元凶はAdobeか
PDFからテキストを抽出しようとすると、一部の漢字が康煕部首になっていることがあるという。
PDFテキストに康煕部首が混じってしまう原因は
- PDF内はUnicodeではなく、CID/GIDで文字を指定している
- フォントによっては、本来Unicodeで別コードとなっている康煕部首とCJK統合漢字を、cmapによって同一のGIDと結びつけている
(フォントの視点からすれば、わざわざ同一のグリフを重複収容する必要はないということだろう。逆に言うと、康煕部首が入ってないフォントでは問題が起き得ない。) - コピペして取り出す際にはTo Unicode CMapでCID/GIDからUnicodeに変換されるが、この変換テーブルが康煕部首を指定してしまっている
といった経緯のよう。
詳細は以下の記事やスライドで解説されている。
この問題はAdobe製品(Acrobat Distiller)でも生じており、フォーラムでも何度か改善を求められてきたようだ。
Adobe以外のアプリでも、康煕部首に置き換わってしまうケースはある。
Chrome、Quartz PDFContext(macOSのプレビューから出力か)、Microsoft print to PDFなど。
仮想プリンタ系が多いようだ。
解決策もあるにはあるが…。
いずれにしろ、AdobeによるPDFの仕様とUnicode逆変換テーブルの出来の悪さが、意図しない康煕部首を発生させてしまっているようだ。
ということで、アプリ搭載のPDF出力機能だとどうなのか試してみた。
何種類か試した限りでは特に問題無し
問題が起きるとされる游ゴシックを用いて、手持ちのアプリのPDF出力機能を試したところ、康煕部首に置き換わるということは無かった(いずれもWindows 10で検証、一部アプリのバージョンが古い点はご容赦)。
- Microsoft Word 2010
- 一太郎2020
- パーソナル編集長 Ver.16
- LibreOffice 25.8
- Affinity 3 by Canva
アプリ自体にPDF出力機能がある場合は、その機能を使った方が康煕部首に置き換わるリスクを極力減らすことができる。
