S3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
はじめに
以下リンク記事を参考に、S3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしをやってみたのでまとめておきます。
S3 + ElasticTranscoder + Lambda + Google Cloud Speech-to-Text APIで、動画の音声を自動でテキストにする
👆完全なる上位互換なので、私の記事は読む必要ないかと。
1. S3の作成
特別なことはしないです。
1-1. 適当なバケット名、リージョン(私は東京)で次へ
1-2. オプションの設定はノータッチ
1-3. アクセス許可の設定もノータッチ(パブリックアクセスをすべてブロック)
1-4. 確認
2. ローカルでGoogle Cloud Speech-to-Text APIをインストール
Google Cloud Speech-to-Text APIを使うため、npmを使ってローカルでインストールします。
後ほどlayerとしてlambdaに追加するため、ディレクトリ名はnodejsにしてください。
mkdir nodejs
cd nodejs
npm init
npm install @google-cloud/speech
node_modulesが入ったnodejsフォルダをzip(nodejs.zip)にしておきましょう。
3. Lambda layerの作成
先ほど作成したzipファイルをlayerとしてlambdaに追加します。
3-1. Lambdaのレイヤー画面からレイヤーの作成へ
3-2. 適当な名前、説明
3-3. zipファイルをアップロード
3-4. ランタイムはご自身のNode.jsのバージョンで選択(私は10.x)
4-5. 作成
4. Google Cloud Speech-to-Textのサービスアカウントを取得
lambda関数に配置するための、サービスアカウントキーをJSON形式で取得します。
4-1. GCPのAPIとサービス内のCloud Speech-to-Textへ
4-2. APIを有効化する
4-3. 認証情報で「+認証情報を作成」、サービスアカウントを選択し、サービスアカウントを作成
4-4. 作ったら鍵の追加をして、JSON形式の秘密鍵を取得
5. lambda関数の作成
5-1. 関数の作成に行き、適当な名前、ランタイム(私はNode.js 10.x)を選択して作成
5-2. アクセス権限に移動し、実行ロールを選択する
5-3. S3にアクセスするポリシーをアタッチする(とりあえずAmazonS3FullAccess)
5-4. lambdaに戻ってトリガーを追加へ移動し、S3で作成したバケットを選択
5-5. 3で作成したlayerを追加(ランタイムが一致してないと出てこないので注意)
5-6. 4で作成したサービスアカウント情報を追加するため、関数コードのところで、JSONファイルを作成
5-7. ここに4でダウンロードしてきた秘密鍵JSONファイルの情報をコピペ(githubのpublic repoとかに上げないように注意!)
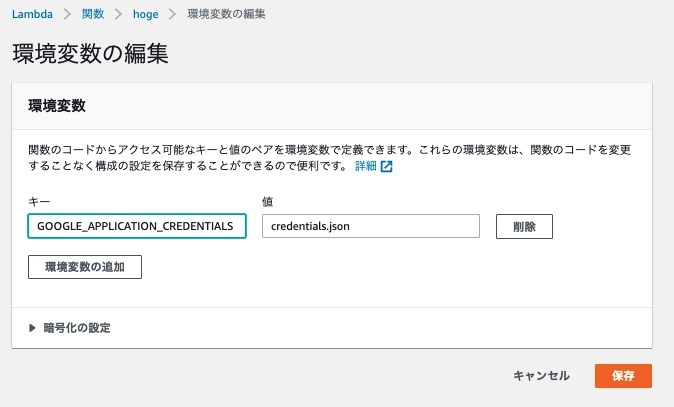
5-8. credientials.jsonを環境変数に追加
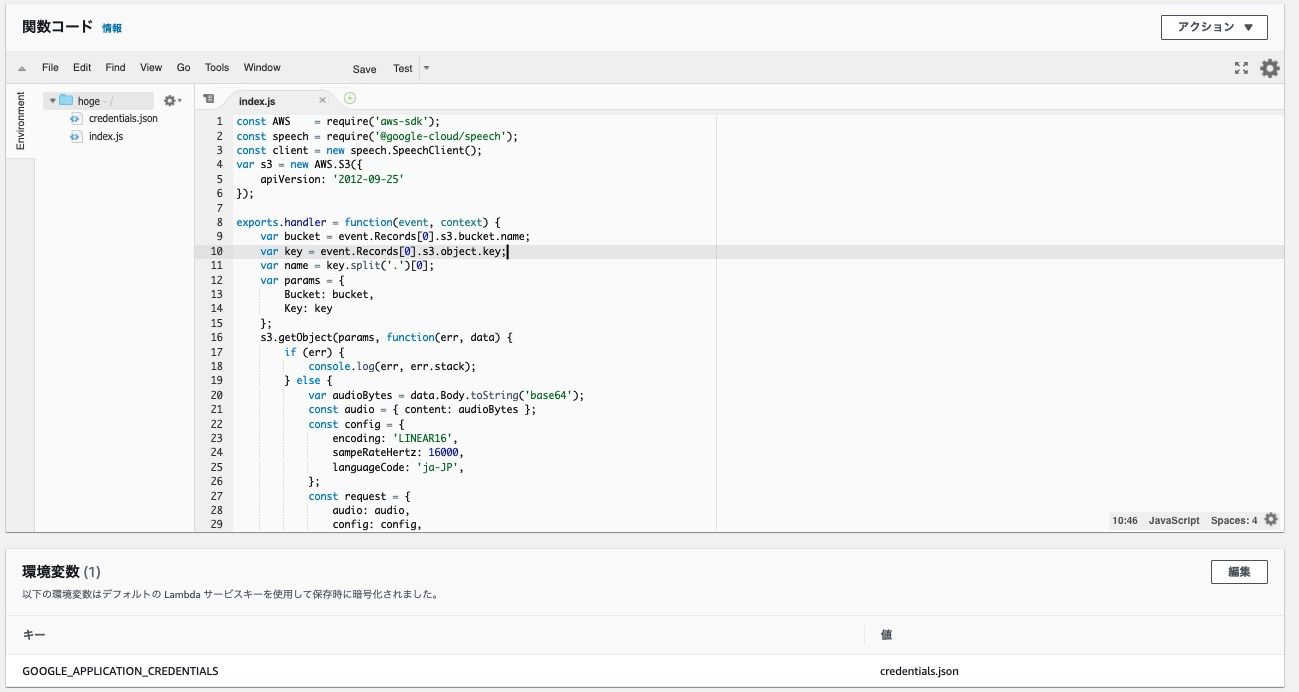
