1. はじめに
みなさん、こんにちは。前回までは、Hugging Faceに公開されているIBM Granite Time Series Modelを使った時系列予測の紹介をしました。
今回からは、Watsonx.ai上に公開されているモデルをAPI経由で呼び出して時系列予測をしてみようと思います。
GitHubに今回利用しているストリームとPythonシンタックスをアップロードしています。
ご自由にダウンロードしてください。
※. Watsonx.aiのAPI KEY等の情報は削除していますので、みなさんのAPI KEY等をご利用ください。
2. 準備
2.1 IBM CloudのID取得
以下のサイトを参考にIBM CloudのIDを取得してください。
以下は、Google AccountでのIBM Cloud IDを作る方法が紹介されています。
サービス等を利用する場合は、無料のフリープランで問題ありませんが、ユーザー登録時にクレジットカード情報等を登録する必要があるので、気軽に利用しようと思っている方にはちょっとハードルが高いんですよね。
2.2 IBM Cloudのサービス利用準備
以下のサイトを参考にして、
・APIキー
・watsonx.ai Runtimeが関連付けられた「プロジェクト ID」
・watsonx.ai Runtimeの「サービス・エンドポイント」
を取得してください。
これらの情報がないとAPIを呼び出すことができません。これらの内容は一度経験しておくと、その他のサービスを利用する時にも応用できるのでやってみることをお勧めします。
なんといっても、モデルを簡単にデプロイしてREST APIで利用できる環境をすぐに構築できることは本当に便利です。
わたしは、Watsonx.ai Studioで作成したAuto AIモデルをREST APIで利用したりしています。
2.3 IBM Watsonx.ai ライブラリの導入
Watsonx.aiの最新のライブラリを導入しましょう。
C:\Program Files\IBM\SPSS\Modeler\18.6\python_venv\Scripts>python.exe -m pip install -U ibm-watsonx-ai
ちなみに、2025-07-23日の時点では、最新バージョンは v1.3.31 となっています。
C:\Program Files\IBM\SPSS\Modeler\18.6\python_venv\Scripts>python.exe -m pip show ibm-watsonx-ai
Name: ibm_watsonx_ai
Version: 1.3.31
Summary: IBM watsonx.ai API Client
Home-page:
Author: IBM
Author-email:
License: BSD-3-Clause
Location: c:\program files\ibm\spss\modeler\18.6\python_venv\lib\site-packages
Requires: cachetools, certifi, httpx, ibm-cos-sdk, lomond, packaging, pandas, requests, tabulate, urllib3
Required-by:
2.4 データの準備
データは、前回まで使用してきた Hugging Face にあるスペインのエネルギーデータです。
energy_dataset.csvをダウンロードしてください。
3. Granite Time Series ・ Watsonx.ai APIの簡単な説明
今回は、Hugging Faceからダウンロードしたモデルではなく、Watsonx.ai上のモデルを利用します。ちょっとだけ仕様が異なるので簡単に利用方法を確認しておきましょう。
3.1 事前にAPI KEYなどを準備
準備の項でも言及していますが、IBM Cloud IDや、Watsonx.aiの各種サービスの準備が事前に必要となります。
そのうえで、API KEYなどを使う設定をする必要があります。
#-----------------------------------------------
# API Key などの準備
#-----------------------------------------------
WATSONX_APIKEY = "YOUR API KEY"
WATSONX_PROJECT_ID = "YOUR PROJECT ID"
WATSONX_URL = "YOUR ENDPOINT URL"
#-----------------------------------------------
# Watsonx.ai ランタイムへの接続情報設定
#-----------------------------------------------
# watsonx.aiランタイムへの接続情報を定義
credentials = Credentials(
url = WATSONX_URL,
api_key = WATSONX_APIKEY,
)
# 接続情報の設定
# クレデンシャルのセット
client = APIClient(credentials)
# プロジェクトのセット
client.set.default_project( WATSONX_PROJECT_ID )
3.2 パラメータ設定
モデルに渡すパラメータ設定が必要です。ここは、Hugging Faceのモデル利用時と同じですね。
ただ、Watsonx.ai上のモデルでは、Fine-TuningはできずZero-Shotモデルのみが利用可能なため、シンプルな設定となりますね。
