この記事は AWS Advent Calendar 2023 18 日目の記事です。
本記事で言及している Amazon OpenSearch Service と S3 の zero-ETL integration (Direct Query) は 2023/12/18 時点で Preview の機能です。運用環境での使用は推奨されません。また将来的に動作や仕様が変更される可能性があります。
はじめに
AWS re:Invent 2023 で Amazon OpenSearch Service zero-ETL integration with Amazon S3 がプレビュー機能として発表されました。

https://www.youtube.com/watch?v=8clH7cbnIQw より引用
AWS re:Invent 2023 では他にも多くの zero-ETL 統合が発表されましたが、このアップデートだけ毛色が違うなと感じたので、整理したいと思います。
AWS の提唱する zero-ETL とは
AWS re:Invent 2022 で発表された Amazon Aurora MySQL zero-ETL integration with Amazon Redshift を皮切りに zero-ETL の概念が提唱され、re:Invent 2023 でも多くの zero-ETL 統合が発表されました。
- Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift
- Amazon RDS for MySQL zero-ETL integration with Amazon Redshift
- Amazon DynamoDB zero-ETL integration with Amazon Redshift
- Amazon DynamoDB zero-ETL integration with Amazon OpenSearch Service
- Amazon OpenSearch Service zero-ETL integration with Amazon S3
一般に ETL (Extract, Transform and Load ) というとデータの変換 (Transform) のプロセスが含まれますが、現時点で発表されている zero-ETL 統合のほとんどがソースとなるデータサービスから宛先のデータサービスへデータを転送するプロセスを自動化しています。
これらのプロセスはどちらかというと Data Ingestion という用語として定義されるものであり、ETL とは異なる、あるいは一部分として認識されているようです。
参考:
その前提からいうと、ETL における Undifferentiated Heavy Lifting (価値を生みずらい重労働) を現状の zero-ETL がすべて解決しているとは言えないのですが、このあたりは AWS 公式の「ゼロETL とは何ですか?」でも以下のように記載されていました。
ゼロ ETL 統合はどのような ETL の課題を解決しますか?
ゼロ ETL 統合は、従来の ETL プロセスでのデータ移動に関する既存の課題の多くを解決します。
違和感の正体
前述の zero-ETL 統合のデータ連携方式をタイプ別に表すと以下のようになります。ここに私が感じていた違和感の正体が隠れています。
| 機能 | データ連携方式 | タイプ |
|---|---|---|
| Aurora MySQL with Redshift | Aurora ストレージ層から Redshift ストレージ層への CDC Streaming | Data Ingestion |
| Aurora PostgreSQL with Redshift | Aurora ストレージ層から Redshift ストレージ層への CDC Streaming | Data Ingestion |
| RDS for MySQL with Redshift | MySQL バイナリログ (binlog) に依存した CDC Streaming | Data Ingestion |
| DynamoDB with Redshift | 詳細不明 | 詳細不明 |
| DynamoDB with OpenSearch Service | OpenSearch Ingestion による Streaming | Data Ingestion |
| OpenSearch Service with S3 | OpenSearch Service から S3 への直接クエリ | Fedrated Query |
DynamoDB と Redshift の統合は 2023/12/18 時点で限定プレビュー中のため、詳細は不明ですが、他の統合はほぼ Data Ingestion に分類できます。
Amazon OpenSearch Service zero-ETL integration with Amazon S3 が提供する機能は S3 から OpenSearch Service への Data Ingestion ではありません。OpenSearch Service へのデータの移動なしに S3 へ直接クエリを実行できる機能です。違和感の正体はこれです。
タイプとしては Amazon Athena や Amazon Redshift Spectrum に代表されるような Fedrated Query の機能であって、zero-ETL ではないだろうと思ったのですが、これに関しても「ゼロETL とは何ですか?」に記載があります。
ゼロ ETL のさまざまなユースケースにはどのようなものがありますか?
