はじめに
こんにちは。技術本部MA部の林です。MAとは「マーケティングオートメーション」の略です!
今回は、MA部で行ったアラート改善について、どのような視点でアラートを改善したか、具体例を交えてお話しします。
1. アラートの基準を実際のデータ量などを加味して調整する
まず1つ目は、アラートの基準(集計期間や閾値)が、監視したい状況に合っているか? という視点です。
具体例
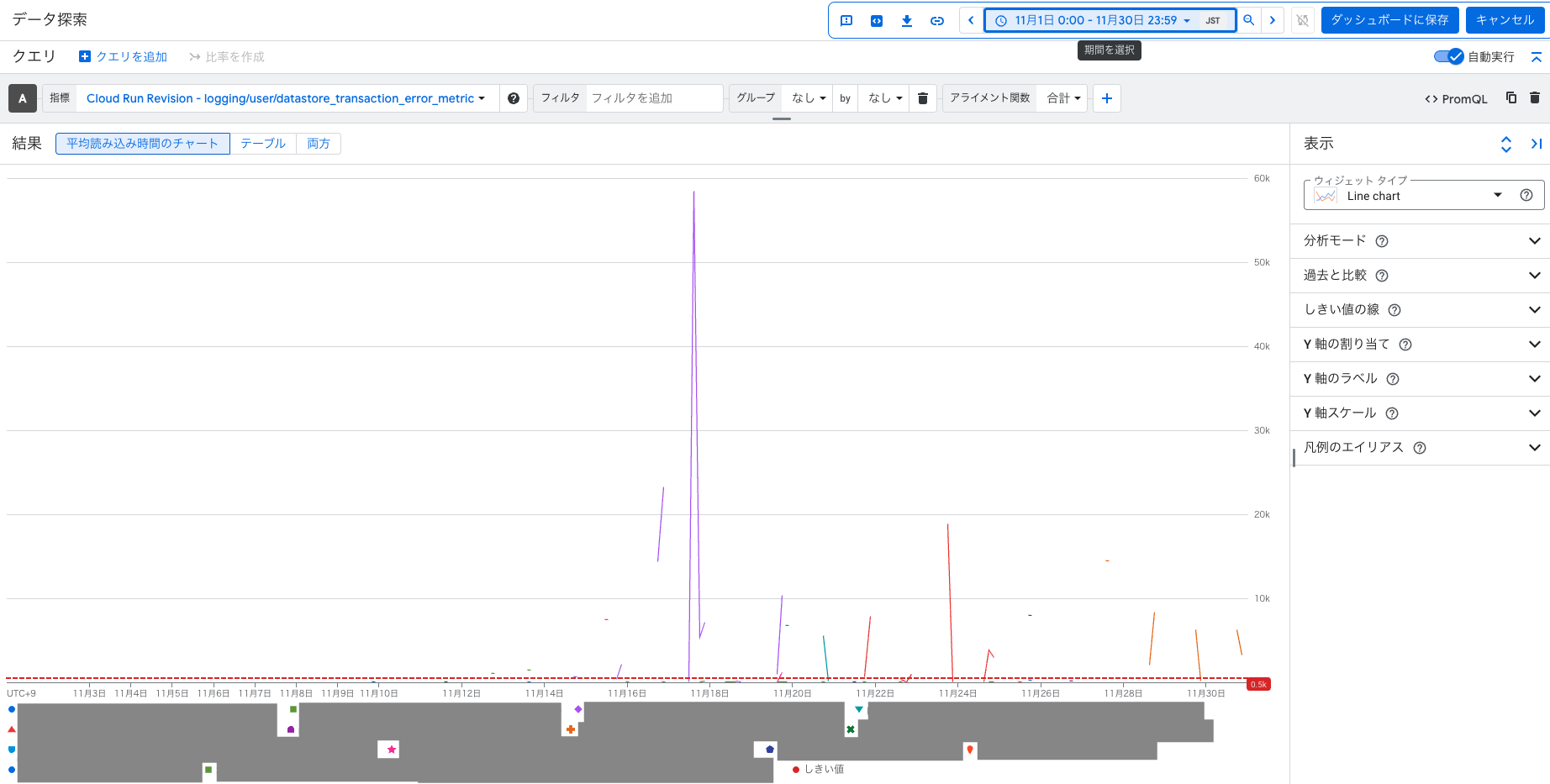
MA部では、Google CloudのDatastoreでTransaction Failedエラーが頻発していたことを受け、エラー監視用のモニターをCloud Monitoringで作成しました。
Datastoreで実行したい処理はリトライで最終的には成功していること、Datastore自体のオートスケールで時間があれば収束していくことから、エラーの発生自体は問題ないと考えています。それを踏まえてモニターを作成したのは、万が一エラーが多発した場合に、Datastoreが過負荷になり他のシステムに影響が出ることを懸念したためです。
最初に設定したアラート条件は、下記のようになりました。
