
はじめに
長いプロジェクトをやってると、「あれ、この実装の経緯ってどうだっけ…?」とか「なんでこの仕様になったんだっけ?」みたいに、過去の情報を探すのに結構、苦労しませんか?
そんなとき、「このプロジェクトのことなら何でも知ってるAIアシスタントがいてくれたらな〜!」って思いますよね!
この記事では、そんな夢を叶えるべく、RAG(Retrieval-Augmented Generation)という技術を使って、プロジェクトに関する情報をAIに気軽に聞ける仕組みを作ってみた話をシェアします!
ざっくりRAG検索とは?
まず、「RAG検索」ってそもそも何なの?ってところをサクッと解説!
LLMには、ざっくり言うと2種類の記憶があります。長期記憶の**「学習済みデータ」と、短期記憶の「コンテキスト」**です。
学習済みデータ: モデルが作られるときに叩き込まれた膨大な知識。LLMの基礎体力みたいなものです。
コンテキスト: 今まさに私たちがLLMに話しかけている、会話の文脈のことです。
「プロンプトエンジニアリング」なんて言葉があるように、LLMに賢く答えてもらうには、このコンテキストをどう伝えるかは重要ですよね。
じゃあ、プロジェクトの仕様書とか議事録とか、関連する情報を全部コンテキストに突っ込めば、AIが何でも答えてくれるようになる…?
と思うかもしれないですが、答えはNo!!
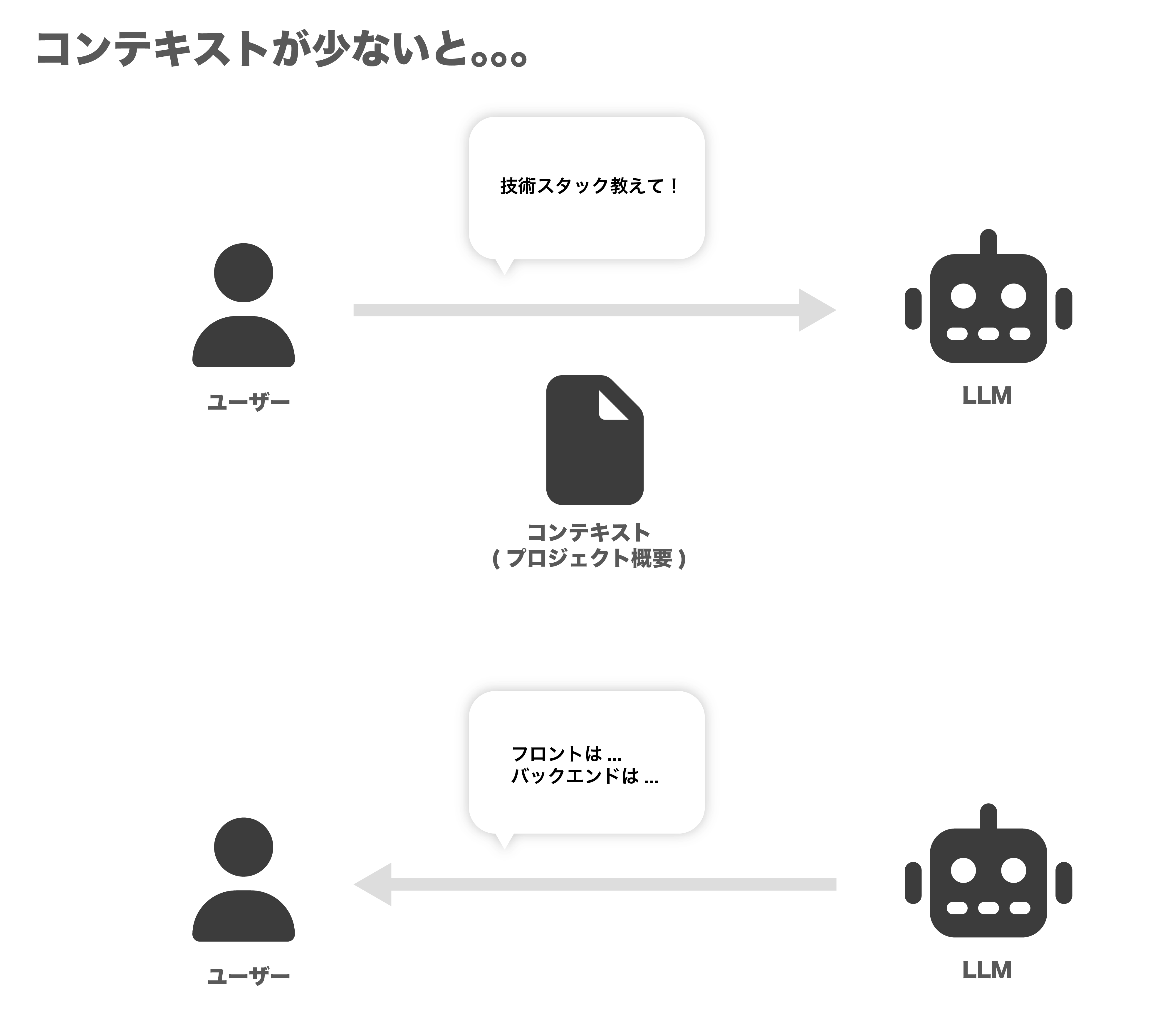
コンテキストが多すぎるとLLMが処理しきれずむしろよくわからない回答が返ってきます。
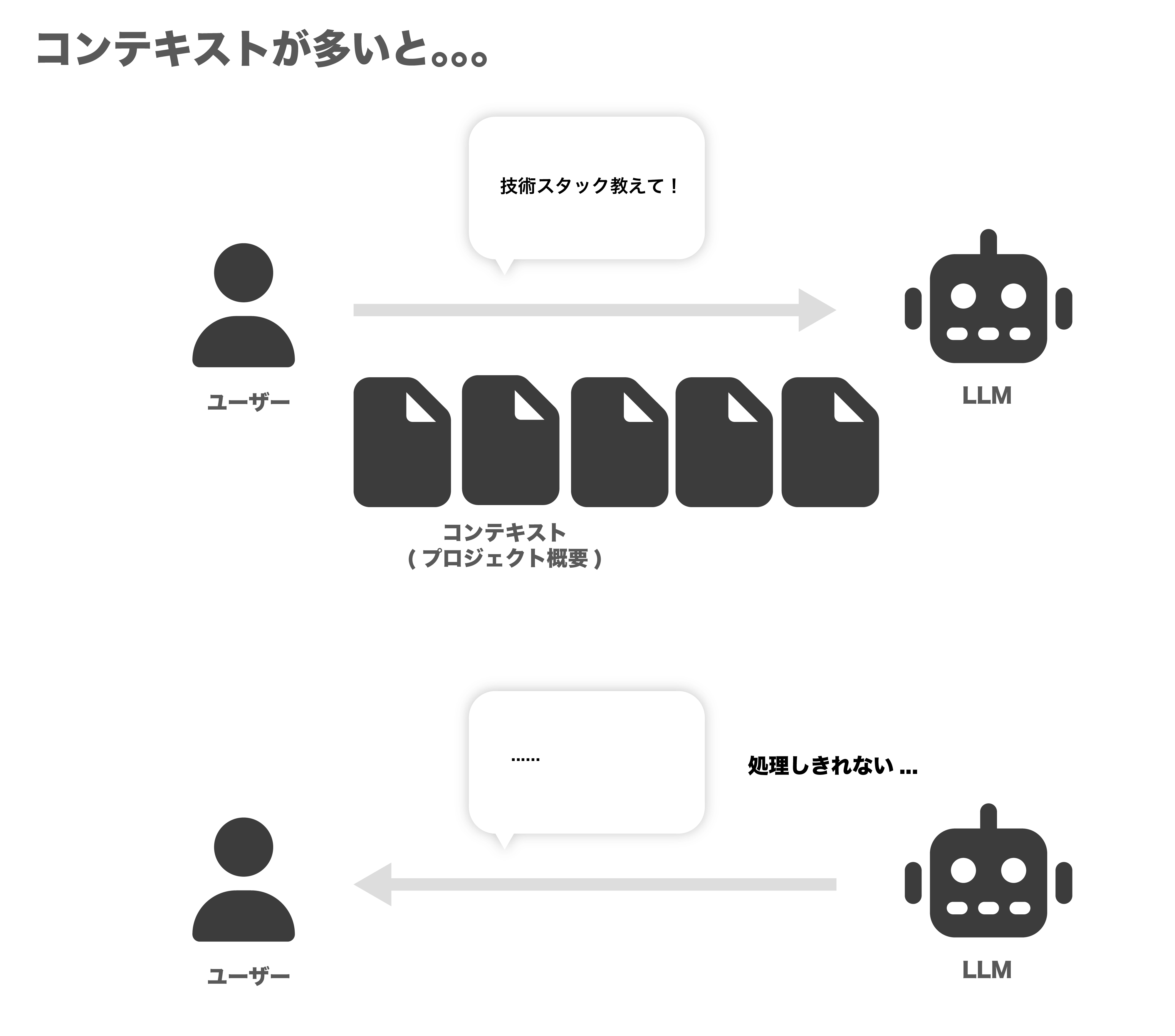
その答えとして出てきたのがRAG検索です。
「膨大なデータの中から、ユーザーの質問に関係ある情報だけをコンテキストとしてLLMに渡せばいいじゃん!」という考え方です。
これなら、LLMも混乱せずに、いつでも的確な情報をもとに答えてくれるってわけですね!