ゼロ ETL には 3 つの主なユースケースがあります。フェデレーテッドクエリ
フェデレーテッドクエリテクノロジーは、データの移動について心配することなく、さまざまなデータソースに対してクエリを実行するための機能を提供します。使い慣れた SQL コマンドを使用してクエリを実行し、運用データベース、データウェアハウス、データレイクなどの複数のソース間でデータを結合できます。
ということで Fedrated Query も AWS 的には zero-ETL の文脈の一つとしてちゃんと定義されていました。
OpenSearch Service Direct Query の実際
Amazon OpenSearch Service zero-ETL integration with Amazon S3 は OpenSearch Service 上は Direct Query という機能名が正式名称であるようです。
アーキテクチャ
Direct Query がどのように動作するか re:Invent 2023 の Breakout Session で紹介されています。
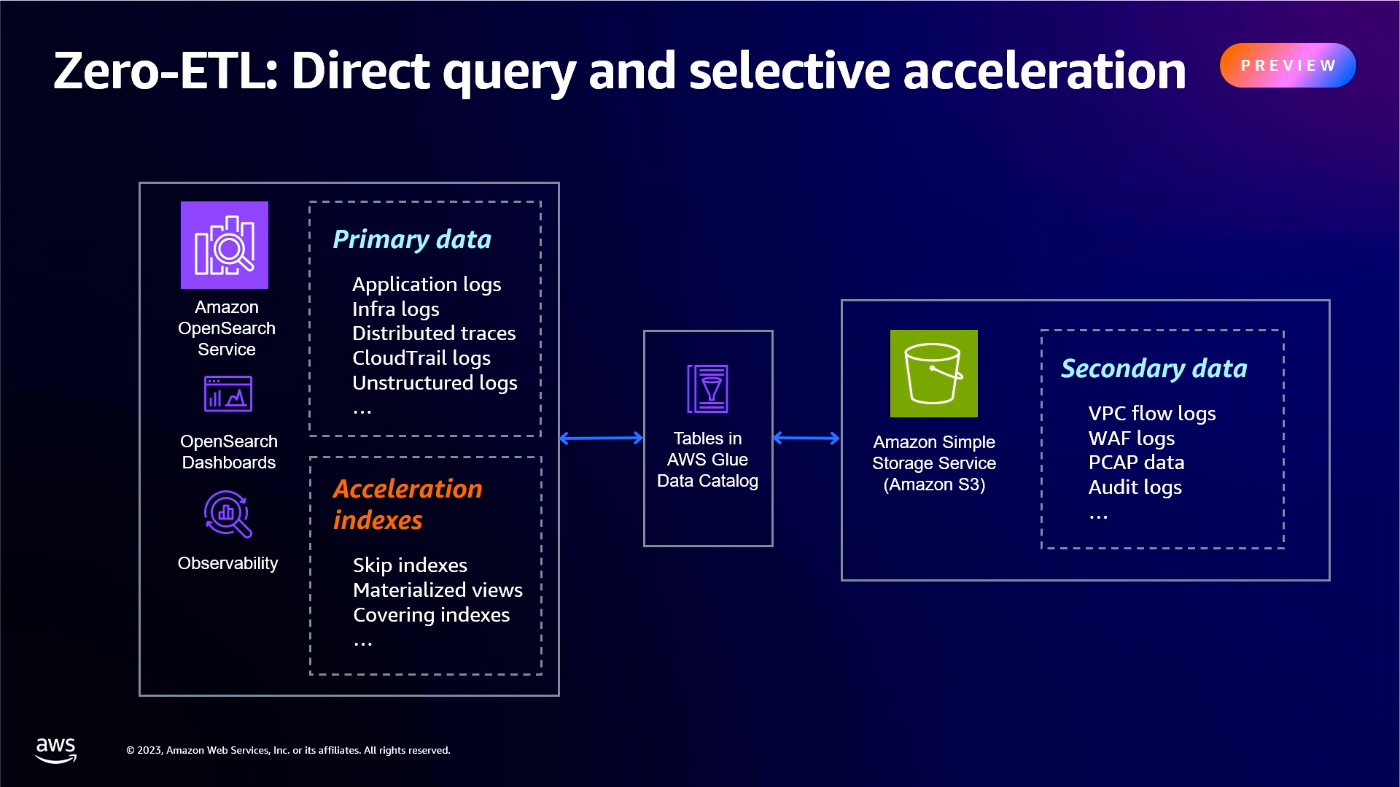
Vector database and zero-ETL capabilities for Amazon OpenSearch Service (ANT353) より引用
Primary data とは頻繁にクエリされ、即時分析が必要な重要データで、完全に OpenSearch に取り込まれているデータを指します。VPC flow logs や S3 アクセスログなどの、履歴やコンプライアンスのためのデータグループは一般にクエリの頻度は低く、ログサイズも大きいため、Secondary data として S3 に保存されています。
Direct Query を使用すると、S3 から OpenSearch にデータを戻さずに、OpenSearch から直接 Secondary data をクエリできます。
実際には OpenSearch Service から S3 への Direct Query には AWS Glue Data Catalog によって定義されたテーブルが使用されます。OpenSearch Service 上で既存のデータベースやテーブルを管理することも、新しいデータベースを作成することもできます。
クエリを高速化する仕組み
S3 へクエリする際に気になるのはパフォーマンスです。Direct Query ではパフォーマンスを高速化するためのオプションが 3 つ用意されており、ユースケースに応じて使用できます。

Vector database and zero-ETL capabilities for Amazon OpenSearch Service (ANT353) より引用
Skipping indexes
Skipping index を作成すると、S3 に保存されているデータのメタデータのみを OpenSearch にインデックスします。これによりクエリプランナーはすべてのパーティションやファイルをスキャンするのではなく、効率的にデータの場所を絞り込むようにクエリを書き換えます。
