簡単なサイネージならブラウザでよくないか
MeePet を Android 端末として使う では Slideshow アプリを使ってサイネージ的な使い方ができることを確認した。
サイネージとして使うにはこうした専用アプリを使うのもよいが、ブラウザを使って Web ページを自動更新させる方法も不可能ではない。
今回は PHP を使って Web の株価指数情報を大きな文字で表示させることを試みる。
PHP 環境をローカルに作る
PHP の使えるレンタル Web サービスを使えばローカルに PHP の動作する環境を作る必要はないが、試行錯誤するのであれば公開サーバー上で行うのではなく、ローカルに環境を作った方がよい。
Windows だと XAMPP を使うと PHP 機能を含む Web サーバーや MySQL などの環境を簡単に構築できる。サービスの稼働・停止も常駐アプリから即座に行える。
そもそも MeePet 内にサーバーを立ててしまうことすら可能である。
スクレイピング
今回情報の取得元とするのは日本取引所グループの TOPIX である。
値は表組み内にあり、左から取引日、始値、高値、安値、現在値(終値)、前日比と並んでいる。
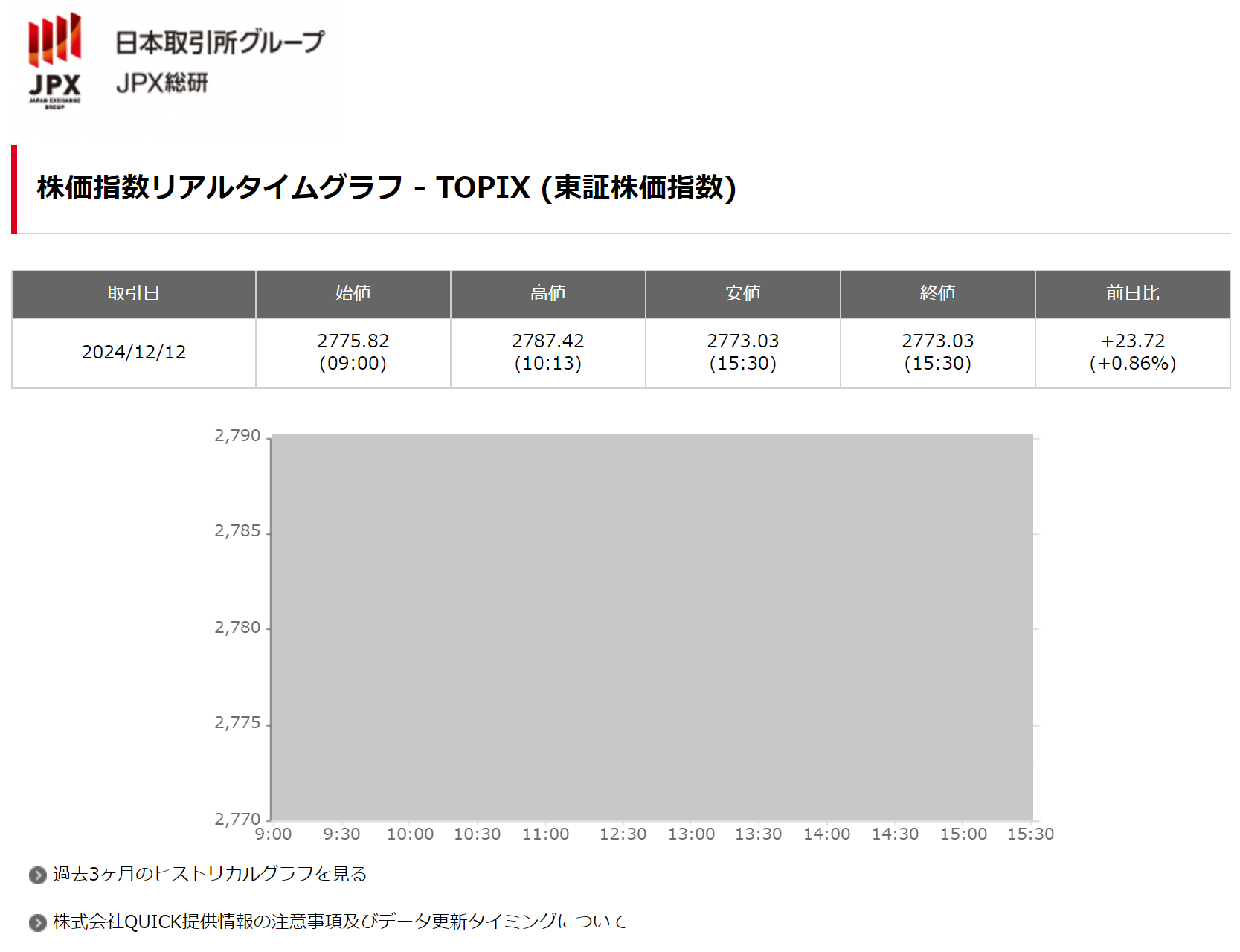
ソースを見ても、 td タグに囲まれた部分を読み込めばよさそうである。

PHP でのスクレイピングは DOM を使ったものが容易とのこと。
ということで、 query を使って td 要素の 0番目、4番目、5番目を取り出すと、あっさり取引日、現在値(終値)、前日比を取り出すことができた。
表が1つしかなく、ヘッダ行を除いたデータ部が1行しかない簡素な作りゆえこれだけで済んだが、普通はここまで簡単にはいかない。
<?php
$dom = new DOMDocument('1.0', 'UTF-8');
$html = file_get_contents("https://quote.jpx.co.jp/jpx/template/quote.cgi?F=tmp/real_index&QCODE=151");
@$dom->loadHTML($html);
$xpath = new DOMXpath($dom);
echo $xpath->query("//td")->item(0)->nodeValue;
