前段
Gaiax Group Advent Calendar 2018の15日目の記事です。
Google Cloud Speech-to-Text API、使ったことありますか?
マイクに向かってしゃべると、テキストにしてくれるヤツです。
google docsでも音声入力でテキストを入れてくれますね。
とても便利です。
さて、音声入力を使いたいシーンはいくつかあると思います。
会議だったり電話だったり。
議事録取るのは大変ですし、電話で何を言ったかの記録を録音で残していても検索しにくいですしね。
では、それぞれ使いたいシーンでテキスト化の精度は変わってくるのでしょうか。
変わってくるんじゃないかと思いますよね。
静かに丁寧に進む会議もあれば、議論が白熱して紛糾する会議だってあります。
一人一人交互に話す電話。でも間に相槌を入れられる。その時音声が重複しているときも正しく認識してくれるだろうか。
実務で使う前に、精度をちょっと見てみようという話になりました。
その際に組んだAWS上でのアーキテクチャについて、ここで書こうと思います。
テキスト化の精度についての話はしません。
最初のやりかた
社内で用意したデータが、社内研修で定期的に閲覧される研修動画。
まずはこれのテキスト化がどうかをチェックしました。
ローカルで動画ファイル(mp4)を音声(wav)に変換。
Google Cloud Speech-to-Text APIは、ファイルアップロードの場合は1分以内という制限があるため、wavを1分おきに分割。
APIに投げてレスポンスを受け取る。
でもこれ、動画ファイルを音声に変換するのも、1分おきに分割するのが面倒くさい。
ならば自動化だ
- S3 bucketsに動画ファイルをアップロード
- イベント検知してLambda(1)が動画ファイルを1分おきに分割して、S3 bucketsに設置
- イベント検知してLambda(2)が分割された動画ファイルをwavに変換して、S3 bucketsに設置
- イベント検知してLambda(3)が、Google Cloud Speech-to-Text APIにファイルを投げて、テキストデータのレスポンスを格納する
動画ファイルをぽんと置くだけで、そのあとは自動でテキストデータになってくれる。
最強。
準備
- S3 bucketを下記3パターンで用意
- 動画を置く場所
- 分割された動画を置く場所
- 変換されたwavを置く場所
Lambda(1) 動画ファイル分割
動画を分割するには、ElasticTranscoderを使います。
指定したフォーマットに変換するサービスなのですが、動画配信でよく利用されるHLSのフォーマットにも変換が可能です。
HLSは、指定の時間で動画を分割したtsファイルと、プレイリストファイルm3u8からなるフォーマットのことです。
このうちtsファイルはmpeg2ですので、この後の(2)の処理も問題ありませんでした。
ElasticTranscoder
Pipeline作成
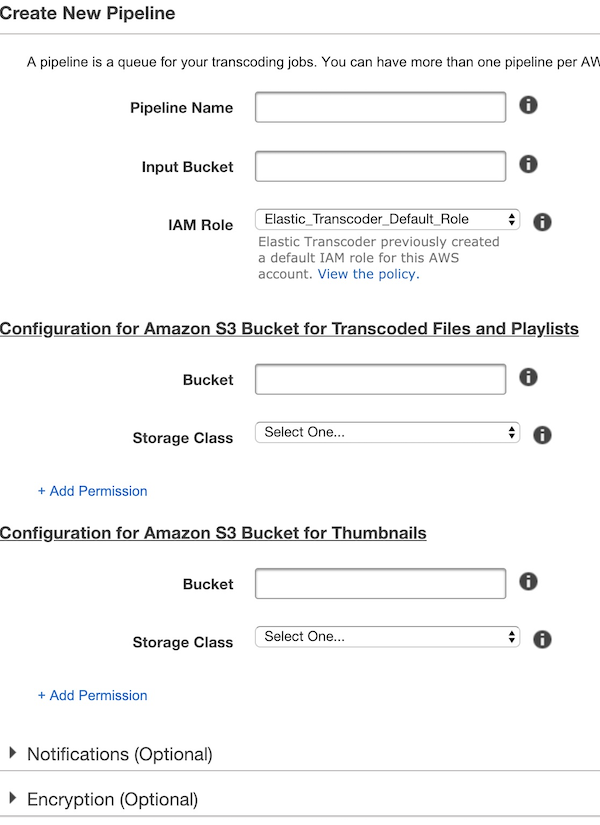
- Pipeline Name
- 適当な名前
- Input Bucket
- 動画ファイルを設置するS3 Bucketを選択
- IAM Role
- デフォルトでOK
- Configuration for Amazon S3 Bucket for Transcoded Files and Playlists
