📝 3行まとめ
- SQLiteを「1件ずつ書く」か「まとめて書く」かで、処理速度に最大19.9倍の差が生まれる
- 読み取りもキャッシュ戦略次第で、素の
sqlite3より最大730倍速になる - NanaSQLite・DictSQLite・sqlite3の3つを件数別・操作別に計測して傾向を可視化した
本記事のベンチマークはすべて NanaSQLite v1.5.3の最新版(2026年4月時点)、DictSQLite、Python標準sqlite3 を用いて、Windows 11・Python 3.11・SSD環境で実施しました。
はじめに
「SQLiteって遅い」と感じたことはありませんか?
実は多くの場合、SQLiteが遅いのではなく「使い方が遅い」のです。
特に「ループで1件ずつ書く」というコードは、件数が増えるにつれて致命的な速度低下を引き起こします。
今回は以下の3ライブラリを対象に、件数(10〜10,000件)×操作(初期化・書き込み・読み取り)の組み合わせで計測し、どのライブラリのどの操作で差が生まれるのかを徹底的に調べました。
計測環境・方法
OS : Windows 11
Python : 3.11
ストレージ : SSD
測定方法 : 各操作をREPEAT=5回実行し、mean/min/maxを記録
テスト日 : 2026年4月
テストデータは以下の構造のdictを件数別に生成しています。
{
f"key_{i}": {
"name": f"user_{i}",
"score": i * 1.5,
"tags": ["admin", "active"],
"meta": {"created": "2026-04-19", "index": i},
}
for i in range(n)
}
計測対象の操作は以下の通りです。
| 操作 | 内容 |
|---|---|
init |
データベースの初期化・接続 |
single_write |
1件ずつループで書き込み |
batch_write |
一括書き込み(batch_update / executemany) |
single_read |
1件ずつループで読み取り |
batch_read |
キーリストで一括読み取り |
bulk_read |
起動時に全データをメモリロードして読み取り |
結果①:初期化
n=10
nanasqlite : 4.14ms
dictsqlite : 17.73ms ← 最大31msの揺れあり
sqlite3 : 2.36ms
sqlite3が最速ですが、DictSQLiteの初期化は不安定で最大440msかかる場合がありました。
NanaSQLiteは件数に関わらず常に約4msで安定しています。
DictSQLiteの初期化は激しく不安定
100件のテストで平均90.87msを記録しましたが、最小値は6.40ms・最大値は413.42msと、実行のたびに大きく変動します。本番環境では予測困難な遅延が発生するリスクがあります。
結果②:書き込み——「1件ずつ」は絶対にやってはいけない
これが本記事の核心です。
シングル書き込み(1件ずつループ)