5-9. コードはこちらのコードを拝借しています。少し変えているので以下に貼っておきます。
const AWS = require('aws-sdk');
const speech = require('@google-cloud/speech');
const client = new speech.SpeechClient();
var s3 = new AWS.S3({
apiVersion: '2012-09-25'
});
exports.handler = function(event, context) {
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
var name = key.split('.')[0];
var params = {
Bucket: bucket,
Key: key
};
s3.getObject(params, function(err, data) {
if (err) {
console.log(err, err.stack);
} else {
var audioBytes = data.Body.toString('base64');
const audio = { content: audioBytes };
const config = {
encoding: 'LINEAR16',
sampeRateHertz: 16000,
languageCode: 'ja-JP',
};
const request = {
audio: audio,
config: config,
};
client.recognize(request).then(
data => {
const response = data[0];
const transcription = response.results.map(
result => result.alternatives[0].transcript
).join('\n');
console.log(name);
console.log(transcription);
}).catch(err => {
console.error('ERROR:', err);
}
);
};
});
}
最終的にはこんな感じかと↓
結果
console.log(transcription);で出力してるtranscriptionに文字起こし結果が入ってます。cloudwatch logで確認してみてください。
最後に
参考記事の劣化版みたいな記事になってしまいましたが、備忘録として書かせていただきました。
劣化版なりの改良点としは以下です。
- node_modulesも一緒にzipにして、関数コードに入れようとしたがうまくいかなかったのでlayerから入れた(nodejsというファイル名にするの注意ですね)
- 環境変数としてサービスアカウントの情報を追加する手順の追加
- ソースコードの簡易化と修正
間違い等ある場合はぜひコメントください。
次回はmp3の文字起こしをやってみたいと思います。
→(2020/06/30 追記)S3に保存されたMP3ファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
参考
S3 + ElasticTranscoder + Lambda + Google Cloud Speech-to-Text APIで、動画の音声を自動でテキストにする