はじめに
LangChainで初めてRAGシステムを完成させた時のアウトプットを記事にしました。
対象読者
- RAGに関する最低限の知識があるけど、実装方法のイメージがつかない人
- LangChainについてこれから学習する人
- LangChainの勉強始めたけど複雑でよくわからなくなってきた人
- 勉強したこと全部忘れた来週の僕
作成したRAGの概要
社内ドキュメントなどの非公開ファイルをシステムにアップロードして、その内容について質問を投げると回答してくれるAI
今回はNaive RAGと呼ばれるもっともシンプルな構成ですので、精度が高いとは言えませんがRAGとして機能はします。
質問入力 → 検索 → 回答生成 → 出力
構成
AWSを使用しました。
- Lambda
- 一連の処理を実行
- S3
- ファイルのアップロード先
- Open Search
- ベクトルデータベース
- S3のデータをベクトル化したものを格納(S3と同期した状態)
- Bedrock Knowledge Base
- インデックス生成
- 検索
- 指定したLLMモデルによる回答文の生成
準備
-
S3を作成
-
S3のバケットポリシーにシステムからのアクセス権限("s3:GetObject","s3:PutObject","s3:ListBucket")を付与
-
Bedrockのコンソール画面からKnowledgeBaseを作成
- 作成したS3を紐付け
- ベクトルデータベースにOpen Searchを選択
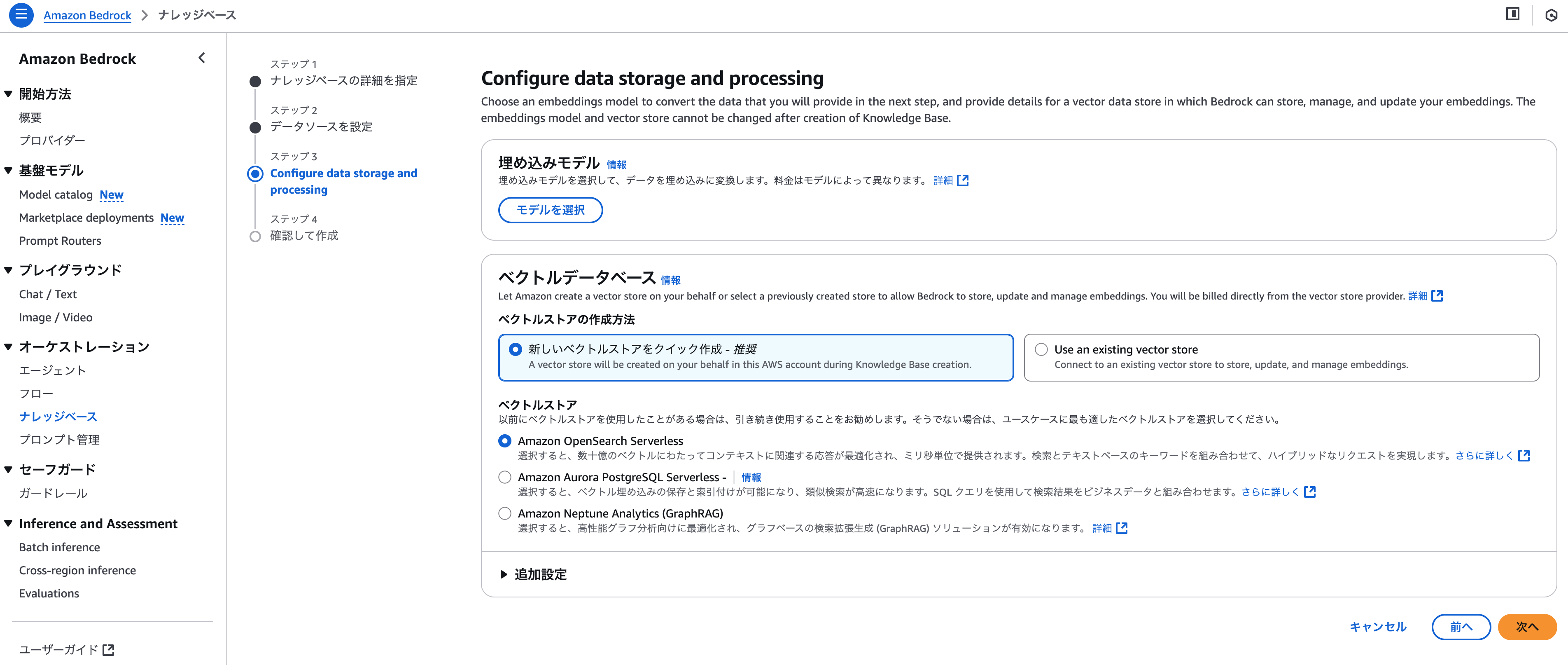
-
ナレッジベースIDを確認(後で使用)
RAG実装
RAG検索と回答生成の部分のコードを上から順にまとめます。
LLMモデルを定義
BedrockのClaudeモデルを使用するために、ChatBedrockConverseを使用しました。
ChatBedrockConverseの公式APIリファレンス
llm = ChatBedrockConverse(
model="apac.anthropic.claude-3-5-sonnet-20241022-v2:0",
region="ap-northeast-1", # 東京リージョン
temperature=0.1, # 低い値でより決定論的な応答を生成
max_tokens=4096, # 最大トークン数
maxRetries=2, # エラー時の再試行回数
verbose="true", # 詳細なログ出力
)
同じようにLLMを定義するものとしてChatBedrockもありますが、こちらと比較してChatBedrockConverseは、インターフェースが標準化されていてストリーミング応答などできることが多いみたいです知らんけど。
プロンプトを定義
今回は会話(チャット)形式でメッセージのやり取りをするため、過去の会話履歴を都度渡す必要があります。
ユーザには見えないシステムプロンプトと、ユーザが入力したメッセージであるユーザプロンプトを設定します。
prompt = ChatPromptTemplate.from_messages([
("system", "以下のコンテキスト情報を使って質問に答えてください。\n\nコンテキスト: {context}"),
("user", "(1つ目の質問)"),
("assistant", "(1つ目の回答)"),
("user", "{question}") # questionは2つ目の質問が入る変数
])
もしチャット形式ではない場合、以下のようにPromptTemplateを使用できます。
prompt = PromptTemplate.from_template("以下の食材でレシピを考えてください。食材: {ingredient}")
{ingredient}の部分は変数として設定できます。この場合、実行時に引数として渡します。
リトリーバを定義
RAG検索を実行するリトリーバの設定をします。
こいつがRAGの核となる部分です。
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="(ナレッジベースID)", # ここで検索先を指定
region_name="ap-northeast-1",
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 10 # 検索結果の件数
}
},
)
Chainの定義
ここでLangChainの真骨頂、チェーンを作ります。
これまで定義した各クラスをひと繋がりの処理にまとめます。
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
RunnablePassthroughは入力値をそのまま出力させる役割があります。質問と一緒に回答を出力させるときに使えます。
StrOutputParserは出力のテキスト部分を抽出してくれるものなので使うことが多そうです。
Chainの実行
あとは実行するだけ
result = chain.invoke({"question": "社内規定について教えてください"})
おわり
思いの外あっさりできました。
やはりAWSとLangChainが優秀ですね。
実際はこのままだと精度が不安なので、検索前と後に整形やフィルター処理などをいれたいです。