| 件数 | nanasqlite | dictsqlite | sqlite3 |
|---|---|---|---|
| 10 | 1.10ms | 1.50ms | 2.75ms |
| 100 | 9.30ms | 13.63ms | 3.15ms |
| 500 | 42.17ms | 66.86ms | 5.23ms |
| 1,000 | 85.38ms | 126.21ms | 7.56ms |
| 5,000 | 404.62ms | 507.13ms | 30.31ms |
| 10,000 | 925.04ms | 1021.49ms | 59.42ms |
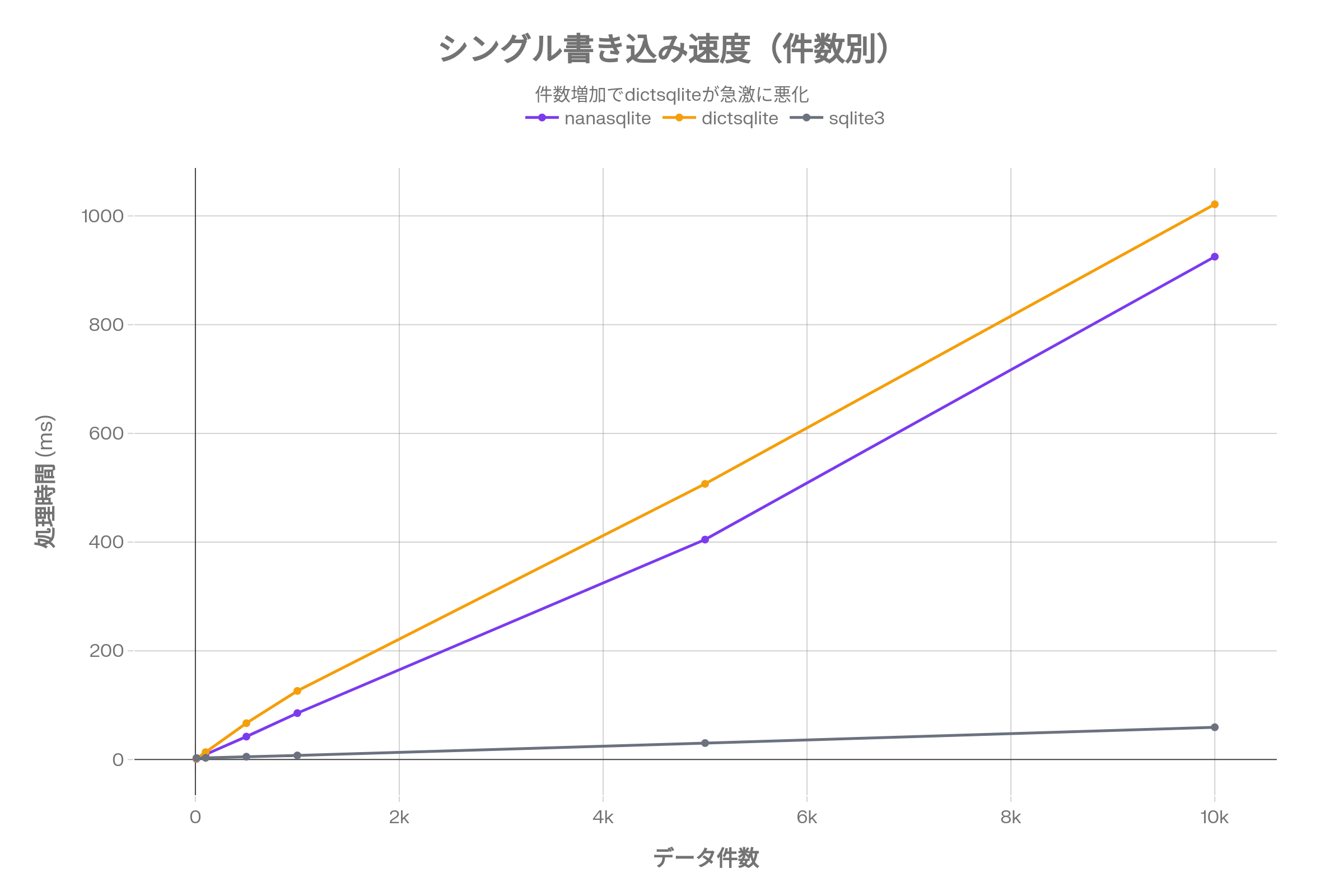
10,000件の1件ずつ書き込みは、nanasqliteで約0.9秒、dictsqliteで約1秒かかります。
一方、sqlite3は59msと最速です。シングル書き込みに関しては、素のsqlite3が最も速い。
なぜこうなるのか。nanasqliteやdictsqliteは書き込みのたびにJSONシリアライズや内部処理が走るため、件数に比例してオーバーヘッドが蓄積します。
バッチ書き込み(一括)
| 件数 | nanasqlite (batch_update) | sqlite3 (executemany) |
|---|---|---|
| 10 | 0.12ms | 2.75ms |
| 100 | 0.44ms | 3.18ms |
| 500 | 1.30ms | 4.77ms |
| 1,000 | 2.36ms | 6.98ms |
| 5,000 | 10.75ms | 27.87ms |
| 10,000 | 38.66ms | 52.60ms |
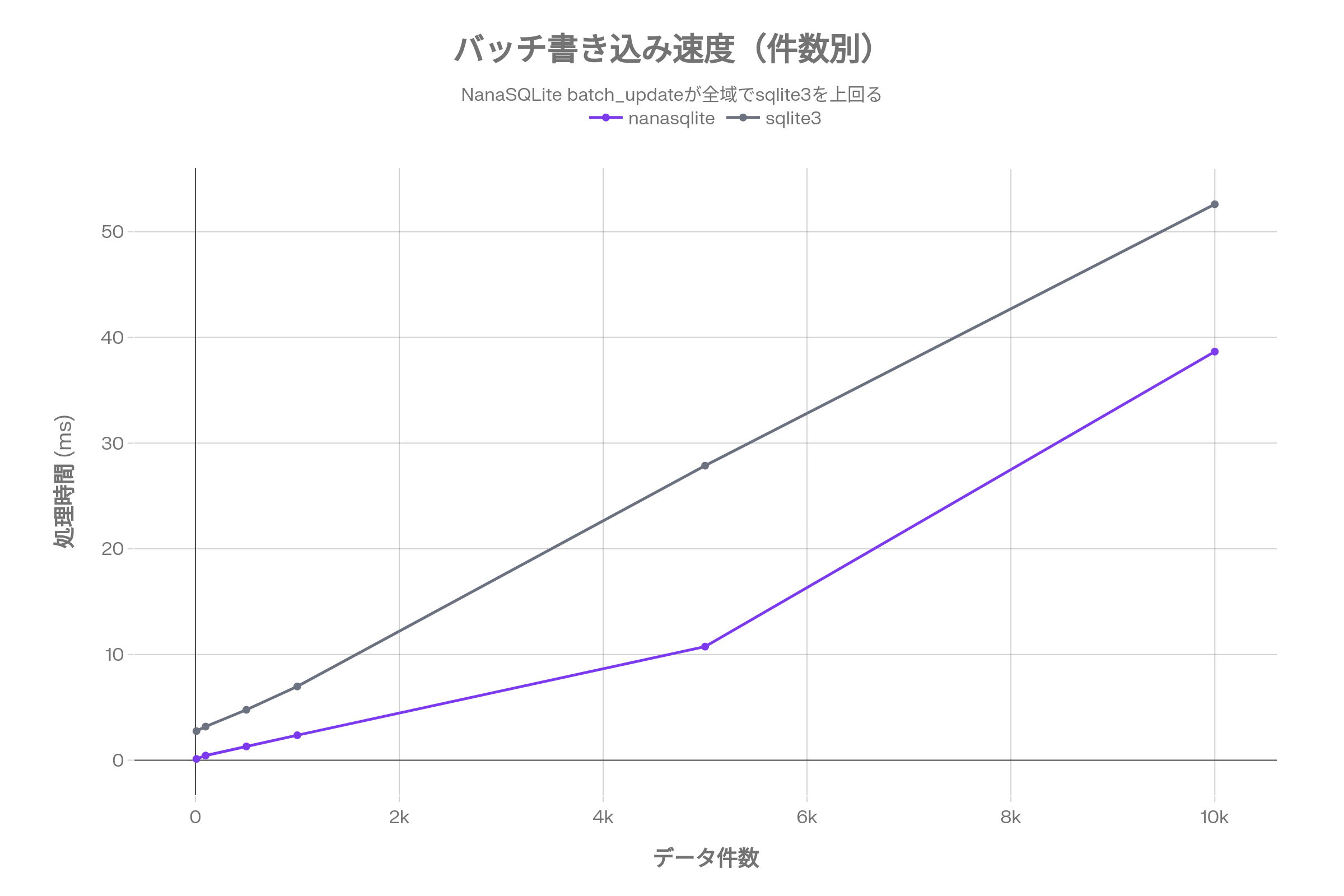
batch_updateを使うと、10,000件でも38msで完了します。
シングル書き込みの925msと比較すると、同じデータ量で約23.9倍速です。
# ❌ これをやると10,000件で約1秒かかる
for key, value in data.items():
db[key] = value
# ✅ これなら10,000件でも38ms
db.batch_update(data)
大量データには必ずbatch_updateを使ってください
1件ずつの書き込みはトランザクションのコミットが毎回走るため、件数に比例して指数的に遅くなります。100件程度なら気にならなくても、1,000件を超えた時点で体感できる差になります。
結果③:読み取り——キャッシュが730倍の差を生む
シングル読み取り(1件ずつ)
| 件数 | nanasqlite | dictsqlite | sqlite3 |
|---|---|---|---|
| 10 | 0.002ms | 0.058ms | 0.960ms |
| 100 | 0.009ms | 0.188ms | 7.97ms |
| 500 | 0.041ms | 0.904ms | 39.39ms |
| 1,000 | 0.095ms | 1.859ms | 77.32ms |
| 5,000 | 0.448ms | 24.860ms | 390.99ms |
| 10,000 | 1.201ms | 50.265ms | 876.14ms |
10,000件の読み取りでnanasqliteは1.2ms、sqlite3は876ms。
約730倍の差です。
この差の正体はインメモリキャッシュです。NanaSQLiteは一度読み込んだデータをメモリにキャッシュするため、2回目以降のアクセスはディスクI/Oが発生しません。
db = NanaSQLite("data.db")
# 初回:ディスクから読む
val = db["key_1"]
# 2回目以降:メモリキャッシュから返す(超速)
val = db["key_1"]
val = db["key_2"]
bulk_load=True:起動時に全データをメモリへ
# 大量データを頻繁に読む場合はbulk_load=Trueが有効
db = NanaSQLite("data.db", bulk_load=True)
| 件数 | bulk_load=True(mean) |
|---|---|
| 10 | 2.996ms |
| 1,000 | 4.233ms |
| 5,000 | 19.514ms |
| 10,000 | 39.008ms |

起動時に全データをメモリへ展開するため、初期化コストは上がりますが以降の読み取りが最速になります。5,000件以上のデータを頻繁に参照するユースケースで特に効果的です。
まとめ:ライブラリ×操作の使い分け早見表

| 操作 | 推奨 | 理由 |
|---|---|---|
| 初期化 | NanaSQLite | 安定した約4ms。DictSQLiteは不安定 |
| 少量シングル書き込み(〜100件) | どれでも可 | 差が小さい |
| 大量シングル書き込み(100件〜) | sqlite3 | オーバーヘッドが最小 |
| バッチ書き込み |
NanaSQLite batch_update
|
sqlite3のexecutemanyより1.4倍速 |
| 読み取り(頻繁なアクセス) | NanaSQLite | キャッシュで最大730倍速 |
| 読み取り(大量・初回) |
NanaSQLite bulk_load=True
|
全ロードで以降の読み取りが最速 |
| 型付きデータ | NanaSQLite + Pydantic | モデルのまま保存・復元できる |
おわりに
「SQLiteが遅い」のではなく「使い方が遅い」——この一言に尽きます。
特にシングル書き込みのループは、件数が増えるほど致命的です。100件以上を扱うなら、バッチ書き込みへの切り替えを強く推奨します。
NanaSQLiteは読み取りとバッチ処理に特化した設計になっており、「サクッとデータを永続化してあとは高速に読みたい」というユースケースに最もフィットします。
pip install nanasqlite
🔗 公式サイト: https://nanasqlite.disnana.com/
🐙 GitHub: https://github.com/disnana/nanasqlite