はじめに
今回は自然言語処理でよく使われる「双方向LSTM」の実装をしていきます。
🌟リカレントニューラルネットワーク(RNN)まとめ(数式なし)
https://qiita.com/hara_tatsu/items/5304479f64297221135d
🌟LSTMの実装(RNN・自然言語処理の前処理)
https://qiita.com/hara_tatsu/items/c3ba100e95e600846125
双方向LSTMとは
通常の「LSTM」は、時系列の古い順(文章であれば前から)に学習して次の単語の意味を予測する。
「①エンジニア ②の ③山田 ④は ⑤WEBアプリ ⑥を ⑦作成する ⑧。」
上記のような文章に対し、「③山田」の意味を理解するのに、「①エンジニア」 と 「②の」で予測する。
このような単純な文章なら問題ないが、複雑な文章であればこの手法での予測は難しい。
そこで、「双方向から学習することで前後の文脈から単語の意味を予測する」双方向LSTMが生まれた。
✅双方向LSTMは2つの学習器をもつ。
❶Forward LSTM(通常のLSTM)
「①エンジニア と ②の」で「③山田」を予測
❷backward LSTM(後ろの単語から学習)
「④は ⑤WEBアプリ ⑥を ⑦作成する ⑧。」で「③山田」を予測
🌟この2つの学習器を組み合わせることで前後の文脈から「③山田」を予測することを実現した。
実装
今回は題材としてkaggleの「映画レビューの感情分析」を利用します。
https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews/data?select=sampleSubmission.csv
細かいフレーズに分割された映画レビューの感情を分析するモデルを構築します。
🌟自然言語処理の前処理はこちらの記事で詳しく解説していますので参照してください!!
https://qiita.com/hara_tatsu/items/c3ba100e95e600846125
双方向RNNの実装
# モデルの構築
# Bidirectional(双方向RNN)
from tensorflow.keras.layers import Embedding, Dense, Bidirectional, LSTM
model = keras.Sequential()
# mask_zero = True(0を0埋め用の数値として扱ってくれる)
model.add(Embedding(17781, 64, mask_zero = True))
# LSTM層(return_sequences=True:完全な系列を返す(Flase:最後の出力を返す(LSTMを多層でできる)))
model.add(Bidirectional(LSTM(64, return_sequences=True)))
model.add(Bidirectional(LSTM(32)))
model.add(Dense(5, activation = 'softmax'))
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
lstm_4 (LSTM) (None, None, 64) 33024
_________________________________________________________________
dropout (Dropout) (None, None, 64) 0
_________________________________________________________________
lstm_5 (LSTM) (None, 32) 12416
_________________________________________________________________
dense_4 (Dense) (None, 5) 165
=================================================================
Total params: 1,183,589
Trainable params: 1,183,589
Non-trainable params: 0
_________________________________________________________________
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
結果の確認
import matplotlib.pyplot as plt
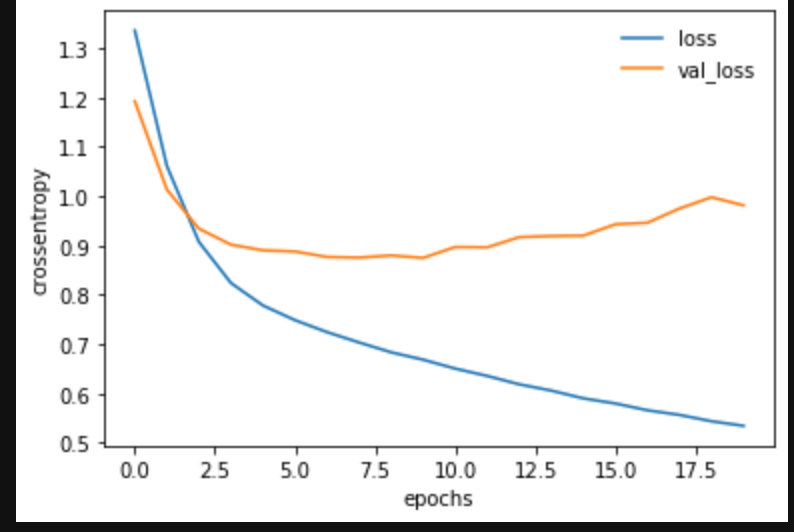
