って抜き出せばOKです。
解答コード
N = int(input())
S = [input() for _ in range(N)]
for i in range(N):
for s in S[i]:
if ord(s) <= ord("Z"):
print(s, end="")
print()
ord()は文字のUnicodeコードポイントを取得する関数であり、アルファベットがUnicodeで連番になっていることを利用して大文字判定をしています。
問題B
問題文
とあるグループ会社で、大規模なオフィスの引っ越しが計画されています。
このグループには N 個の企業があり、移転先候補として M 個のオフィス(オフィス 1, オフィス 2, ..., オフィス M)があります。
現在、企業 i (1 ≤ i ≤ N) はオフィス Si に入居しており、移転計画書でオフィス Diへの移転が計画されています。
移転は、企業 1, 企業 2, ..., 企業 Nの番号順に、1社ずつ順番に行うことが計画されています。
ただし、複数の企業が同じオフィス内に在籍してしまうと混乱して仕事をできなくなってしまうのでこれは避けたいです。
与えられた移転計画通りに移転を実行した際、同時に2つの企業が同じオフィスに在籍することがなく移転を完了できるか判断してください。移転のルールは以下の通りです:
- 1つのオフィスには、いかなる時点でも1つの企業しか存在できません
- 企業 i が移転する際、その移転先であるオフィス Di に他のいずれかの企業が既に入居している場合、移転は「衝突」とみなされ、計画は失敗となります
- Si = Diとなりうることに注意してください
- 企業 i がオフィス Si から正常に移転を完了すると、オフィス Si は空きオフィスとなり、他の企業が後からそこへ移転できるようになります
すべての企業が衝突を起こすことなく移転を完了できるか判定してください。
制約
1 ≤ N ≤ M ≤ 100
1 ≤ Si, Di ≤ M
i ≠ j ならば Si ≠ Sj (すべての企業は異なるオフィスから開始する)
入力はすべて整数である。
入力
N M
S1 D1
S2 D2
...
SN DN
解説
問題Aと比べると問題文が長くなり、問題文をそのまま実装しても正解は得ることができません。
どうやって、「企業が衝突する」が判定できるかを考える必要があります。
問題文より、「企業が衝突する」とは企業iがオフィスSiからDiに移転しようとした時、オフィスDiがすでに入居している場合とわかります。
つまり、企業iが移転する直前にすでに入居されているオフィスのリストを保持し、Diがそのリストに含まれているかを確認することで、衝突が起こるかを判定することができます。
解答コード
N, M = map(int, input().split())
S = [0 for _ in range(N)]
D = [0 for _ in range(N)]
now = set() # 現在入居済みのオフィスのリスト
ans = "YES"
for i in range(N):
S[i], D[i] = map(int, input().split())
now.add(S[i])
for i in range(N):
s, d = S[i], D[i]
now -= {s}
# オフィスDiが入居済みリストに含まれているか確認
if d in now:
ans = "NO"
now.add(d)
print(ans)
あるリストに指定の要素が含まれているかを確認するには、セット(集合、Pythonのset型)というデータ構造がよく用いられます。
セットでは、要素がその集合に含まれているかをおおよそO(1)で判定できます。
一方で、リスト(配列、Pythonのlist型)と呼ばれるデータ構造を用いて要素が含まれているか判定を行うと、O(N)かかってしまいます。
ここで、Nはそのリストの要素数です。
今回の問題では、制約が緩くリストを用いても問題ないですが、制約によってはリストでは処理時間超過してしまうこともあるので、注意が必要です。
参考:Pythonistaなら知っておきたい計算量のはなし
問題C
問題文
Aさんが引っ越しを考えています。Aさんがよく通う駅が1からnまで番号付けされています。 Aさんはこれら全ての駅にアクセスしやすい場所に住みたいと考えています。
駅間の直通関係が ui, vi (1 ≤ i ≤ n - 1)で与えられます。 入力に ui、 vi が含まれるとき、駅 ui と駅 vi が直通で結ばれていることを表します。
他のすべての駅と乗り換えなしで直通している駅を中心駅と呼びます。 駅1から駅nの中に中心駅が存在するならば、その中心駅の番号を返してください。そうでなければ -1 を返してください。
入力
n
u1 v1
u2 v2
...
