1. はじめに
みなさん、こんにちは。前回IBM Granite Time Series ModelをFine-Tuningして精度がよくなるパラメータを調査しました。
最終的な結果のパラメータ設定しか紹介しませんでしたが何回も調整して得たパラメータ値となっています。
(非力な環境ですので妥協はかなりしています。)
今回は、Fine-Tuning Modelを使って予測値を算出していきます。
過去分だけでなく、Zero-Shot Modelの時と同様に未来の値も予測値を算出します。
さて、今回使用したストリームとシンタックスは下記Git Hubにアップロードしています。
ご自由にダウンロードしてください。
但し、一回実行して保存すると拡張ノードが利用不可となりますので、適宜シンタックスを再度コピーしてご利用ください。
データはこちらからダウンロードしてください。
①. 前回と同じスペインのエネルギーデータ
energy_dataset.csv
②. 前回と同じコントロール変数。スペインの気象データを使用します。
weather_features.csv
2. 準備
必要な準備は以下の記事で記載しております。必要なライブラリを導入してください。
また、本ストリームではモデルやログを保存するパスを設定しています。
事前に該当のフォルダを作成しておいてください。
※.パスは任意ですので自由な場所を指定してください。
# Finetuning時のログ、モデルなどの保存フォルダ
OUT_DIR = "C:\\Qiita\\202505\\ttm_results"
3. 使用データ
以下のURLより2つのCSVデータをダウンロードしてください。
①. 前回と同じスペインのエネルギーデータ
energy_dataset.csv
②. コントロール変数として追加で、スペインの気象データを使用します。
weather_features.csv
4. 設定したパラメータ値について
前回試行錯誤した際のパラメータ値について主なものを以下に記載します。
参考にしてください。
①. 使用モデル設定
-
モデルが「過去何ステップ分のデータを見て」学習・予測するか
context_length = 512 -
モデルが「未来何ステップ先まで予測」するか(ここでは96時間先=4日分)
prediction_length = 96 -
使用モデルバージョン
TTM_MODEL_REVISION = "512-96-ft-r2.1"
②. モデルパラメータ設定
-
FCM = Forecast Channel Mixing 複数の特徴量(チャネル)
fcm_use_mixer=True -
FCMに渡す「過去の参照ウィンドウ」の長さ。チャネルミキシングの際に使う特徴量の履歴の長さ。チャネル(変数)同士の関係性を過去どのくらい遡って見るかを指定。
fcm_context_length=10
※. fcm_context_length は context_length より 小さい必要があります。通常は 5〜20程度の値が使われます。逆に大きすぎると、モデルがチャネルの相関を学習するのに過学習気味になったり、学習が不安定になることもあります。
- チャネル間の Mixing を Decoder 側でも使うかどうか。有効にすると、予測を出すときにも特徴量同士を混ぜて、より複雑なパターンを捉えることができる。
enable_forecast_channel_mixing=True
③. ハイパーパラメータ設定
- 学習の速さ
learning_rate: float = 0.001 - エポック数
num_epochs: int = 20 - 精度が改善しない状態が 5 エポック続いたら早期終了
patience: int = 5 - 一度に何個の時系列スライスを学習するか(32個)
batch_size: int = 32
④. その他
-
事前学習を更新せず利用する (backborne)設定
param.requires_grad = False -
データセットのうち、10%だけを使ってトレーニング・評価を行う設定
fewshot_fraction = 0.1 -
データ分割の設定 - 学習用 60% , テスト用 20% , 残り 20%
split_config = {"train": 0.6, "test": 0.2}
5. ストリームについて
以下が、全体となります。データ加工部分は前回と同じなため説明は省略します。
ここでは、赤枠内の新しく実装した部分について説明していきます。
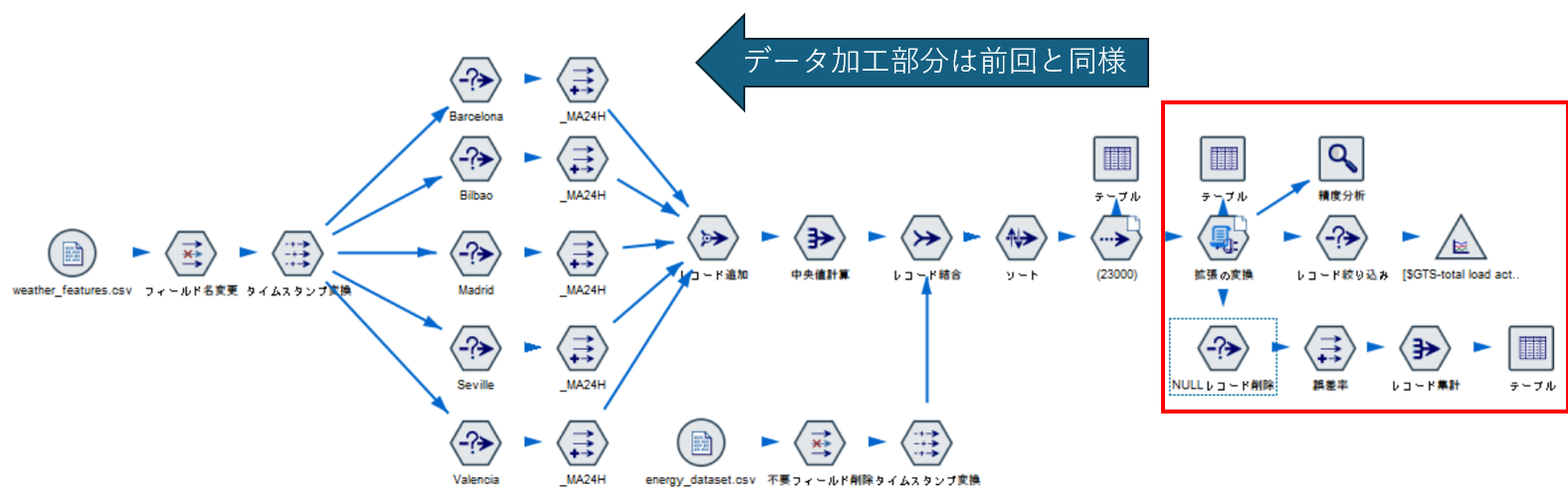
6. Fine-Tuning Modelの実装
まずは、本丸のFine-Tuning Modelを実装していきます。
前回は予測値などは取得せず、あくまで精度を確認するだけでしたので拡張の出力ノードを使用しました。
今回は、予測値をModelerでも利用したいのでデータをModelerへ戻せるように拡張の変換ノードを使用します。

①. シンタックス説明
a. シンタックス全体
基本的にZero-Shot Modelと、前回精度確認したシンタックスの合わせ技であり、処理自体は大きく違いません。
拡張の変換ノードで特有のデータモデル定義のif文の分岐がある部分は注意していください。
#---------------------------------------------------------------
# IBM Granite Time Series ( Tiny Time Mixer )
# HugingFace Granite Time Series を利用
# "ibm-granite/granite-timeseries-ttm-r2
# "512-96-ft-r2.1",
# FineTurning Modelを使って予測
#---------------------------------------------------------------
#---------------------------------------------------------------
# A. ライブラリ導入パート
#---------------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# 各種処理用
import numpy as np
import pandas as pd
# Finetuningモデル保存用
import math
import os
# モデル作成用 - Finetuning
# pytorch
import torch
# 最適化手法の一つで、Adam に weight decay(重みの減衰) を加えたもの
# 補足: 通常のAdamだとL2正則化がうまく効かないことがある → それを修正したのがAdamW
from torch.optim import AdamW
# スケジューラ
# 学習率(Learning Rate)を 1サイクルの形で調整するスケジューラ
from torch.optim.lr_scheduler import OneCycleLR # 最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
# 早期終了(Early Stopping) 用のコールバック
# トレーニング統合クラス
# Trainer に渡す設定(学習率、バッチサイズ、出力先など)を保持するクラス
from transformers import EarlyStoppingCallback, Trainer, TrainingArguments, set_seed
# IBM Granite TTM
from tsfm_public import (
TimeSeriesForecastingPipeline, # 時系列予測のパイプライン
TimeSeriesPreprocessor, # 入力データの整形・スケーリング