作る内容
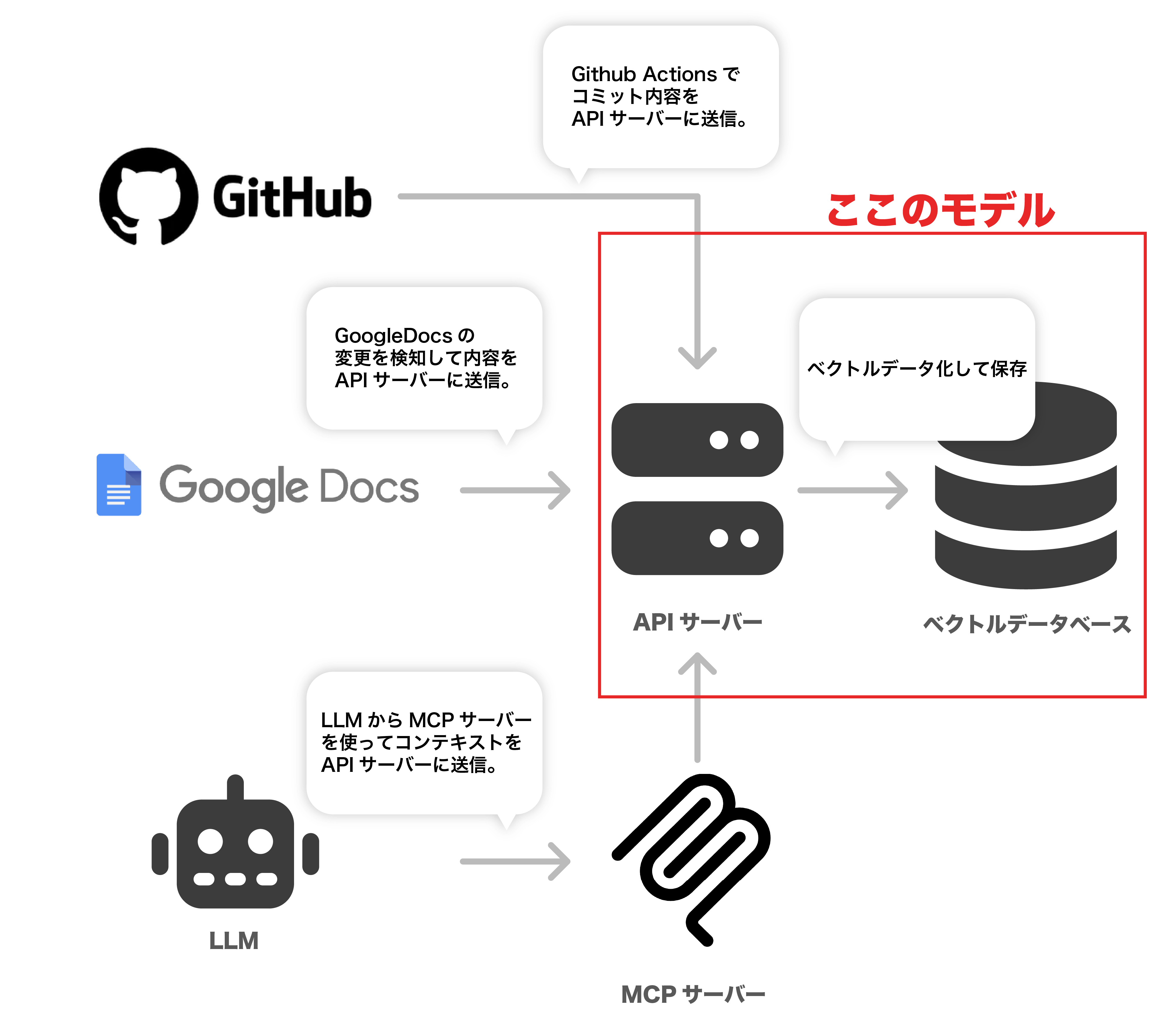
今回作るのはざっくり主にMCPサーバーとAPIサーバーです。
これを中心に、コンテキストを**「参照する仕組み」と「蓄積する仕組み」**を実装しました。
コンテキストを参照する側
ユーザーからの質問は、まずMCPサーバー(LLMに外部ツールを使わせるための便利サーバー)がキャッチします。
MCPサーバーは、質問に応じてAPIサーバーを呼び出し、APIサーバーがベクトルデータベースの中から関連情報を探してきます。
最後に、LLMがその検索結果を分かりやすくまとめて答えてくれる、という流れです。


コンテキストを蓄積する仕組み
プロジェクトの知識は、放っておくと古くなっちゃいます。なので、以下の3つの方法で常に最新の情報がデータベースに貯まっていくようにしました。
-
LLMとの対話から: 「これ、覚えといて!」みたいに、会話の中から直接知識を登録。
-
GitHub Actionsで自動化: mainブランチにマージされたら、その変更内容をAIが自動で要約して保存!