Adobe DistillerやMicrosoft print to PDFなど仮想プリンタアプリの方がPDF出力時の操作を単純化できるが、康煕部首問題を考えると用途を限った利用が望ましい。
康煕部首とCJK統合漢字を混在させたらどうなるか
では、上記5アプリで康煕部首とCJK統合漢字を混在させてPDF出力したらどうなるだろうか。
ちょっと便利帳の康煕部首検出ページのサンプルテキストを使用し、試してみた。
以下のようなテキストを各アプリに読み込ませ(パーソナル編集長だけはUTF-8のテキスト読み込みで文字化けしたのでコピペ)、康煕部首なしテキスト→康煕部首ありテキストの順に並べた文書と、康煕部首ありテキスト→康煕部首なしテキストの順に並べた文書の2種類を用意。

MSゴシック(康煕部首なしフォント)と游ゴシック(康煕部首ありフォント)にフォントを変更し、PDF出力した。
康煕部首かどうかの判定は、PDFをSumatraPDF v3.5.2で開き、テキストをコピー、サクラエディタに貼り付けて目視で行っている(上記キャプ画のように、地のUDEV Gothic JPDOCに対して康煕部首は小さく游ゴシックで表示されるため)。
PDFを解析する方法と比べると不十分な検証ではあるが(ToUnicode CMapの結果かActualTextの結果かは判別できない)、康煕部首問題を概観するには十分ではないかと考える。
MSゴシック
| アプリ名 | 康煕部首ありテキスト |
|---|---|
| Word2010 | 全て康煕部首 |
| 一太郎2020 | 全て康煕部首 |
| パソ編Ver16 | 全て康煕部首 |
| LibreOffice25.8 | 全て康煕部首だがテキスト乱れ |
| Affinity3 | 風非雨香鹿米戸豆毋立鹿鼠龍のみ康煕部首 |
- 並び順に関係なく、康煕部首なしテキストだと全てCJK統合漢字になり、康煕部首ありテキストは上記の結果となった。
- Affinityは一部の康煕部首がCJK統合漢字に置き換わった。要注意。