TinyTimeMixerForPrediction, # 時系列予測モデル
TrackingCallback, # 学習中にログを取ったり、追加で何かを記録するための カスタムCallback
count_parameters, # モデルの総パラメータ数を数えて出力してくれる関数
get_datasets, # 前処理済みのDataFrameを、モデルが扱える Dataset形式(学習/検証/テスト) に変換する関数
)
# 入力データをtrain/valid/test に自動で分割してくれる関数
from tsfm_public.toolkit.time_series_preprocessor import prepare_data_splits
#---------------------------------------------------------------
# B. カラム定義
#---------------------------------------------------------------
# タイムスタンプカラム
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
# モデルの予測値格納カラム名
prediciton_column = target_column + "_prediction"
# Modeler用予測値格納カラム名
predictField = "$GTS-" + target_column
#-----------------------------------------------
# C. 使用モデル用パラメータ設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# モデルが「未来何ステップ先まで予測」するか(ここでは96時間先=4日分)
prediction_length = 96 # the max forecast length for the 512-96 model
# 使用モデルバージョン
TTM_MODEL_REVISION = "512-96-ft-r2.1"
#-----------------------------------------------
# D. ハイパーパラメータ設定
#-----------------------------------------------
learning_rate: float = 0.001 # learning_rate: 学習の速さ
num_epochs: int = 20 # num_epochs: 最大 20 エポックまで学習
patience: int = 5 # patience: 精度が改善しない状態が 5 エポック続いたら早期終了
batch_size: int = 32 # batch_size: 一度に何個の時系列スライスを学習するか(32個)
#-----------------------------------------------
# E.データモデル定義
#-----------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#モデル用変数フィールドを追加
#predictField - 実数を格納予定
modelerDataModel.addField(modelerpy.Field( predictField, "real", measure="continuous"))
#修正したデータモデルをModelerへ戻します。
modelerpy.setOutputDataModel(modelerDataModel)
#-----------------------------------------------
# F.時系列モデルパ―ド
# 1. データの入力
# 2. モデル用データ準備
# 3. モデル実行設定
# 4. モデル作成 - FineTurning実行
# 5. Modelerへのデータ出力処理
#-----------------------------------------------
else:
#---------------------------------------------------------------
# 1. データ入力パート
#---------------------------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
# 時系列カラム"time"をタイムスタンプ型に変更
input_df[ timestamp_column ] = pd.to_datetime(input_df[ timestamp_column ])
#---------------------------------------------------------------
# 2. モデル用データ準備パート
#---------------------------------------------------------------
#-----------------------------------------------
# カラムロール設定
#-----------------------------------------------
# 予測対象カラム定義
target_columns = [ target_column ] #リストにする
# カラムロール設定
# 説明変数には、各日時の気象データの中央値を指定
column_specifiers = {
"timestamp_column": timestamp_column, # タイムスタンプカラム
"id_columns": [], # 複数系列を識別するためのID(今回は1系列なので空)
"target_columns": target_columns, # 予測対象カラム
"control_columns": [ # コントロール変数(気象データなど)
"temp_MA24H_Median",
"temp_min_MA24H_Median",
"temp_max_MA24H_Median",
"pressure_MA24H_Median",
"wind_speed_MA24H_Median",
"wind_deg_MA24H_Median",
"humidity_MA24H_Median",
"rain_1h_MA24H_Median",
"rain_3h_MA24H_Median",
"clouds_all_MA24H_Median",
],
}
#-----------------------------------------------
# 使用データ設定
#-----------------------------------------------
# データセットのうち、10%だけを使ってトレーニング・評価を行う設定
fewshot_fraction = 0.1
# データ分割の設定 - 学習用 60% , テスト用 20% , 残り 20%
split_config = {"train": 0.6, "test": 0.2}
# Finetuning時のログ、モデルなどの保存フォルダ
OUT_DIR = "C:\\Qiita\\202505\\ttm_results"
# GPU(CUDA)が使えれば使う、無ければCPU。
device = "cuda" if torch.cuda.is_available() else "cpu"
#-----------------------------------------------
# データ分割「訓練・検証・テスト」
#-----------------------------------------------