-
Google Docsから: 議事録とかドキュメントが更新されたら、その内容も自動で取り込みます。

具体的な実装
大まかな実装はこんな感じです。
リモートMCPサーバー、APIサーバーにGoogle cloudRUNを
ベクトルDBにsupabaseを使っています。
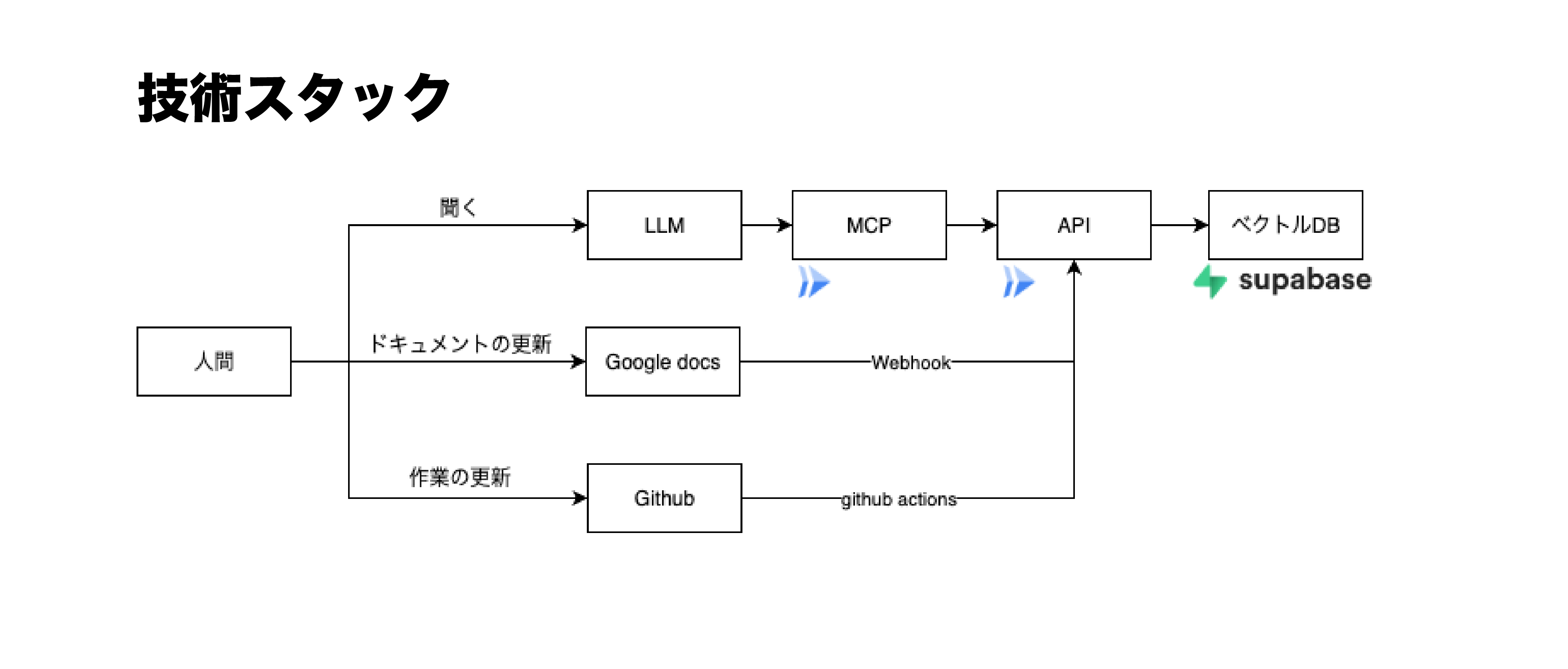
APIサーバー
最初にAPIサーバーを作ります。
このAPIサーバーは主にベクトルデータへの書き込みと、ベクトルデータへの検索を行います。
ベクトルデータはsupabaseを使いました。
github actions用のエンドポイントと、Google docs用のエンドポイントが他にもありますが、今回はシンプルな検索と書き込みのエンドポイントのみを紹介します。
APIサーバーはHonoを使って実装しました。
// 検索用
app.post("/api/query", apiAuthMiddleware, async (c) => {
try {
const { query } = await c.req.json();
if (!query) return c.json({ error: "Query is required" }, 400);
const embeddingModel = genAI.getGenerativeModel({
model: "text-embedding-004",
});
const { embedding } = await embeddingModel.embedContent(query);
const { data, error } = await supabase.rpc("match_documents", {
query_embedding: embedding.values,
match_threshold: 0.5, // 検索がヒットする閾値
match_count: 5, // 検索のヒット数
});
if (error) throw error;
return c.json({ context: data });
} catch (e) {
console.error("/api/query error:", e);
return c.json({ error: (e as Error).message }, 500);
}
});
// 書き込み用
app.post("/api/context/update", apiAuthMiddleware, async (c) => {
try {
const { content, metadata } = await c.req.json();
if (!content) return c.json({ error: "Content is required" }, 400);
const embeddingModel = genAI.getGenerativeModel({
model: "text-embedding-004",
});
const { embedding } = await embeddingModel.embedContent(content);
const { error } = await supabase.from("documents").insert({
content,
embedding: embedding.values,
metadata,
});
if (error) throw error;
return c.json({ success: true });
} catch (e) {
console.error("/api/context/update error:", e);
return c.json({ error: (e as Error).message }, 500);
}
});
ここでのポイントはsupabaseのベクトルデータへの操作と、データをベクトル変換するモデルについてです。
今回は全てのアプリをGCP圏内で実装しているので、geminiのtext-embedding-004というテキストベクトル変換用のモデルに丸投げしてます。