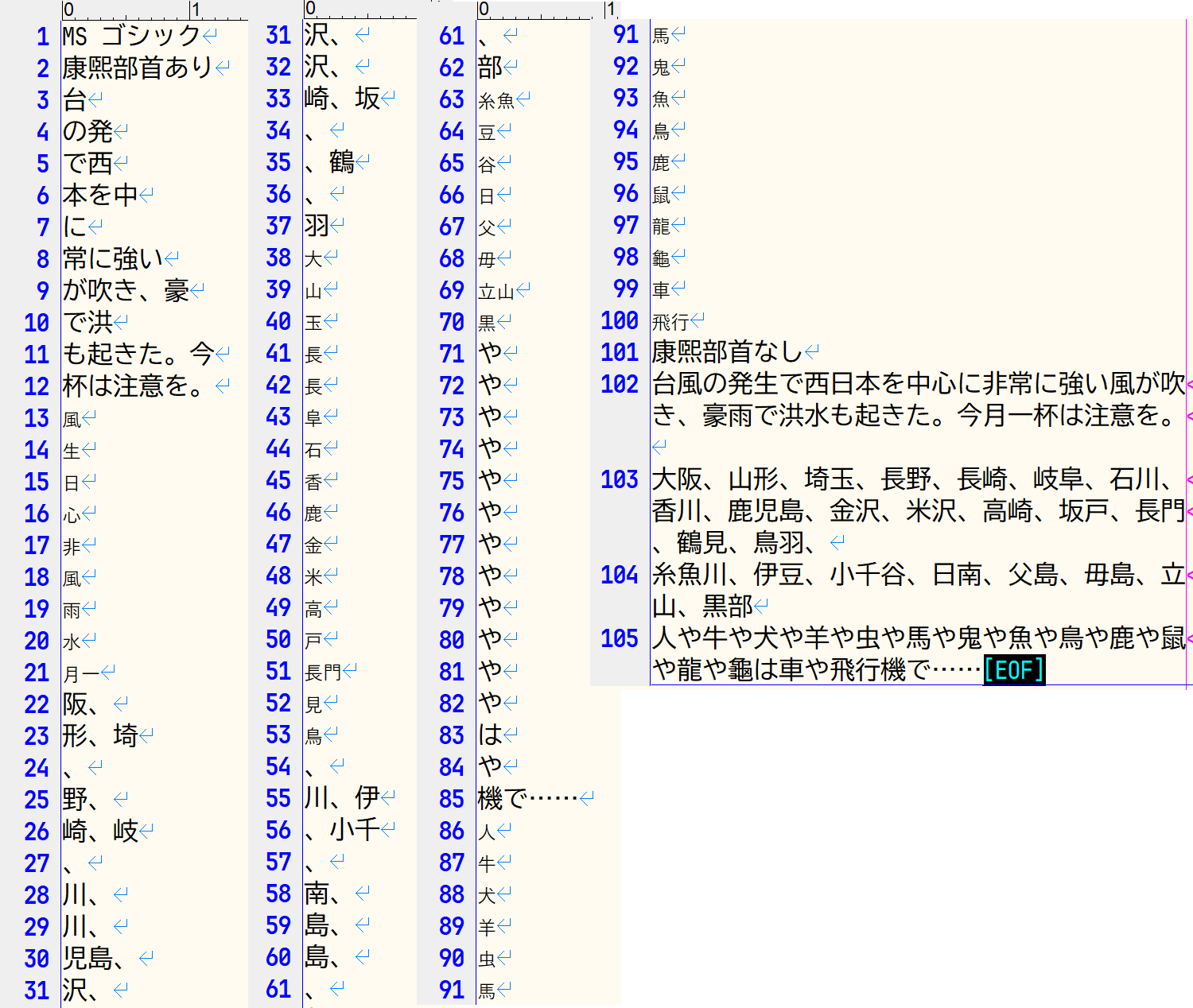
- LibreOfficeは康煕部首が維持されたが、康煕部首の部分が分離して1文字ごと改行になる等、テキストが乱れてしまった(画像2~3)。
現状は康煕部首を含めてPDF出力をした場合、テキストの再利用は難しくなる。 - PDFの康煕部首の見た目は、国産の一太郎とパソ編が游ゴシックの平体、他3アプリが中国語フォント。
游ゴシック
| アプリ名 | 康煕部首なし→ありの順 | 康煕部首あり→なしの順 |
|---|---|---|
| Word2010 | 全てCJK統合漢字 | 全て康煕部首 |
| 一太郎2020 | 全てCJK統合漢字 | 全てCJK統合漢字 |
| パソ編Ver16 | 全てCJK統合漢字 | 全てCJK統合漢字 |
| LibreOffice25.8 | 全てCJK統合漢字 | 全て康煕部首 |
| Affinity3 | 全てCJK統合漢字 | 全てCJK統合漢字 |
- 康煕部首が入った游ゴシックの場合、ActualTextの影響がなければ、ToUnicode CMapによる一対一対応でCJK統合漢字のみか康煕部首のみのどちらかとなる。
- 一太郎、パソ編、Affinityは先に康煕部首が来てもCJK統合漢字となる。
康煕部首入りテキストが紛れ込んでも二次被害は生まない。 - 一方、WordとLibreOfficeは先に登場したUnicodeをToUnicode CMapで紐づけているのか、あり→なしの場合、CJK統合漢字まで康煕部首に置き換わってしまった。
Adobe等のPDFが生んだ康煕部首入りテキストが文書冒頭に来てしまった場合、さらなる康煕部首入りPDFを生んでしまいかねない。
画像
画像2:LibreOfficeから出力したPDF。
MSゴシック康煕部首ありの部分を選択すると、選択範囲が異様に広がっている。
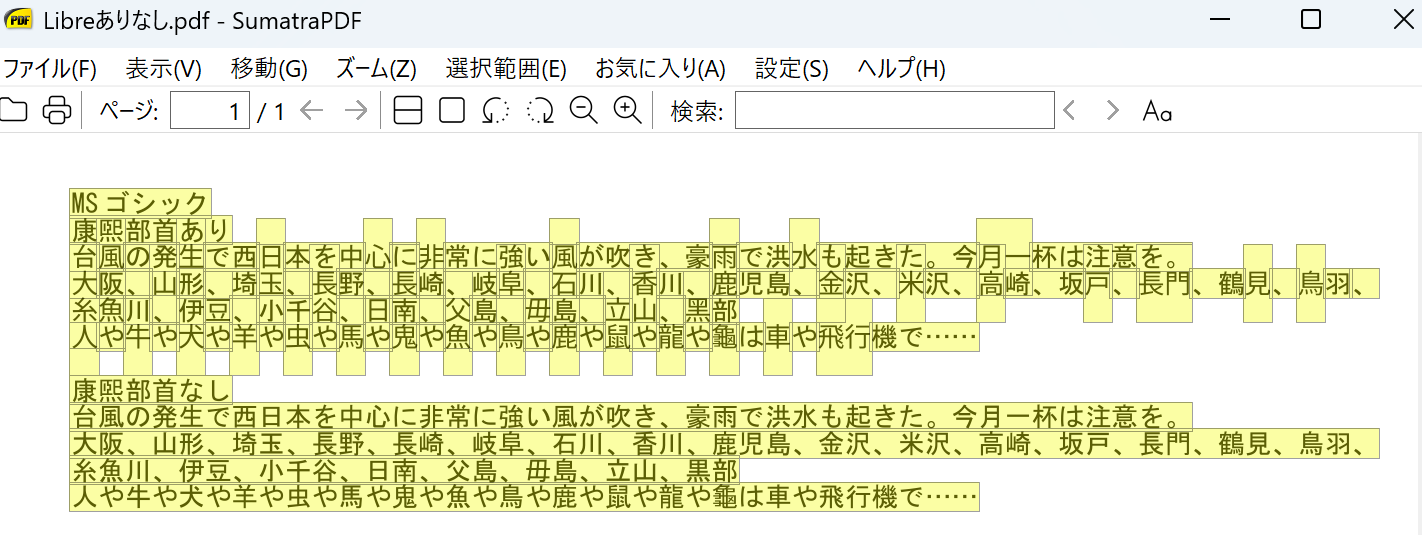
画像3:LibreOfficeのPDFからテキストをコピーしてサクラエディタに貼り付けたもの。
適宜右端を省略して横に並べた。