#-----------------------------------------------
# モデル用パラメータ定義
#-----------------------------------------------
# モデル用パラメータの指定
forecasting_params = TSForecastParameters(
id_columns=[], # 複数系列を識別するためのID(今回は1系列なので空)
timestamp_column=timestamp_column, # 時間
freq="1h", # 1時間単位
target_columns=target_columns, # 予測対象("total load actual")
prediction_length=prediction_length, #予測する長さ <96レコード先まで予測>
)
3.3 モデルの実行
使うモデルと接続情報を使ってインスタンス化します。
そして、forecast()でモデルを実行します。
#-----------------------------------------------
# モデルの実行 - APIで実行
#-----------------------------------------------
#モデルの指定
ts_model_id = client.foundation_models.TimeSeriesModels.GRANITE_TTM_512_96_R2
# モデルインスタンスの初期化と設定
ts_model = TSModelInference(model_id=ts_model_id, api_client=client)
# Watsonx.ai Granite TimeSeries の実行 <予測用データ> - 512レコードを入力して96レコードを予測
results = ts_model.forecast(data=train_data, params=forecasting_params)['results'][0]
3.4 結果の取得
モデルの実行結果ですが、Hugging Faceの時とはちょっと異なります。
Hugging Faceの場合は、Pipelineの実行後に以下のように結果が戻されます。
自動生成されるtarget_predictionカラムに予測した結果がリストで格納されています。
また、targetカラムには、予測対象のデータが上書されて予測結果と対になる実績値がリストで格納されます。
| time | target_prediction | target |
|---|---|---|
| 2018-05-14 16:00:00 | 29782, 29904, 30401 | 29422, 28956, 28988 |
| 2018-05-14 17:00:00 | 29811, 30104, 30893 | 28956, 28988, 29499 |
| 2018-05-14 18:00:00 | 29871, 30471, 30949 | 28988, 29499, 30870 |
Watsonx.ai APIの場合は、forecast実行後に以下のように結果が戻されます。
リストではなく、未来の時系列レコードが生成されてtargetカラムに予測結果が格納されます。
target_predictionカラムは生成されません。
| time | target |
|---|---|
| 2018-05-14 16:00:00 | 29782 |
| 2018-05-14 17:00:00 | 29811 |
| 2018-05-14 18:00:00 | 29871 |
Hugging Faceの時は各レコード毎に予測結果が格納されていました。
2018-05-14 16:00:00のレコードには、2018-05-14 17:00:00以降の予測値がリストになっています。
2018-05-14 17:00:00のレコードなら、2018-05-14 18:00:00以降の予測値がリスト。。という感じです。
Watsonx.ai APIの場合は、リスト形式ではありません。
上記の例だと、2018-05-14 15:00:00以前のレコードまでを入力として、2018-05-14 16:00:00以降のレコードを自動生成し予測値を各レコード毎に格納しているのです。
4. モデルを実行して予測精度を確認する
準備とモデルについて簡単な理解がすんだら、今回もSPSS Modelerの拡張ノードを使って実装していきましょう。
4.1 ストリーム全体
以下が、ストリームの全体になります。
今回は、赤枠で囲った部分を説明していきます。
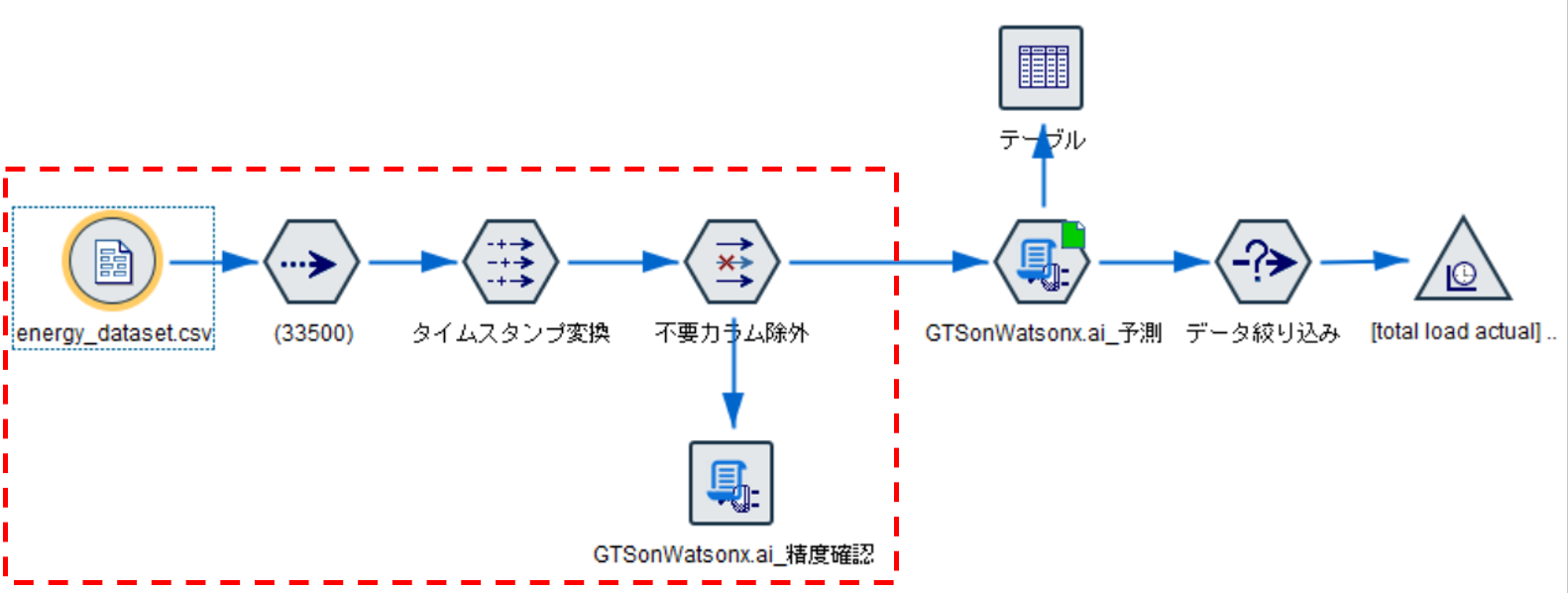
4.2 データ入力から不要カラム削除まで
以下の記事を参考にして実装してみてください。
サンプリングノードでの除外するレコード数が異なるだけでまったく一緒です。
レコード数を絞っていますが、APIを使ってZero-Shot予測するので、多くは必要ないのです。
4.3 Granite Time Series Model Watsonx.ai版の精度確認
続いて拡張ノードで実装していきます。
4.3.1 シンタックス全体
まずは、以下がシンタックス全体になります。
#-------------------------------------------------
# IBM Granite Time Series ( Tiny Time Mixer )
# Watsonx.ai 上の Granite Time Series を利用
# 精度確認用シンタックス - Python版
#-------------------------------------------------