un-1 vn-1
制約
nは、駅の数を表す、3以上1000以下の整数である。
続く n-1 行は、それぞれ駅間の直通関係を表し、以下の条件を満たす。
- 各 ui、vi は整数
- 1 ≤ ui, vi ≤ n
- ui ≠ vi
- uiとviのペアは一意である。 すなわち、 i ≠ j ならば (ui, vi) ≠ (uj, vj) かつ (ui, vi) ≠ (vj, uj) である。
解説
グラフ理論の用語を用いて説明します。(詳しくはグラフ理論を参照してください)
まずは、入力および制約を整理します。
「ui ≠ vi」という制約から自己ループはなく、「uiとviのペアは一意である」という制約から多重辺もないということがわかります。
次に、中心駅の判定条件について考えます。
問題文より、中心駅は「他のすべての駅と乗り換えなしで直通している」という定義です。
そして、制約より自己ループ・多重辺がないことから、定義を「中心駅は辺がn-1個ある」と言い換えることができます。
従って、中心駅の存在判定は、各駅の辺数を数えておき、最終的に辺数がn-1の駅が存在するかを判定すれば良いです。
解答コード
N = int(input())
# 各駅の辺数を格納する配列
edge_count = [0]*1010
for i in range(N-1):
u, v= map(int,input().split())
# 各駅の辺数をカウント
edge_count[u] += 1
edge_count[v] += 1
if max(edge_count) == N-1:
print(edge_count.index(max(edge_count)))
else:
print(-1)
問題D
問題文
※この問題は、E問題と入力の制約だけが異なります。先にE問題を読まれた場合は、入出力のセクションのみご確認ください。
N人のプレイヤーが円環上に座っています。 以下ではプレイヤー1、プレイヤー2、…、プレイヤーNが順に時計回りに配置されているものとします。
各プレイヤーはそれぞれ A、B、...、Z の文字が書かれたカードを何枚か持っています。
このプレイヤーを隣り合ったプレイヤーどうしのグループに分割し、以下の目標を達成することを考えます。
目標
- グループ内のプレイヤーが持つカードを全てまとめる。グループ内の全てのカードを、同じ種類のカード2枚ずつの組にすることができる
適切にグループ分けをすることで目標を達成できるか判定し、可能な場合は最大でいくつのグループで目標を達成できるか求めてください。
ここで、グループの分割は以下の条件を満たす必要があります。
- 各プレイヤーはちょうど1つのグループに所属する。
- 各グループは隣り合ったプレイヤーのみで構成される (プレイヤー番号の差の絶対値が1であるプレイヤーどうし、およびプレイヤー1とプレイヤーNが隣り合っているとみなされる)。
- グループは1人以上のプレイヤーで構成される。
入力
N
h1
h2
...
hN
制約
Nは、プレイヤーの数を表す、1以上100以下の整数である。