# input_df を context_length を考慮しながら「訓練・検証・テスト」に分割
train_df, valid_df, test_df = prepare_data_splits(input_df, context_length=context_length, split_config=split_config)
#---------------------------------------------------------------
# 3. モデル実行設定パート
#---------------------------------------------------------------
#-----------------------------------------------
# モデル用 Preprocessor の初期化と学習
#-----------------------------------------------
tsp = TimeSeriesPreprocessor(
**column_specifiers, # カラム定義
context_length=context_length, # 学習に使用するレコード数(ここでは512)
prediction_length=prediction_length, # 予測するレコード数(96)
scaling=True, # スケーリング(標準化や正規化)
encode_categorical=False, # カテゴリ変数(文字列など)を数値にエンコードするかどうか。数値データのみのためFalse
scaler_type="standard", # 平均0・標準偏差1に標準化(StandardScalerを使うイメージ)
)
#-----------------------------------------------
# モデルパラメータ設定
#-----------------------------------------------
# ランダムSeeDの設定 - 42はおまじない
set_seed(42)
# Granite Time Seriesモデル設定
finetune_forecast_model = TinyTimeMixerForPrediction.from_pretrained(
"ibm-granite/granite-timeseries-ttm-r2", # Hugging Face 上の IBMのGraniteシリーズ 時系列モデル(TinyTimeMixer)
num_input_channels=tsp.num_input_channels, # 入力のチャンネル数(= モデルに渡す特徴量の数) tspで自動で計算されてる。
prediction_channel_indices=tsp.prediction_channel_indices, # 予測対象の指定 tspで計算されている。
exogenous_channel_indices=tsp.exogenous_channel_indices, # 外部変数(エクソジェニアス変数)」の位置を指定。tspで計算されている。
fcm_use_mixer=True, # FCM = Forecast Channel Mixing 複数の特徴量(チャネル)を混ぜながら時系列の未来を予測するしくみを有効化する。
fcm_context_length=10, # FCMに渡す「過去の参照ウィンドウ」の長さ。10ステップ分のデータを見て未来を考える、という設定。
enable_forecast_channel_mixing=True, # チャネル間の Mixing を Decoder 側でも使うかどうか。有効にすると、予測を出すときにも特徴量同士を混ぜて、より複雑なパターンを捉えることができる。
decoder_mode="mix_channel", # Decoder(予測を生成する側)での挙動設定。"mix_channel" にすると、チャンネル間のミキシングを有効化した構造になる
)
#-----------------------------------------------
# 事前学習を更新せず利用する (backborne)設定
#-----------------------------------------------
# **「backbone」部分の重みは、事前学習されたまま固定して、学習時には更新しない(凍結する)**という意味
for param in finetune_forecast_model.backbone.parameters():
param.requires_grad = False
#-----------------------------------------------
# データセット作成(Preprocessorの内容を反映)
#-----------------------------------------------
# データセットの作成 (split_config 60:20:20)
# 学習・検証・テスト用のPyTorch Dataset に変換
train_dataset, valid_dataset, test_dataset = get_datasets(
tsp, # 事前定義したPreprocessor
input_df,
split_config, # 60:20:20
fewshot_fraction=fewshot_fraction, # 0.1
fewshot_location="first", # few-shotに使うデータの取り方。「first」なら、データの最初からfew-shotサンプルを取る。("random"もある)
use_frequency_token=finetune_forecast_model.config.resolution_prefix_tuning, # 周波数情報(時間の粒度情報、'1H'や'1D'を埋め込むか?)。ここではモデルの事前設定をそのまま使う設定
)
#-----------------------------------------------
# Fine-Tuningのパラメータ設定
#-----------------------------------------------
# Trainer の学習設定(TrainingArguments)
finetune_forecast_args = TrainingArguments(
output_dir=os.path.join(OUT_DIR, "output"), # モデル出力先ディレクトリ
overwrite_output_dir=True, # 上書
learning_rate=learning_rate,
num_train_epochs=num_epochs,
do_eval=True, # 各エポックごとに検証を行う
eval_strategy="epoch", # 1エポックごとに評価
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=0, # CPUなら 0 推奨 (マルチスレッドより安定)
report_to=None,
save_strategy="epoch", # 1エポックごとにモデル保存(ただし save_total_limit=1 なので最新だけ残す)
logging_strategy="epoch",
save_total_limit=1,
logging_dir=os.path.join(OUT_DIR, "logs"), # Make sure to specify a logging directory
load_best_model_at_end=True, # 最も良かったエポックのモデルを保存
metric_for_best_model="eval_loss", # 評価指標は損失関数(小さい方が良い)
greater_is_better=False, # For loss
use_cpu=device != "cuda", # GPU が使えないときは CPU で実行
)