Materialized views
Materialized view を使用して少量のデータを OpenSearch Service に取り込み、事前に集計しておくことで OpenSearch Dashboard のビジュアライゼーションを高速化できます。
Covering indexes
テーブルのカラムを指定して、Covering index を作成することができます。Covering index は指定したカラムからすべてのデータを取り込むため、OpenSearch Servicen のストレージ使用量は増えますが、3 つのインデックスタイプの中で最も高パフォーマンスです。頻繁かつ、リアルタイムに分析したいデータが存在している場合に適しています。
料金
Direct Query は既存の Amazon OpenSearch Service ドメインのノードではなく、サーバーレスで実行されます。クエリが消費するコンピューティングに対して、実行時間 (分単位) の料金が発生します。課金単位は OpenSearch Serverless や OpenSearch Ingestion と同じ OpenSearch Compute Unit (OCU) です。
2023/12/18 時点の東京リージョンの料金は $0.299 per OCU per hour となっています。
注意点としては
- 前述の 3 つのインデックスを作成するクエリに対しても料金は発生します
- Glue Data Catalog および S3 に対する保存料金やリクエスト料金も通常通り発生します
まとめ: ニアリアルタイムに連携する世界

- 現状の zero-ETL 統合は従来の ETL プロセスのうち、データ移動の課題を解決するもの (Data Ingestion)
- OpenSearch Service と S3 の zero-ETL 統合は Data Ingestion ではなく、S3 へ直接クエリを行う機能 (Fedrated Query)
- Fedrated Query も AWS の zero-ETL に定義として含まれる
AWS re:Invent 2022 で発表された Amazon Aurora MySQL zero-ETL integration with Amazon Redshift は zero-ETL という言葉の強さで大きな話題になりました。Aurora と Redshift のストレージ層で CDC によるデータストリーミングを行うアーキテクチャも革新的でした。
re:Invent 2023 でも多くの zero-ETL 統合が発表されましたが、binlog に依存したストリーミングや OpenSearch Ingestion によるストリーミングなどそれを実現する内部アーキテクチャーは様々です。
単に zero-ETL が拡充されているというよりも Redshift、OpenSearch Service を中心としつつデータ系のサービスがメッシュかつニアリアルにつながっていく未来を感じました。
以上です。
参考になれば幸いです。