はじめに
今回は、【SIGNATE】の練習問題である「自動車の評価」にチャレンジします!!
環境情報
Python 3.6.5
【SIGNATE】自動車の評価について
自動車の情報から自動車の評価値(unacc, acc, good, vgood)を予測する問題です。
以下リンク
https://signate.jp/competitions/122
挑戦
データを読み込んで可視化
python.py
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('train.tsv', delimiter = '\t')
# idは削除
df = df.drop('id', axis = 1)
print(len(df))
df.head()
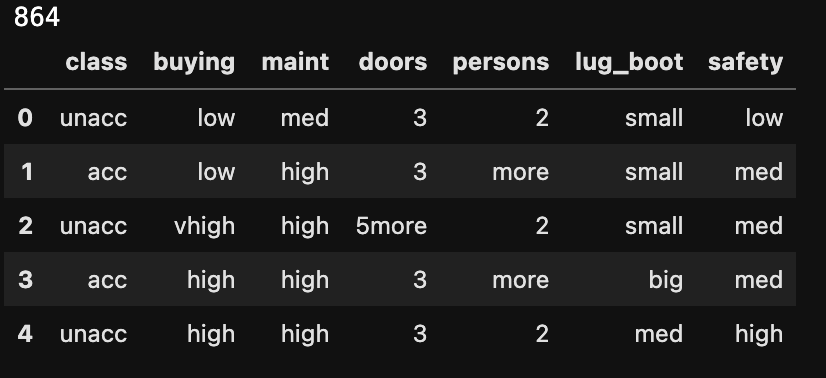
データ数:864
目的変数:class
説明変数:6つ
目的変数を可視化
python.py
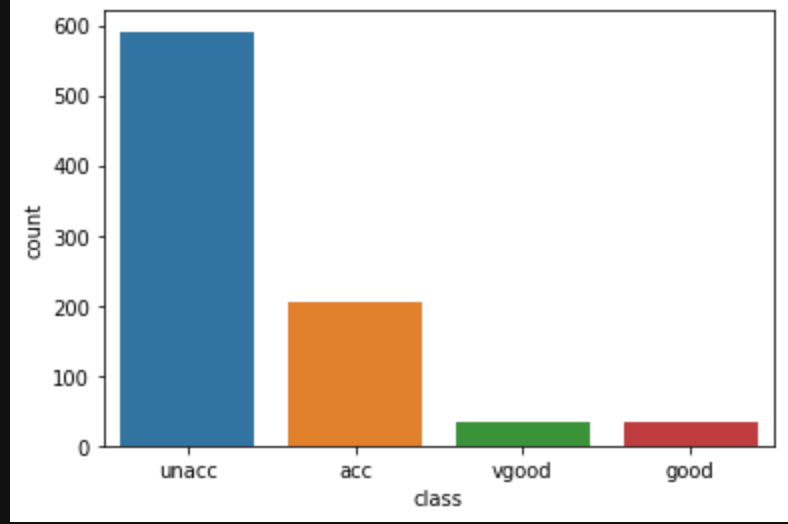
sns.countplot(x='class', data=df)
ほとんどのデータが「unacc」、「acc」になってますね。
データの数値化
python.py
# 説明変数
df = df.replace({'buying': {'low': 1, 'med': 2, 'high': 3, 'vhigh': 4}})
df = df.replace({'maint': {'low': 1, 'med': 2, 'high': 3, 'vhigh': 4}})
df = df.replace({'doors': {'5more': 6}})
df = df.replace({'persons': {'more': 6}})
df = df.replace({'lug_boot': {'small': 1, 'med': 2, 'big': 3}})
df = df.replace({'safety': {'low': 1, 'med': 2, 'high': 3}})
# 目的変数
df = df.replace({'class': {'unacc': 1, 'acc': 2, 'good': 3, 'vgood': 4}})
※「doors」,「persons」の一部が数字の文字列のままですが、学習可能なモデルを使うので無視しています。
評価データとテストデータに分類
python.py
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(df, test_size=0.2, random_state = 0)
# 訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割
X_train = train_set.drop('class', axis=1)
y_train = train_set['class']
# 評価データを説明変数データ(X_train)と目的変数データ(y_train)に分割
X_test = test_set.drop('class', axis=1)
y_test = test_set['class']
最適モデルの検討
python.py
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# 正解率
from sklearn.metrics import accuracy_score
# モデルをリストに格納
model_list = []
# ロジスティック回帰
model_list.append(LogisticRegression(solver = 'lbfgs', multi_class = 'multinomial'))
# ランダムフォレスト
model_list.append(RandomForestClassifier(n_estimators=100))
# サポートベクターマシン
model_list.append(SVC(gamma = 'scale'))
# for文を利用して学習と正解率を出す
for i in model_list:
i.fit(X_train, y_train)
pred = i.predict(X_test)
print(accuracy_score(y_test, pred))
結果は以下のとおり
0.8034682080924855
0.953757225433526
0.9017341040462428
ランダムフォレストの正解率が高い
パラメーターの最適化
python.py
# グリットサーチ
from sklearn.model_selection import GridSearchCV
# 試すパラメーターの設定
search_gs = {
"max_depth": [None, 5, 10],
"n_estimators":[50, 100],
"min_samples_split": [4, 10],
"min_samples_leaf": [3, 10],
}
model_gs = RandomForestClassifier()
gs = GridSearchCV(model_gs, search_gs, cv = 3, iid = False)
gs.fit(X_train, y_train)
print(gs.best_params_)
最適なパラメーターは以下のとおり
{'max_depth': None, 'min_samples_leaf': 3, 'min_samples_split': 4, 'n_estimators': 50}
python.py
# 最適なパラメーターを設定
clf_rand = RandomForestClassifier(max_depth = None, min_samples_leaf = 3, min_samples_split = 4, n_estimators =50)
model_rand = clf_rand.fit(X_train, y_train)
pred_rand = model_rand.predict(X_test)
# モデルの評価
from sklearn import metrics
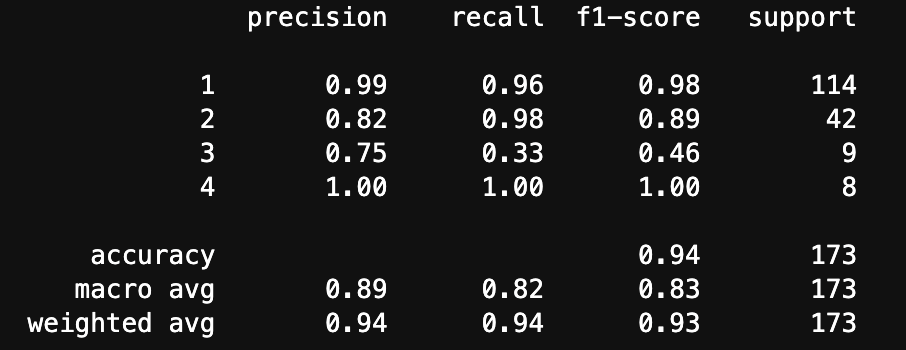
print(metrics.classification_report(y_test, pred_rand))
結果は以下のとおり
結果の提出
算定評価: 0.9710648
順位 : 115位
でした!!