はじめに
今回は自然言語処理でよく使われる「1次元畳み込みニューラルネットワーク」の実装をしていきます。
🌟リカレントニューラルネットワーク(RNN)まとめ(数式なし)
https://qiita.com/hara_tatsu/items/5304479f64297221135d
🌟LSTMの実装(RNN・自然言語処理の前処理)
https://qiita.com/hara_tatsu/items/c3ba100e95e600846125
🌟双方向LSTM(Bidirectional LSTM)の実装
https://qiita.com/hara_tatsu/items/d1ddb5f1e0dee55dcdfa
1次元畳み込みニューラルネットワークとは
2次元畳み込みニューラルネットワークは、画像処理分野で利用されている。
1次元畳み込みニューラルネットワークはテキスト分類や時系列予測で成果を出しているモデル。
また、RNNやLSTMよりも計算コストが非常に少ない。
実装
今回は題材としてkaggleの「映画レビューの感情分析」を利用します。
https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews/data?select=sampleSubmission.csv
細かいフレーズに分割された映画レビューの感情を分析するモデルを構築します。
🌟自然言語処理の前処理はこちらの記事で詳しく解説していますので参照してください!!
https://qiita.com/hara_tatsu/items/c3ba100e95e600846125
1次元畳み込みニューラルネットワークの実装
# モデルの構築
from tensorflow.keras.layers import LSTM, Embedding, Dense, Conv1D, MaxPooling1D, GlobalMaxPooling1D
model = keras.Sequential()
model.add(Embedding(17781, 64, mask_zero = True))
# 1次元の畳み込み層
model.add(Conv1D(64, 7, activation = 'relu'))
# 1次元のプーリング層
model.add(MaxPooling1D(5))
model.add(Conv1D(32, 7, activation = 'relu'))
# 時系列データのためのグローバルなマックスプーリング層
model.add(GlobalMaxPooling1D())
model.add(Dense(5, activation = 'sigmoid'))
model.summary()
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
conv1d_7 (Conv1D) (None, None, 64) 28736
_________________________________________________________________
max_pooling1d_4 (MaxPooling1 (None, None, 64) 0
_________________________________________________________________
conv1d_8 (Conv1D) (None, None, 32) 14368
_________________________________________________________________
global_max_pooling1d_2 (Glob (None, 32) 0
_________________________________________________________________
dense_3 (Dense) (None, 5) 165
=================================================================
Total params: 1,181,253
Trainable params: 1,181,253
Non-trainable params: 0
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
結果の確認
import matplotlib.pyplot as plt
acc = log.history['accuracy']
val_acc = log.history['val_accuracy']
loss = log.history['loss']
val_loss = log.history['val_loss']
epochs_range = range(29)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.show()
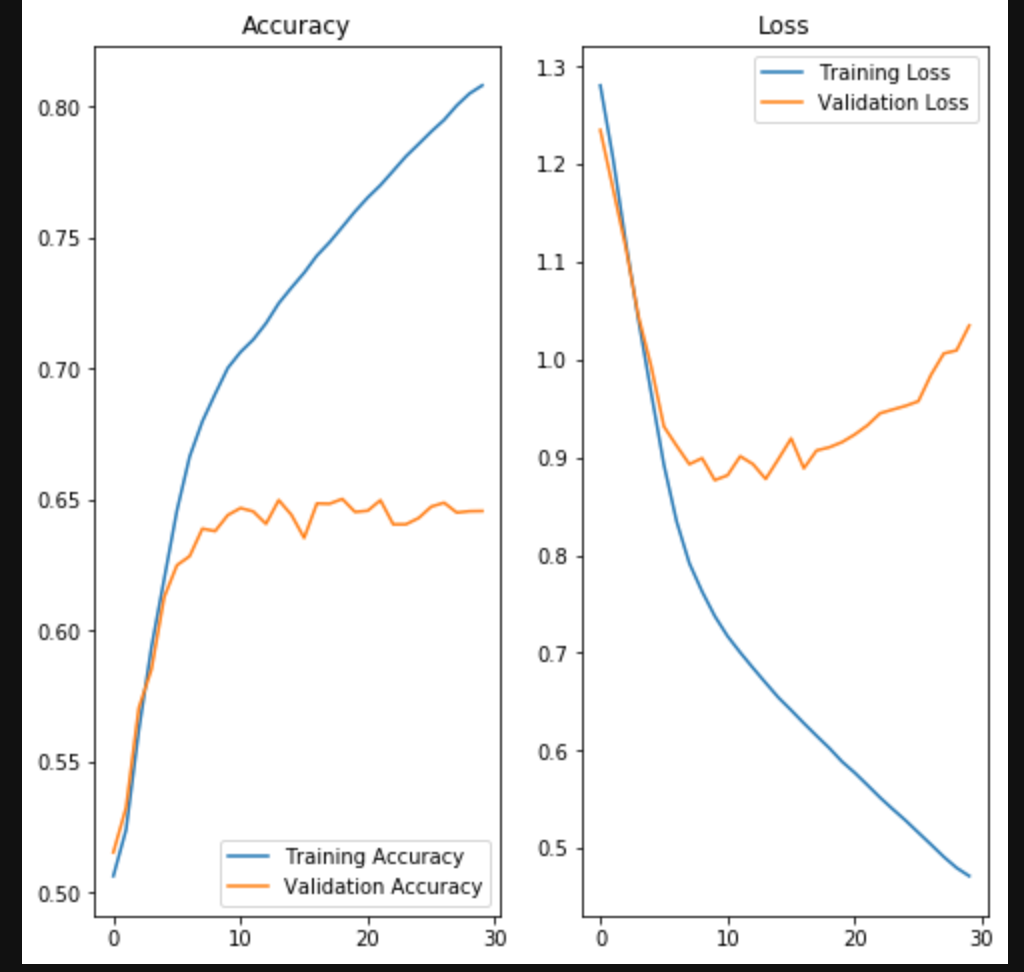
テストデータを用いて結果を確認
# テスト用データ(Y_test)をダミー変数から通常の数値へ復元
Y_test_ = np.argmax(Y_test, axis=1)
from sklearn.metrics import classification_report
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.53 0.34 0.41 1504
1 0.54 0.49 0.51 5453
2 0.72 0.81 0.76 15982
3 0.56 0.55 0.56 6441
4 0.57 0.32 0.41 1832
accuracy 0.65 31212
macro avg 0.58 0.50 0.53 31212
weighted avg 0.64 0.65 0.64 31212
正解率 65%!!!
学習時間 3分31秒
【参考】
🌟双方向LSTM
正解率 65%
学習時間 23分11秒
✅双方LSTMと比べると正解率は変わらないのに学習時間が大幅に少なくなりました。
LSTM層の追加
最後に1次元畳み込みニューラルネットワークにLSTM層を追加して見ようと思います。
model = keras.Sequential()
model.add(Embedding(17781, 64, mask_zero = True))
model.add(Conv1D(64, 7, activation = 'relu'))
model.add(MaxPooling1D(5))
model.add(Conv1D(32, 7, activation = 'relu'))
# LSTM層
model.add(LSTM(64,
dropout=0.1,
recurrent_dropout=0.5))
model.add(Dense(5, activation = 'sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, None, 64) 1137984
_________________________________________________________________
conv1d_9 (Conv1D) (None, None, 64) 28736
_________________________________________________________________
max_pooling1d_5 (MaxPooling1 (None, None, 64) 0
_________________________________________________________________
conv1d_10 (Conv1D) (None, None, 32) 14368
_________________________________________________________________
lstm_2 (LSTM) (None, 64) 24832
_________________________________________________________________
dense_4 (Dense) (None, 5) 325
=================================================================
Total params: 1,206,245
Trainable params: 1,206,245
Non-trainable params: 0
_________________________________________________________________
model.compile(loss= 'categorical_crossentropy',
optimizer= 'rmsprop',
metrics = ['accuracy'])
log = model.fit(X_train, Y_train, epochs = 100, batch_size = 2048,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=20,
verbose=1)],
validation_data=(X_valid, Y_valid))
結果の確認
Y_pred = model.predict_classes(X_test)
print(classification_report(Y_test_, Y_pred))
precision recall f1-score support
0 0.38 0.46 0.42 1504
1 0.48 0.50 0.49 5453
2 0.75 0.73 0.74 15982
3 0.53 0.51 0.52 6441
4 0.47 0.48 0.47 1832
accuracy 0.62 31212
macro avg 0.52 0.54 0.53 31212
weighted avg 0.62 0.62 0.62 31212
正解率 62%!!
おわりに
今回は、自然言語処理で1次元畳み込みニューラルネットを実装してみました。
正解率は、LSTMや双方向LSTMと変わりませんでしたが、学習時間が大幅に短縮できました!!