echo $xpath->query("//td")->item(4)->nodeValue;
echo $xpath->query("//td")->item(5)->nodeValue;
?>
2024/12/12 2773.03(15:30) +23.72(+0.86%)
あとは現在値の前半部分だけ取り出して大きく表示させたい…のだが、なぜか DOM で取り出した文字列をさらに substr や mb_substr で切り出すことができない。全部取り出されてしまうか全く表示されないかになってしまう(どうやらソース整形のタブ文字が前後に含まれてしまっているようだ)。
そこで文字列を置き換える str_replace を試すと、これは機能した(マッチング部分を空文字に置き換えることで文字を削除する使い方ができる)。正規表現の preg_replace でカッコ内の数字もマッチングさせて削除できるので、とりあえずこれらを駆使すれば前半部分のみ取り出せそうである。
そもそもマッチさせて抜き出すのであれば、 preg_match を使うこともできた。この場合、マッチした文字列は配列[0]に入る。
また、 strpos も使えたので、前日比に + を含む場合・ - を含む場合の条件分岐で色付けを施すことも可能だ。
試行錯誤の末、以下のようなスクリプトで、1分毎にリロードする TOPIX 表示 Web ページを作ることができた。
CSS も MeePet 上の Firefox の見た目で調整しただけなので雑だが、それでもこの程度の見栄えには持っていくことができる。
<html>
<head>
<meta http-equiv="refresh" content="60">
<style type="text/css">
.header {
font-size: 50px;
line-height: 2em;
}
.cur {
font-size: 250px;
font-weight: bold;
line-height: 1.2em;
}
.comp {
font-size: 100px;
text-align: right;
line-height: 1em;
}
.comp_plus {
font-size: 100px;
text-align: right;
color: red;
line-height: 1em;
}
.comp_minus {
font-size: 100px;
text-align: right;
color: green;
line-height: 1em;
}
</style>
</head>
<?php
$dom = new DOMDocument('1.0', 'UTF-8');
$html = file_get_contents("https://quote.jpx.co.jp/jpx/template/quote.cgi?F=tmp/real_index&QCODE=151");
@$dom->loadHTML($html);
$xpath = new DOMXpath($dom);
$cur = $xpath->query("//td")->item(4)->textContent;
$cur1 = preg_replace("/\(\d+:\d+\)/", "", $cur);
$comp = $xpath->query("//td")->item(5)->textContent;
preg_match("/\d+:\d+/", $cur, $cur2);
echo '<div class="header">';
echo "TOPIX ";
echo $xpath->query("//td")->item(0)->nodeValue;
echo ' ' . $cur2[0];
echo "<br></div>";
echo '<div class="cur">';
echo $cur1;
echo "<br></div>";
if(strpos($comp,'+') !== false){
echo '<div class="comp_plus">';
}elseif(strpos($comp,'-') !== false){
echo '<div class="comp_minus">';
}else{
echo '<div class="comp">';
}
echo $xpath->query("//td")->item(5)->nodeValue;
echo "</div>";
?>
</html>
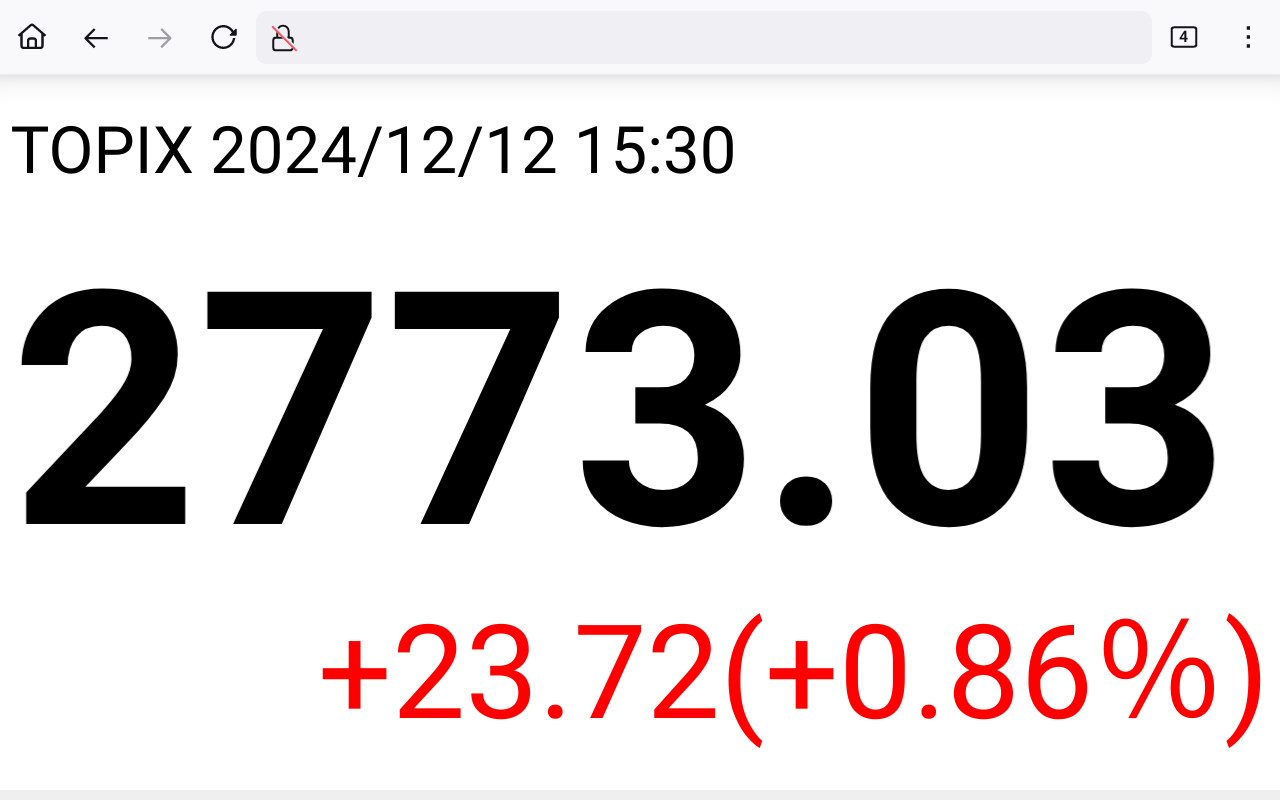
Slideshow なら
RSS に変換して Slideshow に読み込ませれば、本物のティッカーのように表示させることもできる。
