OpenAI「gpt-oss-20b」導入手順と活用評価まとめ【ローカル実行OK】
**2025年8月に公開されたオープンウェイトLLM「gpt-oss-20b」**について、
導入手順・システム要件・実践評価をまとめます。
ローカルPCでも動作可能で、Apache 2.0ライセンスなので商用利用OK。
✅ gpt-oss-20bとは?
- OpenAI初のオープンウェイトLLM
- パラメータ数:20.91B(実アクティブ 3.61B)
- 131,072トークンの超長文対応(小説1冊分)
- Apache 2.0ライセンス(商用利用OK)
- MoE構造+MXFP4量子化で効率的推論
- モデルサイズ:約12.8 GiB
ポイント:16GBメモリのPCでもローカル実行OK
✅ 主要特徴
| 項目 | 内容 |
|---|---|
| パラメータ数 | 20.91B(実動3.61B) |
| コンテキスト長 | 131,072トークン |
| 量子化方式 | MXFP4(約4.25bit) |
| 必要メモリ | 16GB以上 |
| ライセンス | Apache 2.0 |
✅ システム要件
- メモリ:16GB以上(推奨24GB)
- ストレージ:SSD(モデルサイズ12.8GiB)
-
GPU:RTX 3090 / 4080 / 4090推奨
※Apple Silicon (M2 Pro以上) でも動作確認済み
✅ 導入方法(4パターン)
① LM Studio(GUIで簡単)
- LM Studio公式 からインストール
- アプリ内で「gpt-oss-20b」をダウンロード(約12GB)
- チャット開始(推論設定 Low/Medium/High)
② Ollama(CLIで柔軟)
OllamaはMac / Windows / Linux対応のCLIベースLLM実行環境です。
APIサーバーとしても利用可能で、LangChainや外部アプリとの連携も簡単。
インストール方法
-
Mac(Homebrew)
bash
brew install ollama -
Windows / Linux
公式サイト からインストーラをダウンロードしてインストール。
モデルの取得と実行
モデルダウンロード
ollama pull gpt-oss:20b
モデル実行
ollama run gpt-oss:20b
APIサーバー起動
デフォルトで http://localhost:11434 にREST APIが有効。
curl http://localhost:11434/api/generate -d '{"model":"gpt-oss:20b","prompt":"こんにちは"}'
⸻
③ Python + Transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "openai/gpt-oss-20b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "日本語で自己紹介してください。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=120)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
⸻
④ クラウドAPI
• Groq API:高速推論($0.10 / $0.50 per 1M tokens)
• Together AI:柔軟なOSSモデル対応($0.05 / $0.20 per 1M tokens)
⸻
✅ ベンチマーク結果

⸻
✅ 実践評価(コード生成タスク)
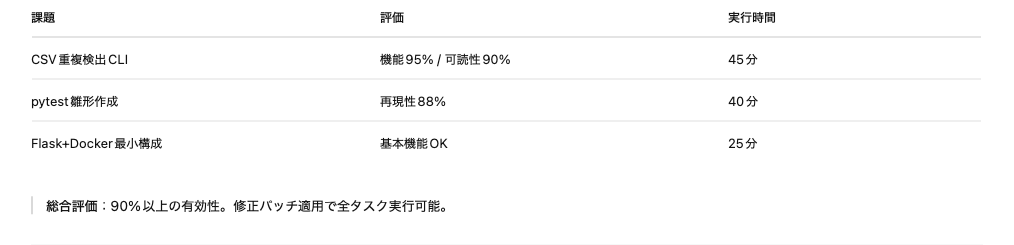
⸻
✅ 活用シーン
• 社内チャットボット(オフライン対応)
• RAGシステム(文書検索・FAQ)
• コード生成・テスト自動化
• 医療・ヘルスケア(オンプレ処理)
• 多言語コンテンツ生成
⸻
✅ まとめ
• 商用利用OKのLLMが、16GBメモリのPCで動く時代に
• 導入はGUI・CLI・Python・クラウドAPIの4パターン
• コード生成や業務自動化で高い実用性を確認
⸻
🔗 参考
• LM Studio公式
• Ollama公式
• HuggingFace Transformers