- 1分間に合計して500回以上のエラーが発生した場合に通知
数ヶ月モニターを運用してみて、以下の傾向がつかめました。
- 特定のDatastoreに大量のデータが流入する時間帯がある
- その時にエラーが頻発している
- 大量のデータは1時間以上かけて入る場合があり、その間に閾値を超えたり下がったりしてしまう
そこで、アラート条件を下記のように見直しました。
- 集計時間: 1分ごと → 10分ごと に変更
- 閾値: 合計500回以上 → 平均2000回以上 に引き上げ
まず、エラーの発生傾向を踏まえて時間のスパンを伸ばし、平均値を取ることで過度なアラート発生を防ぎました。
また、モニター作成後、Datastoreが起因の問題は特に発生していませんでした。よって、仮に他のシステムに影響を与えるとしてももっと大量のエラーが出ている時だと考え、アラートの閾値を直近のエラー発生数を踏まえて2000回まで引き上げました。
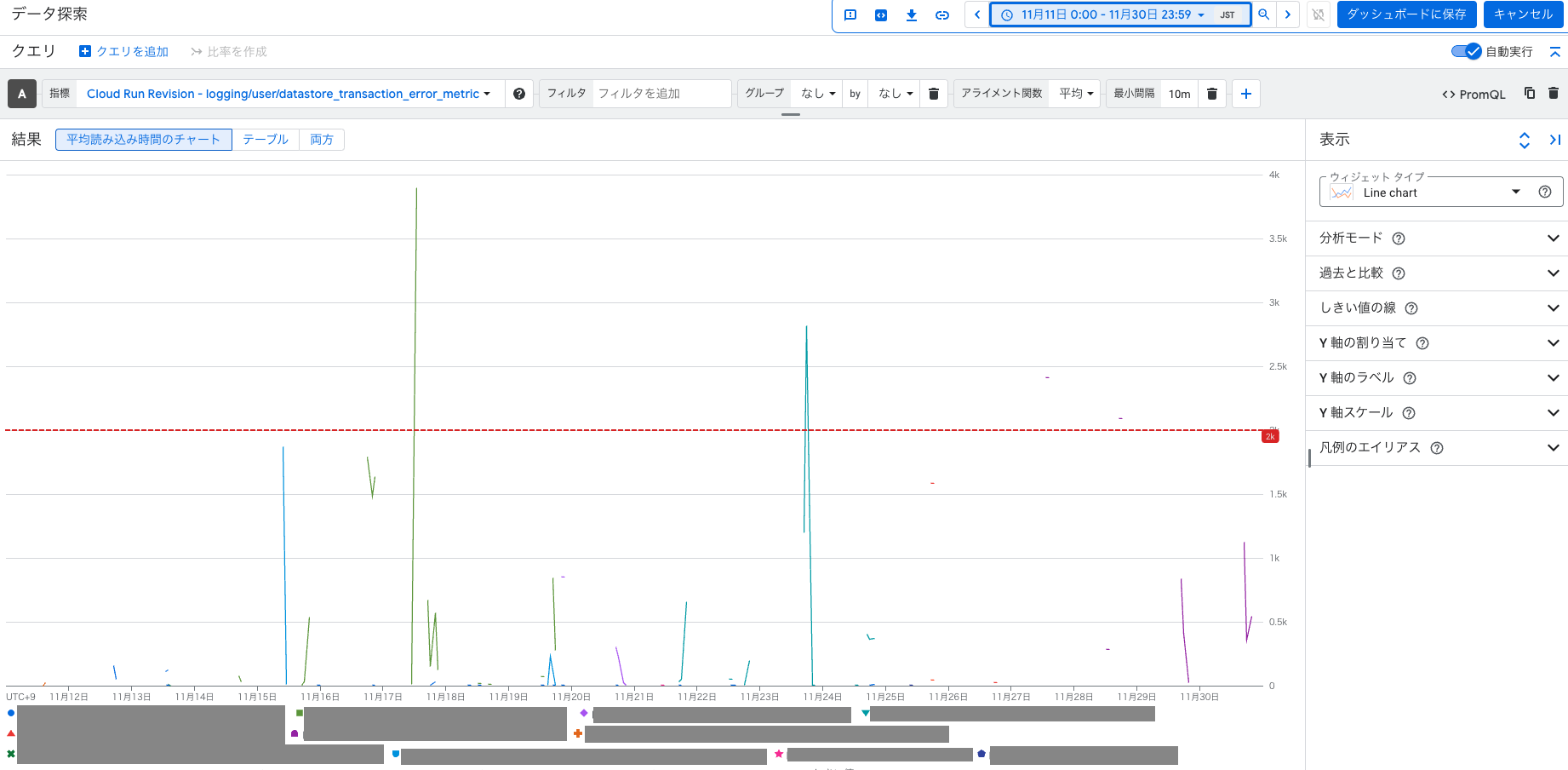
これにより、アラートの過剰検知を減らし、エンジニアの負荷を緩和することができました。今後も状況を見つつ、Datastoreの問題が発生しなければ、さらに閾値を見直していく予定です!
2. アラート後の対応が毎回同じなら、システムに組み込む
次に2つ目は、アラート後に毎回同じ対応手順を取っているなら、それをシステムに組み込もう という視点です。
具体例
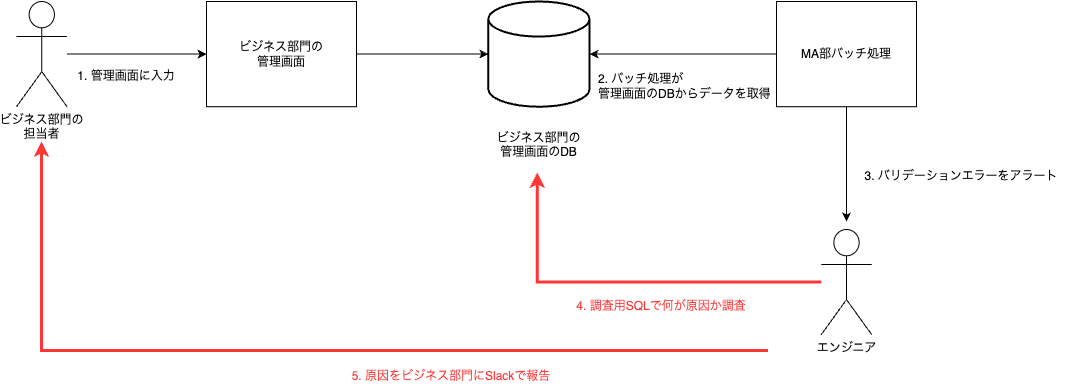
MA部では、ビジネス部門が管理画面で入力したデータを元に、メール配信のバッチ処理を行っています。この管理画面は、他のエンジニア部門が管理しているため、入力時点でバリデーションチェックを行うことができません。そのため、メール配信時にバリデーションエラーが発生した場合、以下のオペレーションを実施していました。
- バッチ処理がバリデーションエラー検知
- MA部エンジニアはアラートを受け、調査用SQLを実行
- SQLの実行結果を元に、ビジネス部門の担当者に報告
全体のフローを図にまとめました。
何度かこのオペレーションを行ううちに、「このSQLを定番としてシステムに組み込めばいいのでは?」 という結論に至りました。つまり、以下のフローです。
- バッチ処理がバリデーションエラー検知
- バッチ処理自身が調査用SQLを実行
- バッチ処理自身がSlackに調査結果を投稿
改善後の全体のフローを図にまとめました。
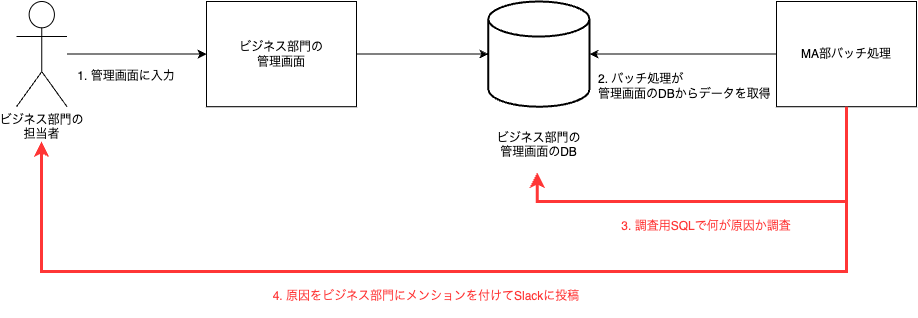
この改善により、MA部エンジニアはアラート調査の手間が省けるようになりました。また、ビジネス部門の入力担当者も調査待ちの時間を省略でき、双方に取って効率的なフローになりました!
まとめ
今回は、MA部で実際に行ったアラート改善について、具体例を交えながら紹介しました。
- アラートの基準を実際のデータ量などを加味して調整する
- アラート後の対応が毎回同じなら、システムに組み込む
アラートの根本原因を修正するのは大前提としつつ、修正に時間がかかる場合や、ハードリミットのために修正したくてもできない場合があると思います。そんな時に、小さな改善を積み重ねて、アラートの品質は落とさずに、エンジニアの負担を減らせればと思っています。
ちなみに、Datastoreのアラート見直しの過程で、保存されているデータが、ストレージ容量を圧迫していることがわかりました。これにより、不要なデータを消すなどの対策を早めに検討することができました。
このように、アラート見直しをきっかけに新たな発見があるかもしれませんので、気になるアラートがあれば、ぜひ見直してみてください!