続く hi は、プレイヤーi が持っているカードを表す文字列であり、以下の条件を満たす。
- 各文字列の長さは1以上50以下である。
- 各文字列は英大文字のみからなる。
解説
問題を整理します。
求める値は「適切にグループ分けをすることで目標を達成できるか判定し、可能な場合は最大でいくつのグループで目標を達成できるか」です。
まず、「目標を達成できるか」の判定方法について考えましょう。
目標とは、「グループ内の全てのカードを、同じ種類のカード2枚ずつの組にすることができる」と定義されています。
言い換えると、「グループ内のカードを合わせた時、全種類のカードが偶数枚」であれば良いです。
従って、グループ内のカードの枚数を種類ごとに足し合わせ、全種類が偶数枚となっているかを確かめれば良いです。
次に、グループの分割方法について考えましょう。
条件より、グループは隣り合ったプレイヤーから構成されています。
従って、プレーヤーiから始めたとすると、プレーヤーi、プレーヤーi+1、...、と各プレーヤーの持つカードを順に加算していき、加算ごとにカード枚数が偶数であるかを判定します。
こうすることで、目標達成していると判定できた場合、そのプレーヤーまでを1つのグループとしてまとめられます。
そして、次のプレーヤーから新たなグループとしてカード枚数を数えていき、最後のプレーヤー分を加算した時に目標を達成できれば適切にグループ分けできたと判定できます。
解答コード
N = int(input())
# 各プレーヤーの種類ごとのカード枚数を保持するリスト
card = [[0 for _ in range(26)] for _ in range(N)]
# アルファベットを0~25に変換する
alp2num = lambda s: ord(s) - ord("A")
# 全種類のカード枚数が偶数枚かを判定する
def check(A):
for i in range(26):
if A[i] % 2 == 1:
return False
return True
for i in range(N):
S = input()
for s in S:
card[i][alp2num(s)] += 1
Ans = -1
for i in range(N):
ans = 0
card_sum = [0 for _ in range(26)]
for j in range(N):
for k in range(26):
card_sum[k] += card[(i + j)%N][k]
if check(card_sum):
ans += 1
# 最後のプレーヤー分を加算後に目標を達成できているかを確認
if check(card_sum):
Ans = max(Ans, ans)
print(Ans)
問題E
問題文
問題Dと同じです。
入力
問題Dと同じです。
制約
Nは、プレイヤーの数を表す、1以上100,000以下の整数である。
続く hi は、プレイヤーi が持っているカードを表す文字列であり、以下の条件を満たす。
- 各文字列の長さは1以上50以下である。
- 各文字列は英大文字のみからなる。
解説
問題Eは問題Dと制約を除き全く同じ問題ですので、問題Dで考えた解法が適用できるか考えてみます。
解法の計算量はO(QN2)でした。
制約を見ると、Nの最大値は100,000であり、問題Dの解法だと最悪の場合1010ほどの処理が必要となってしまい、1処理時間超過してしまいます。
よって、この解法は適用できず、もっと効率的な解法を考える必要があります。
効率化①
まず、あるグループ内で目標が達成できているかの判定を効率的にできないかを考えます。
結論から述べると、問題DではO(Q)かかっていましたが、O(1)まで効率化できます。
偶数判定について簡略化できないかを考えます。
偶数であるかどうかは、数の1桁目が偶数であるかと同等であり、さらにいうと数を2二進数表記した際の1bit目が0であるかどうかと同等です。

従って、枚数を保持するのではなく、偶数なら0、奇数ならば1という状態を保持するだけで良くなります。
これは、初め0枚からスタートし、カードが1枚増えるごとに現状態と1の排他的論理和を計算することで次状態を求められます。
次に、全カード種類での偶数判定について考えます。
問題Dではカードの種類ごとに枚数を保持していたためカードの種類数Qだけ計算が必要でした。
しかし、今では各カード種類において0か1かの状態のみを保持しておけば良いです。
ここで、カード種類iをiビット目の値と考えることで、高々Qビットの値で各種類の枚数の偶奇を保持することができます。
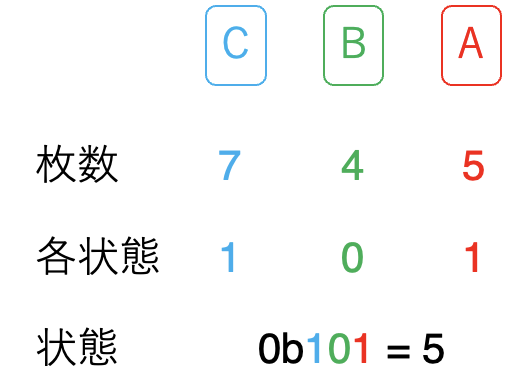
例えば、カードAとカードCが奇数枚、その他は偶数枚の時は0b101 = 5 という数値で偶奇状況を判定できます。
また、カードBを1枚増やす場合は 0b101 XOR 0b10 = 0b111 = 7と計算できます。
以上より、すべてのカード種類で枚数が偶数であるかは、偶奇状況を表す数の各bitが0であるか、つまり全カードの偶奇状況を表す数が0であるかを判定するだけでよくなり、これはO(1)です。
効率化②
次に、グループ分けの探索を効率的にできないかを考えます。
問題Dでは、グループの一人目を全探索し、さらにそのグループの最後のプレーヤーを全探索するO(N2)のアルゴリズムとなっていました。
まずは、グループの初めのプレーヤーは固定として、最後のプレーヤーを効率的に見つける方法を考えましょう。
問題Dでは、探索の度にカードの累積の計算を行い、状態の判定を行なっていました。
最後のプレーヤーを効率的に見つけるためには、毎回累積計算をするわけにはいきません。
実は、3累積和を用いることでこの累積の計算を一度だけ行うだけで済ませることができます。
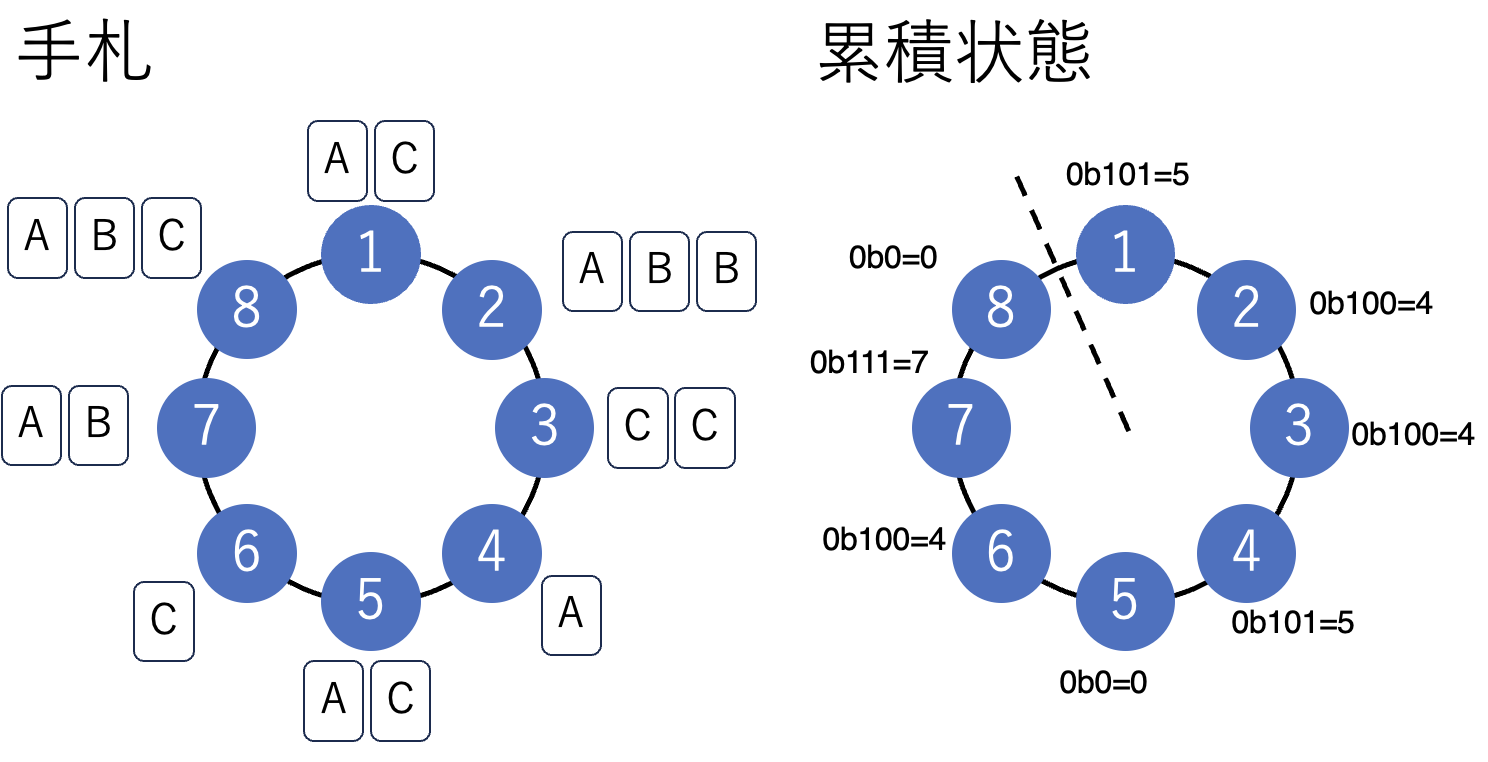
例えば、左図のように各プレーヤーにカードが配られているとします。
このとき、プレーヤー1を一人目とした4累積状態は右図のように計算できます。
プレーヤー1~プレーヤーiまでの累積状態がcumsum[i]というリストに格納されているとします。
そうすると、プレーヤーi~プレーヤーj(i $\leq$ j)の累積状態は cumsum[j] XOR cumsum[i-1]と5表せ、これはO(1)で計算できます。
例えばプレーヤー2~プレーヤー5までの累積状態はcumsum[5] XOR cumsum[1] = 0b10 XOR 0b101 = 0b111 = 5と計算できます。
またプレーヤーNを跨ぐ場合、つまりプレーヤーi~プレーヤーN、プレーヤー1~プレーヤーj(i $\geq$ j)の累積状態は (cumsum[N] XOR cumsum[i-1]) XOR cumsum[j]と表せます。
ここで、6cumsum[N] = 0の場合のみ考えれば良いため、結局はcumsum[j] XOR cumsum[i-1]が累積状態になります。
ここで、プレーヤー1~プレーヤーjが目的を達成するグループであるとは累積状態が0となる、つまりcumsum[j] XOR cumsum[i-1] = 0となれば良いです。
さらに、同じ数同士の排他的論理和は必ず0となることを利用することで、cumsum[j] = cumsum[i-1]を満たせば良いということがわかります。
つまり、プレーヤーiから始まったグループが目的を満たすには、cumsum[i-1]と同じ値を持つcumsum[j]を見つければ良いです。
例えば、プレーヤー1を一人目とする場合は、累積状態がcumsum[0] = 0となるプレーヤーの数を数えることでグループ分けを最適に行うことができます。
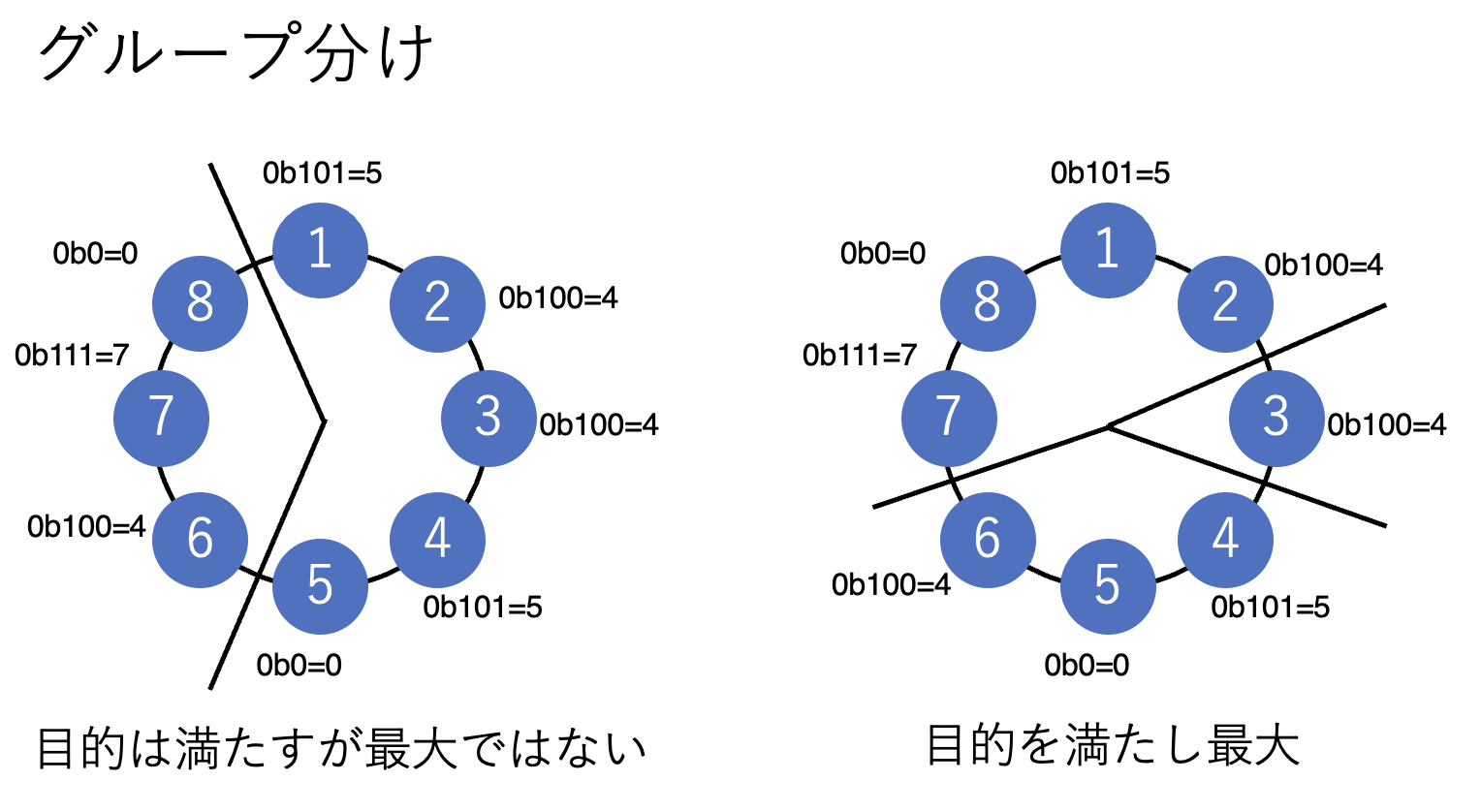
プレーヤー1からグループを始めた場合は、左図のようにプレーヤー1~5、及びプレイヤー6~8のグループに分けることが最適です。
しかし、これは正解ではありません。
正解は、右図のように、プレーヤー3、プレーヤー4~6、及びプレイヤー1、7~8の3グループに分ける方法です。
このような分け方を発見するには、グループの一人目を全探索する必要があるように思えます。
ただし、グループ一人目を全探索して毎回累積和を計算していては結局O(N2)となってしまいます。
そこで、プレーヤー1を一人目として計算した累積状態を用いて、効率的にプレーヤーiを一人目とした累積状態を計算できないかを考えると、実は容易に計算することができます。
排他的論理和の特性より、プレーヤーiを一人目とした場合の累積状態は、プレーヤー1を一人目として計算した累積状態とcumsum[i-1]の排他的論理和を計算することで求めることができます。
従って、プレーヤーiを一人目とした場合のグループ分けはcumsum[k] XOR cumsum[i-1] = 0を満たすkの個数を数え上げることで求めることができます。
さらに、cumsum[k] XOR cumsum[i-1] = 0はcumsum[k] = cumsum[i-1]と変換することができます。
これは、同じ値となる累積状態の個数を求めることで同等です。
つまり、目的を満たすグループ分けの最大個数を求めることは、累積状態の最頻値の出現回数を求めることと同等であるとわかりました。
従って、O(N)まで効率化できました。
解答コード
from collections import defaultdict
N = int(input())
# 大文字アルファベットを0~26に変換
alp2num = lambda s : ord(s) - ord("A")
# 状態の累積値: state_cumsum[i]はプレーヤー1~プレーヤーiまでのカードを加えた状態
state_cumsum = [0 for _ in range(N + 1)]
for i in range(N):
h = input()
state = 0
for s in h:
# カードのアルファベット順と状態の二進数における桁が対応
# カードが1枚増えるごとに、状態と1の排他的論理和を計算する
state ^= 1 << alp2num(s)
state_cumsum[i + 1] = state_cumsum[i] ^ state
# 全プレーヤーのカードを用いて目的達成できない場合は解なし
if state_cumsum[N] != 0:
print(-1)
else:
# 最頻値の出現回数を数える
state_number = defaultdict(int)
for state in state_cumsum[1:]:
state_number[state] += 1
print(max(state_number.values()))
最後に感想を
今回初めて、競技プログラミングの解説を行いましたが、なかなかに説明を行うのは難しかったです。
図や数式などを用いて、端的に説明ができる方は本当にすごいのだなあと感じました。
とはいえ、今回を説明を記述するにあたり、普段はスキップして考えている部分を順を追って細かく考えましたが、非常に良い勉強になったと感じました。
次回のKDH CUPに向けてゆるりと精進していきます。
皆様も、ぜひ次回の大会に参加していただければと思います。
-
一般的に2秒の処理時間にできる最大は108ほどと言われています ↩
-
発想の飛躍に思えますが、bit表現に変換するのはよくある考え方で、閃きというよりかは慣れです。また、排他的論理和の累積値は、累積に加える場合も除く場合も単に排他的論理和を計算すればよくとても相性が良いと思います。 ↩
-
累積和を何も考えずに書けるようにする!や累積和とは(超初心者用)を参考にしてください。 ↩
-
状態を排他的論理和で累積していくため、今回は累積和を累積状態と呼ぶこととします。 ↩
-
排他的論理和で計算しているのは今回の問題特有であり、数値の加算の累積和の場合は
cumsum[j] - cumsum[i-1]のように差を計算することに注意してください。 ↩ -
cumsum[N] = 0は全プレーヤーのカードを累積した時目的を達成できるということを表します。一方で0でない時、これはどのようなグループ分けをしても目的を達成できません。 ↩