- Bucket
- 分割された動画を置くS3 Bucketを選択
- Storage Class
- Standard
- Bucket
- Configuration for Amazon S3 Bucket for Thumbnails
- サムネイルを置く場所だが今回は使用しない。とはいえ設定だけはしておく
- Bucket
- 分割された動画を置くS3 Bucketを選択
- Storage Class
- Standard
Lambda関数
難しくない内容なので、AWSコンソール上でOK。
'use strict';
var AWS = require('aws-sdk');
var s3 = new AWS.S3({
apiVersion: '2012-09-25'
});
var util = require('util');
var transcoder = new AWS.ElasticTranscoder({
apiVersion: '2012-09-25',
region: 'ap-northeast-1'
});
exports.handler = function(event, context) {
console.log("START!!");
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
var pipelineId = '{{ pipelineId }}'; // ←作成したパイプラインID
var HLSpresetId = '1351620000001-200030'; // ←ElasticTranscoderにすでにあるプリセットを利用する。これはHLS 1Mのプリセット。
var srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));
var newKey = key.split('.')[0];
var params = {
PipelineId: pipelineId,
Input: {
Key: srcKey,
FrameRate: 'auto',
Resolution: 'auto',
AspectRatio: 'auto',
Interlaced: 'auto',
Container: 'auto'
},
Outputs: [{
Key: newKey,
SegmentDuration: "50", // ← 分割する秒数。60秒きっかりではなく余裕持って50秒にした。
Rotate: 'auto',
PresetId: HLSpresetId,
}]
};
transcoder.createJob(params, function(err, data){
if (err){
console.log('Error');
console.log("(´・ω・`)" + util.inspect(err, false, null));
} else {
console.log('Success');
}
});
};
S3 bucketのイベントからLambdaが起動するよう設定する
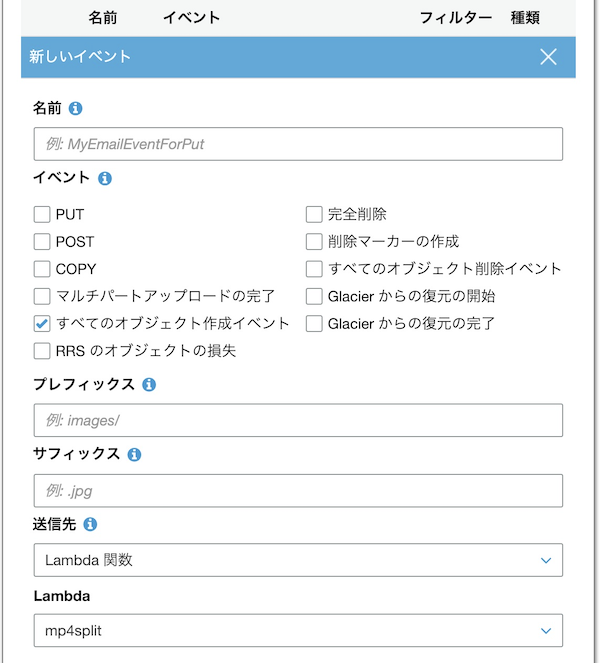
「すべてのオブジェクト作成イベント」にチェック。
送信先に作成したLambda関数を選択する。
実際に、S3 bucketにファイルを設置してみて、tsファイルが作成されていればOK!
Lambda(2) 動画を音声ファイルに変換
分割されたtsファイルを音声に変換します。
これもElasticTranscoderを使います。
ElasticTranscoder
(1)と同じようにパイプラインを作成。
Lambda関数
'use strict';
var AWS = require('aws-sdk');
var s3 = new AWS.S3({
apiVersion: '2012-09-25'
});
var util = require('util');
var transcoder = new AWS.ElasticTranscoder({
apiVersion: '2012-09-25',
region: 'ap-northeast-1'
});
exports.handler = function(event, context) {
console.log("START!!");
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
var pipelineId = '{{ PipelineID }}'; // ← 作成したパイプラインID
var wavPresetId = '1351620000001-300200'; // ← wav変換するプリセット
var srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));
var newKey = key.split('.')[0];
var params = {
PipelineId: pipelineId,
Input: {
Key: srcKey,
FrameRate: 'auto',
Resolution: 'auto',
AspectRatio: 'auto',
Interlaced: 'auto',
Container: 'auto'
},
Outputs: [{
Key: newKey + '.wav',
PresetId: wavPresetId,
}]
};
transcoder.createJob(params, function(err, data){
if (err){
console.log('Error');
console.log("(´・ω・`)" + util.inspect(err, false, null));
} else {
console.log('Success');
}
});
};
S3 bucketのイベントからLambdaが起動するよう設定する
これも(1)と同じカタチでOK!
Lambda(3) 音声ファイルをテキストに変換
最後は音声ファイルをGoogle Cloud Speech-to-Text APIに投げて返ってきたデータを格納するだけです。
GoogleのAPIを使うため、ライブラリとGCPのcredential情報をLambdaに含める必要があります。
以下Node.jsで用意します。
まず、 npm init して @google-cloud/speech をnpmで入れます。
またGCPで作成したGoogle Cloud Speech-to-Text APIを有効化したサービスアカウントキーのJSONファイルを設置します。
app
│ index.js
│ client_secret.json
│ package.json
└─ node_modules
(内容省略)
const AWS = require('aws-sdk');
const fs = require('fs');
const speech = require('@google-cloud/speech');
const client = new speech.SpeechClient();
var s3 = new AWS.S3({
apiVersion: '2012-09-25'
});
var util = require('util');
exports.handler = function(event, context) {
console.log("START!");
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
var name = key.split('.')[0];
var params = {
Bucket: bucket,
Key: key
};
s3.getObject(params, function(err, data) {
if (err) {
console.log(err, err.stack);
} else {
var audioBytes = data.Body.toString('base64');
const audio = { content: audioBytes };
const config = {
encoding: 'LINER16',
sampeRateHertz: 16000,
languageCode: 'ja-JP',
};
const request = {
audio: audio,
config: config,
};
client.recognize(request).then(
data => {
const response = data[0];
const transcription = response.results.map(
result => result.alternatives[0].transcript
).join('\n');
console.log(name);
console.log(transcription);
var params = {
Bucket: bucket,
Key: name + ".txt",
Body: transcription,
ContentType: "text/plain"
};
s3.putObject(params, function(err, data){
if (err) console.log(err, err.stack);
});
}).catch(err => {
console.error('ERROR:', err);
}
);
};
});
}
app.zipで固めて、Lambdaにアップロード。
あとはwavが設置されるbucketで、(1),(2)同様に、イベントからLambdaが起動するように設定しましょう。
(1)〜(3)が連続して起動して、wav設置bucketにtxtファイルが作られていきます。
結果
時短できて、色んなパターンの動画・音声をテキストにすることが出来ました。
ただGoogle Cloud Speech-to-Text APIの、テキスト化精度の点では、専門用語や口語にはまだ弱いのか、キレイなテキストにならず、修正が必要でした。
あと、実際にこれら取り組んだのが少し前で、記憶も少し正確ではないので、間違っている部分などあるかもしれません。
細かい部分間違いあればご指摘ください。
以上。
余談
処理失敗した際の処理はココには含まれていません。
Lambda(1),(2)は、ElasticTranscoderのJobを投入する役割なので、ElasticTranscoder側でオチた場合はElasticTranscoder側で拾う必要があります。オチた際はSNSに通知を投げる仕組みがあるので、そこから拾い上げる形が想定されます。
またElasticTranscoderのJob同時起動上限は100。Lambdaも起動上限があるため、ガチで大量に処理させる場合は注意。
S3のイベント検出は数万回に一回漏れることがあるらしいです。(噂)
処理できていない箇所を拾い上げてリトライさせるなどの仕組みが必要です。