はじめに
今回の記事はシリーズ物です。他の記事はこちら↓
0.設計編(キーを判別するAIとは?)
1.データ収集(クローリング)
2.データ整形(スクレイピング)
3.機械学習を用いたAIの開発
4.Djangoを用いたWebアプリ開発←この記事です。
このシリーズもやっとこさ最終回です。色々な人に使ってもらえるよう、前回作ったモデルを搭載したWebアプリを作ります。
コードはGitHubにて公開しております。
https://github.com/hatena-hanata/
完成したWebアプリはコチラ
https://kja-app.herokuapp.com/
設計
デプロイで躓かないようにするため、超シンプル設計にしています。今回はDBを使用せず、modelも一切作りません。
機械学習モデルは静的ファイルとして、staticに格納しておきます。予測値を文字列に戻すための、ラベルエンコーダも一緒に格納します。
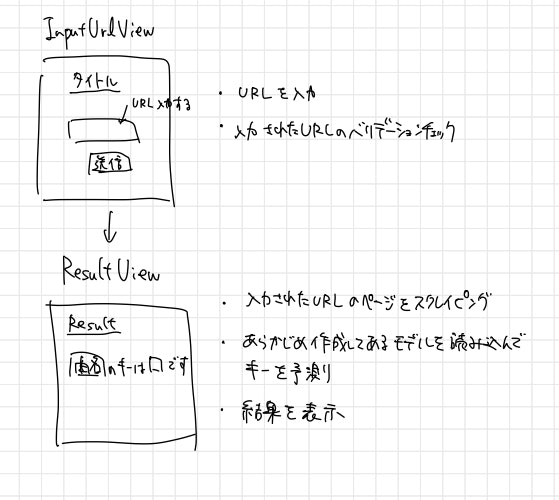
作る画面は以下の通り。
- U-fretの楽曲URLを入力する画面(
InputUrlView) - 結果を表示する画面(
ResultView)
2つだけです。 Viewごとに細かい機能の説明をしていきます。
InputUrlView
FormViewです。URLを入力するボックスだけ用意します。forms.pyで少しだけカスタムしたフォームを作成します。
スクレイピングやキーの予測はResultViewで行うので、入力されたURLをResultViewに渡す必要があります。 ViewからViewへ変数を渡す方法が分からなかったため、URLをテキストファイルに出力します。
class InputUrlView(FormView):
template_name = 'kj_ai/input_url.html'
form_class = InputUrlForm
# バリデーションを通過すると、入力されたURLをテキストファイルに書き込む
def form_valid(self, form):
url = form.cleaned_data['url_str']
url_dir = os.path.join(BASE_DIR, 'static/model/input_data.txt')
with open(url_dir, 'w') as f:
f.write(url)
return redirect('kj_ai:result')
InputUrlForm
bootstrapのデザインを反映させるために、初期化メソッドでform-controlクラスを付与しています。
入力されたURLのバリデーションチェックはここに書きます。今回はUfretの曲ページのURLだけを受け付けるようにします。
正規表現でチェックしているのですが、これだけだとパターンは合っているものの、末尾の数字がテキトーで曲データが存在しない場合も、バリデーションを通過してしまいます。そのため、一度入力されたURLでスクレイピングしてみて、曲が存在するかどうかを確認しています。
class InputUrlForm(forms.Form):
def __init__(self, *args, **kwargs):
super(InputUrlForm, self).__init__(*args, **kwargs)
# bootstrapを反映させるために、form-controlを付与
for field in self.fields.values():
field.widget.attrs["class"] = "form-control"
url_str = forms.CharField(max_length=60, required=True, label='URL')
# バリデーション
def clean_url_str(self):
input_url = self.cleaned_data['url_str']
# URLのパターンがU-fretの曲データのURLではない
pattern = 'https:\/\/www\.ufret\.jp\/song\.php\?data=[0-9]+'
if re.search(pattern, input_url) is None:
raise forms.ValidationError('URLが正しくありません')
url = re.search(pattern, input_url).group()
# URL末尾の番号によっては曲が存在しないので、スクレイピングして確認
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
if soup.find('title').text.split('/')[0] == ' ':
raise forms.ValidationError('URLが正しくありません')
return url
ResultView
結果を表示するViewですが、内部では色々やっています。
- テキストファイルからURLを読み込んでスクレイピングを行って、予測に使う説明変数となるデータフレームを作成
- キーの予測をして、ラベルエンコーダで予測値を文字列に戻す
- 結果をテンプレートに渡す
こんな感じです。
class ResultView(TemplateView):
template_name = 'kj_ai/result.html'
def get_context_data(self, *, object_list=None, **kwargs):
context = super().get_context_data(**kwargs)
# 入力されたURLを読み込む
url_dir = os.path.join(BASE_DIR, 'static/model/input_data.txt')
with open(url_dir, 'r') as f:
url = f.read()
# urlから曲のコードカウントしたdfと曲名を抽出
df, song_name = scraping(url)
# urlを記載したファイルを削除
os.remove(url_dir)
# 学習済みモデルとラベルエンコーダーの読み込み
model_pkl_dir = os.path.join(BASE_DIR, 'static/model/model.pkl')
le_pkl_dir = os.path.join(BASE_DIR, 'static/model/le.pkl')
loaded_model = pickle.load(open(model_pkl_dir, 'rb'))
le = pickle.load(open(le_pkl_dir, 'rb'))
# 予測して、結果を文字列に変換
pred_y_value = loaded_model.predict(df)
pred_y_label = le.inverse_transform(pred_y_value)[0]
if pred_y_label.split('_')[-1] == 'Major':
answer = pred_y_label.split('_')[0]
else:
answer = pred_y_label.split('_')[0] + 'm'
# htmlに結果を渡す
context['answer'] = answer
context['song_name'] = song_name
return context
スクレイピングのコードはコチラです。
def func(url):
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
# 曲名取得
song_name = soup.find('title').text.split('ギ')[0]
song_name = song_name[:len(song_name) - 1]
# Songインスタンス作成
song = Song(song_name, Chord('C'))
# コードを読み取る
chord_lst = soup.find_all('rt')
for c in chord_lst:
chord_str = c.text
if c.text[0] == 'N':
continue
chord = Chord(chord_str)
song.append_chord(chord)
# dfに変換して、説明変数部分だけ抽出。
df = song.to_DataFrame()
df = df[df.columns[2:]]
for col in df.columns:
df[col] = df[col].astype(float)
return df, song_name
デプロイ
いよいよデプロイ!全て無料で済ませたいので、herokuにデプロイします。
以下のサイトを大いに参考にしました。ほとんど下のサイトのコピペになってしまうので、詳しい手順はぜひ下のサイトを御覧ください。
[Django] Heroku デプロイ方法 2018年版
Django + Heroku + WhiteNoise + AWS S3 によるWebアプリのデプロイ
学習済みのモデルやラベルエンコーダは、静的ファイルとして全てプロジェクトフォルダ直下のstatic/modelに.pklとして格納しております。詳しいディレクトリ構造に興味がありましたら、GitHubの方をご確認ください。
完成
Webアプリをリリースするのは初めてなので、とても嬉しいです。我が子のように可愛がろうと思います。
次回やりたいこと
今回の開発を進めていく上で、新たなアイデアが出てきました。
曲中の転調を検出するAIの開発
僕が作ったキーを判別するAIの最大の敵は、転調する曲です。転調する曲に対しても一つしかキーを出力できないため、予測が難しくなります。
転調を検出するAIが作れれば、キーを複数出力するAIが作れるかもしれません。
ただ、転調するかどうかのラベルが記載されているコード譜掲載サイトは無いので、教師なし学習になりそうです。教師なし学習に関しては知識不足なので、勉強しようと思います。
さいごに
ここまで読んでくださった皆様、本当にありがとうございます。少しでも役に立てば幸いです。質問等あれば気軽にお願いします。
今回のAIの精度検証ですが、どうしても人力での確認が必要です。キー判別に自信のある方、実際に使ってみた感想を教えていただきたいです!笑 よろしくお願いします〜