1.はじめに
みなさん、こんにちは。前回、Watsonx.ai上に公開されているモデルをAPI経由で呼び出し、時系列予測の精度を確認する方法を紹介しました。
今回は、予測結果を活用するためにデータをModelerへ戻す方法を紹介します。
GitHubに今回利用しているストリームとPythonシンタックスをアップロードしています。
ご自由にダウンロードしてください。
※. Watsonx.aiのAPI KEY等の情報は削除していますので、みなさんのAPI KEY等をご利用ください。
2. Grnaite Time Seires Modele - Watsonx.ai APIを実装
早速ストリームを作成していきます。前回からの続きになります。
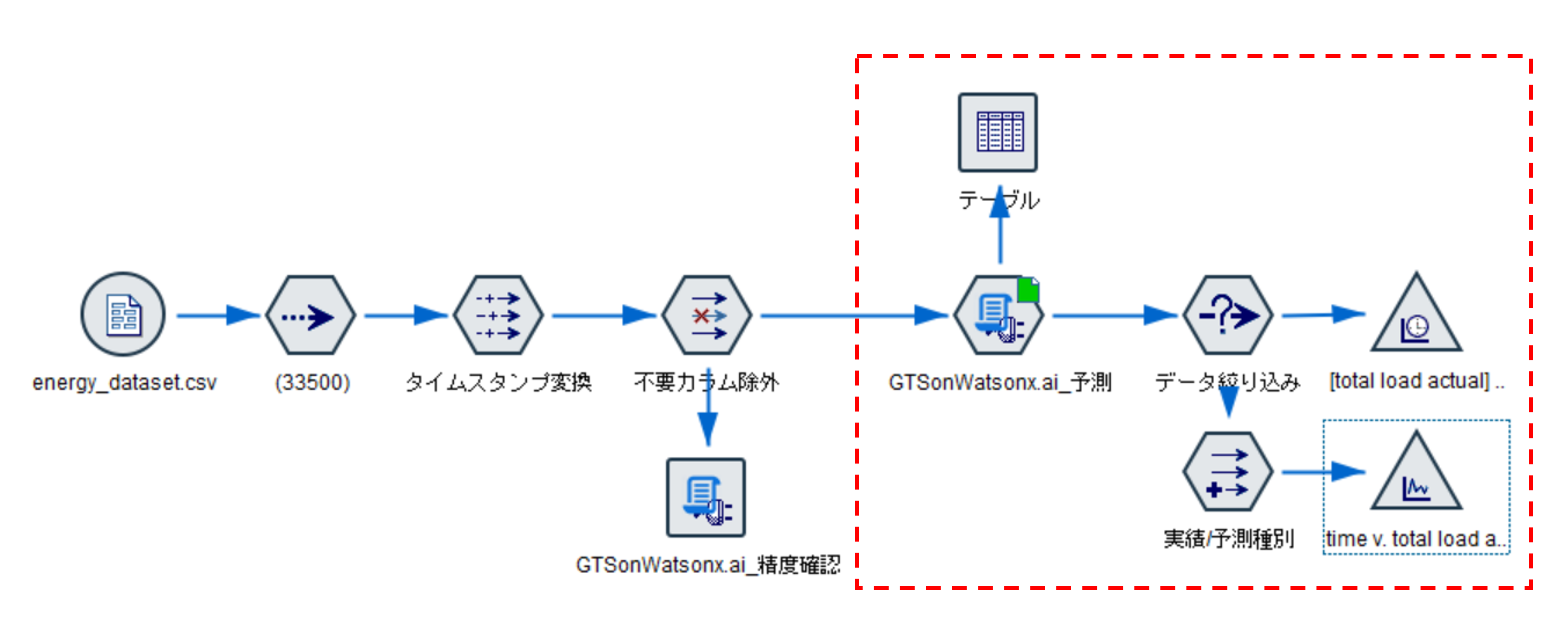
2.1 ストリーム全体
赤枠で囲った部分を説明していきます。
グラフ出力の部分を若干処理を追加していますが特に難しい部分はありません。
2.2 Granite Time Series Model API シンタックス
Modelerでもデータを活用するため、拡張の変換ノードを使います。
そこに、Granite Time Seires APIを利用するためのシンタックスを記述していきます。

2.2.1 シンタックス全体
ほとんど前回と同じです。
拡張の変換ノードを使うので、
・データモデル定義処理の追加
・データをModelerへ戻す処理の追加
を行っています。
#-------------------------------------------------
# IBM Granite Time Series ( Tiny Time Mixer )
# Watsonx.ai上の Granite Time Series を利用
# Modeler連携 - 予測値取得シンタックス
#-------------------------------------------------
#-----------------------------------------------
# ライブラリ導入パート
# ・データモデル定義時のために必要最低限を導入
#-----------------------------------------------
# Modeler用ライブラリ
import modelerpy
# すべての警告を無視
import warnings
warnings.filterwarnings("ignore")
#-----------------------------------------------
# カラム定義
#-----------------------------------------------
# タイムスタンプカラム定義
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
#-----------------------------------------------
# データモデル定義パート
#-----------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#特に変更しない
modelerpy.setOutputDataModel(modelerDataModel)
#-----------------------------------------------
# 時系列予測値取得パ―ド
#-----------------------------------------------
else:
#-----------------------------------------------
# モデル作成用ライブラリのインポート
#-----------------------------------------------
# Pandas & Numpy
import numpy as np
import pandas as pd
# IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai import APIClient
from ibm_watsonx_ai import Credentials
# Granite Time Series Forcasting on IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai.foundation_models import TSModelInference
from ibm_watsonx_ai.foundation_models.schema import TSForecastParameters
#-----------------------------------------------
# データ入力
#-----------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
#-----------------------------------------------
# API Key などの準備
#-----------------------------------------------
WATSONX_APIKEY = "YOUR API KEY"
WATSONX_PROJECT_ID = "YOUR PROJECT ID"
WATSONX_URL = "YOUR ENDPOINT URL"
#-----------------------------------------------
# Watsonx.ai ランタイムへの接続情報設定
#-----------------------------------------------
# watsonx.aiランタイムへの接続情報を定義
credentials = Credentials(
url = WATSONX_URL,
api_key = WATSONX_APIKEY,
)
# 接続情報の設定
# クレデンシャルのセット
client = APIClient(credentials)
# プロジェクトのセット
client.set.default_project( WATSONX_PROJECT_ID )
#-----------------------------------------------
# 学習データレコード数、予測レコード数設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# 予測対象("total load actual")
prediction_length = 96 # the max forecast length for the 512-96 model
#-----------------------------------------------
# モデルカラム定義
#-----------------------------------------------
# 予測対象カラムをリストで定義
target_columns = [ target_column ]
# 時系列カラム"time"を文字列型に変更
# Watsonx の裏側では、HTTP リクエストを通じてモデルにデータを渡すため、
# JSON形式に変換可能なデータ(文字列、数値、配列など)しか渡せません。
input_df[ timestamp_column ] = input_df[ timestamp_column ] .astype(str)
#-----------------------------------------------
# モデルの予測・検証用データの準備
#-----------------------------------------------
# 予測用データ - 最後から512レコードを使う
future_data = input_df.iloc[-context_length:,]
#-----------------------------------------------
# モデルパラメータ定義
#-----------------------------------------------
forecasting_params = TSForecastParameters(
id_columns=[], # 複数系列を識別するためのID(今回は1系列なので空)
timestamp_column=timestamp_column, # 時間
freq="1h", # 時間単位 - 1時間ごとのデータ
target_columns=target_columns, # 予測対象("total load actual")
prediction_length=prediction_length, # 予測する長さ
)
#-----------------------------------------------
# Watsonx.aiモデルのインスタンス化
#-----------------------------------------------
#モデルの指定 - 512レコードを使い96レコード先を予測するモデルを指定
ts_model_id = client.foundation_models.TimeSeriesModels.GRANITE_TTM_512_96_R2
# モデルインスタンスの初期化と設定 - APIKEYやProject IDをここで使用
ts_model = TSModelInference(model_id=ts_model_id, api_client=client)
#-----------------------------------------------
# モデル実行
#-----------------------------------------------
# 予測用データ(最後から512レコード)でモデル実行
results = ts_model.forecast(data=future_data, params=forecasting_params)['results'][0]
# 予測結果をデータフレームに取り込み - 予測値 96 レコードが格納されている
watsonx_gts_forecast = pd.DataFrame(results)
#-----------------------------------------------
# 入力データに予測値を追加して戻す
#-----------------------------------------------
# それぞれのtimeのカラムをtime stampに変換してから追加する
modelerData[ timestamp_column ] = pd.to_datetime(modelerData[ timestamp_column ])
watsonx_gts_forecast[ timestamp_column ] = pd.to_datetime(watsonx_gts_forecast[ timestamp_column ])
# 追加
df_combined = pd.concat([modelerData, watsonx_gts_forecast], ignore_index=True)
# Modelerにデータを戻す
modelerpy.writePandasDataframe(df_combined)
2.2.2 シンタックス詳細
では、パート毎に詳細をみていきましょう。
2.2.2.1 ライブラリインポート #1
ライブラリインポート部分ですが、今回は、変換の拡張ノードであることを意識しました。
※. 以前からやっておけと。
データモデルの定義処理のみ場合もあるので、データモデル定義に
必要ないようなライブラリや処理はモデル実行部分のパートに記述しました。
インポートするのはModeler用のライブラリくらいですね。
あと、modeler.pyは処理で、Warningがよく出力されるのでここでは、無視するように設定しました。
#-----------------------------------------------
# ライブラリ導入パート
# ・データモデル定義時のために必要最低限を導入
#-----------------------------------------------
# Modeler用ライブラリ
import modelerpy
# すべての警告を無視
import warnings
warnings.filterwarnings("ignore")
以下が、よく出る modeler.pyのWarningです。
modelerpy.py:671: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use ser.iloc[pos]
2.2.2.2 カラム定義 #1
予測対象カラムと時系列カラムを定義しています。
今回は使いませんでしたが、データモデル定義で必要になる場合もあるので、この位置に記述をするようにしておきました。
#-----------------------------------------------
# カラム定義
#-----------------------------------------------
# タイムスタンプカラム定義
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
2.2.2.3 データモデル定義
後続ノードへデータモデルを渡すための処理です。
今回はカラム追加などはないので、取得したものをそのまま戻しています。
※.データモデル定義に変更がなくても、この処理を記述してください。エラーになります。
#-----------------------------------------------
# データモデル定義パート
#-----------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#特に変更しない
modelerpy.setOutputDataModel(modelerDataModel)
2.2.2.4 ライブラリインポート #2
ここから、Granite Time Series APIの実行パートです。
まずは、時系列モデル実行に必要なライブラリインポートします。
ここは、前回と同じものをインポートしています。
else:
#-----------------------------------------------
# モデル作成用ライブラリのインポート
#-----------------------------------------------
# Pandas & Numpy
import numpy as np
import pandas as pd
# IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai import APIClient
from ibm_watsonx_ai import Credentials
# Granite Time Series Forcasting on IBM Watsonx.ai ライブラリ
from ibm_watsonx_ai.foundation_models import TSModelInference
from ibm_watsonx_ai.foundation_models.schema import TSForecastParameters
2.2.2.5 データ入力
ModelerからPandasでデータを取得します。
#-----------------------------------------------
# データ入力
#-----------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
2.2.2.6 認証情報設定
API KEY、PROJECT ID、ENDPOINT URLが必要になります。
みなさんのものを準備して設定してください。
#-----------------------------------------------
# API Key などの準備
#-----------------------------------------------
WATSONX_APIKEY = "YOUR API KEY"
WATSONX_PROJECT_ID = "YOUR PROJECT ID"
WATSONX_URL = "YOUR ENDPOINT URL"
#-----------------------------------------------
# Watsonx.ai ランタイムへの接続情報設定
#-----------------------------------------------
# watsonx.aiランタイムへの接続情報を定義
credentials = Credentials(
url = WATSONX_URL,
api_key = WATSONX_APIKEY,
)
# 接続情報の設定
# クレデンシャルのセット
client = APIClient(credentials)
# プロジェクトのセット
client.set.default_project( WATSONX_PROJECT_ID )
2.2.2.7 モデル使用データ定義
モデルが使用する学習データ量や、予測レコード数を定義しています。
APIでモデルを使用する場合には、入力するデータはJSON形式である必要があるため、
時系列カラムは文字列型に変換する必要があります。
学習データは、入力データの最後から学習データ量定義に則って定義します。
#-----------------------------------------------
# 学習データレコード数、予測レコード数設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# 予測対象("total load actual")
prediction_length = 96 # the max forecast length for the 512-96 model
#-----------------------------------------------
# モデルカラム定義
#-----------------------------------------------
# 予測対象カラムをリストで定義
target_columns = [ target_column ]
# 時系列カラム"time"を文字列型に変更
# Watsonx の裏側では、HTTP リクエストを通じてモデルにデータを渡すため、
# JSON形式に変換可能なデータ(文字列、数値、配列など)しか渡せません。
input_df[ timestamp_column ] = input_df[ timestamp_column ] .astype(str)
#-----------------------------------------------
# モデルの予測・検証用データの準備
#-----------------------------------------------
# 予測用データ - 最後から512レコードを使う
future_data = input_df.iloc[-context_length:,]
2.2.2.8 インスタンス化
モデル推論インスタンスの作成を行います。
model_id でどのモデルを使うか指定し、api_client で API接続情報(APIキー、project_id など含む)を渡しています。
#-----------------------------------------------
# Watsonx.aiモデルのインスタンス化
#-----------------------------------------------
#モデルの指定 - 512レコードを使い96レコード先を予測するモデルを指定
ts_model_id = client.foundation_models.TimeSeriesModels.GRANITE_TTM_512_96_R2
# モデルインスタンスの初期化と設定 - APIKEYやProject IDをここで使用
ts_model = TSModelInference(model_id=ts_model_id, api_client=client)
2.2.2.9 モデル実行
モデルを実行します。
戻り値は、96レコード分の予測値と時系列データになります。
Watsonx.ai APIの場合は、forecast実行後に以下のように結果が戻されます。
リストではなく、未来の時系列レコードが生成されてカラムに予測結果が格納されます。
| time | total load actual |
|---|---|
| 2018-05-14 16:00:00 | 29782 |
| 2018-05-14 17:00:00 | 29811 |
| 2018-05-14 18:00:00 | 29871 |
#-----------------------------------------------
# モデル実行
#-----------------------------------------------
# 予測用データ(最後から512レコード)でモデル実行
results = ts_model.forecast(data=future_data, params=forecasting_params)['results'][0]
# 予測結果をデータフレームに取り込み - 予測値 96 レコードが格納されている
watsonx_gts_forecast = pd.DataFrame(results)
2.2.2.10 Modelerへデータを戻す
予測結果を、入力データの下に追加してModeler へ戻します。
※. 予測結果をそのまま戻してもいいと思います。レコード追加は、Modelerでもできるので。
Modelerへ戻す際には、時系列カラムが文字列型になっているので、タイムスタンプ型に直してから戻します。
#-----------------------------------------------
# 入力データに予測値を追加して戻す
#-----------------------------------------------
# それぞれのtimeのカラムをtime stampに変換してから追加する
modelerData[ timestamp_column ] = pd.to_datetime(modelerData[ timestamp_column ])
watsonx_gts_forecast[ timestamp_column ] = pd.to_datetime(watsonx_gts_forecast[ timestamp_column ])