#-----------------------------------------------
# 早期終了の設定
#-----------------------------------------------
# EarlyStopping(早期終了の設定)
# 評価損失 (eval_loss) の改善が 0.001 未満で 5 エポック 続くと自動終了
# → 無駄な学習を防いでオーバーフィッティングも回避!
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=patience, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.001, # Minimum improvement required to consider as improvement
)
# ログなどのカスタム設定
tracking_callback = TrackingCallback()
#-----------------------------------------------
# Optimizer / スケジューラ設定
#-----------------------------------------------
# Optimizer(最適化手法)と Scheduler(学習率スケジューラー)の設定
# AdamW:定番の最適化手法(重み減衰に強い)
optimizer = AdamW(finetune_forecast_model.parameters(), lr=learning_rate)
# OneCycleLR:最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
scheduler = OneCycleLR(
optimizer,
learning_rate,
epochs=num_epochs,
steps_per_epoch=math.ceil(len(train_dataset) / (batch_size)),
)
#-----------------------------------------------
# 4. モデル作成 - FineTurning実行パート
#-----------------------------------------------
#-----------------------------------------------
# FineTurningの実行
#-----------------------------------------------
# Trainer インスタンス作成
finetune_forecast_trainer = Trainer(
model=finetune_forecast_model, # FineTuneモデル
args=finetune_forecast_args, # Trainer の学習設定
train_dataset=train_dataset, # 学習用データセット
eval_dataset=valid_dataset, # 検証用データセット
callbacks=[early_stopping_callback, tracking_callback], # EarlyStopping(早期終了の設定)
optimizers=(optimizer, scheduler), # Optimizer(最適化手法)と Scheduler(学習率スケジューラー)
)
# 学習スタート
finetune_forecast_trainer.train()
#-----------------------------------------------
# モデルPipelineの作成・実行
#-----------------------------------------------
# 予測パイプラインの作成と実行
pipeline = TimeSeriesForecastingPipeline(
finetune_forecast_model, # fewshot - finetuneモデル
device=device, # GPU or CPU.
feature_extractor=tsp, # Preprocessor
batch_size=batch_size,
)
# Make a forecast on the target column given the input data.
finetune_forecast = pipeline(input_df)
#------------------------------------------------------------
# 5. Modelerに戻すためのデータ加工パート
# 1. 過去データに対する予測値の取得し入力データに結合
# 戻り値の特性を考慮して、リストの先頭の値を一つ下のレコードへ配置
# 2. 最後のレコードから96レコード先までの予測を取得
# 3. 最終レコードより未来の値を1.のデータに結合させ、Modelerに戻す
#------------------------------------------------------------
#=====================================
# Step 1: 過去の1ステップ先予測を格納
# 過去の実績値に対してのモデルの予測値も求めておく
#=====================================
# モデルの戻り値をコピー
past_pred_df = finetune_forecast.copy()
# ndarrayから1つ目の値を取得する関数
def get_first_val(x):
if isinstance(x, (list, np.ndarray)) and len(x) > 0:
return x[0]
return np.nan
# 予測値の1ステップ先だけ取り出す(リストの1つ目を取得)
past_pred_df[ predictField ] = (
past_pred_df[ prediciton_column ].apply(get_first_val)
)
# 1ステップ先なので、「1時間後」にずらす(一つ先のレコードに格納)
past_pred_df[ predictField ] = past_pred_df[ predictField ].shift(1)
# input_df にマージする(timeで結合、inner join でOK)
merged_df = pd.merge(input_df, past_pred_df[[timestamp_column, predictField]], on=timestamp_column, how="left")
#=====================================
# Step 2: 96時間先の未来を予測する処理
# 新しいデータフレームに未来の値を格納
#=====================================
# 入力の最後の512件だけ取得(512はcontext_length)
input_tail = input_df.tail(context_length)
# 未来96時間分の空の DataFrame を作成
last_time = input_tail[timestamp_column].iloc[-1]