(たぶん調整したほうがいいw)
ベクトルデータへの操作は、閾値と検索数を操作して調整します。今回はちょっとだけ広く0.5で設定してますが、0.7とかの方が多分精度はいい。(ここはやりながら調整)
MCPサーバー
MCPサーバー全体の実装は以下を参考にしてください。
https://qiita.com/jerrywdlee/items/d20de494f47091babf7e
今回実装したツールは以下のようになります。
やってることはAPIサーバーで作ったエンドポイントをLLMが使えるようにしてるだけです。
// 書き込み用ツール
mcpServer.registerTool(
"update_context",
{
title: "コンテキストの直接更新",
description:
"与えられたコンテンツをベクトル化し、データベースに保存します。",
inputSchema: {
content: z.string(),
metadata: z.record(z.unknown()).optional(),
},
},
async ({ content, metadata }) => {
try {
await callInternalApi("/api/context/update", { content, metadata });
return {
content: [
{ type: "text", text: "コンテキストの更新に成功しました。" },
],
};
} catch (e) {
return {
content: [
{ type: "text", text: `エラー: ${(e as Error).message}` },
],
isError: true,
};
}
}
);
// 検索用ツール
mcpServer.registerTool(
"query_context",
{
title: "コンテキスト検索",
description:
"プロジェクト固有の技術仕様、API設計、過去の意思決定に関する情報をベクトル検索します。",
inputSchema: { query: z.string() },
},
async ({ query }) => {
try {
const result = await callInternalApi("/api/query", { query });
return {
content: [
{ type: "text", text: JSON.stringify(result.context, null, 2) },
],
};
} catch (e) {
return {
content: [
{ type: "text", text: `エラー: ${(e as Error).message}` },
],
isError: true,
};
}
}
);
Github Actions
GithubActionsでメインブランチにマージされたタイミングでAIに要約させ、ベクトルデータ化して保存します。

mainブランチにマージされたことを検知してコミットメッセージとdiffをAPIに投げます。
URLやトークンはgithubのシークレットで管理してます。
name: Update AI Context with Summary
on:
push:
branches:
- main # mainブランチにプッシュされた時のみ実行
jobs:
update-context:
runs-on: ubuntu-latest
steps:
# Step 1: リポジトリのコードをチェックアウト
# 直前のコミットとの差分を取得するために fetch-depth: 2 が必要
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 2
# Step 2: 最新のコミットメッセージを取得
- name: Get commit message
id: commit_message
run: echo "message=$(git log -1 --pretty=%B)" >> $GITHUB_OUTPUT
# Step 3: コードの差分を取得 (git diff)
# 複数行になる差分を正しく扱うための処理
- name: Get code diff
id: diff
run: |
diff_content=$(git diff HEAD~1 HEAD)
echo "diff_content<<EOF" >> $GITHUB_OUTPUT
echo "$diff_content" >> $GITHUB_OUTPUT
echo "EOF" >> $GITHUB_OUTPUT
# Step 4: 新しい差分要約APIを呼び出す
# 環境変数を経由してjqに渡すことで、特殊文字や改行の問題を回避する
- name: Call Summarize and Update API
env:
COMMIT_MESSAGE: ${{ steps.commit_message.outputs.message }}
GIT_DIFF: ${{ steps.diff.outputs.diff_content }}
SUMMARIZE_API_URL: ${{ secrets.SUMMARIZE_API_URL }}
API_KEY: ${{ secrets.API_KEY }}
run: |
JSON_PAYLOAD=$(jq -n \
--arg commitMessage "$COMMIT_MESSAGE" \
--arg diff "$GIT_DIFF" \
--argjson metadata "$(jq -n \
--arg source "github_commit_summary" \
--arg repository "${{ github.repository }}" \
--arg commit_hash "${{ github.sha }}")" \
'{commitMessage: $commitMessage, diff: $diff, metadata: $metadata}')
curl -X POST "$SUMMARIZE_API_URL" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d "$JSON_PAYLOAD"
apiサーバーの設定は以下のようになってます。
geminiAPIのflashで要約→text-embedding-004でベクトル化して保存しています。
プロンプトはとりあえずGeminiさんに出してもらったそれっぽいものでようやくしてもらっています。
app.post(
"/api/context/summarize-and-update",
apiAuthMiddleware,
async (c) => {
try {
const { commitMessage, diff, metadata } = await c.req.json();
if (!commitMessage || !diff)
return c.json({ error: "Commit message and diff are required" }, 400);
const model = genAI.getGenerativeModel({ model: "gemini-1.5-flash" });
// コミット要約プロンプト
const prompt = `あなたはシニアソフトウェアエンジニアとして、以下のGitコミット情報を分析し、他の開発者が後から参照しやすいように、指定されたJSON形式で変更内容を詳細に要約してください。
# 指示
- この変更が「なぜ(Why)」必要で、「何を(What)」したのかを明確にしてください。
- 技術的な観点から、変更点を具体的に記述してください。
- コード差分を注意深く読み取り、コミットメッセージだけでは分からない実装の詳細も要約に含めてください。
# 入力情報
## コミットメッセージ:
${commitMessage}