# 損失値
plt.plot(log.history['loss'], label='loss')
plt.plot(log.history['val_loss'], label='val_loss')
plt.legend(frameon=False) # 凡例の表示
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
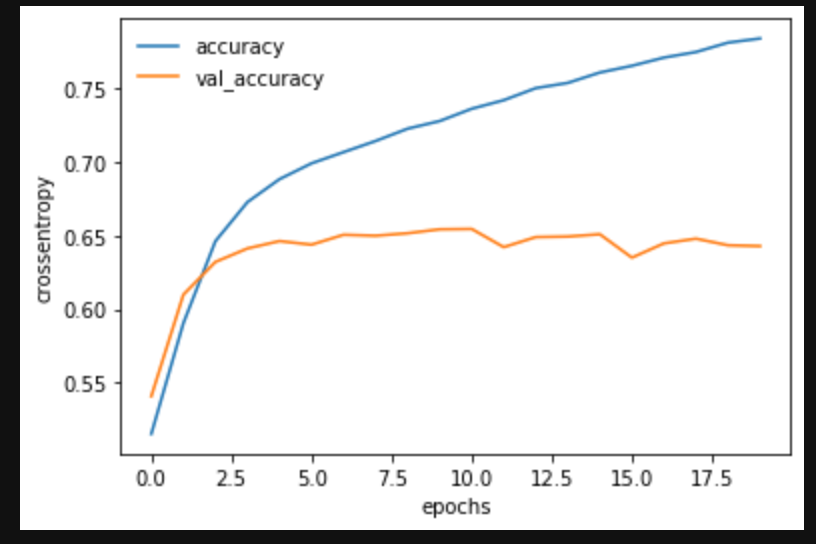
# 正解率
plt.plot(log.history['accuracy'], label='accuracy')
plt.plot(log.history['val_accuracy'], label='val_accuracy')
plt.legend(frameon=False) # 凡例の表示
plt.xlabel("epochs")
plt.ylabel("crossentropy")
plt.show()
テストデータを用いて結果を確認
# テスト用データ(Y_test)をダミー変数から通常の数値へ復元
Y_test_ = np.argmax(Y_test, axis=1)
from sklearn.metrics import classification_report
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.47 0.39 0.43 1504
1 0.51 0.59 0.54 5453
2 0.75 0.77 0.76 15982
3 0.56 0.54 0.55 6441
4 0.55 0.38 0.45 1832
accuracy 0.65 31212
macro avg 0.57 0.53 0.55 31212
weighted avg 0.65 0.65 0.64 31212
正解率 65%!!!
過学習対策
model = keras.Sequential()
model.add(Embedding(17781, 64, mask_zero = True))
model.add(Bidirectional(LSTM(64,
dropout=0.1,
recurrent_dropout=0.5,
return_sequences=True)))
model.add(Bidirectional(LSTM(32,
dropout=0.1,
recurrent_dropout=0.5,)))
model.add(Dense(5, activation = 'softmax'))
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
bidirectional_3 (Bidirection (None, None, 128) 66048
_________________________________________________________________
bidirectional_4 (Bidirection (None, 64) 41216
_________________________________________________________________
dense_3 (Dense) (None, 5) 325
=================================================================
Total params: 1,245,573
Trainable params: 1,245,573
Non-trainable params: 0
_________________________________________________________________
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
結果の確認
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.49 0.38 0.43 1504
1 0.49 0.63 0.55 5453
2 0.76 0.76 0.76 15982
3 0.58 0.53 0.55 6441
4 0.55 0.42 0.48 1832
accuracy 0.65 31212
macro avg 0.57 0.54 0.55 31212
weighted avg 0.65 0.65 0.65 31212
おわりに
過学習対策をしてもあまり結果は変わりませんでした。
kaggleのリーダーボードを確認しても同じような正解率で停滞しています。
ただ、通常の「LSTM」よりも僅かながら良い正解率でした!!
CPU環境だと20〜30分くらいの学習時間がかかってしまうのが難点ですね。