#-----------------------------------------------
# ライブラリインポート
#-----------------------------------------------
# Modeler用ライブラリ
import modelerpy
# すべての警告を無視
import warnings
warnings.filterwarnings("ignore")
# Pandas & Numpy
import numpy as np
import pandas as pd
import pprint
# scikit-learn - MAPE計算用
from sklearn.metrics import mean_absolute_percentage_error
# IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai import APIClient
from ibm_watsonx_ai import Credentials
# Granite Time Series Model on IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai.foundation_models import TSModelInference
from ibm_watsonx_ai.foundation_models.schema import TSForecastParameters
#-----------------------------------------------
# API Key などの準備
#-----------------------------------------------
WATSONX_APIKEY = "YOUR API KEY"
WATSONX_PROJECT_ID = "YOUR PROJECT ID"
WATSONX_URL = "https://jp-tok.ml.cloud.ibm.com"
#-----------------------------------------------
# Watsonx.ai ランタイムへの接続情報設定
#-----------------------------------------------
# watsonx.aiランタイムへの接続情報を定義
credentials = Credentials(
url = WATSONX_URL,
api_key = WATSONX_APIKEY,
)
# 接続情報の設定
# クレデンシャルのセット
client = APIClient(credentials)
# プロジェクトのセット
client.set.default_project( WATSONX_PROJECT_ID )
#-----------------------------------------------
# Watsonx.ai で利用できるモデルの確認
#-----------------------------------------------
for model in client.foundation_models.get_time_series_model_specs()["resources"]:
pprint.pp("--------------------------------------------------")
pprint.pp(f'model_id: {model["model_id"]}')
pprint.pp(f'functions: {model["functions"]}')
pprint.pp(f'long_description: {model["long_description"]}')
pprint.pp(f'label: {model["label"]}')
#-----------------------------------------------
# データ入力
#-----------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
#-----------------------------------------------
# カラム定義
#-----------------------------------------------
# タイムスタンプカラム定義
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
#-----------------------------------------------
# モデルで使用するカラムの指定
#-----------------------------------------------
# 予測対象カラムをリストで定義
target_columns = [ target_column ]
# 時系列カラム"time"を文字列型に変更
# Watsonx の裏側では、HTTP リクエストを通じてモデルにデータを渡すため、
# JSON形式に変換可能なデータ(文字列、数値、配列など)しか渡せません。
input_df[ timestamp_column ] = input_df[ timestamp_column ] .astype(str)
#-----------------------------------------------
# モデルの学習・予測レコード数定義
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# 予測対象("total load actual")
prediction_length = 96 # the max forecast length for the 512-96 model
#-----------------------------------------------
# モデルの予測・検証用データの準備
#-----------------------------------------------
# 精度検証用データ - 最後から96レコードを検証用にとっておく
future_data = input_df.iloc[-prediction_length:,]
# 予測用データ - 最後から96レコードを除いた512レコードをモデルに投入
train_data = input_df.iloc[-context_length-prediction_length:-prediction_length,]
#-----------------------------------------------
# モデル用パラメータ定義
#-----------------------------------------------
# モデル用パラメータの指定
forecasting_params = TSForecastParameters(
id_columns=[], # 複数系列を識別するためのID(今回は1系列なので空)
timestamp_column=timestamp_column, # 時間
freq="1h", # 1時間単位
target_columns=target_columns, # 予測対象("total load actual")
prediction_length=prediction_length, #予測する長さ <96レコード先まで予測>
)
#-----------------------------------------------
# モデルの実行 - APIで実行
#-----------------------------------------------
#モデルの指定
ts_model_id = client.foundation_models.TimeSeriesModels.GRANITE_TTM_512_96_R2
# モデルインスタンスの初期化と設定
ts_model = TSModelInference(model_id=ts_model_id, api_client=client)
# Watsonx.ai Granite TimeSeries の実行 <予測用データ> - 512レコードを入力して96レコードを予測
results = ts_model.forecast(data=train_data, params=forecasting_params)['results'][0]
#-----------------------------------------------
# 予測精度の確認
#-----------------------------------------------
# 予測結果をデータフレームに取り込み - 予測した96レコードが格納されている。
watsonx_gts_forecast = pd.DataFrame(results)
#最後 検証用にとっておいた 96レコードと予測した96レコードでMAPEを計算
mape = mean_absolute_percentage_error(future_data[target_column], watsonx_gts_forecast[target_column]) * 100
print("mape = ", mape)
4.3.2 シンタックス詳細
では、詳細をパート毎にみていきましょう。
4.3.2.1 ライブラリインポート
ここでは、必要なライブラリをインポートしています。
Watsonx.aiのライブラリはAPIで呼び出す際に必要になるので忘れずに。
#-----------------------------------------------
# ライブラリインポート
#-----------------------------------------------
# Modeler用ライブラリ
import modelerpy
# すべての警告を無視
import warnings
warnings.filterwarnings("ignore")
# Pandas & Numpy
import numpy as np
import pandas as pd
import pprint
# scikit-learn - MAPE計算用
from sklearn.metrics import mean_absolute_percentage_error
# IBM watsonx.ai ライブラリ
from ibm_watsonx_ai import APIClient
from ibm_watsonx_ai import Credentials
# Granite Time Series Model on IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai.foundation_models import TSModelInference
from ibm_watsonx_ai.foundation_models.schema import TSForecastParameters
4.3.2.2 APIで必要になる設定
次にAPIを呼び出す際に必要な設定を定義しています。
API KEY、PROJECT ID、エンドポイントURL はみなさんが取得したものを指定しましょう。
URLに関しては、東京リージョンにプロジェクトを設定している場合は私のものと同じだと思います。
#-----------------------------------------------
# API Key などの準備
#-----------------------------------------------
WATSONX_APIKEY = "YOUR API KEY"
WATSONX_PROJECT_ID = "YOUR PROJECT ID"
WATSONX_URL = "https://jp-tok.ml.cloud.ibm.com"
#-----------------------------------------------
# Watsonx.ai ランタイムへの接続情報設定
#-----------------------------------------------
# watsonx.aiランタイムへの接続情報を定義
credentials = Credentials(
url = WATSONX_URL,
api_key = WATSONX_APIKEY,
)
# 接続情報の設定
# クレデンシャルのセット
client = APIClient(credentials)
# プロジェクトのセット
client.set.default_project( WATSONX_PROJECT_ID )
4.3.2.3 利用できるモデルの確認
APIで呼び出せるモデルを確認できます。
利用したいモデルを確認しましょう。
#-----------------------------------------------
# Watsonx.ai で利用できるモデルの確認
#-----------------------------------------------
for model in client.foundation_models.get_time_series_model_specs()["resources"]:
pprint.pp("--------------------------------------------------")
pprint.pp(f'model_id: {model["model_id"]}')
pprint.pp(f'functions: {model["functions"]}')
pprint.pp(f'long_description: {model["long_description"]}')
pprint.pp(f'label: {model["label"]}')
以下のように出力されます。
・granite_ttm_512_96_r2
・granite_ttm_1024_96_r2
・granite_ttm_1536_96_r2
の3つが利用可能ですね。
これはHugging Faceのモデルと一緒ですね。
512や1024という数字は、学習データで何レコード必要かを意味しています。
96という数字は、予測する際に何レコード分の予測をするかを意味しています。
なので、
granite-ttm-512-96-r2は、
512レコードを使って、96レコード分未来の予測をするモデルになります。

4.3.2.4 データ入力・カラム定義
データをModelerから受け取り、モデルで使用するカラムの定義をします。
ここは、前回までのものとほぼ同じですね。
ちょっと違うのは、予測値を格納するカラム (XX_prediction) を定義していません。
XX_predictionは生成されず、予測値は予測対象のカラムに格納されるためです。
また、APIを呼び出す時にデータはJSON形式に変換可能なものである必要があります。
Hugging Faceモデルの時は、時系列カラムのデータをtime stump型で渡せたものが、APIでは文字列型にして渡す必要があります。
#-----------------------------------------------
# データ入力
#-----------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
#-----------------------------------------------
# カラム定義
#-----------------------------------------------
# タイムスタンプカラム定義
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
#-----------------------------------------------
# モデルで使用するカラムの指定
#-----------------------------------------------
# 予測対象カラムをリストで定義
target_columns = [ target_column ]
# 時系列カラム"time"を文字列型に変更
# Watsonx の裏側では、HTTP リクエストを通じてモデルにデータを渡すため、
# JSON形式に変換可能なデータ(文字列、数値、配列など)しか渡せません。
input_df[ timestamp_column ] = input_df[ timestamp_column ] .astype(str)
4.3.2.5 データの準備
モデルに渡すためのデータを準備します。
モデルについて学習に使うレコード数と、予測レコード数を定義します。
★使用するモデルについて
・512レコードを学習データとして使用
・96レコード先の予測を実施
その定義に沿った学習データとテストデータを準備しています。
★使用データについて
・データの最後から96レコードを検証用として指定
・検証用レコードを除き512レコードを学習用として指定
こんなイメージです。
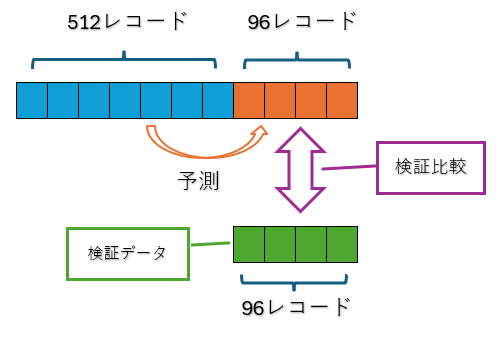
#-----------------------------------------------
# モデルの学習・予測レコード数定義
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# 予測対象("total load actual")
prediction_length = 96 # the max forecast length for the 512-96 model
#-----------------------------------------------
# モデルの予測・検証用データの準備
#-----------------------------------------------
# 精度検証用データ - 最後から96レコードを検証用にとっておく
future_data = input_df.iloc[-prediction_length:,]
# 予測用データ - 最後から96レコードを除いた512レコードをモデルに投入
train_data = input_df.iloc[-context_length-prediction_length:-prediction_length,]
4.3.2.6 モデルパラメータ定義
モデルのパラメータを指定します。
時系列カラム、予測対象カラム、時系列の間隔等です。
Hugging Faceの時と同じですね。
#-----------------------------------------------
# モデル用パラメータ定義
#-----------------------------------------------
# モデル用パラメータの指定
forecasting_params = TSForecastParameters(
id_columns=[], # 複数系列を識別するためのID(今回は1系列なので空)
timestamp_column=timestamp_column, # 時間
freq="1h", # 1時間単位
target_columns=target_columns, # 予測対象("total load actual")
prediction_length=prediction_length, # 予測する長さ <96レコード先まで予測>
)
4.3.2.7 モデルの実行
学習レコード数、予測レコード数定義と同じモデルを指定します。
"GRANITE_TTM_512_96_R2"を指定します。
そして、認証情報を使いインスタンス化してから、forecast()で予測を実行します。
resultsにはモデルの説明にも記載した形式で予測結果が返されます。
#-----------------------------------------------
# モデルの実行 - APIで実行
#-----------------------------------------------
#モデルの指定
ts_model_id = client.foundation_models.TimeSeriesModels.GRANITE_TTM_512_96_R2
# モデルインスタンスの初期化と設定
ts_model = TSModelInference(model_id=ts_model_id, api_client=client)
# Watsonx.ai Granite TimeSeries の実行 <予測用データ> - 512レコードを入力して96レコードを予測
results = ts_model.forecast(data=train_data, params=forecasting_params)['results'][0]
4.3.2.8 精度確認
最後に精度を確認します。
Pandasに変換後、scikit-learn の mean_absolute_percentage_error を使ってMAPEを計算します。
#-----------------------------------------------
# 予測精度の確認
#-----------------------------------------------
# 予測結果をデータフレームに取り込み - 予測した96レコードが格納されている。
watsonx_gts_forecast = pd.DataFrame(results)
#最後 検証用にとっておいた 96レコードと予測した96レコードでMAPEを計算
mape = mean_absolute_percentage_error(future_data[target_column], watsonx_gts_forecast[target_column]) * 100
print("mape = ", mape)
最後に拡張ノードを実行して確認します。
結果は以下のとおりです。6%くらいの誤差ですね。
Zero-Shotモデルでの精度と考えると素晴らしいと思います。

5. まとめ
さて、いかがでしたでしょうか。今回はWatsonx.ai上のGranite Time SeriesモデルをAPI経由で利用する方法を紹介しました。
最初の準備部分は、IBM Cloudの利用に慣れていないとちょっと面倒かもしれませんね。
ただ、様々なサービスを無料で利用できるので、ぜひ活用をお勧めします。
次回は予測データを活用できるように、Modelerにデータを戻す部分を紹介する予定です。今回のシンタックスから大きな変更はないですが。宜しくお願いします。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan