tl;dr
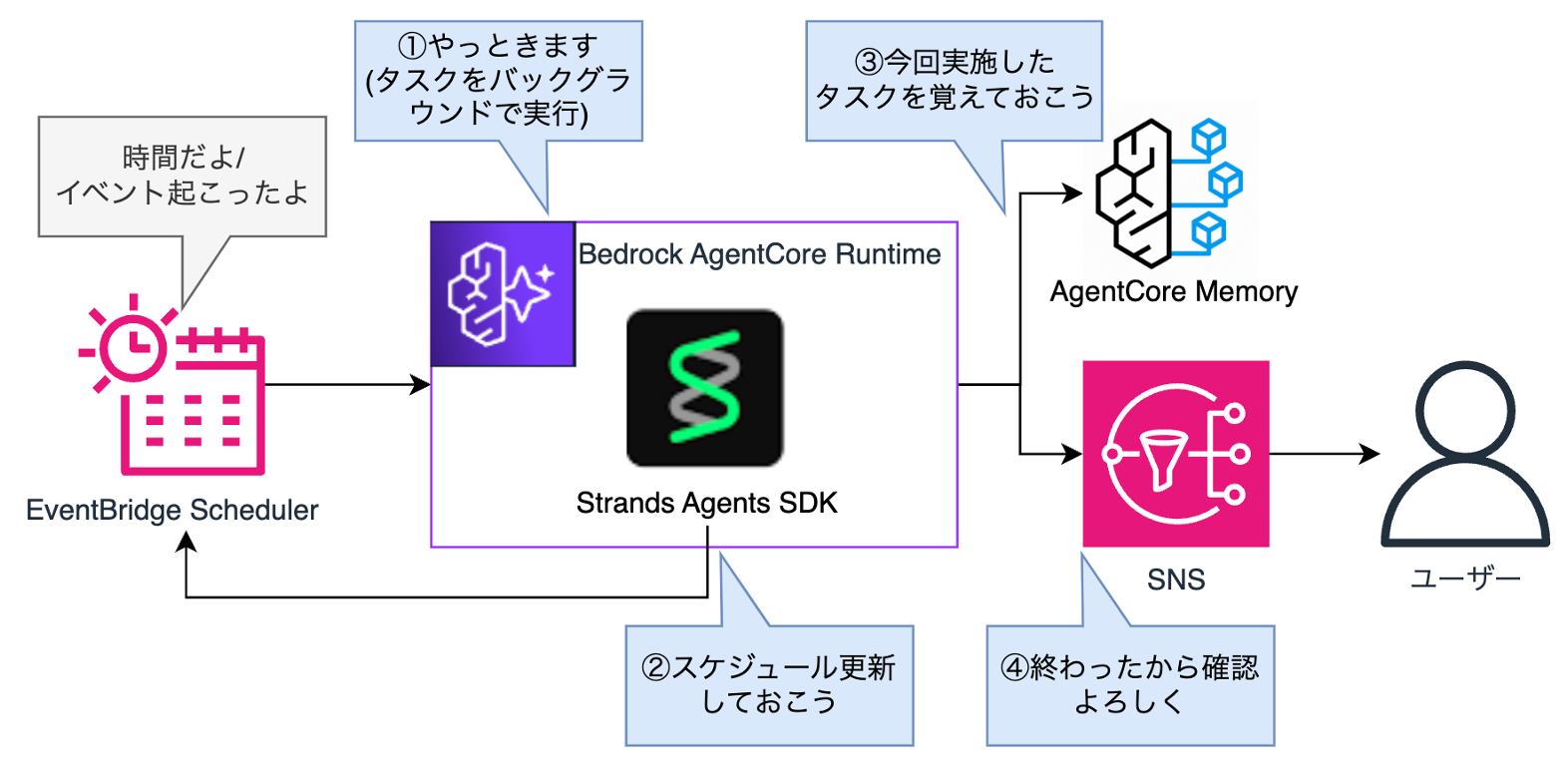
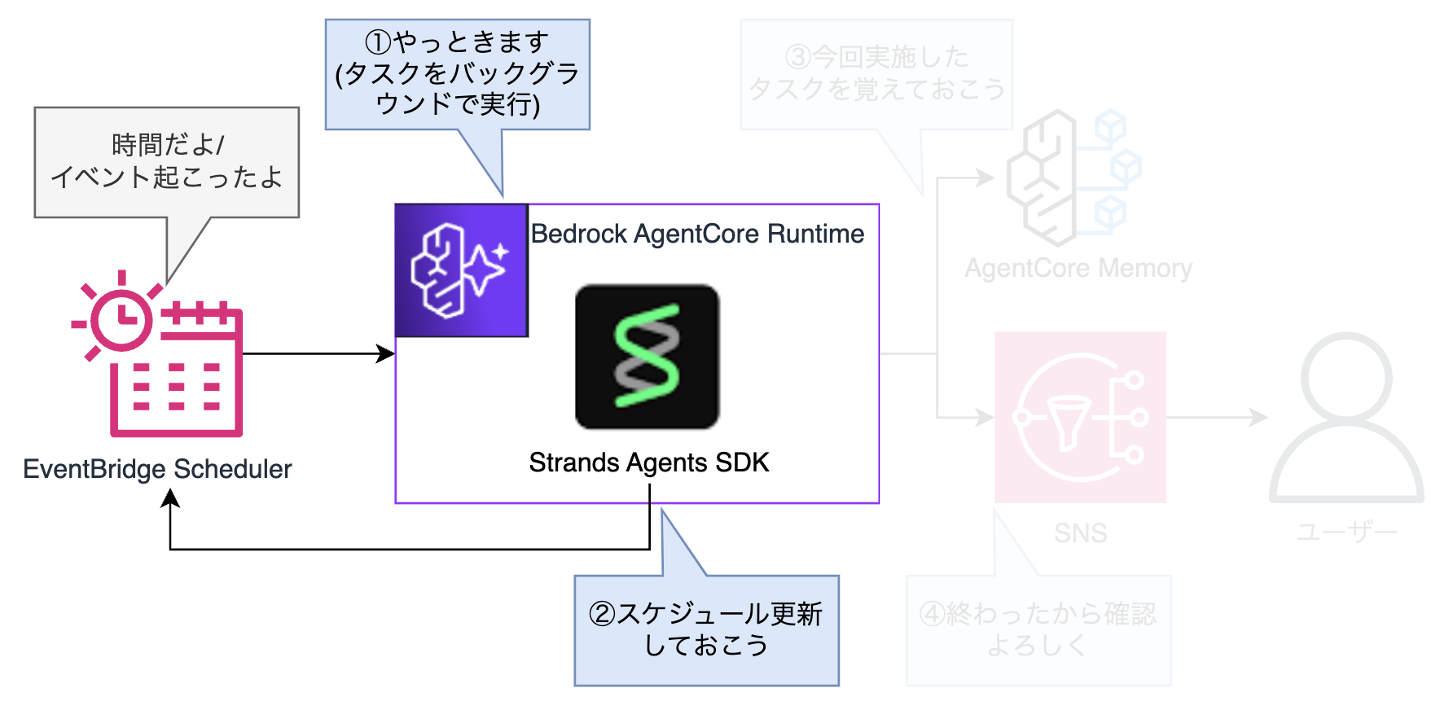
- EventBridge SchedulerからAgentCore Runtimeを直接起動できるようになった
- この時、AgentCore Runtime内でエージェントを非同期実行させる
- スケジュール駆動エージェント実装のポイントは以下3点
- 次のタスク実行スケジュールをエージェント自身に考え、更新させる
- 毎回の作業進捗をメモリーとして保存しておく
- 完了時の通知を入れておく
- 詳細な解説は当記事と以下スライド参照
はじめに
こんにちは、ふくちです。
今回はスケジュール駆動AIエージェントをAWS上で構築していこうと思います。
以前作成した記事・登壇資料からいくらかアップデートがあるので、違いを中心に解説していきます。
スケジュール駆動エージェントを構築する
今回のポイントは以下です。
- スケジュール駆動でエージェントを動かすこと
- 単発のスケジュール実行で終わらないこと
- 以前の実行内容を含むコンテキストを適切に与えること
- 完了時に通知すること
特に、できるだけ自律的にエージェントが動くような世界線を目指してみました。
良い改善案などあればぜひ教えて下さい!
具体的な実装については以下をご参照ください。
1.EventBridgeからAgentCore Runtimeを起動する
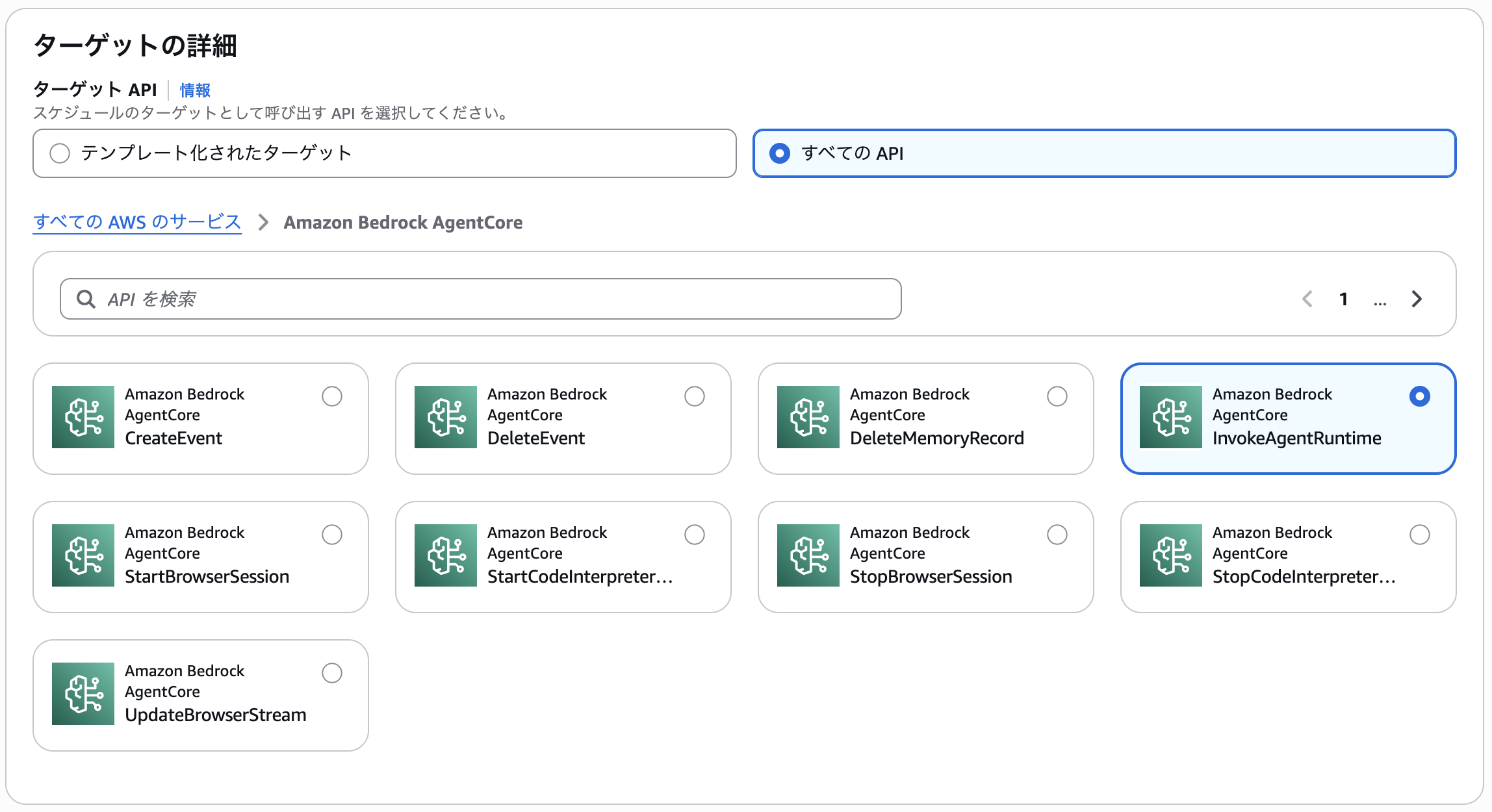
以前の記事では「EventBridgeからAgentCore Runtimeを直接起動することができない」と紹介していましたが、いつの間にかできるようになっていました。
具体的には、EventBridge Schedulerの「すべてのAPI」でAgentCoreを検索するとInvokeAgentRuntimeが出てきます。
最低限の入力ペイロードは以下です。ARNはご自身のエージェントARN、Payloadはエージェントが受け付ける入力値です。
{
"AgentRuntimeArn": "MyData",
"Payload": "BLOB"
}
Schedulerサービスロールに、AgentCore Runtimeを起動する権限だけ忘れずに与えてあげてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock-agentcore:InvokeAgentRuntime"
],
"Resource": [
"arn:aws:bedrock-agentcore:ap-northeast-1:123456789012:runtime/<ランタイムID>",
"arn:aws:bedrock-agentcore:ap-northeast-1:123456789012:runtime/<ランタイムID>/runtime-endpoint/DEFAULT"
]
}
]
}
2.エージェント自身に次回の実行スケジュールを更新させる
続いて、単発の実行で終わらないように修正を加えていきます。
普通にEventBridge Schedulerを1つ用意するだけだと、1回実行して終わりor定期的な実行の繰り返しになってしまって若干エージェントっぽさが無くなります。
そこでもう少しエージェントたらしめるべく、エージェント自身にスケジュールを更新させてみます。
ということで、Schedulerを更新するためのツールを用意してみました(Claudeが)。
ポイントは以下のように、「現在のスケジュール設定を取得する→そのスケジュールを上書きする」という形にしていることです。
変更してほしくないパラメータにエージェントが手を加えることがないようにしています。
また、場合によっては入力値に何か追加で書き込む必要があるかもしれないため、Schedulerの入力Payloadを修正できるようにもしています。
def _update_schedule_sync(next_datetime: datetime, timezone: str, next_input: str = None) -> dict:
"""get_schedule → update_schedule を同期的に実行
Args:
next_datetime: 次回実行日時
timezone: タイムゾーン
next_input: 次回実行時のエージェントへの入力(省略時は変更なし)
Returns:
更新結果の辞書
"""
schedule_name = os.environ.get("SCHEDULE_NAME")
group_name = os.environ.get("SCHEDULE_GROUP_NAME", "default")
if not schedule_name:
raise ValueError("SCHEDULE_NAME environment variable is not set")
# 既存のスケジュール設定を取得
existing = scheduler_client.get_schedule(
Name=schedule_name,
GroupName=group_name
)
# next_input が指定されている場合、Target.Input 内の Payload.input を更新
if next_input is not None:
# Target.Input は二重にJSON化されている構造:
# { "AgentRuntimeArn": "...", "Payload": "{\"action\":\"start\",\"input\":\"...\"}" }
original_input = json.loads(target['Input'])
payload = json.loads(original_input['Payload'])
payload['input'] = next_input
original_input['Payload'] = json.dumps(payload, ensure_ascii=False)
target['Input'] = json.dumps(original_input, ensure_ascii=False)
# 更新パラメータを構築(既存設定を保持)
update_params = {
'Name': schedule_name,
'GroupName': group_name,
'ScheduleExpression': at_expression,
'ScheduleExpressionTimezone': timezone,
'FlexibleTimeWindow': existing['FlexibleTimeWindow'],
'Target': target,
}
# オプションフィールドを保持
optional_fields = ['Description', 'EndDate', 'StartDate', 'State', 'KmsKeyArn', 'ActionAfterCompletion']
for field in optional_fields:
if field in existing and existing[field] is not None:
update_params[field] = existing[field]
# スケジュールを更新
response = scheduler_client.update_schedule(**update_params)
return {
'schedule_arn': response['ScheduleArn'],
'new_expression': at_expression,
'timezone': timezone,
'schedule_name': schedule_name,
'group_name': group_name,
'next_input': next_input
}
3.エージェントに記憶を持たせる
異なる日時で起動するエージェントには複数のタスクをこなしてもらいたい場合が出てくると思います。
例えば1/10に開催するハンズオン会のメールを1/1に1回目を送信したので、各日の朝には問い合わせメールが来ていないか確認してほしい。また3日前と前日にはリマインドメールを送ってほしい…など。
その場合、今はどのタスクまで完了しているのか・次どのタスクをすればいいのかといった情報(コンテキスト)を起動してくるエージェントに適切に与えてあげる必要があります。
そこでAgentCore Memoryを使って、タスク実行状況を記憶させておきます。

Strands側で用意されているAgentCoreMemoryConfigやAgentCoreMemorySessionManagerを用いると、簡単にAgentCore Memoryをエージェントに組み込むことができるのでおすすめです。
閑話休題:MemoryにおけるセッションIDとアクターID
ここで、Memoryの記憶管理やセッション分離について簡単にまとめておきます。
登場人物はSession IDとActor IDです。この2つを組み合わせることで、セッション分離・ユーザー分離が手軽に実現できます。
- Session ID
- 各セッションの識別子
- AgentCore Runtimeはステートレスなため、session_idを用いて会話コンテキストを維持する
- 同じsession_idを設定すると、同じ会話として扱われる
- ChatGPTなどのように適宜新しい会話を立ち上げたい場合は、独立したsession_idを管理する
- Actor ID
- ユーザーの識別子
- どのユーザーとの会話履歴なのかを識別する
- 同じactor_idを設定すると、同じユーザーの会話として扱われる
- 複数ユーザーが利用するアプリケーションの場合は、独立したactor_idを管理する
この2つのIDを用いて、長期記憶で用いられる名前空間を読み解いていきます。
名前空間サンプル
/strategies/{MEMORY_STRATEGY_ID}/actors/{ACTOR_ID}/sessions/{SESSION_ID}
| 変数 | 説明 |
|---|---|
{memoryStrategyId} |
メモリ戦略を識別(コンソールなどで確認) |
{sessionId} |
セッションを識別 |
{actorId} |
アクターを識別 |
このレイヤーを指定することで、Memoryを取り出す階層を指定できます。
# 最も細かい(セッションレベル)
/strategies/{memoryStrategyId}/actors/{actorId}/sessions/{sessionId}
# アクターレベル(セッション横断)
/strategies/{memoryStrategyId}/actors/{actorId}
# 戦略レベル(アクター横断)
/strategies/{memoryStrategyId}
また、この順番を組み替えることも可能なようです。
/actors/{actorId}/strategies/{memoryStrategyId}/sessions/{sessionId}
のようにすると、アクター単位で複数の記憶戦略を設定できるようになるそうです。
https://aws.amazon.com/jp/blogs/machine-learning/building-smarter-ai-agents-agentcore-long-term-memory-deep-dive/
そして今回のスケジュール駆動エージェントでは以下2パターンが考えられるでしょうか。
ここではパターン1の方を選んでみました。
session_id = "scheduled_agent_session" # 固定値
actor_id = "async_agent" # 固定値
- スケジュール駆動エージェント、バッチ処理などで活用
- すべての実行を同じ会話として扱い、履歴を累積
- 名前空間は
/strategies/{MEMORY_STRATEGY_ID}/actors/{ACTOR_ID}/sessions/{SESSION_ID}
session_id = f"execution_{job_id}" # 実行ごとに新規
actor_id = "async_agent" # 固定
- 独立したタスク実行で活用
- 短期メモリは各実行で新規、長期メモリで実行間のコンテキストを共有
- 名前空間は
/strategies/{MEMORY_STRATEGY_ID}/actors/{ACTOR_ID}
4.エージェントのタスク完了時に通知する
バックグラウンドで動くエージェントなので完了時には人間に通知してもらいましょう。

ここはツールではなく、エージェント完了後のプログラムとして実装しています。
通知は毎回必ず実行するため、わざわざエージェント側の処理としなくて済むようにしています。
これは単に通知するだけです。
動かしてみる・まとめ
具体的に動いているところをお見せできるわけではないのですが、届いたメールをお見せします。
ここではシステムプロンプトに
- 奇数回目の実行時は現在時刻を返し、次回実行スケジュールを5分後に設定して
- 偶数回目の実行時はAWSの最新情報を検索し、次回実行スケジュールを10分後に設定して
と記載しています。
1回目:

↓2回目: 5分後

↓3回目: 10分後

↓4回目: 5分後

という形で再スケジューリングした時間ごとに実行されており、スケジュール駆動エージェントっぽくなりましたね!
エージェントは動く時間がどうしても長くなるので開始時刻や完了通知時刻が少しずつズレていますが、これがあれば自動で動き出してくれるスケジュール駆動エージェントが作れそうです。
あとはシステムプロンプトとSOPsなどで細かくタスク分割・指示してあげれば、かなりAmbientなAgentが作れるのではないでしょうか!
とはいえスケジュール駆動だけでは限界があるので、次はイベント駆動(アラームなど)で動かせるように頑張ってみます!