## コード差分:
\`\`\`diff
${diff}
\`\`\`
# 出力形式(JSON)
以下のキーを持つJSONオブジェクトとして出力してください。
{
"summary": "この変更の概要を1〜2文で記述",
"background": "この変更が必要となった背景、目的、解決しようとした課題",
"technical_details": [
{
"change_point": "具体的な変更点1(例: 認証APIの追加)",
"description": "その変更内容の詳細(例: /api/auth/loginにJWT認証を導入)"
},
{
"change_point": "具体的な変更点2(例: データベーススキーマの更新)",
"description": "その変更内容の詳細(例: usersテーブルにlast_loginカラムを追加)"
}
],
"impact": "この変更が他の機能や開発者に与える影響、注意点など"
}`;
const result = await model.generateContent(prompt);
const summary = result.response.text();
const embeddingModel = genAI.getGenerativeModel({
model: "text-embedding-004",
});
const { embedding } = await embeddingModel.embedContent(summary);
const { error } = await supabase.from("documents").insert({
content: summary,
embedding: embedding.values,
metadata,
});
if (error) throw error;
return c.json({ success: true, summary });
} catch (e) {
console.error("/api/context/summarize-and-update error:", e);
return c.json({ error: (e as Error).message }, 500);
}
}
);
動いてる様子
今回はみんな大好きGemini CLIくんに手伝ってもらいます。
あらかじめGemini CLIくんにリモートで作ったMCPサーバーを認識させておきます。
Gemini CLIでのMCPサーバーの登録方法

プロジェクトのことを説明してもらいましょう。

LLMがこのツールを使ってもいいか許可を求めてきます(ちょっと可愛い)

許可をするとLLMがAPIサーバーにqueryを勝手に投げてくれます。
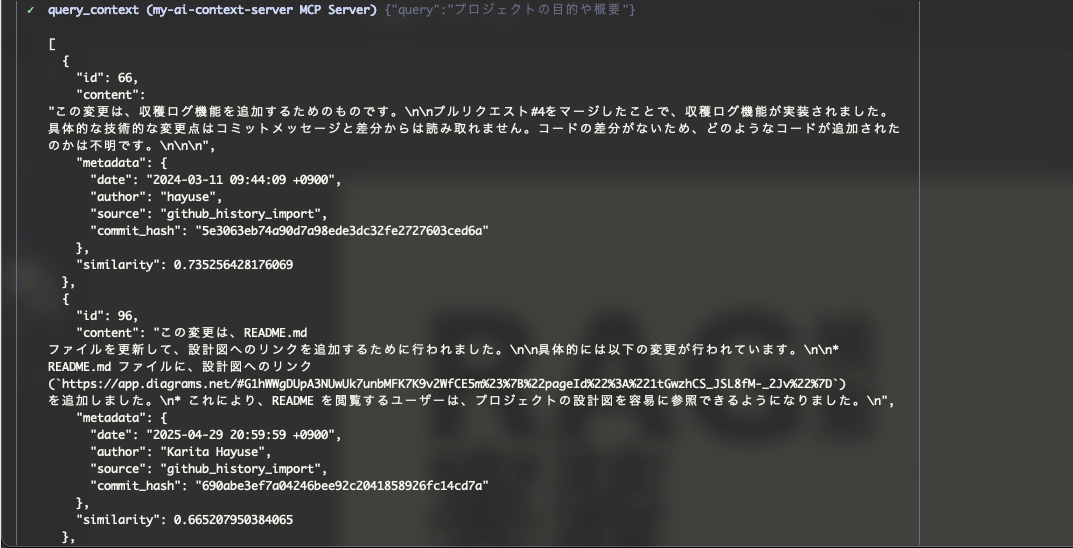
あとはそれをようやくして返答してくれました。(リンクも合ってるみたいですね)
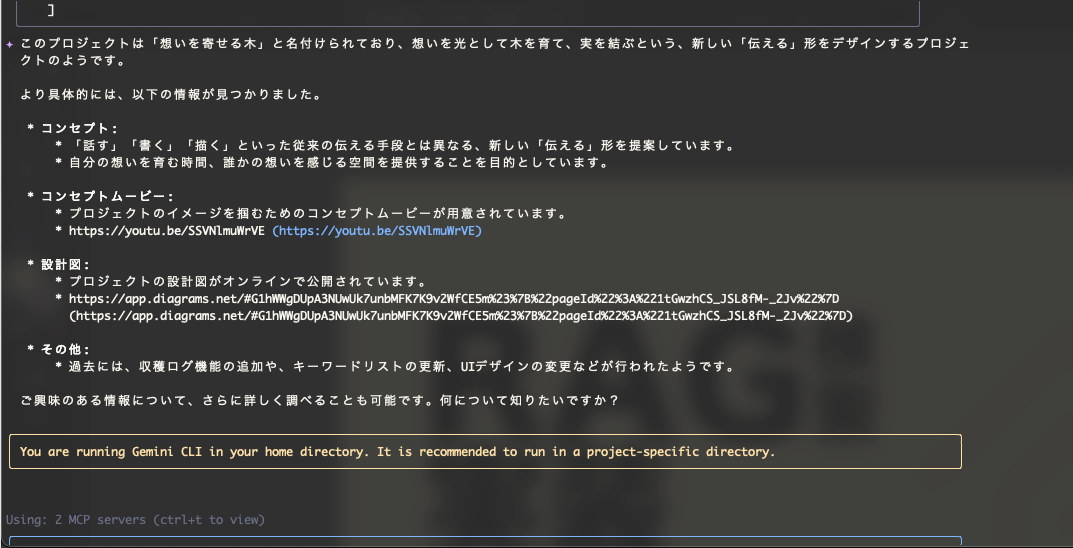
これで新しくメンバーが追加されることがあっても内容理解してくれるはず、、、?
調整ポイント
今回ベクトルデータの保存、検索をするにあたって精度を上げるために調整する余地があるポイントがいくつかあります。
このあたりは実際に使いながら調整をしていくしかないと思いちょっとずつ調整しています。
調整ポイントは主に3つです。
ベクトル化モデル
今回はGeminiのtext-embedding-004というモデルを検索とコンテキスト保存の時に使っています。
検索と保存のモデルは揃えた方がいいみたい?ですが、そもそものここのモデルの選定はいるかもしれないです。
要約のコンテキスト
今回はリポジトリの内容のをAIに一度まとめさせてからベクトル化しています。
ベクトル化のモデルをテキスト用のものを使っているのでコードをまるまる送るより、その方が精度が出そう、、、?と思ってやったのですがもしかしたらそのままベクトル化してもいいかもしれないです、、、そこは要調整。(なんならここだけ別のモデルを使うか。。。?)

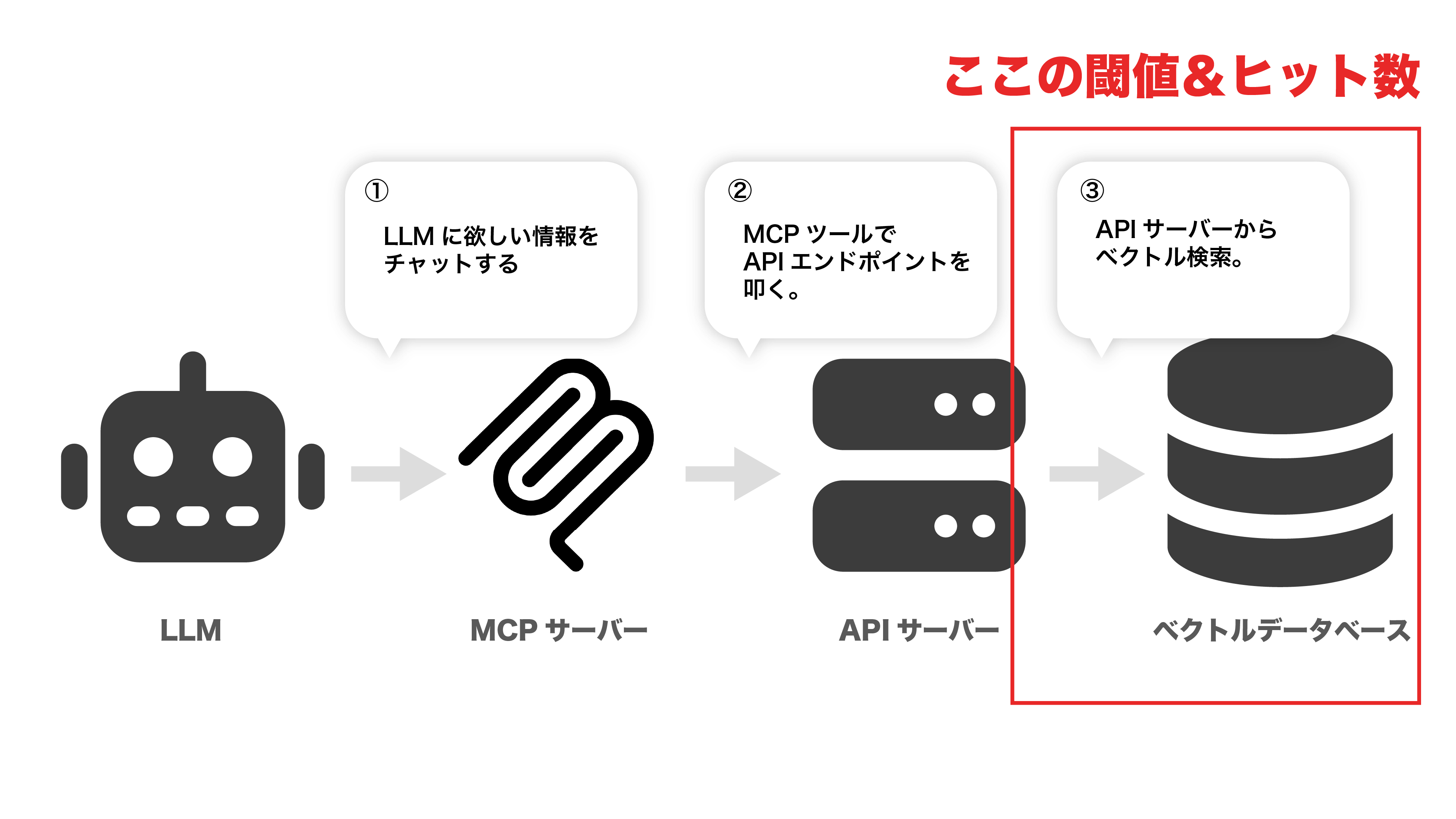
検索ヒットの閾値とヒット数
ベクトルの検索を行う時の、粒度の調整も必要かもです。
今回は0.7だとあまりにもコンテキストがヒットしなさすぎたので0.5で動くかどうかを検証しました。ここはなるべく粒度は高くヒット数は少なくした方がユーザーの意図した内容を返してくれそうですが、そもそもベクトル化するデータ自体がよくない可能性もあるので、どこから手をつけるべきか。。。。
まとめ
今回はRAG検索を独自のシステムで実装してますが、なんとGCPにはRAG検索のサービスが!!!。。。。
https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=ja
とはいえRAG検索の仕組みについて詳しく知ることができ、実際にMCPサーバーとして使えることができたのはかなり大きいと思います。
リポジトリの内容理解についてはCopilotくんが得意じゃね?ともう一人のプロジェクトの方が案を出してくれました。(確かに、、、)
そうなるとA2Aでやり取りすればいいかもなぁ、、、と漠然と思いながら一旦今の環境をチューニングしてます。
MCPサーバーもリモートでホスティングしているので、導入しているプロジェクトの方にもFBもらいながら修正していきたいと思います💦