初めに
TensorFlowと言えばDeepLearningのためのフレームワーク...というだけではなく、実際のところ、TFはもっと色々な事が出来ます。
モデルの式を定義して、損失を定義して、それを勾配法で解ける枠組みに落とし込めば、TFはそれをGPUを使って高速に解くためのモジュールとして使えます。
DeepLearningブームは思いのほか長持ちしていますが(2019/7/1現在)、仮にこのブームが終わった後でも、企業に貯まるデータはどんどん増え続けます。
計算科学のためのモジュールにはnumpyがありますが、numpyはそのままではGPUで計算が出来ないため、超大量のデータを処理するのには向いていません。
なので、CPUでは処理しきれないほどのデータをGPUでお手軽に高速処理するためのツールとして、TFに注目しました。
諸事情によりTensorflow==1.12.0を使用しますが、TF2が安定したら早く移りたいですね。
計算科学のツールとしてのTensorFlowのメリット
numpyの様な感覚でTFを使うメリットはいくつかあります。
様々な文献や使用例が豊富なので、初学者でも比較的扱いやすいです。
統計モデリングの文脈で主流になりつつあるベイズ統計モデリングなど、分布推論に対応したTensorFlow Probabilityが開発されています。数式を定義するだけで、面倒な勾配計算や事後分布の推論を行ってくれる様になることを期待しています。
TensorFlow Extendedというモデルのデプロイ周りをカバーするモジュールも開発されているので、作成したモデルを運用するコストが下がるかもしれません。
tf.kerasなどDeepLearningを簡単に組むためのモジュールと繋がっているので、必要に応じて非線形なモデルに拡張する事が容易です。
TensorBoardとの連携が出来るので、可視化のためのコードをガッツリ書かなくても、簡単に学習経過を可視化する事が出来ます。
ゴール
以上のメリットを踏まえて、TensorFlow Coreを実際に使ってみたいと思います。
Tensorflow CoreとTensorBoardを使って、簡単な線形回帰を実装します。
数式をコードに落とし込み、任意の処理と可視化を行うための一連の流れを整理します。
全体の流れをふんわり追っていく一方で、個々の関数の詳細な使い方までは触れません。
適宜公式サイトを参照してください。
やる事
- TensorFlow Coreで線形回帰
- 損失関数+正則化項の定義
- GPUのメモリ消費を抑えるやり方(公式の手順だが正常に作動せず?)
- TensorBoardで可視化するための連携
- 変数の名前空間を適切に区切る
- tf.data.Datasetを用いたスケーラブルなデータの受け渡し
- バッチ処理
- tf.train.Saverを使った重みの保存
- 学習と予測
やらない事
- tensorflow-gpuのセッティング
- 数式の詳細な説明や正則化、勾配計算の解説
- train/valid/testの分離
実装
モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook as tqdm
sns.set_style("darkgrid")
%config InlineBackend.figure_formats = {"png", "retina"}
%matplotlib inline
import tensorflow as tf
print(tf.__version__)
tf.test.is_gpu_available()
Sessionとconfigの設定
TFは、計算を実行する際にsessionを用います。
この中に任意の変数を入れる事で、その変数がGPU上で計算されます。
TFはSessionで計算を行う際にGPUの全てのメモリ領域を確保しようとするため、複数のモデルを並列で計算させたいときは予めsessionあたりのメモリ使用量を制限します。
GPUをどれくらい使用するかは、sessionを作る際の引数に渡すconfigを設定すれば良いです(と公式サイトには書いてありましたが、上手く反映されませんでした、何故...)。
config = tf.ConfigProto(
gpu_options=tf.GPUOptions(
visible_device_list = "0", # 特定のGPUのみ使用
allow_growth = True, # メモリを必要に応じて確保
# メモリの最大使用割合を制限
per_process_gpu_memory_fraction = 0.5
)
)
sess = tf.Session(config=config) # セッションを立ち上げ
線形回帰モデルを定義
TF1はDefine and Runといって、モデルを定義してからデータを流していきます。
まずは、モデルを定義します。
ポイントをまとめた後に、最終的なコードを載せてあります。
適宜参照してください。
TFにおける変数の定義
モデルにおいて、計算の単位はTensorですが、特にデータを流す入力となる変数はPlaceholder、学習を通じて値を更新していく係数となる変数をVariableと言います。
変数を定義した後、sess.rum(hoge)とする事で、実際にその変数が計算されます。
Tensorと名前空間
TFには名前空間という概念があり、個々のTensorには一意な名前が割り振られます。
TensorBoardを使用するとモデル全体図を概観する事が出来ますが、TensorBoardはモデルを可視化する際に個々のTensorに割り振られた名前を用います。
より見やすくするためには、tf.name_scopeを用いて適切に名前空間を区切っていきます。
例えば、
{山田, 田中, Smith, Jonnson}
という姓集合があるとします。
全ての姓をバラバラに管理するより、
{日本/山田, 日本/田中, アメリカ/Smith, アメリカ/Jonnson}
と管理する事で、集合が階層的になり、見やすくなります。
with tf.name_scope("日本"):
山田
田中
with tf.name_scope("アメリカ"):
Smith
Jonnson
モデルには学習を通じて最適化したい変数が含まれます。そのため、モデルを定義する際は、tf.name_scopeではなくtf.variable_scopeを用いています。基本的に両者は同じ挙動をしますが、変数を変数空間上で定義する事で、モデルや層を跨いで重みを共有できる様になります。
TensorBoardで変数を可視化するには
TensorBoardを扱うモジュールはtf.summary()です。
- 学習経過を可視化したい→
tf.summary.scalar() - 変数の分布を可視化したい→
tf.summary.histogram()
を用いて、ログをとる対象の変数を定義します。
histogramは結構いい感じに可視化出来るので面白いです。
次に、merged=tf.summary.merge_all()でログを取りたい変数を1つの変数として集約します。
sess.rum(merged)を実行する事で、ログを取りたい変数が各イテレーションでどんな値なのかが計算されます。
ログを実際にファイルとして吐き出すのは、tf.summary.FileWriterですが、これは後述します。
損失関数と最適化関数
モデルを定義して、予測値と実測値を用いる事で、誤差関数が得られます。
ここでは、純粋な誤差をerror、正則化項を加えた誤差をlossとして、lossを最小化することを考えます。
lossを最小化させるには、最適化関数にlossを最小化するように定義し、定義した変数を実行する事で逆伝搬計算が行われます。
下の例では、train_stepを実行する事で係数が更新されていきます。
逆に、lossを実行しただけでは、係数の更新は行われません。
loss = hogehoge
train_step = tf.train.AdamOptimizer(name="opt").minimize(loss)
モデル定義のコード
今までの説明を踏まえた、モデル定義のコードはこのようになります。
# Linear Regression
# name_scope, variable_scopeはしっかり区切っておく
# TensorBoardで可視化が綺麗になる
# tf.get_variableは、name_scopeを無視する
# name_scopeを超えてweight sharingが出来るようになる
# 参考URL: https://stackoverflow.com/questions/35919020/whats-the-difference-of-name-scope-and-a-variable-scope-in-tensorflow
with tf.variable_scope("linear_regression", reuse=tf.AUTO_REUSE):
input_x = tf.placeholder(tf.float32, shape=[None,1], name="input_x")
input_y = tf.placeholder(tf.float32, shape=[None, 1], name="input_y")
# 切断正規分布
# stddevの2倍で切断する
# この場合は1 * 2 = 2
init = tf.truncated_normal_initializer(mean=0,
stddev=1,
dtype=np.float32)
# get_variableで変数空間から変数を定義する
# 既に使用されている名前を呼び出すと、同じ変数を参照する
# これにより、重み共有が出来る様になる
W = tf.get_variable(name="W",
shape=[1,1],
dtype=np.float32,
initializer=init,
trainable=True)
b = tf.get_variable(name="b",
shape=[1,1],
dtype=np.float32,
initializer=init,
trainable=True)
pred_y = tf.add(tf.matmul(input_x, W), b, name="pred_y")
# Tensorboardで係数の事後分布(のようなもの)を見たいので、summaryに追加する
tf.summary.histogram("model/W", W)
tf.summary.histogram("model/b", b)
with tf.name_scope("loss"):
# l2正則化付きの損失関数
loss = tf.add(tf.reduce_mean(tf.square(tf.subtract(pred_y, input_y))), tf.reduce_mean(tf.square(W))*0.01, name="loss")
# 純粋な誤差
error = tf.reduce_mean(tf.square(tf.subtract(pred_y, input_y)), name="error")
# Tensorboardに誤差の下がり具合を格納したいので、summaryに追加する
tf.summary.scalar("error_with_l2_regularizer", loss)
tf.summary.scalar("mean_squared_error", error)
with tf.name_scope("train"):
# train_stepを実行すると、逆伝搬が計算され、重みが更新される
# それ以外のlossやerrorなどは、順伝搬しか計算されない
train_step = tf.train.AdamOptimizer(name="opt").minimize(loss)
# tf.summary.scalarなどで追加した、ログを取る対象を集約する
# sess.runするときに、mergedのみを流せばログを取りたい全ての変数が流せる
merged = tf.summary.merge_all()
TensorBoard描画用のwriterを定義
TensorBoardはモデルや学習経過を可視化する際eventというファイルを参照します。
eventファイルを生成・リアルタイムに更新するのはtf.summary.FileWriterです。
writerインスタンスを定義し、何かしらのアイテムをそこに加える事で、指定したディレクトリにeventファイルが生成されます。
validation, testを学習したい場合は、それぞれに対してwriterを定義すれば良いでしょう。
- eventに定義したgraphを追加→
writer.add_graph - eventに学習経過を追加→
writer.add_summary
を用います。
まずは、writerインスタンスを定義して、定義したグラフを追加してみましょう。
グラフを追加する前に、グラフが完全に作り終わったことを確認してください。
# Tensorboard描画用のwriterを設定
# 指定ディレクトリが存在しない場合は、新規に作られる
writer = tf.summary.FileWriter('./tensorboard')
# writerにモデルを追加
# writerに初めて何かが追加されると、eventファイルが生成される
writer.add_graph(tf.get_default_graph())
すると、指定したディレクトリにevents.hogehogeといったファイルが生成されていると思います。
これで、TensorBoardを起動する準備が整いました。
BashなどコマンドラインシェルからTensorBoardを起動します。
tensorboard --logdir={tensorboardディレクトリがあるパス}
と実行すると、TensorBoardが立ち上がります。
モデルを見てみましょう。
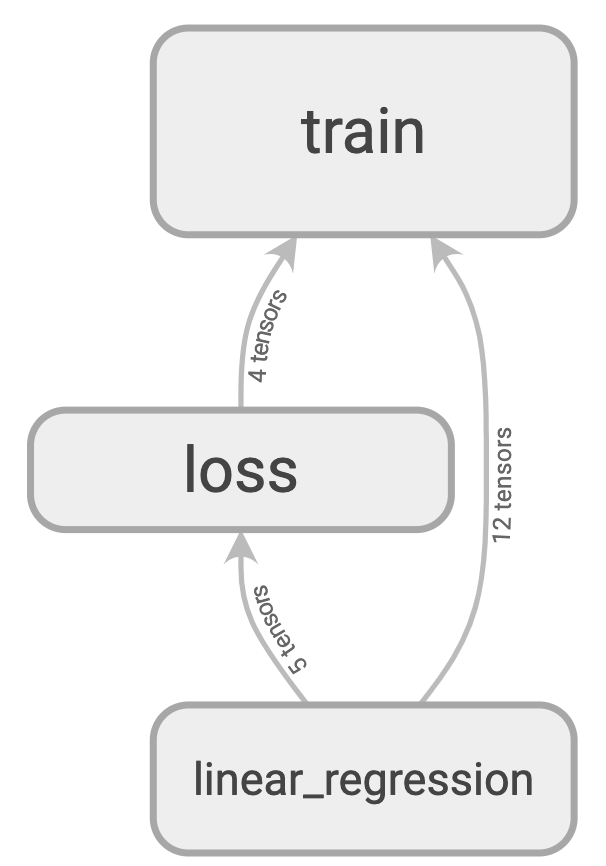
定義した名前空間に従って、モデルが可視化されました。
"train", "loss", "linear_regression"という3つのname_scopeに別れています。
"linear_regression"をダブルクリックして、モデルの中身を見てみましょう。
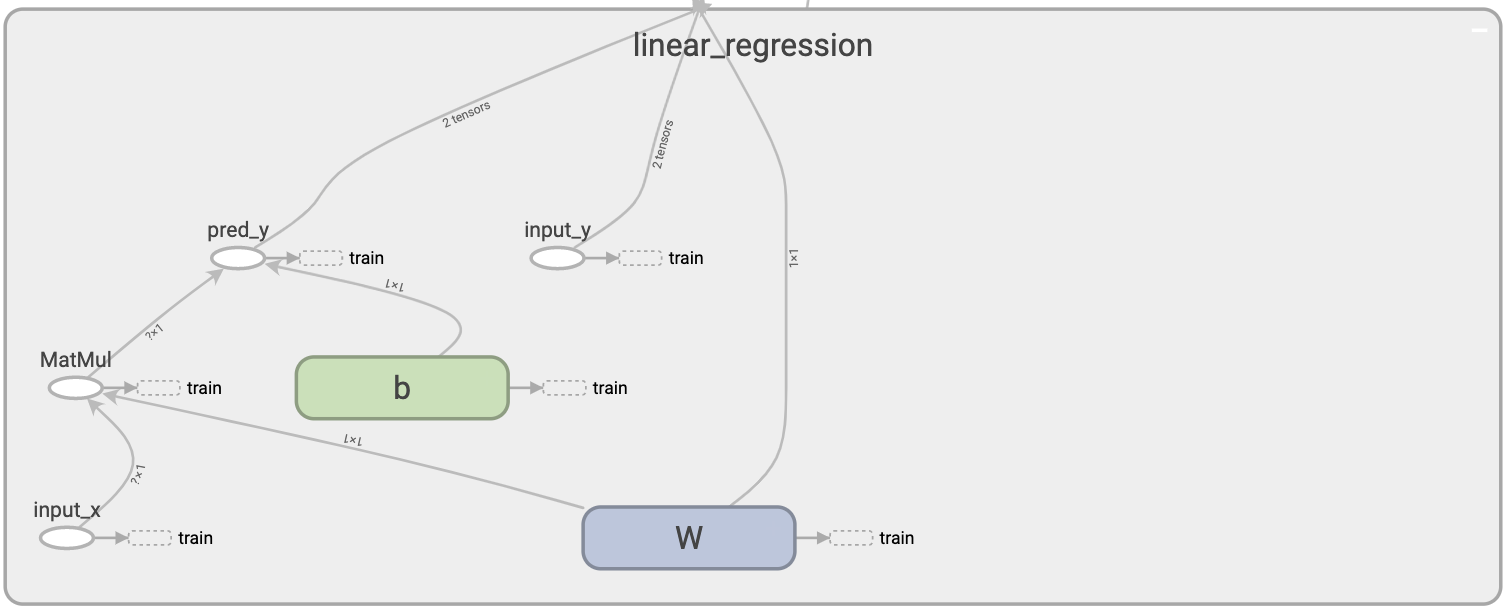
モデルの中身が見えました。
input_xに値が代入されてから、データがどの様な経路を辿るのかが一目瞭然です。
学習
学習を行なっていきます。
ここもいくつかのトピックをまとめておきます。
データの定義
学習用のデータを定義します。
とりあえず、以下の式に従う様にデータを用意します。
$$
y = 2 x + 50
$$
x_train = np.array([50, 100, 150, 200]).reshape(-1,1)
y_train = np.array([150, 250, 350, 450]).reshape(-1,1)
最低でも数万はデータ数が必要(個人の感想です)なDeepと比べると、データ数4つでもちゃんと学習する線形回帰ってすごいですね。
実務に機械学習を適用する場合、データを全て保持するのではなく必要に応じて読み込む事で、全てのデータをメモリに展開する必要が無くなり、巨大なデータに対応する事ができます。
そのために、generatorを定義します。
def data_generator():
x = x_train/100 # 計算を安定させたい
y = y_train/100 # ので、デフレートする
for i in range(len(x)):
yield x[i], y[i]
今回の定義ではgeneratorにデータを全て載せていますが、必要に応じてforループの中でSQLクエリ叩いてデータを持ってくるなどの応用例が考えられます。
TensorFlowにはTFRecordという独自のデータ形式があります。速いらしいです。
変数の初期化
TensorFlowは、変数を定義した段階では何も値を保持していません。
計算を実行する前に、変数の初期化を行います。
これにより、変数が初期値を持つ様になります。
global_init = tf.global_variables_initializer()
sess.run(global_init)
重みの保存と復元
学習した重みを保存するには、tf.train.Saverを使います。
変数に設定された名前に紐づく形で、重みが保存されます。
重みを復元する際も、予め定義した変数に同様の名前をつけておきましょう。
TFでは、学習経過の重みを保存する際に"checkpoint"という単語を用います。
max_to_keepを適切に設定しておかないと、古いcheckpointから順に上書きされていくので注意してください。
# モデルの重みなどを保存する
# max_to_keepで、最大直近3個しか保存しないようにする
saver = tf.train.Saver(max_to_keep=3)
# 復元
# この場合、initializerする必要はない
# saver.restore(sess, "/tmp/model.ckpt")
Dataset
TensorFlowでは、学習データをtf.data.Datasetというモジュールで管理します。
Kerasなどの高レベルAPIではdatasetをそのまま渡せますが、TF Coreでは適宜Datasetからバッチを取り出します。
取り出したバッチは、sess.runのfeed_dictの引数としてモデルに流していきます。
feed_dictには、sess.runで計算したい変数に必要な分だけ代入すれば良いです。
例えば、yの予測値を計算したい場合は、feed_dictにinput_yを渡す必要はありません。
学習の実行
sess.as_defaultでセッションを開始して、イテレータを回していきます。
datasetからバッチを取り出して勾配計算を繰り返します。
定期的にsaverで学習経過(重み)を保存します。
ログが大きいので、write_meta_graph=Falseで重みだけを保存します。
n_epoch = 10000
with sess.as_default():
dataset = tf.data.Dataset.from_generator(data_generator,
output_types=(tf.float32, tf.float32),
output_shapes=(tf.TensorShape(1), tf.TensorShape(1)))
dataset = dataset.batch(2)
iterator = dataset.make_initializable_iterator()
next_batch = iterator.get_next()
for i in range(n_epoch):
sess.run(iterator.initializer)
while True:
try:
x_batch, y_batch = sess.run(next_batch)
batch_loss, summary = sess.run([train_step, merged], feed_dict={input_x: x_batch, input_y: y_batch})
writer.add_summary(summary, i)
# datasetが回りきると以下のエラーが出る
except tf.errors.OutOfRangeError:
break
if i % 100 == 0:
saver.save(sess=sess,
save_path="./checkpoint/linear_regression_{}.ckpt".format(i),
write_meta_graph=False)
学習結果の確認
学習を進めつつ、TensorBoardで学習経過を確認していきましょう。
損失の可視化
学習を実行すると、tf.summary.scalarでログを取っている変数の値の推移がwriterを通じてeventファイルに記録されていきます。
なので、eventファイルを参照しているTensorBoardを見ると、学習の推移がリアルタイムにわかるようになります。
今回の例だと、lossとerrorのログを取る様に設定したので、TensorBoardのSCALARSというタブで学習の推移が見れます。
いちいちlossを計算してlistに格納して学習推移をplotして...といった手間から解放されます。
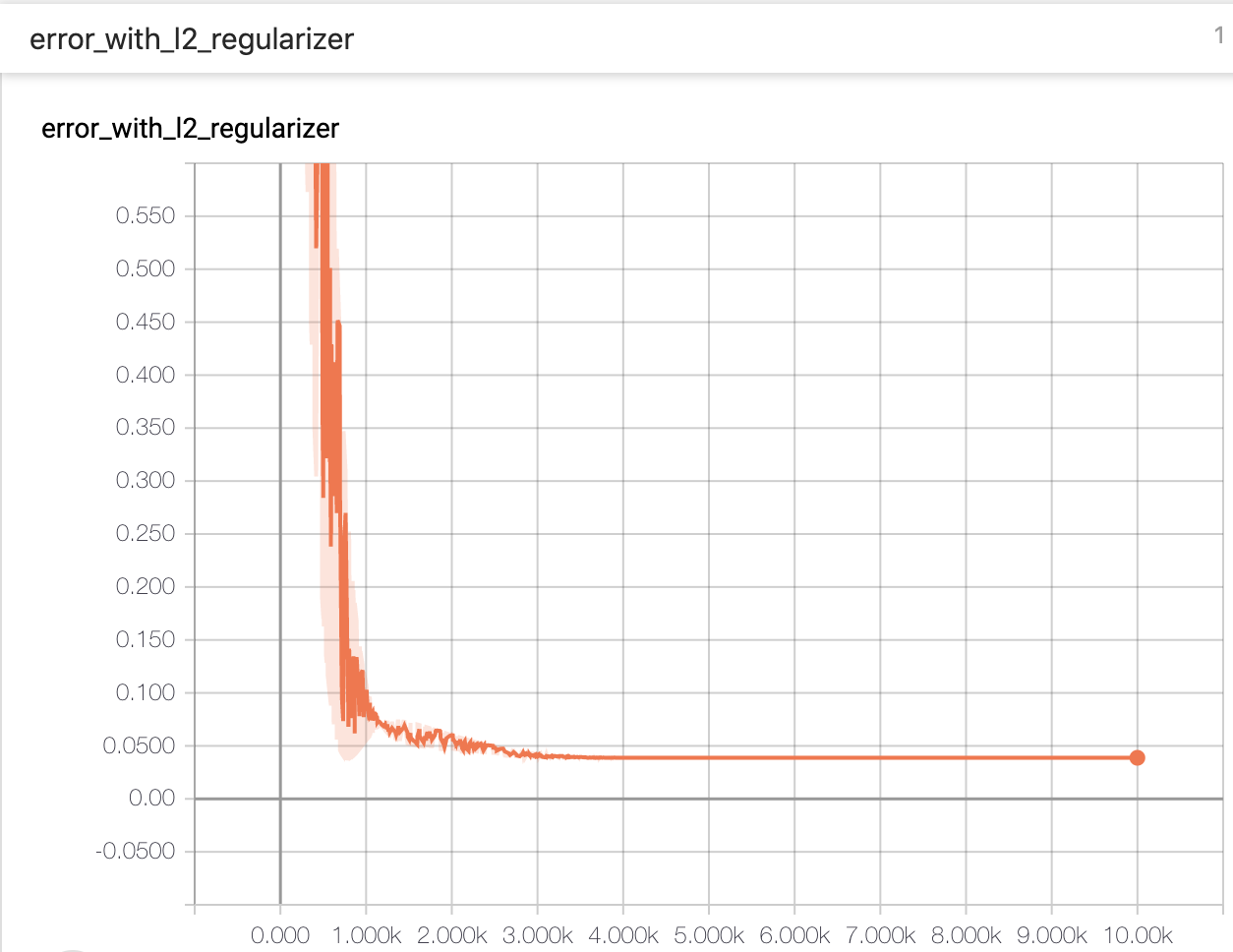

順調に学習が進んだことがわかります。
正則化項を入れていないmean_squared_errorは0に張り付いている一方で、L2正則化項を入れたlossは0に張り付いていません。
係数の可視化
モデルを定義する際に、tf.summary.histgramで係数を可視化する様に設定したのを覚えているでしょうか。
TensorBoardのDISTRIBUTONSというタブを見ると、学習の推移と共に係数の値がどう移り変わっていったのかを見ることが出来ます。
$$
y = b + Wx
$$
ちなみに、理論的な最適解はW=2, b=0.5です。
bが小さいのは、generatorを定義するときにXとyを÷100しているからです。
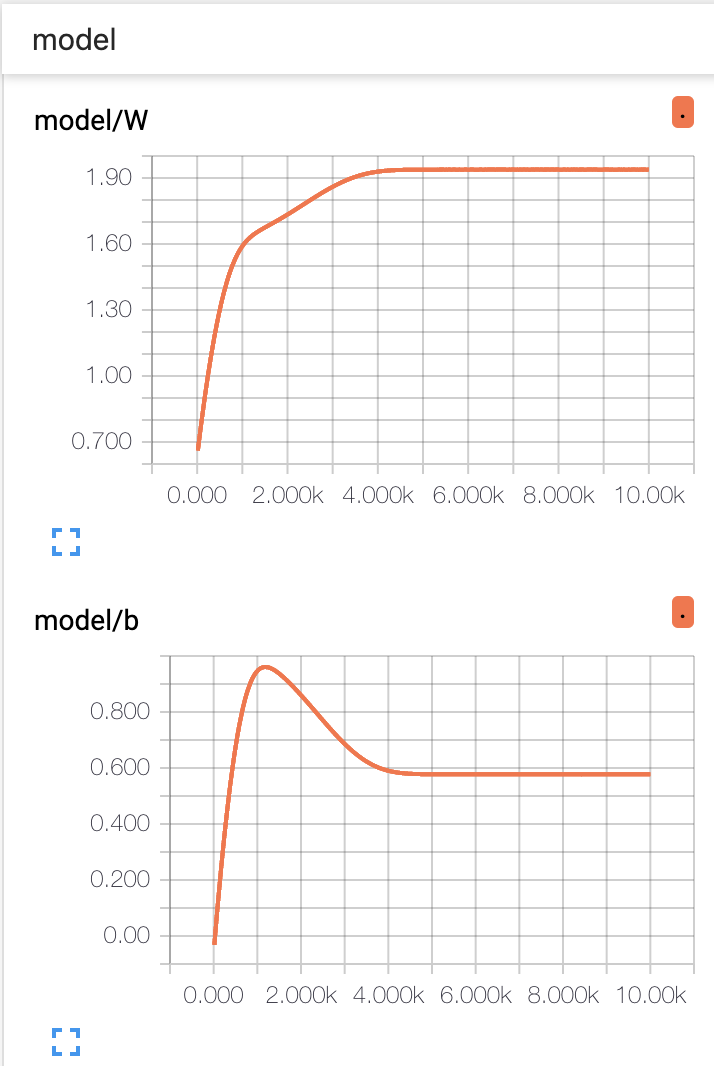
上図を見ると、Wは順調に最適解に向かっていく一方で、bは最適解を通り越してから戻ってきていることがわかります。
Wに対して正則化項を入れているので、理論的な最適解と比べると若干Wが小さく、bが大きくなっています。
また、係数の分布が学習の推移と共にどう変わっていったかもわかります。
HISTOGRAMSというタブを開きましょう。
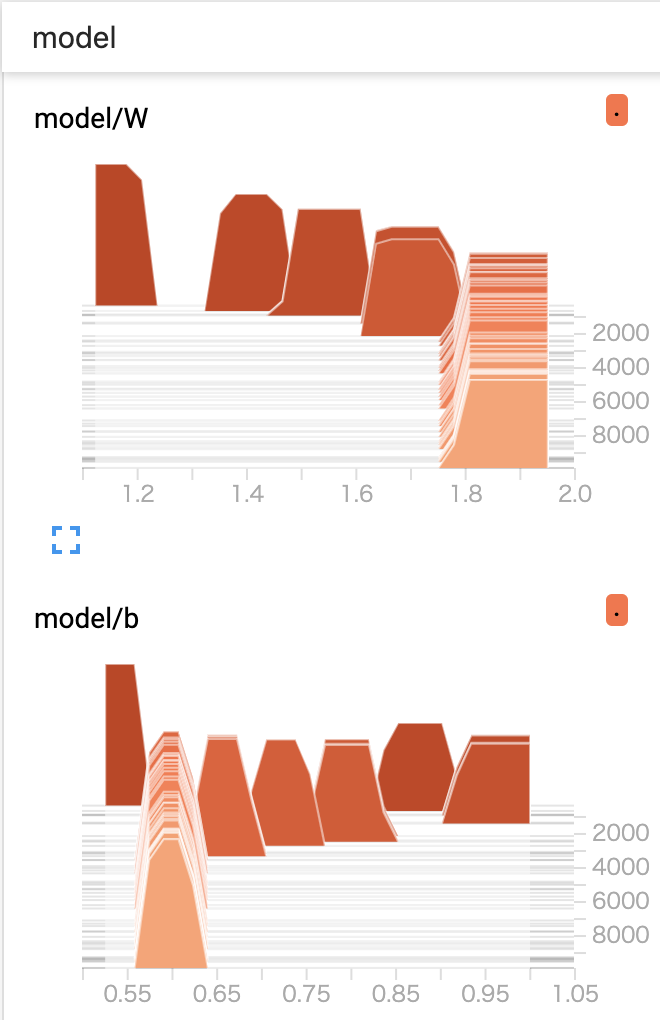
まだ使いこなせてないので怪しいですが、例えばmodel/bの分布が学習の推移とともに尖っていることがわかります。その値に対してより確信を持っているという事が言えるかもしれません。
学習結果の確認
学習したW, bの値を確認したい場合は、今までと同様にsess.runします。
係数の値を確認するだけなので、feed_dictの指定は必要ありません。
pred_W, pred_b = sess.run([W, b])
pred_W, pred_b

Wに対してL2正則化を入れているので、若干Wが小さく、bが大きくなっています。
予定通りの値に学習が進んだ事を確認出来ました。
今回はただの線形回帰なので過学習を気にする必要はありませんが、Deepなモデルを学習させる際は、valid_lossを見つつ最適な学習時点でのcheckpointを用いて重みを復元しましょう。
予測
最後に、予測値を求めます。
重みを復元し、未知の入力を入れて、出力を受け取ります。
generator定義の際に、入力データを割り算しているのに注意してください。
saver.restore(sess, "./checkpoint/linear_regression_9900.ckpt")
data_x_pred = np.array([100, 150, 200]).reshape(-1, 1)
data_x_pred_normed = data_x_pred/100
data_y_pred_normed = sess.run(pred_y, feed_dict={input_x: data_x_pred_normed})
data_y_pred = data_y_pred_normed*100
data_y_pred


それぞれの入力に対して、適切な出力が返ってきました。
これで、勾配降下法で計算可能な任意の統計モデルが学習になりました。
まとめ
TensorFlow Coreを用いてモデルの定義から学習、可視化、重みの保存と復元を行いました。
長くなってしまいましたが、TensorFlowを用いたモデル開発の流れの概観が掴めたかと思います。
気になる個々の処理や関数を調べたり、class化をして、快適な統計・機械学習モデル開発ライフを送りましょう。