future_times = pd.date_range(start=last_time + pd.Timedelta(hours=1), periods=prediction_length, freq="h")
# 空のDataFrameを作る(NaNが入る)
future_df = pd.DataFrame({timestamp_column: future_times})
# 入力+未来のDataFrameを作って予測(前処理器が内部で補完など行う)
input_for_forecast = pd.concat([input_tail, future_df], ignore_index=True)
# 予測を実行
future_forecast = pipeline(input_for_forecast)
# 未来予測部分だけを切り出して新しいDataFrameに
# 各行の total load actual_prediction は 96個の予測値が入ったリストなので、
# 最初の行だけ使って 1レコードに展開
pred_list = future_forecast[ prediciton_column ].iloc[0]
future_df = pd.DataFrame({
timestamp_column: future_times,
predictField: pred_list,
})
#=====================================
# Step 3: 過去データの予測値と未来の値を結合してModelerに戻す
# 新しいデータフレームに未来の値を格納
#=====================================
# 他のカラム(total load actual など)は input_df と同じ構造にするため、NaN で埋める
for col in merged_df.columns:
if col not in future_df.columns:
future_df[col] = np.nan
# カラム順を merged_df に合わせて並べ替え
future_df = future_df[merged_df.columns]
# merged_df + future_df を縦に結合
input_df_with_pred = pd.concat([merged_df, future_df], ignore_index=True)
# 結果確認
print(input_df_with_pred.tail(100)) # 最後の100行を表示
# Modelerにデータを戻す
modelerpy.writePandasDataframe(input_df_with_pred)
b. シンタックス詳細
詳細をみていきましょう。
前回とZero-Shot Modelの時から変更がある部分を主に説明します。
それぞれのシンタックスの詳細は以下を参照してください。
b-1. カラム定義
Zero-Shot Modelの時と同様にModelerへ戻すためのカラム定義も追加しています。
#---------------------------------------------------------------
# B. カラム定義
#---------------------------------------------------------------
# タイムスタンプカラム
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
# モデルの予測値格納カラム名
prediciton_column = target_column + "_prediction"
# Modeler用予測値格納カラム名
predictField = "$GTS-" + target_column
b-2. パラメータ設定
つづいて、パラメータ設定の記述をすぐに変更できるように、シンタックスの最初にもってきました。
#-----------------------------------------------
# C. 使用モデル用パラメータ設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# モデルが「未来何ステップ先まで予測」するか(ここでは96時間先=4日分)
prediction_length = 96 # the max forecast length for the 512-96 model
# 使用モデルバージョン
TTM_MODEL_REVISION = "512-96-ft-r2.1"
#-----------------------------------------------
# D. ハイパーパラメータ設定
#-----------------------------------------------
learning_rate: float = 0.001 # learning_rate: 学習の速さ
num_epochs: int = 20 # num_epochs: 最大 20 エポックまで学習
patience: int = 5 # patience: 精度が改善しない状態が 5 エポック続いたら早期終了
batch_size: int = 32 # batch_size: 一度に何個の時系列スライスを学習するか(32個)
b-3. データモデル定義
後続ノードへデータを渡すためにデータモデル定義をしています。
データモデルを取得して、予測値を格納するためのフィールドを追加しています。
if modelerpy.isComputeDataModelOnly(): 以下に処理を記述します。
#-----------------------------------------------
# E.データモデル定義
#-----------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#モデル用変数フィールドを追加
#predictField - 実数を格納予定
modelerDataModel.addField(modelerpy.Field( predictField, "real", measure="continuous"))
#修正したデータモデルをModelerへ戻します。
modelerpy.setOutputDataModel(modelerDataModel)
else
b-4. モデルの結果出力取得
データモデル定義以下については、この処理までは前回のモデルを作る処理とまったく同じ記述になっています。
異なるのは、Pipelineの実行結果取得の部分です。ここでは、Pipelineにinpud_df(入力データ全件)を渡しています。
前回はテストデータを渡していました。
#-----------------------------------------------
# モデルPipelineの作成・実行
#-----------------------------------------------
# 予測パイプラインの作成と実行
pipeline = TimeSeriesForecastingPipeline(
finetune_forecast_model, # fewshot - finetuneモデル
device=device, # GPU or CPU.
feature_extractor=tsp, # Preprocessor
batch_size=batch_size,
)
# Make a forecast on the target column given the input data.
finetune_forecast = pipeline(input_df)
b-5. Modelerへのデータ出力処理
この部分は、Zero-Shot Modelの時の記述とほぼ同じです。
最初のデータコピーの変数名が異なるだけです。
- モデルの戻り値をコピー
past_pred_df = finetune_forecast .copy()
#------------------------------------------------------------
# 5. Modelerに戻すためのデータ加工パート
# 1. 過去データに対する予測値の取得し入力データに結合
# 戻り値の特性を考慮して、リストの先頭の値を一つ下のレコードへ配置
# 2. 最後のレコードから96レコード先までの予測を取得
# 3. 最終レコードより未来の値を1.のデータに結合させ、Modelerに戻す
#------------------------------------------------------------
#=====================================
# Step 1: 過去の1ステップ先予測を格納
# 過去の実績値に対してのモデルの予測値も求めておく
#=====================================
# モデルの戻り値をコピー
past_pred_df = finetune_forecast.copy()
# ndarrayから1つ目の値を取得する関数
def get_first_val(x):
if isinstance(x, (list, np.ndarray)) and len(x) > 0:
return x[0]
return np.nan
# 予測値の1ステップ先だけ取り出す(リストの1つ目を取得)
past_pred_df[ predictField ] = (
past_pred_df[ prediciton_column ].apply(get_first_val)
)
# 1ステップ先なので、「1時間後」にずらす(一つ先のレコードに格納)
past_pred_df[ predictField ] = past_pred_df[ predictField ].shift(1)
# input_df にマージする(timeで結合、inner join でOK)
merged_df = pd.merge(input_df, past_pred_df[[timestamp_column, predictField]], on=timestamp_column, how="left")
#=====================================
# Step 2: 96時間先の未来を予測する処理
# 新しいデータフレームに未来の値を格納
#=====================================
# 入力の最後の512件だけ取得(512はcontext_length)
input_tail = input_df.tail(context_length)
# 未来96時間分の空の DataFrame を作成
last_time = input_tail[timestamp_column].iloc[-1]
future_times = pd.date_range(start=last_time + pd.Timedelta(hours=1), periods=prediction_length, freq="h")
# 空のDataFrameを作る(NaNが入る)
future_df = pd.DataFrame({timestamp_column: future_times})
# 入力+未来のDataFrameを作って予測(前処理器が内部で補完など行う)
input_for_forecast = pd.concat([input_tail, future_df], ignore_index=True)
# 予測を実行
future_forecast = pipeline(input_for_forecast)
# 未来予測部分だけを切り出して新しいDataFrameに
# 各行の total load actual_prediction は 96個の予測値が入ったリストなので、
# 最初の行だけ使って 1レコードに展開
pred_list = future_forecast[ prediciton_column ].iloc[0]
future_df = pd.DataFrame({
timestamp_column: future_times,
predictField: pred_list,
})
#=====================================
# Step 3: 過去データの予測値と未来の値を結合してModelerに戻す
# 新しいデータフレームに未来の値を格納
#=====================================
# 他のカラム(total load actual など)は input_df と同じ構造にするため、NaN で埋める
for col in merged_df.columns:
if col not in future_df.columns:
future_df[col] = np.nan
# カラム順を merged_df に合わせて並べ替え
future_df = future_df[merged_df.columns]
# merged_df + future_df を縦に結合
input_df_with_pred = pd.concat([merged_df, future_df], ignore_index=True)
# 結果確認
print(input_df_with_pred.tail(100)) # 最後の100行を表示
# Modelerにデータを戻す
modelerpy.writePandasDataframe(input_df_with_pred)
7. 精度、結果の確認
さて、モデルシンタックスの実装が完了したら後は、Modelerで精度やデータを確認していきましょう。
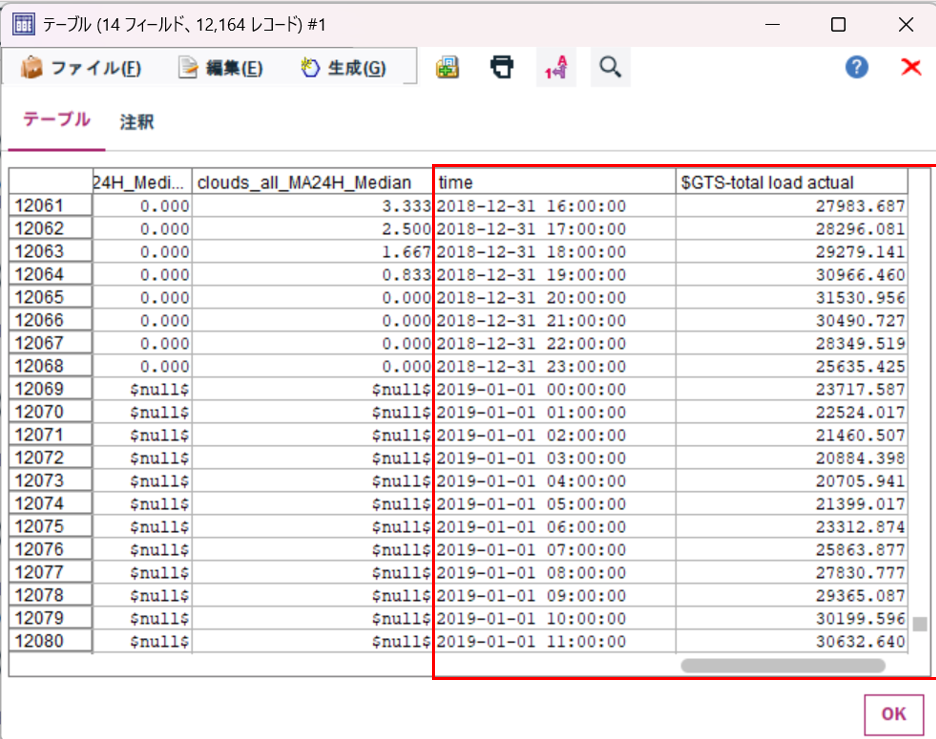
①. データ確認
テーブルノードでデータを確認します。未来のレコードに対しても予測値が算出されていることを確認できます。
②. 精度確認
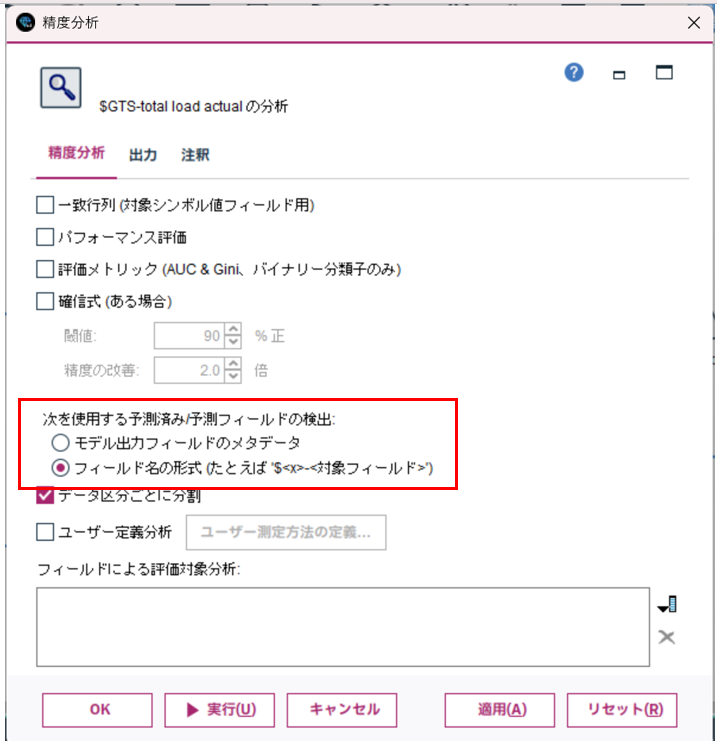
精度分析ノードで精度を確認します。

精度分析ノードでは、予測フィールドの検出の設定で、フィールド名の形式を選択して実行します。
実は前回確認した時より精度がよくなっているように見えます。
これは、対象とするデータが異なるためです。
前回は、レコード毎に96個の予測値が算出されその全てに対して精度を確認しました。
ここでは、各レコードの最初の値のみを採用して直後のレコードの予測値として扱っています。そのための96個先までは予測していないので精度も上がっているように見えるのです。
実際96個先まで予測した場合は、前回のような精度になると思っておいてください。

③. MAPE確認
MAPEを確認します。
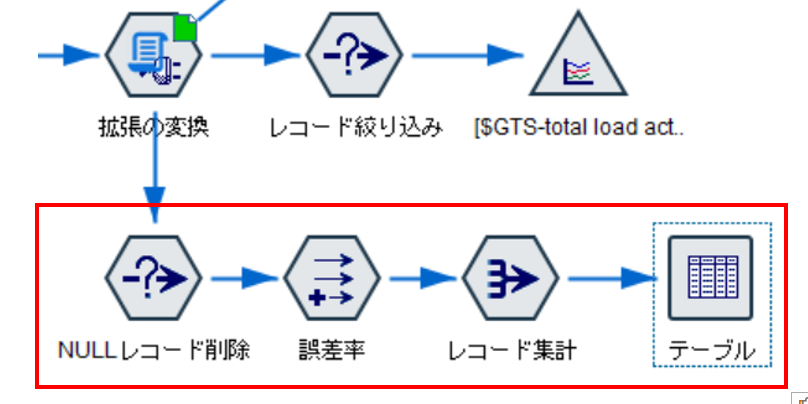
まず、条件抽出ノードで実測値と予測値についてNULLの含まれるレコードを除外します。
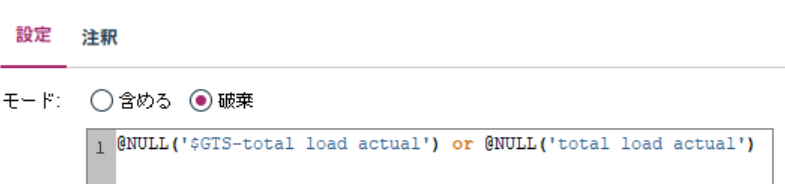
続いて、フィールド作成ノードで誤差率を計算します。
単純に(予測値ー実測値 / 実測値)× 100 を計算して絶対値を取得しています。

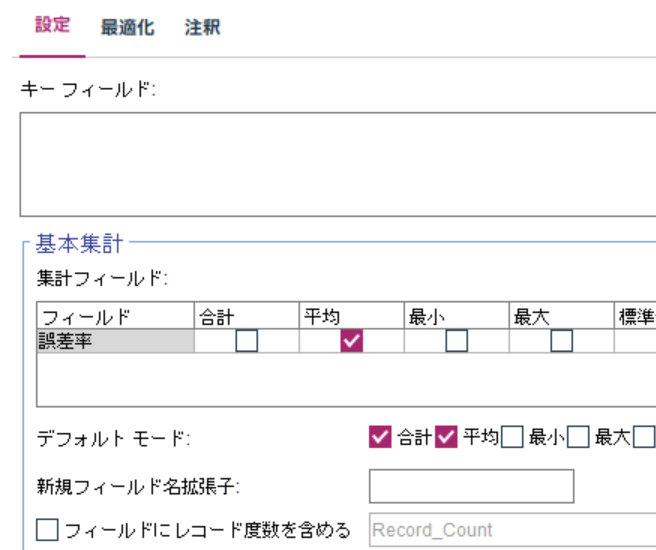
最後に平均値をレコード集計ノードで計算します。
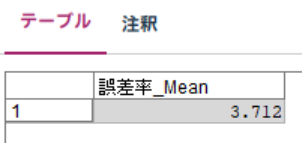
テーブルノードで確認すると、MAPEは 3.712 % でした。
先ほども説明しましたが、この値は1個先の未来を予測した場合のMAPEです。96個先まで予測した場合には、8%程度になると思ってください。
④. グラフの確認
最後に予測値と実測値の関係をグラフで確認します。
最初に、全期間を描画すると細かくなりすぎるので、適当にデータを絞り込みます。
ここでは、"2018-12-15 16:00:00" 以降のデータに絞りこんでいます。

続いて、線グラフノードで描画します。特に特別な設定はしません。
結果は以下の通り。
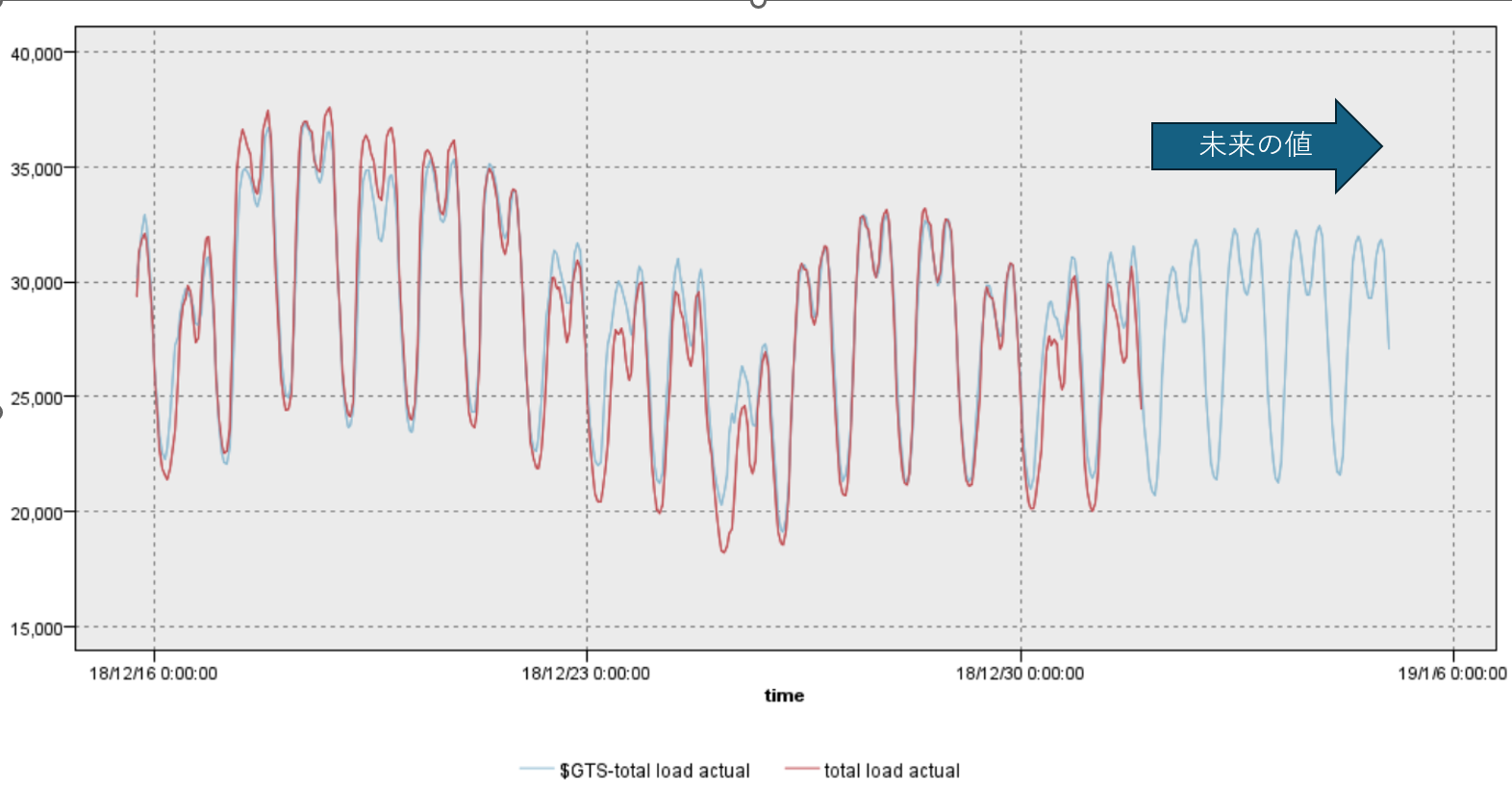
きれいに予測できていますね。
8. まとめ
IBM Granite Time Series の Fine-Tuning ModelをModelerで活用できるにように、ストリームとシンタックスを紹介してきました。
モデル自体は保存できないので、毎回<モデル作成→モデル実行>をいうプロセスを実行する必要があることが課題ですね。
Modelerにも時系列モデル自体は実装されているため、無理やり利用する必要はありませんが、新しい技術を学んで活用できるように勉強を続けていきましょう。
次回以降は、Watsonx.aiのAPIを活用する例や、Modelerの時系列モデルとの比較もしていきたいと思っています。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan