はじめに
今回は自然言語処理でよく使われるリカレントニューラルネットワーク(RNN)の進化系である「LSTM」の実装をしていきます。
🌟リカレントニューラルネットワーク(RNN)まとめ(数式なし)
https://qiita.com/hara_tatsu/items/5304479f64297221135d
🌟双方向LSTM(Bidirectional LSTM)の実装
https://qiita.com/hara_tatsu/items/d1ddb5f1e0dee55dcdfa
実装
今回は題材としてkaggleの「映画レビューの感情分析」を利用します。
https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews/data?select=sampleSubmission.csv
細かいフレーズに分割された映画レビューの感情を分析するモデルを構築します。
データの読み込み
必要なライブラリーとデータの読み込み。
import pandas as pd
import numpy as np
# 学習データ
train_data = pd.read_csv('train.tsv', delimiter = '\t')
print(len(train_data))
156060
# テストデータ
test_data = pd.read_csv('test.tsv', delimiter = '\t')
print(len(test_data))
66292
学習データから目的変数を取り出し、ダミー変数に変換。
Y = train_data['Sentiment']
Y = np.array(Y)
# 2次元化
Y = Y.reshape(-1, 1)
# ダミー変数へ変換
from tensorflow.keras.utils import to_categorical
Y = to_categorical(Y)
print(Y.shape)
(156060, 5)
学習データとテストデータから説明変数を取り出し、結合する。
# 学習データ
train = train_data['Phrase']
# テストデータ
test = test_data['Phrase']
# 学習データとテストデータを結合
total_data = pd.concat([train, test], axis=0)
print(len(total_data))
222352
自然言語の前処理
🌟自然言語の前処理の基本
①テキストを単語ごとに分割
②不要な単語を削除(#$%&+*など)
③数値化(ベクトル化)
今回は、テキストが英語のため、すでに単語ごとに区切りがあり不要な単語もない。
そのため、数値化の処理のみ行う。
🌟単語の数値化(ベクトル化)手法
・one_hotエンコーディング
・シンプルな数値化
・学習済モデルを使った数値化(Word2vec)
今回は、Tensorflowにある単語を数値化できるライブラリー「Tokenizer」を利用する。
「Tokenizer」を利用するにはデータをリスト型にする必要がある。
# numpy型へ変換
total_np = np.array(total_data)
# リスト型へ変換
total_list = total_np.tolist()
「Tokenizer」を利用してテキストを数値化
from tensorflow.keras.preprocessing.text import Tokenizer
# インスタンスを生成
keras_tokenizer = Tokenizer()
# 単語からデータを学習
keras_tokenizer.fit_on_texts(total_list)
# 学習した単語数
len(keras_tokenizer.word_index)
17780
# 単語を数値に変換
sequence_data = keras_tokenizer.texts_to_sequences(total_list)
# 1つ目のデータの変換結果
print(sequence_data[0])
[2, 315, 3, 16573, 7660, 1, 8313, 9, 53, 8, 47, 13, 1, 3940, 8, 187, 47, 13, 1, 13024, 61, 3, 89, 592, 12156, 19, 617, 3, 89, 2810, 5, 52, 3, 2, 42]
単語を数値に変換できたが、データごとに数値の長さが違っている。
# データによって数値の長さが違う
print(len(sequence_data[0]))
print(len(sequence_data[1]))
35
14
一番数値の長いデータに合わせるため、短いデータは「0」埋めすることで全てのデータの長さを揃える
from tensorflow import keras
X = keras.preprocessing.sequence.pad_sequences(sequence_data, padding = 'post')
print(len(X[0]))
print(len(X[1]))
52
52
これで自然言語の前処理が終わった。
次に学習用データ、検証用データ、テストデータに分割する。
# 学習データとテストデータを分割
train = X[:156060]
test = X[156060:]
print(train.shape)
print(test.shape)
(156060, 52)
(66292, 52)
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(train, Y, test_size = 0.2, random_state = 0)
X_train, X_valid, Y_train, Y_valid = train_test_split(X_train, Y_train, test_size=0.2, random_state=0)
print(X_train.shape)
print(Y_train.shape)
print(X_valid.shape)
print(Y_valid.shape)
print(X_test.shape)
print(Y_test.shape)
(99878, 52)
(99878, 5)
(24970, 52)
(24970, 5)
(31212, 52)
(31212, 5)
🌟「Tokenizer」を使用する際の注意点
「Tokenizer」は、与えた単語のデータを学習して数値へ変換する。そのため、学習後に未知の単語データを与えても対応することができない。
対処方法としては、
①未知の単語データは削除する
②「Tokenizer」ではなく、学習済モデルを使って数値化する
今回のようなコンペやデータ分析をするためのモデルであれば「Tokenizer」で問題ないが、凡化性のある自然言語AIアプリを作る場合は、学習済モデルを使用した方がいい。
LSTMの実装
モデルの構築
from tensorflow.keras.layers import LSTM, Embedding, Dense
model = keras.Sequential()
# 埋め込み層(数値をベクトル表現化)
# 17781:単語の種類+1、mask_zero = True:0を0埋め用の数値として扱う
model.add(Embedding(17781, 64, mask_zero = True))
# LSTM層
model.add(LSTM(64, return_sequences=True))
model.add(LSTM(32))
model.add(Dense(5, activation = 'sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
lstm_4 (LSTM) (None, None, 64) 33024
_________________________________________________________________
dropout (Dropout) (None, None, 64) 0
_________________________________________________________________
lstm_5 (LSTM) (None, 32) 12416
_________________________________________________________________
dense_4 (Dense) (None, 5) 165
=================================================================
Total params: 1,183,589
Trainable params: 1,183,589
Non-trainable params: 0
_________________________________________________________________
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
結果の確認
import matplotlib.pyplot as plt
# グラフ表示
plt.plot(log.history['loss'], label='loss')
plt.plot(log.history['val_loss'], label='val_loss')
plt.legend(frameon=False)
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
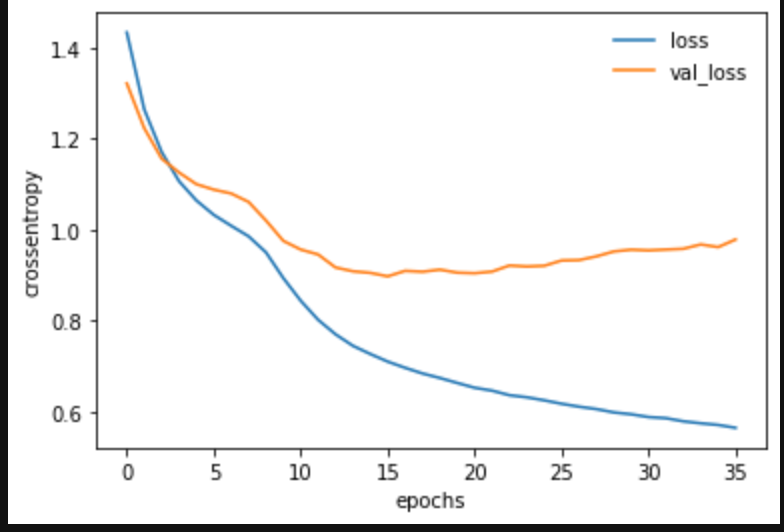
# グラフ表示
plt.plot(log.history['accuracy'], label='accuracy')
plt.plot(log.history['val_accuracy'], label='val_accuracy')
plt.legend(frameon=False)
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
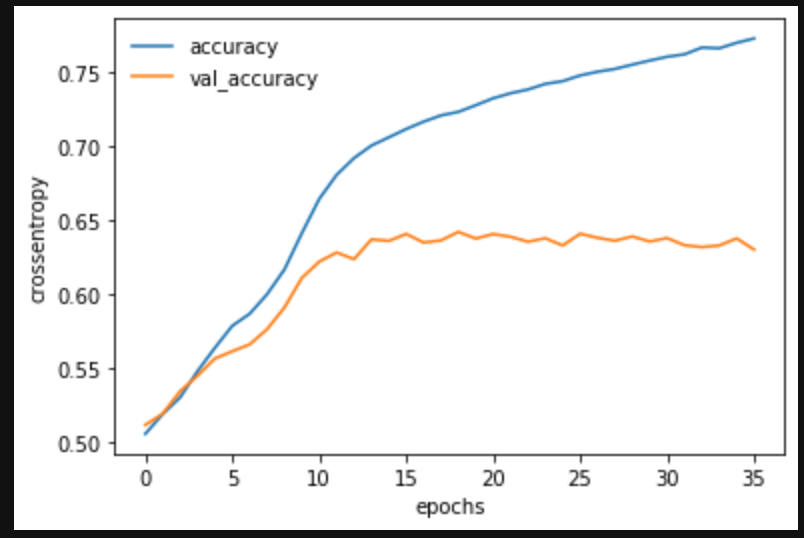
# テスト用データ(Y_test)をダミー変数から通常の数値へ復元
Y_test_ = np.argmax(Y_test, axis=1)
from sklearn.metrics import classification_report
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.41 0.33 0.37 1504
1 0.50 0.57 0.53 5453
2 0.76 0.74 0.75 15982
3 0.54 0.53 0.53 6441
4 0.45 0.50 0.47 1832
accuracy 0.63 31212
macro avg 0.53 0.53 0.53 31212
weighted avg 0.64 0.63 0.63 31212
正解率63%!!
過学習対策
最後に過学習対策を施したモデルを構築。
model = keras.Sequential()
model.add(Embedding(17781, 64, mask_zero = True))
# LSTM層
model.add(LSTM(64,
dropout=0.1,
recurrent_dropout=0.5,
return_sequences=True))
model.add(LSTM(32,
dropout=0.1,
recurrent_dropout=0.5))
model.add(Dense(5, activation = 'sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
lstm_8 (LSTM) (None, None, 64) 33024
_________________________________________________________________
lstm_9 (LSTM) (None, 32) 12416
_________________________________________________________________
dense_6 (Dense) (None, 5) 165
=================================================================
Total params: 1,183,589
Trainable params: 1,183,589
Non-trainable params: 0
_________________________________________________________________
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
%%time
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
# グラフ表示
plt.plot(log.history['loss'], label='loss')
plt.plot(log.history['val_loss'], label='val_loss')
plt.legend(frameon=False)
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
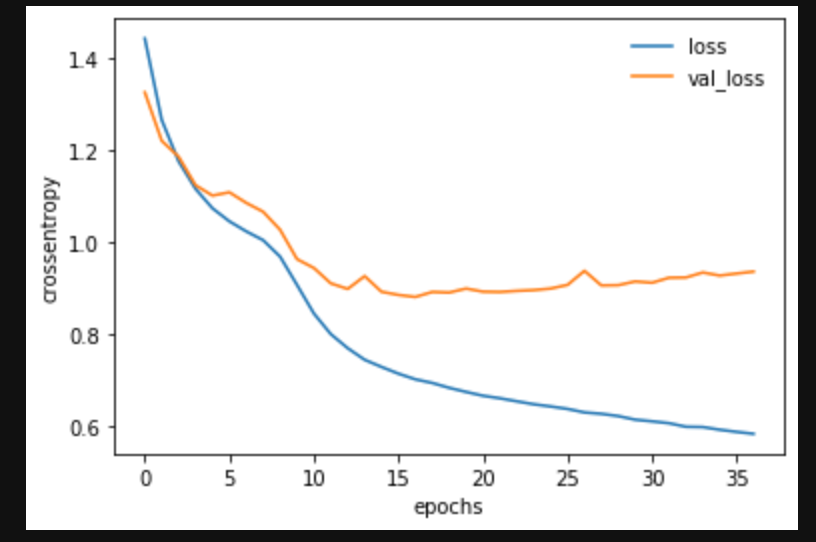
# グラフ表示
plt.plot(log.history['accuracy'], label='accuracy')
plt.plot(log.history['val_accuracy'], label='val_accuracy')
plt.legend(frameon=False)
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
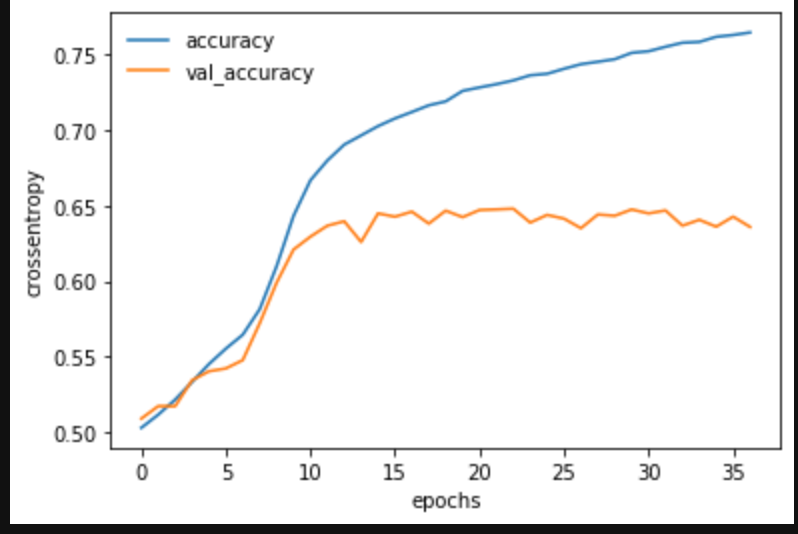
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.46 0.42 0.44 1504
1 0.52 0.57 0.54 5453
2 0.77 0.73 0.75 15982
3 0.54 0.56 0.55 6441
4 0.49 0.48 0.48 1832
accuracy 0.64 31212
macro avg 0.55 0.55 0.55 31212
weighted avg 0.64 0.64 0.64 31212
正解率64%!!
おわりに
過学習対策をしてもあまり結果は変わりませんでした。
kaggleのリーダーボードを確認しても同じような正解率で停滞しています。
※コード内の「LSTM」を「GRU」に変更すれば「GRU」を使った学習ができます。