# 追加
df_combined = pd.concat([modelerData, watsonx_gts_forecast], ignore_index=True)
# Modelerにデータを戻す
modelerpy.writePandasDataframe(df_combined)
2.3 グラフで確認
最後は予測結果をグラフで確認しましょう。
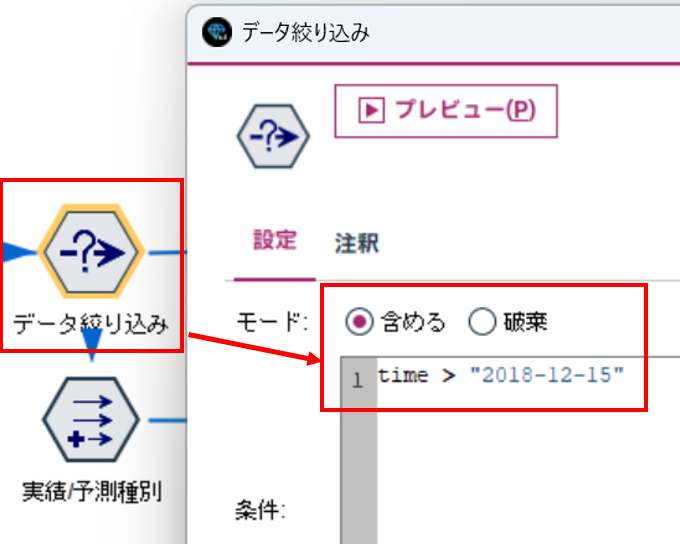
2.3.1 データの絞り込み
全量を表示すると細かくなってしまうので、少量データに絞り込みます。
ここでは、"2018-12-15"以降にしています。
2.3.2 時系列グラフ #1
あとは、時系列グラフで表示するだけです。
時系列グラフノードで、
系列 : total load actual
X軸ラベル : time (ユーザー設定を選択)
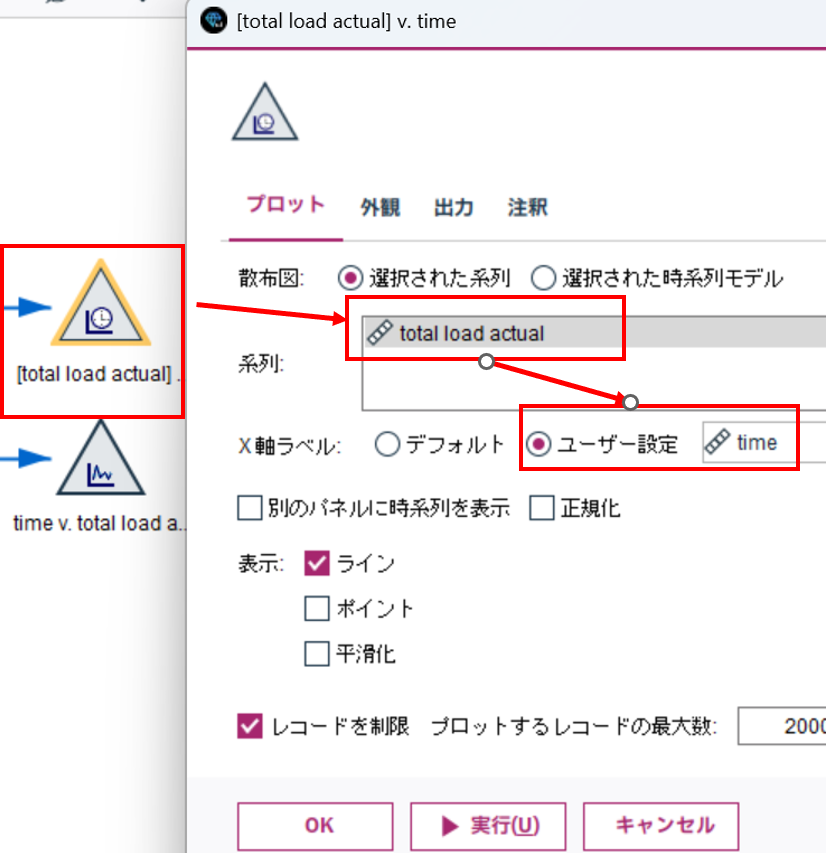
表示すると、以下のような感じです。
ちょっと、実績値と予測値の区別が分かりにくいですね。
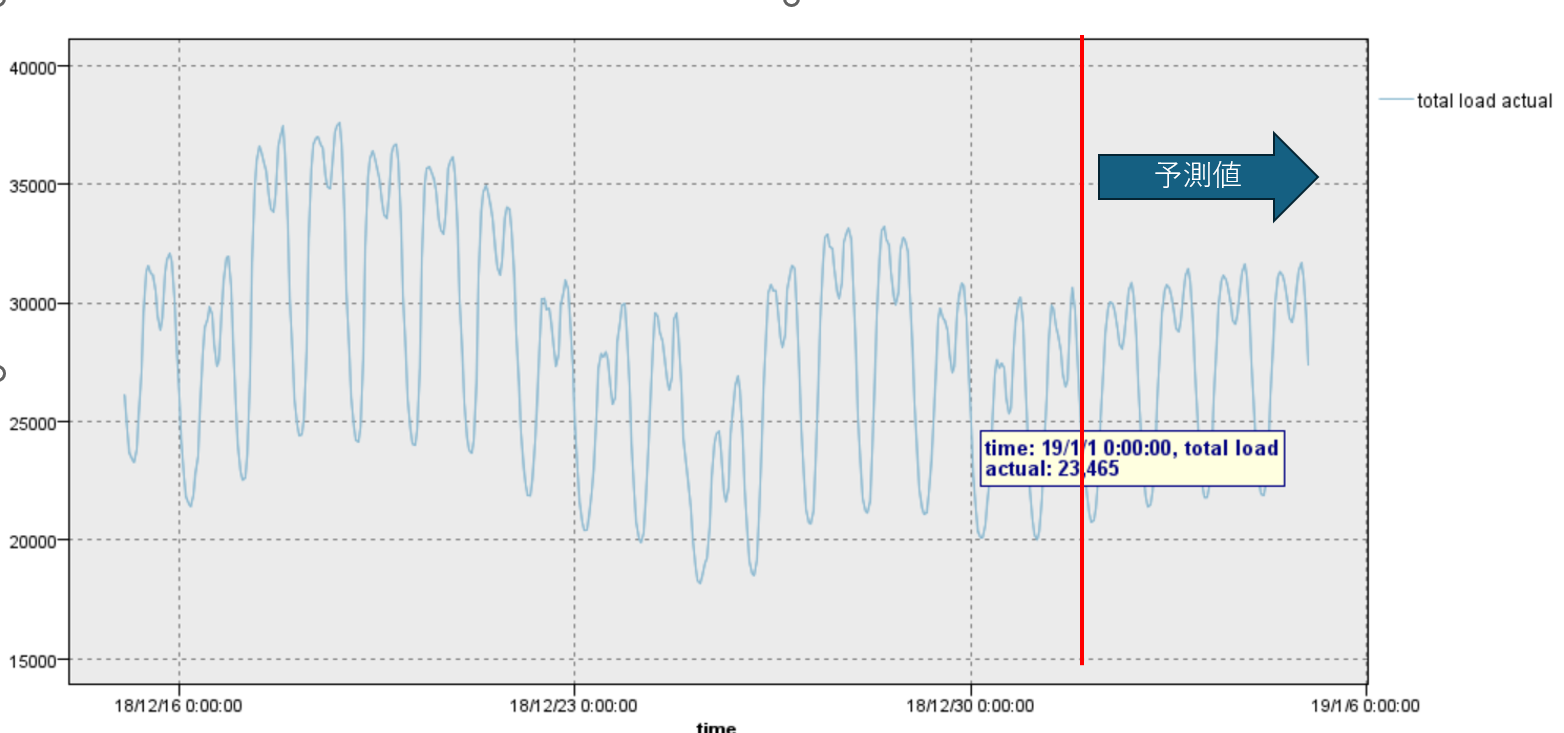
2.3.3 時系列グラフ #2
予測値と実績値を色分けして表示してみましょう。
2.3.3.1 種別フィールドの作成
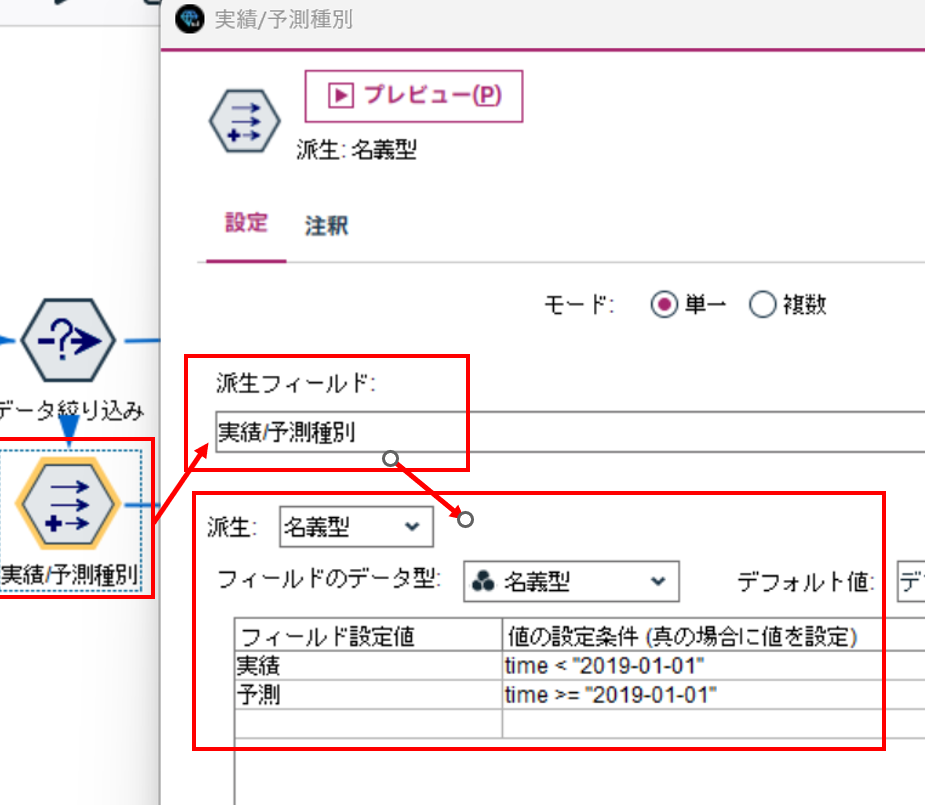
フィールド作成ノードで、実績値と予測値を区別する種別フィールドを作成します。
ここでは、"2019-01-01"から未来が予測値なので、そこで種別を定義しています。
2.3.3.2 散布図ノードで時系列グラフを描く
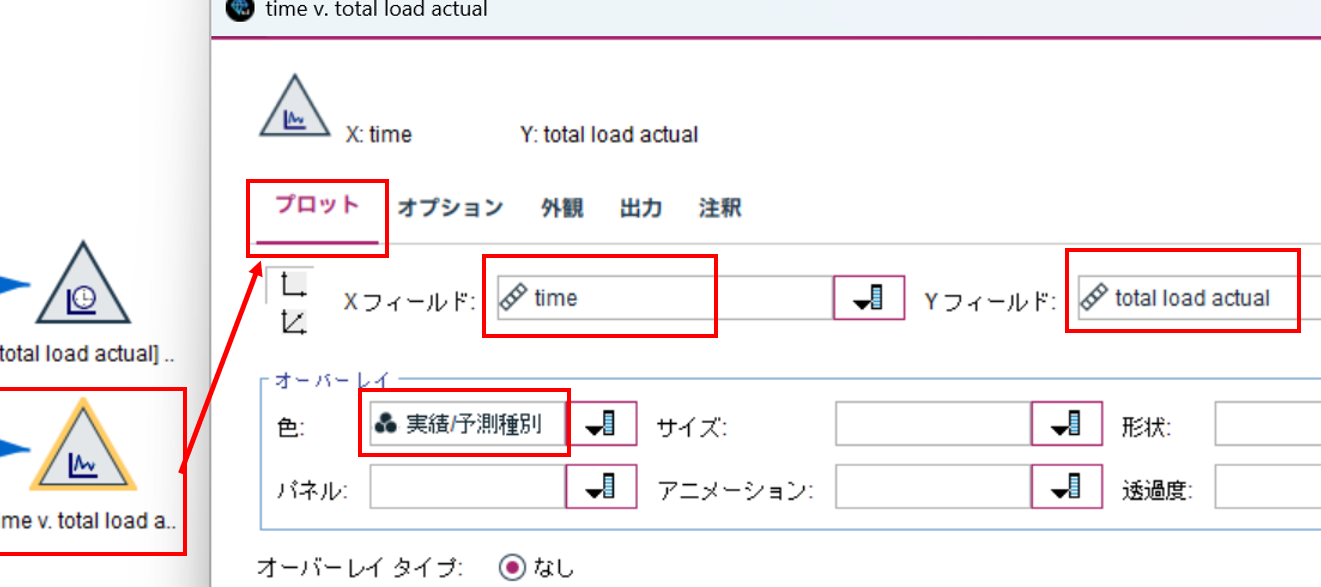
そして、散布図ノード でグラフを描いてみましょう。
プロットタブで、
Xフィールド : time
Yフィールド : total load actual
オーバーレイ 色 : 実績/予測種別
を選択します。
時系列グラフでは、このオーバーレイが指定できないんですよね。
つづいて、オプションタブで
スタイル : 線
を選択して、実行しましょう。
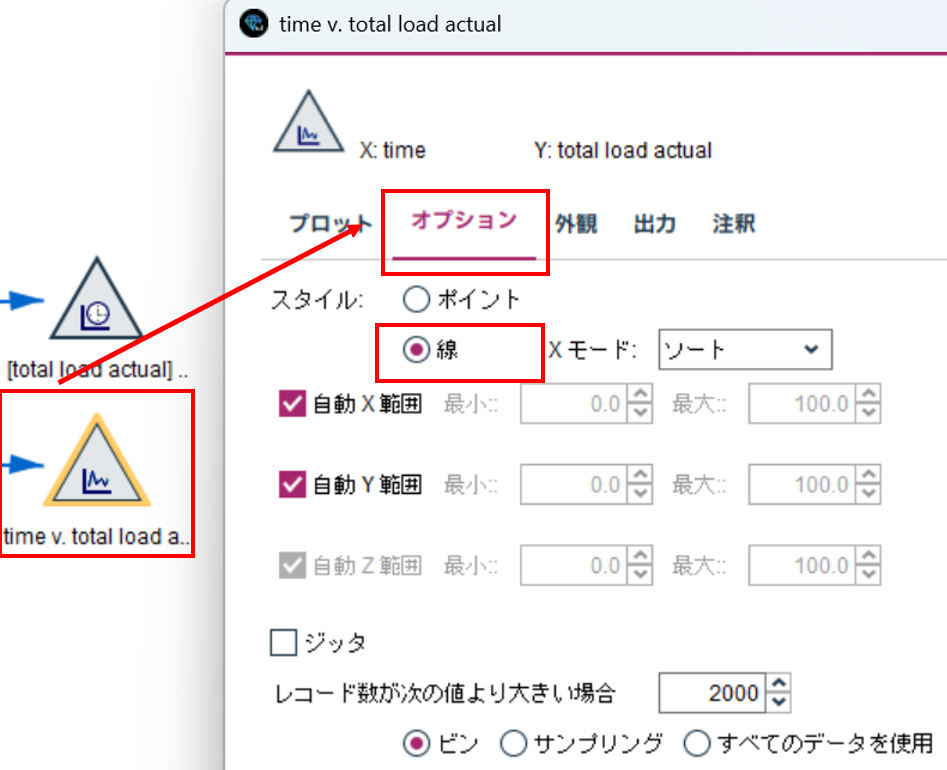
以下のように描画されます。赤い部分が予測値です。
実績と予測の境界でグラフが途切れてしまいますが、まぁ目をつぶりましょう。

散布図ノードはとても便利です。
普通に散布図を描画するだけでなく、線グラフも描画できます。
また、他のグラフノードでは、X軸、Y軸の範囲はそれぞれの値を自動で考慮して範囲が決められてしまいますが、
散布図ノードでは、ユーザーが値の範囲を決めることができます。
ぜひ活用してみてください。
3. まとめ
さて、いかがでしたでしょうか?
Watsonx.ai 上の Granite Time Series Model を APIで呼び出し利用する方法を紹介してきました。
Hugging Faceに公開されているモデルは、Fine-Tuningまで行える点がいいと思いますが、こちらは、モデルを準備しなくてもすぐに利用でき便利ですね。
次回、Modelerの時系列モデルと精度の比較を簡単に実施し、Granite Time Series Model編の最終回にしたいと思っています。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan