はじめに
Kaggle 問題にチームで取り組み奮闘記での発表内容です。
このKaggleの問題に取り組みました。
PyCaret でかんたん AutoML
PyCaret ?
PyCaretは、機械学習のワークフローを自動化する Python 製のオープンソース、ローコード機械学習ライブラリです。PyCaret は基本的に、いくつかの機械学習ライブラリやフレームワークの Python ラッパーです。
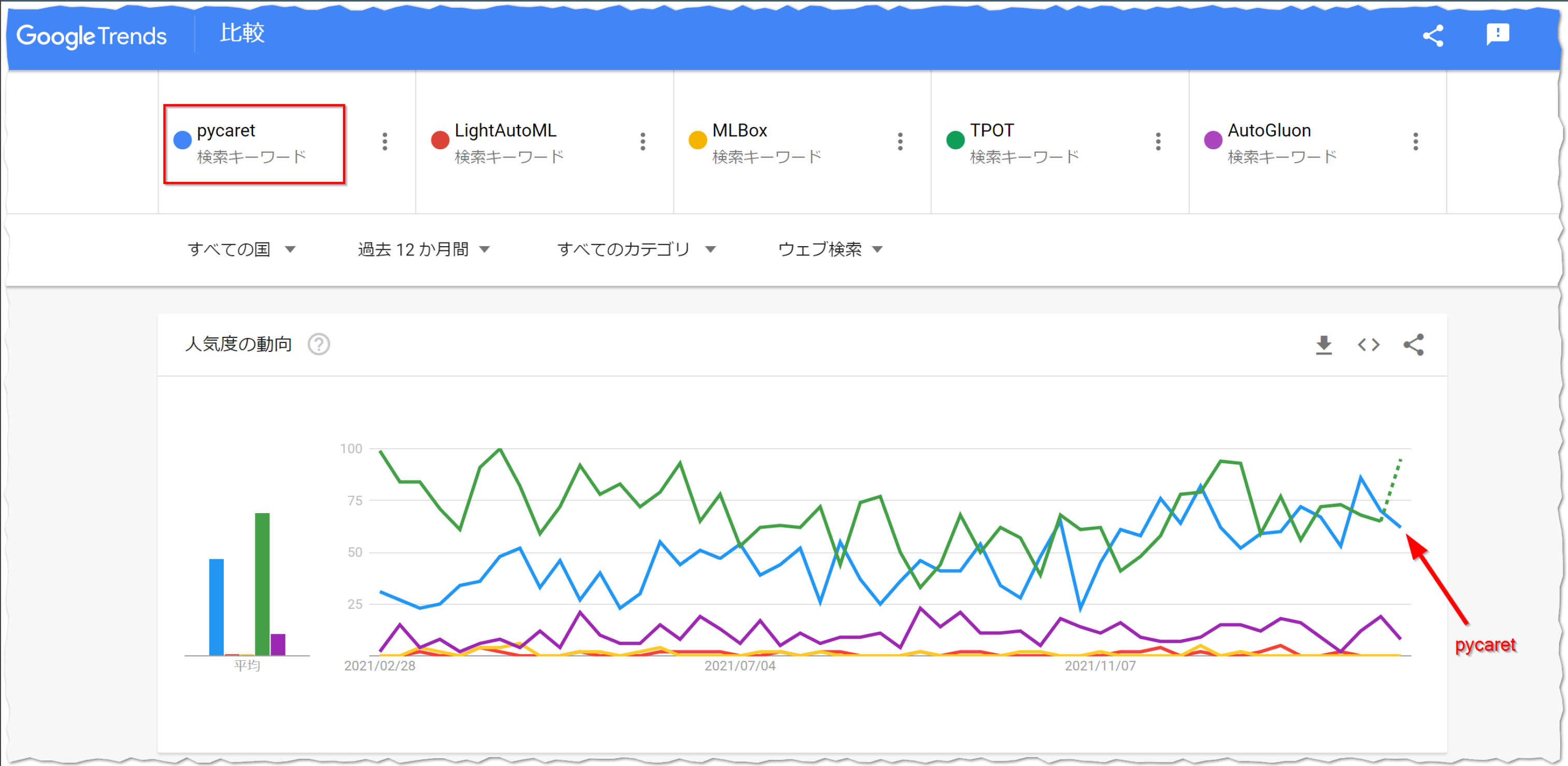
Googleトレンドでも注目度が高いのが確認できます。
使われている主なライブラリ・フレームワーク
機械学習ライブラリ
勾配ブースティング × 決定木
自然言語処理
ハイパーパラメーター 最適化フレームワーク
分散実行フレームワーク
PyCaretクイックスタート
Kaggleの問題に取り組む前に、PyCaretをかんたんに動かしてみたいと思います。
回帰問題における PyCaret の最小の流れは、
- setup()
- create_model()
- predict_model()
の流れです。インスタンスを作成したあと、モデルも決め打ちで、ビジュアライズもとくになしで OK であれば、この 3 つの関数に最低限の引数およびデータを入れてあげればすぐに機械学習を実行することが可能です。
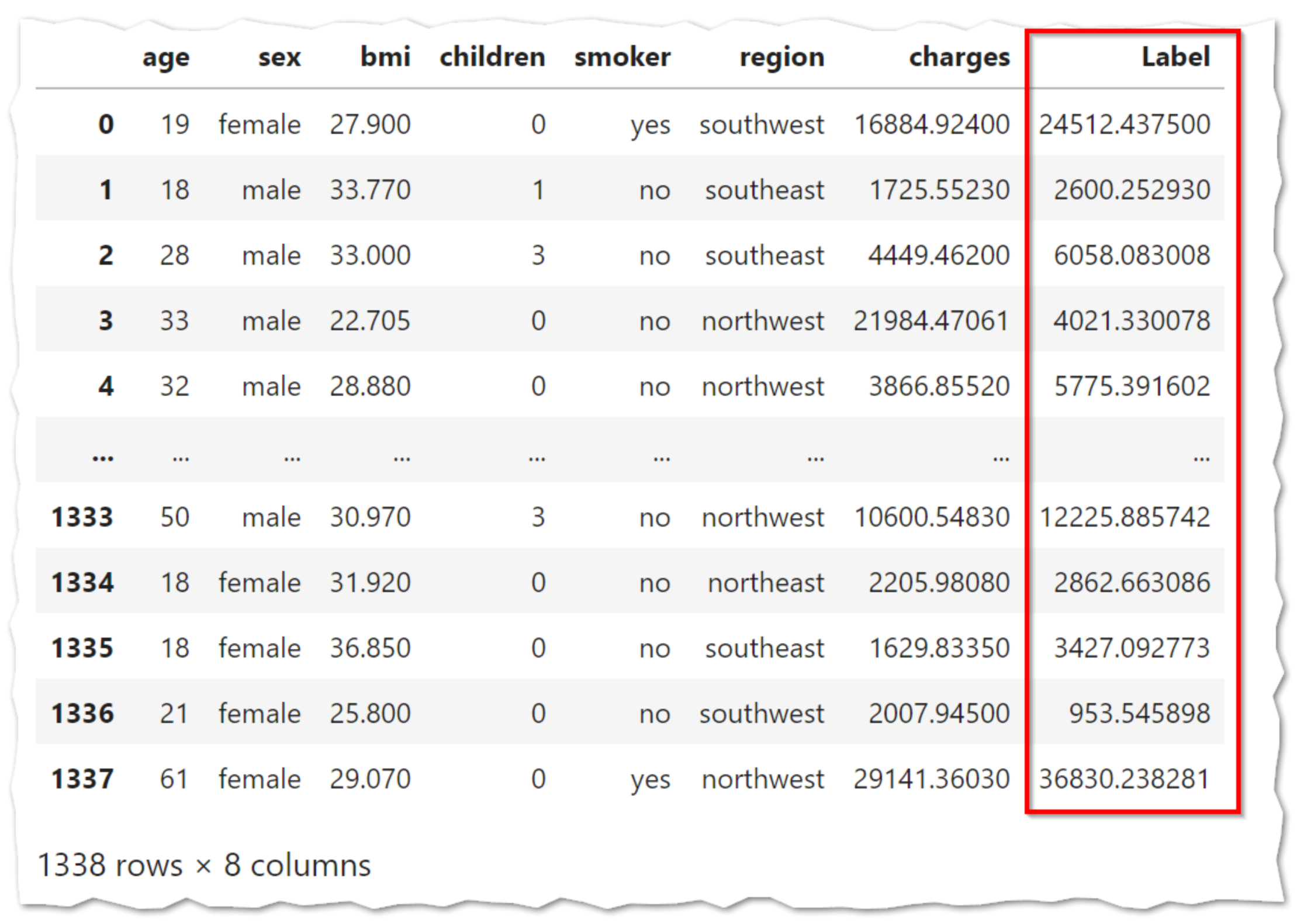
このコードを実行するだけで、予測値が出力されます。
# PyCaretの最初単位
# !pip install PyCaret
from PyCaret.datasets import get_data
from PyCaret.regression import *
data = get_data('insurance') # テストデータの取得
s = setup(data, target = 'charges') # インスタンスの作成
lr = create_model('lr') # モデルの作成
predictions = predict_model(lr, data=data) # 実行
Label列に予測値が入っていることを確認できます。
scikit-learn での実装例
これをscikit-learnで実装しようとすると、
- データセットの分割
- 特徴量の取捨
- グラフの作成
などで多くのコードが必要。
分析開始
ということで、Kaggleの問題に取り組んでいきます。取り組む問題はこちら。
前処理部分は省略します
前処理たくさんしてます。
Library Import
!pip install openpyxl
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
DATA LOAD
train = pd.read_csv('../input/tabular-playground-series-jul-2021/train.csv')
test = pd.read_csv('../input/tabular-playground-series-jul-2021/test.csv')
前処理
l_data = pd.read_excel('../input/air-quality-time-series-data-uci/AirQualityUCI.xlsx')
l_data.drop(columns = ['NMHC(GT)', 'NO2(GT)'], inplace = True)
# Preprocessing Time Column
l_data['hour'] = 0
for i in range(l_data.shape[0]):
l_data['hour'][i] = l_data['Time'][i].hour
time_se = l_data['Date'].dt.date - l_data['Date'].dt.date.min()
``
```python
# Making DataFrame to concat with train data!
leak = pd.DataFrame({
'deg_C' : l_data['T'],
'relative_humidity' : l_data['RH'],
'absolute_humidity' : l_data['AH'],
'sensor_1' : l_data['PT08.S1(CO)'],
'sensor_2' : l_data['PT08.S2(NMHC)'],
'sensor_3' : l_data['PT08.S3(NOx)'],
'sensor_4' : l_data['PT08.S4(NO2)'],
'sensor_5' : l_data['PT08.S5(O3)'],
'target_carbon_monoxide' : l_data['CO(GT)'],
'target_benzene' : l_data['C6H6(GT)'],
'target_nitrogen_oxides' : l_data['NOx(GT)'],
'year' : l_data['Date'].dt.year,
'month' : l_data['Date'].dt.month,
'week' : l_data['Date'].dt.week,
'day' : l_data['Date'].dt.day,
'dayofweek' : l_data['Date'].dt.dayofweek,
'time' : time_se,
'hour' : l_data['hour'],
'working_hours' : l_data['hour'].isin(np.arange(8, 21, 1)).astype("int"),
'is_weekend' : (l_data["Date"].dt.dayofweek >= 5).astype("int")
})
leak['time'] = leak['time'].apply(lambda x : x.days)
leak
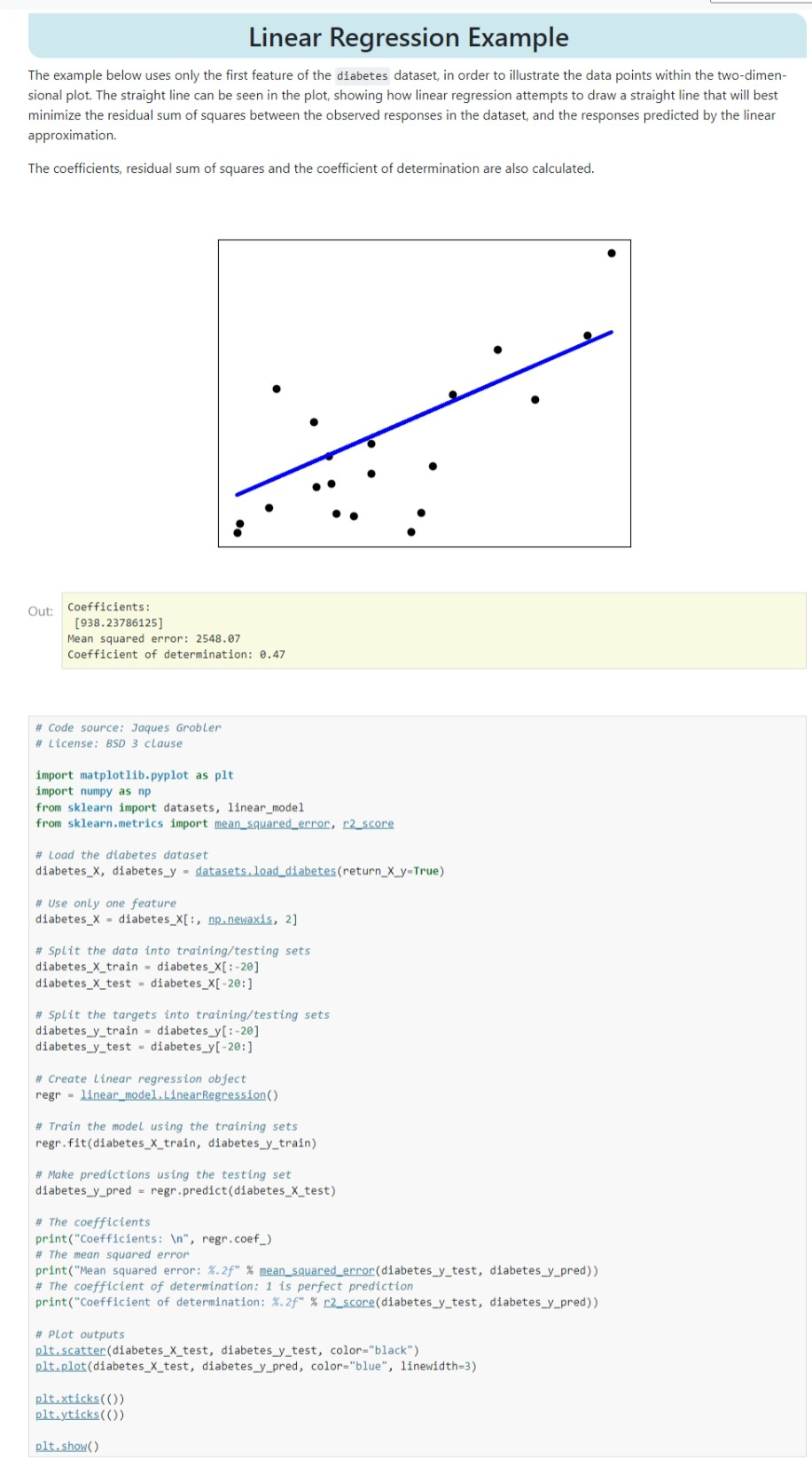
一つのデータセットにまとめる
all_data = pd.concat([train, test])
日付の前処理
all_data['date_time'] = pd.to_datetime(all_data['date_time'])
all_data['year'] = all_data['date_time'].dt.year
all_data['month'] = all_data['date_time'].dt.month
all_data['week'] = all_data['date_time'].dt.week
all_data['day'] = all_data['date_time'].dt.day
all_data['dayofweek'] = all_data['date_time'].dt.dayofweek
all_data['time'] = all_data['date_time'].dt.date - all_data['date_time'].dt.date.min()
all_data['hour'] = all_data['date_time'].dt.hour
all_data['time'] = all_data['time'].apply(lambda x : x.days)
# all_data["is_winter"] = all_data["month"].isin([1, 2, 12])
# all_data["is_sprint"] = all_data["month"].isin([3, 4, 5])
# all_data["is_summer"] = all_data["month"].isin([6, 7, 8])
# all_data["is_autumn"] = all_data["month"].isin([9, 10, 11])
all_data["working_hours"] = all_data["hour"].isin(np.arange(8, 21, 1)).astype("int")
all_data["is_weekend"] = (all_data["date_time"].dt.dayofweek >= 5).astype("int")
all_data.drop(columns = 'date_time', inplace = True)
all_data
外れ値前処理
leak = leak.reset_index(drop = True)
all_data = all_data.reset_index(drop = True)
out_index = []
for col in leak.columns[:8]:
out_index.append(leak[leak[col] == -200].index)
for i in range(8):
leak.loc[out_index[i], leak.columns[i]] = all_data.loc[out_index[i], leak.columns[i]]
all_data['dayofweek'] = all_data['dayofweek'].astype(object)
# all_data['month_c'] = all_data['month'].astype(object)
# all_data['hour_c'] = all_data['hour'].astype(object)
leak['dayofweek'] = leak['dayofweek'].astype(object)
all_data = pd.get_dummies(all_data)
leak = pd.get_dummies(leak)
all_data['SMC'] = (all_data['absolute_humidity'] * 100) / all_data['relative_humidity']
all_data['Dew_Point'] = 243.12*(np.log(all_data['relative_humidity'] * 0.01) + (17.62 * all_data['deg_C'])/(243.12+all_data['deg_C']))/(17.62-(np.log(all_data['relative_humidity'] * 0.01)+17.62*all_data['deg_C']/(243.12+all_data['deg_C'])))
leak['SMC'] = (leak['absolute_humidity'] * 100) / leak['relative_humidity']
leak['Dew_Point'] = 243.12*(np.log(leak['relative_humidity'] * 0.01) + (17.62 * leak['deg_C'])/(243.12+leak['deg_C']))/(17.62-(np.log(leak['relative_humidity'] * 0.01)+17.62*leak['deg_C']/(243.12+leak['deg_C'])))
train2 = all_data[:len(train)]
test2 = all_data[len(train):].reset_index(drop = True)
train2 = pd.concat([train2, leak]).reset_index()
train2.drop(columns = 'index', inplace = True)
Scaling
Log Scaling
def log_scaling(col):
col = np.log1p(col)
return col
cols = ['target_carbon_monoxide', 'target_benzene', 'target_nitrogen_oxides']
for col in cols:
train2[col] = log_scaling(train2[col])
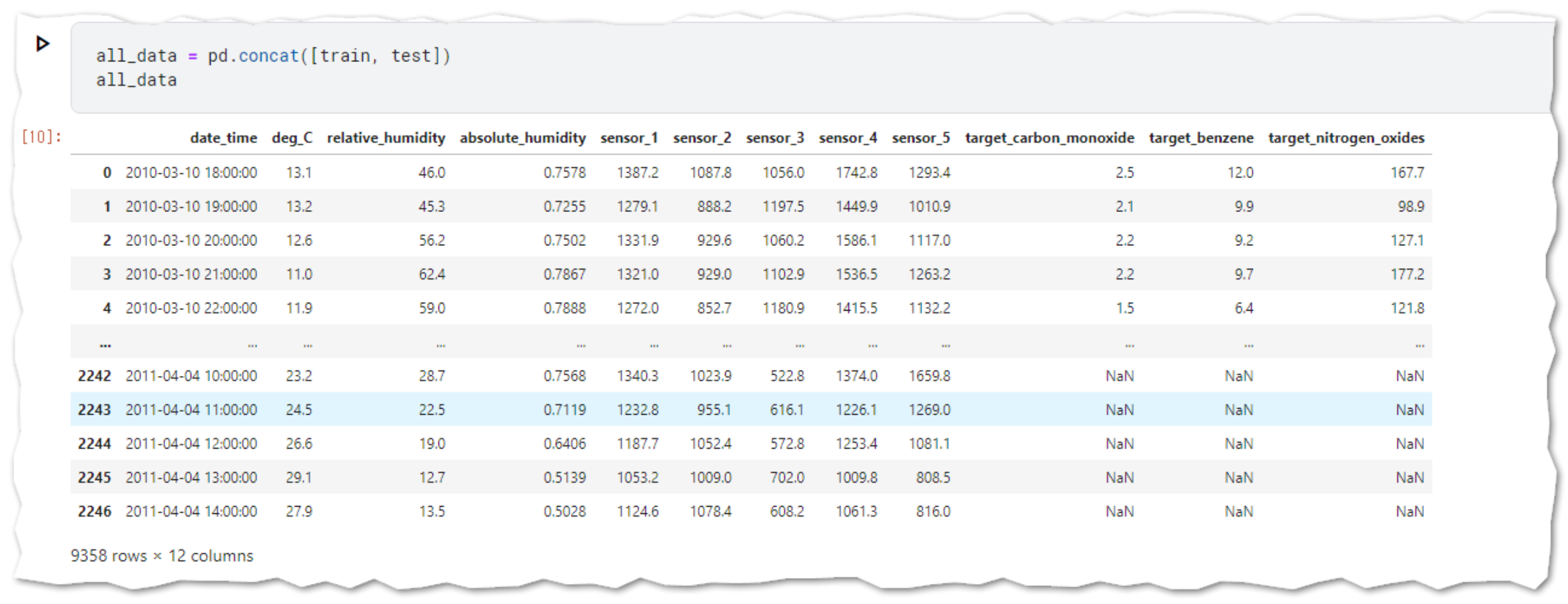
ビジュアライゼーションと比較
ログをとることにより、目的変数の値の幅を少なくし、ばらつきも正規分布に近いかたちになりました。
fig, ax = plt.subplots(len(cols), 2, figsize=(12,12))
n = 0
for i in cols:
sns.histplot(train[i], ax=ax[n, 0]);
sns.histplot(train2[i], ax = ax[n, 1]);
n += 1
fig.tight_layout()
plt.show()
データセットの分割
今回のコンクールでは、目的変数が3つあるため、Trainとtestでそれぞれ 3 つのDataSetを作成します。
train_3 = train2.drop(columns = ['target_carbon_monoxide', 'target_benzene', 'target_nitrogen_oxides'])
test_3 = test2.drop(columns = ['target_carbon_monoxide', 'target_benzene', 'target_nitrogen_oxides'])
train_co = train2.drop(columns = ['target_benzene', 'target_nitrogen_oxides'])
train_be = train2.drop(columns = ['target_carbon_monoxide', 'target_nitrogen_oxides'])
train_no = train2.drop(columns = ['target_carbon_monoxide', 'target_benzene'])
PyCaretの使用開始
インストールとライブラリのインポート
Kaggle(及びGoogleColab)のカーネルにはプリインストールされていないので、pip installをおこないます。
!pip install pycaret
from pycaret.regression import *
PyCaret でモデルを作成
Kaggle の問題に戻ります。PyCaret の関数は下記を使用します。
- setup()
- compare_models()
- blend_models()
- tune_model()
- plot_model()
- evaluate_model()
- predict_model()
- finalize_model()
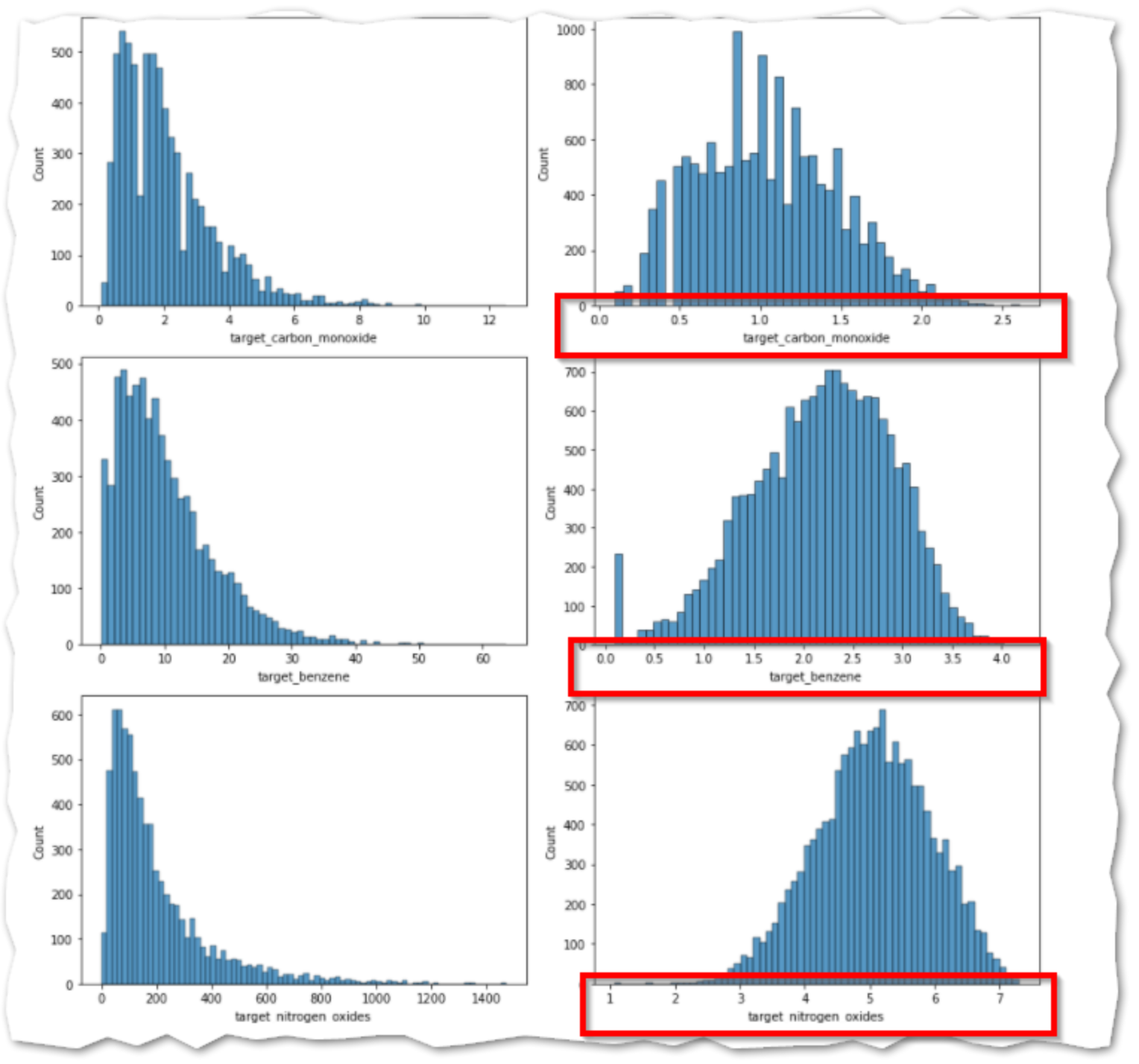
setup()
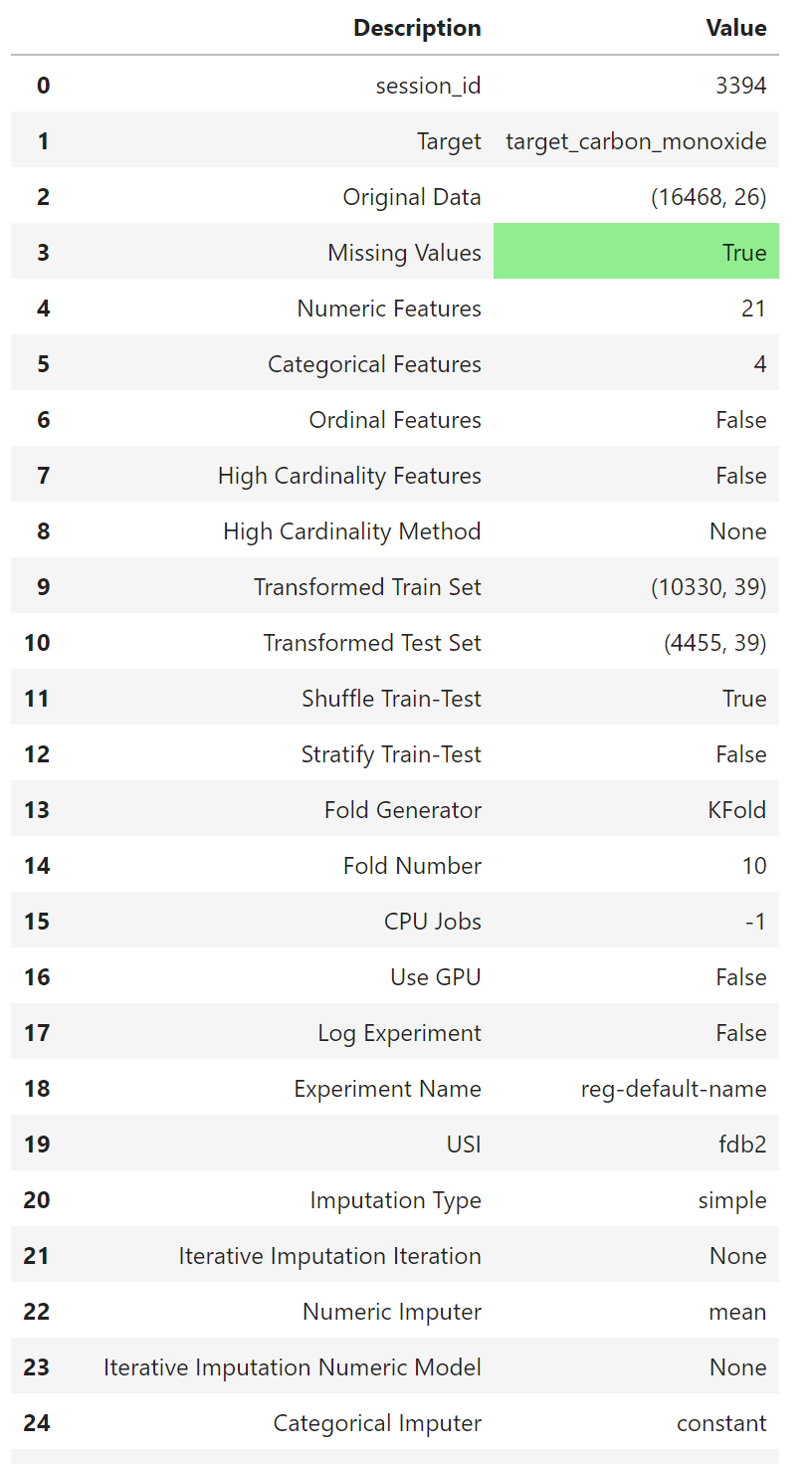
この関数は学習環境を初期化し、変換パイプラインを作成します。Setup 関数は他の関数を実行する前に呼び出す必要があります。この関数は、dataとtargetという 2 つの必須パラメーターを受け取ります。その他のパラメーターは任意です。
設定可能項目はこんなにあります![]()

exp = setup(data=train_co,
target='target_carbon_monoxide')
上記コードを実行するとデータ・タイプの一覧が出力され、Enter を押すと処理が続行、Quitをテキスト入力すると処理が中止されます。
処理が終わるとデータセットの情報を出してくれます。
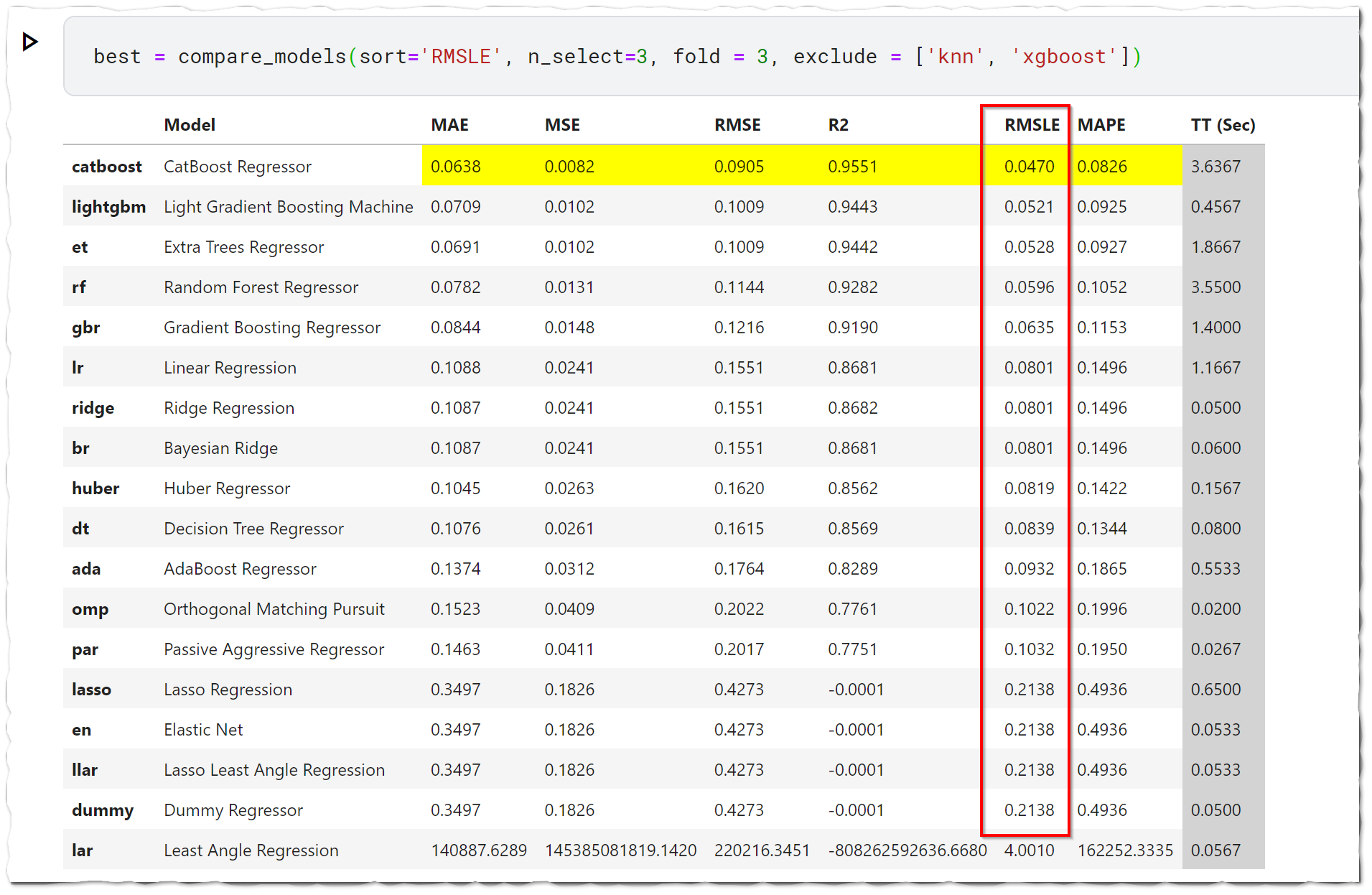
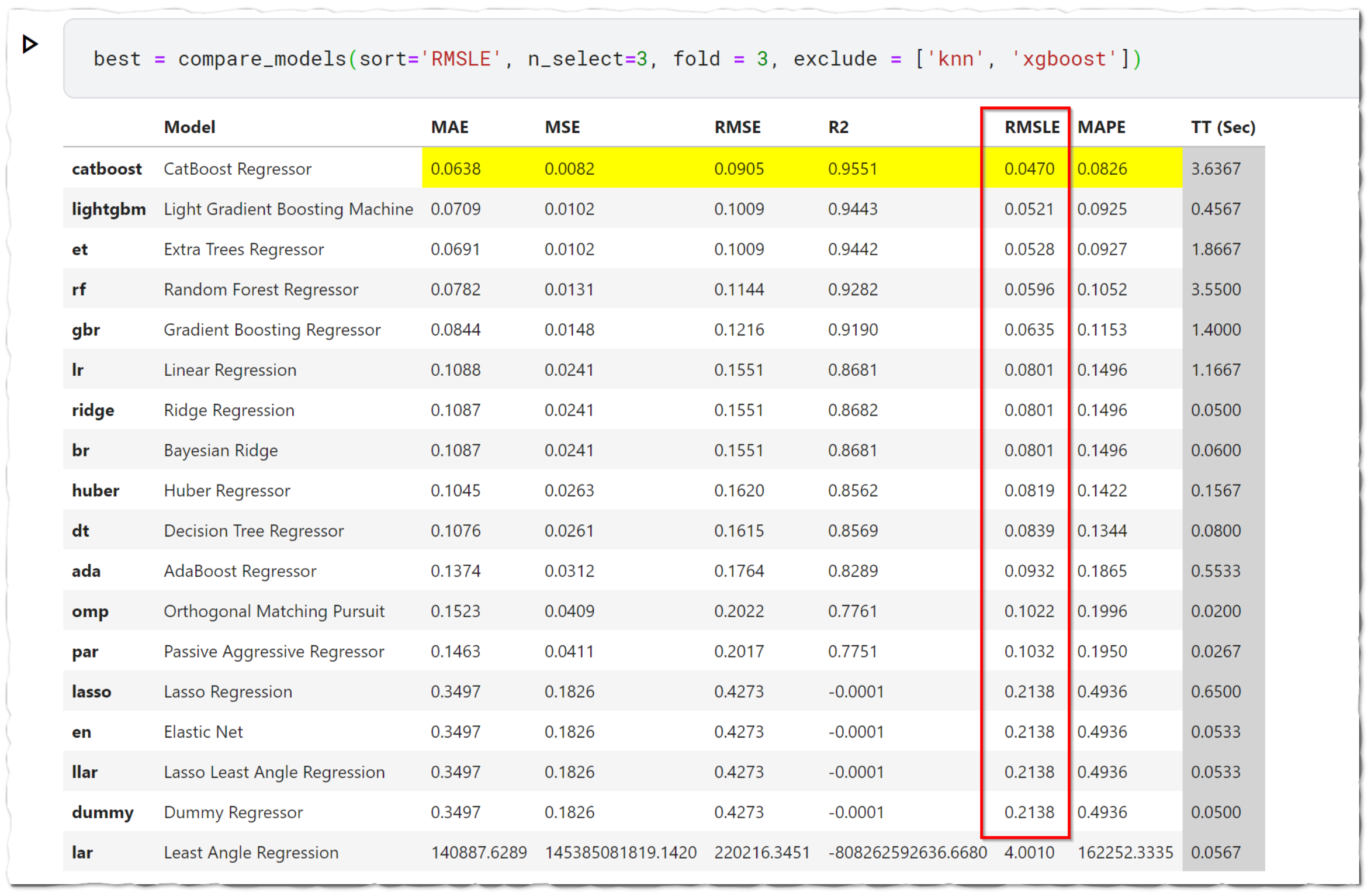
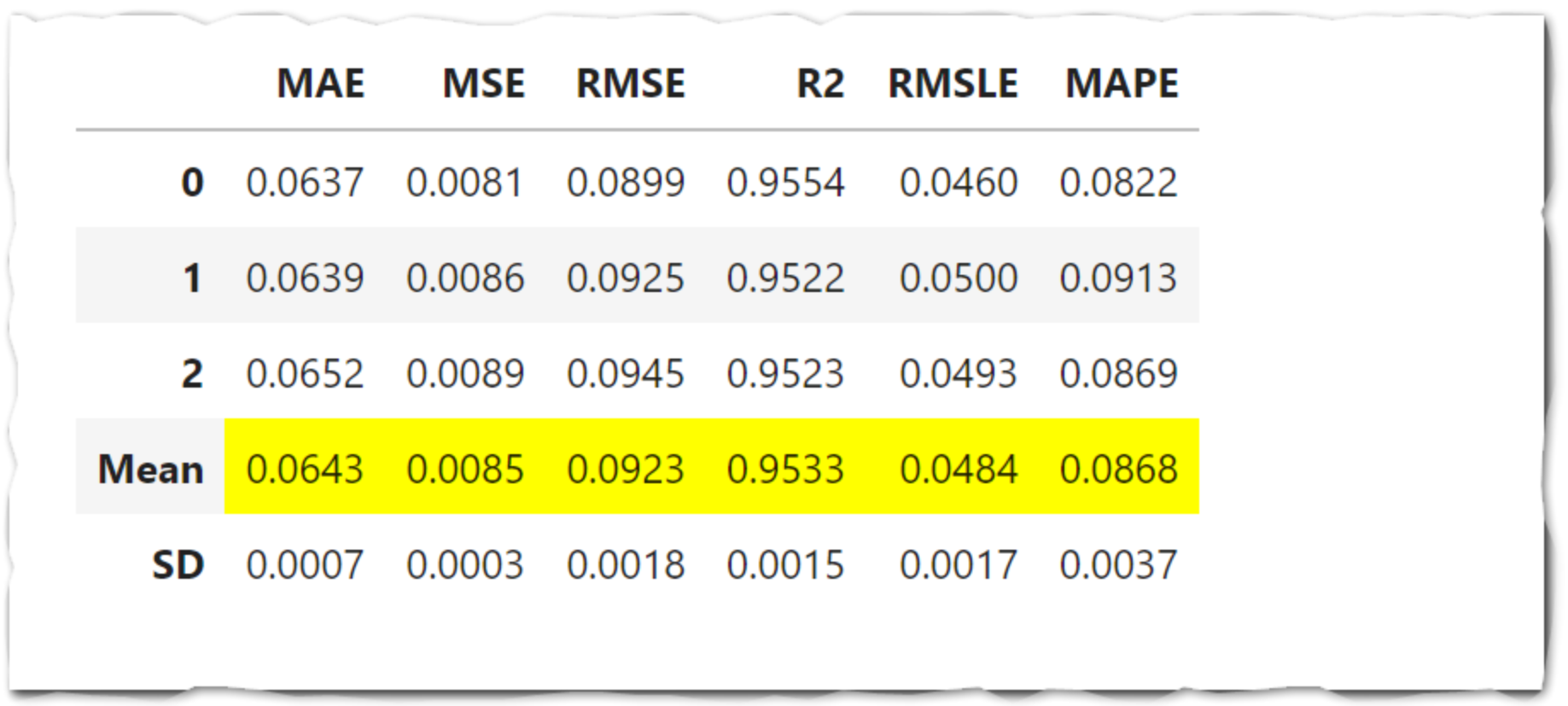
compare_models()
回帰用にモデル 20 個以上が使えるようになっています。
それぞれのモデルで交差検証をして評価指数順に並び替えて表示。
デフォルトの評価指数は決定係数になっているので注意。
top3 = compare_models(sort='RMSLE', n_select=3, fold = 3)
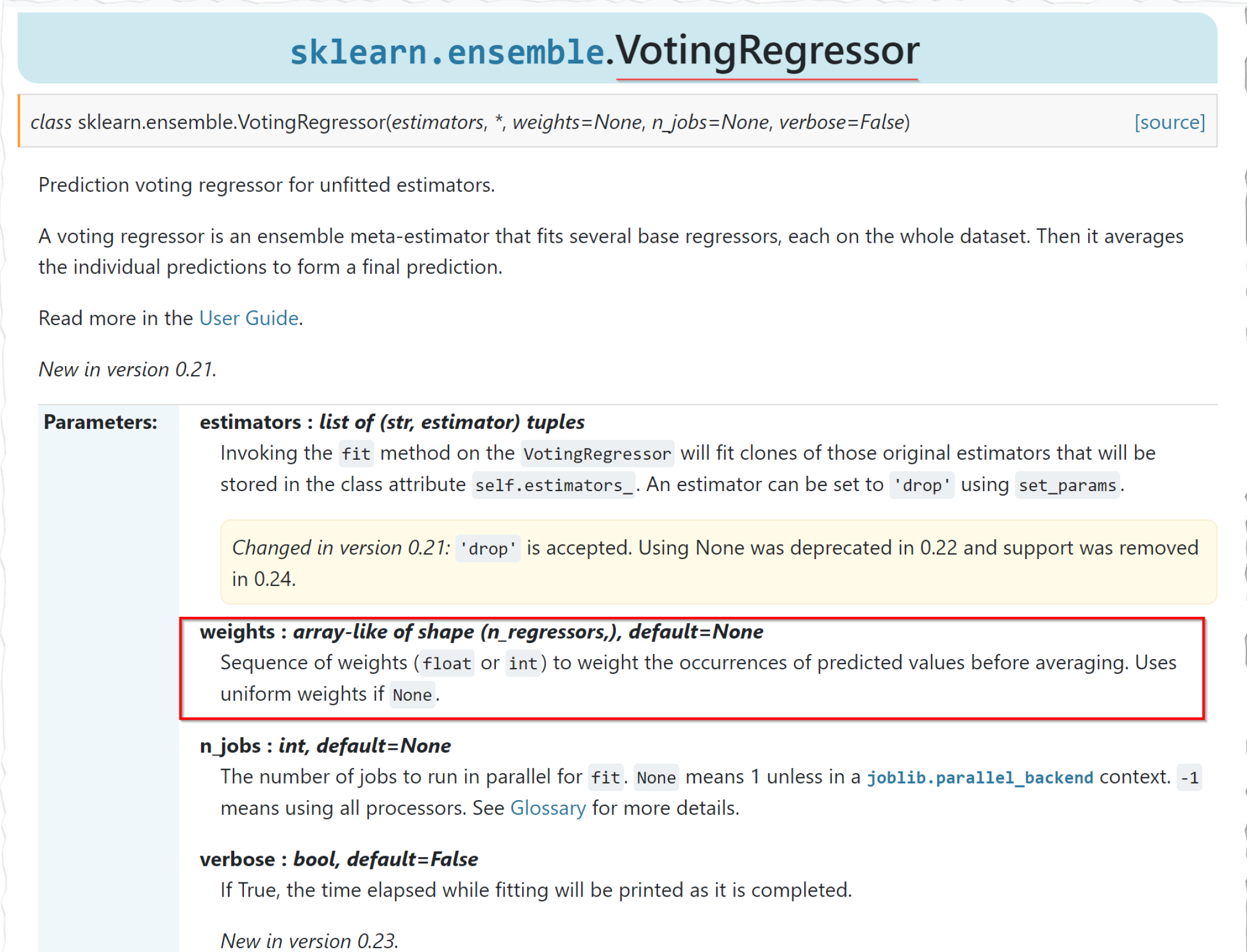
blend_models()
estimator_list パラメーターで渡されたモデルに対して、Voting Regressor を学習します。
blended = blend_models(estimator_list= top3, fold=3, optimize='RMSLE')
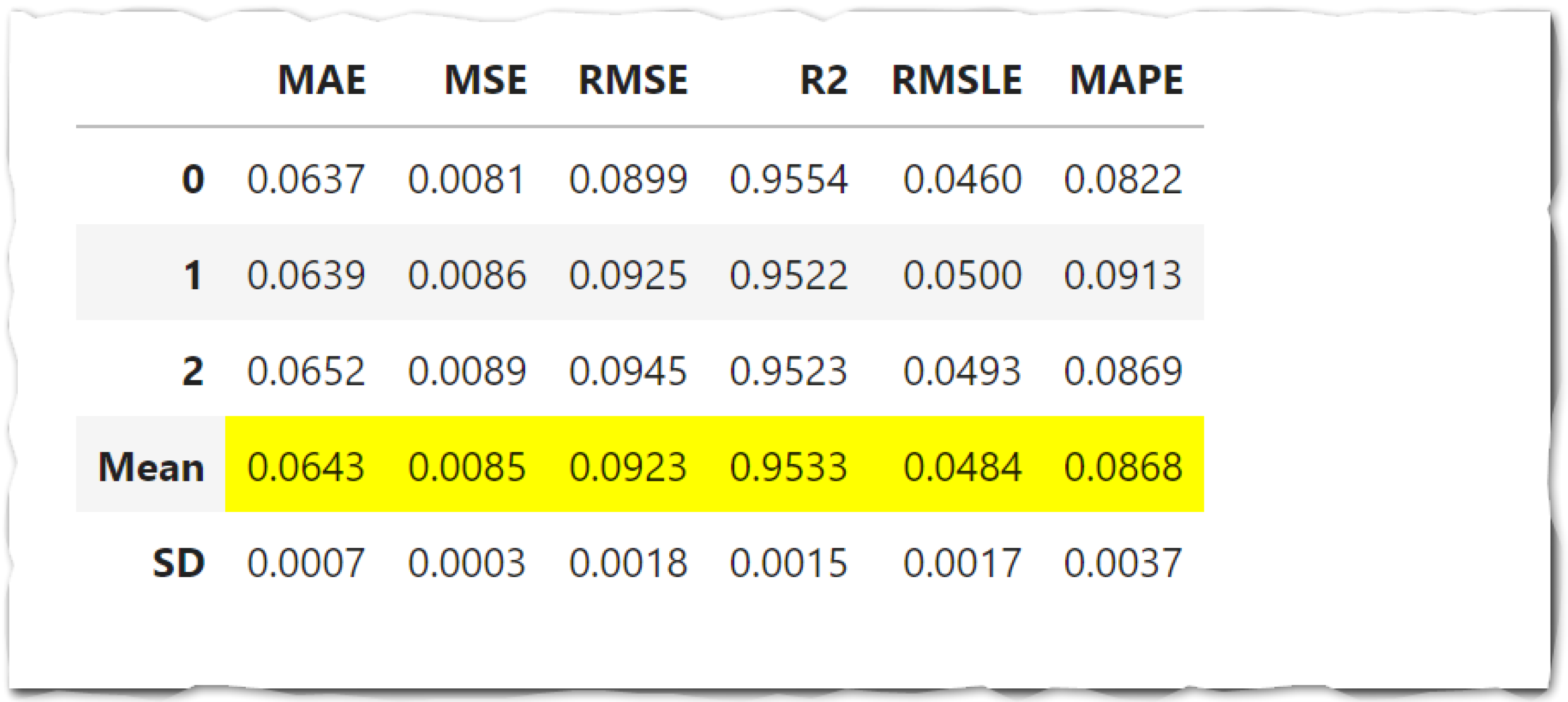
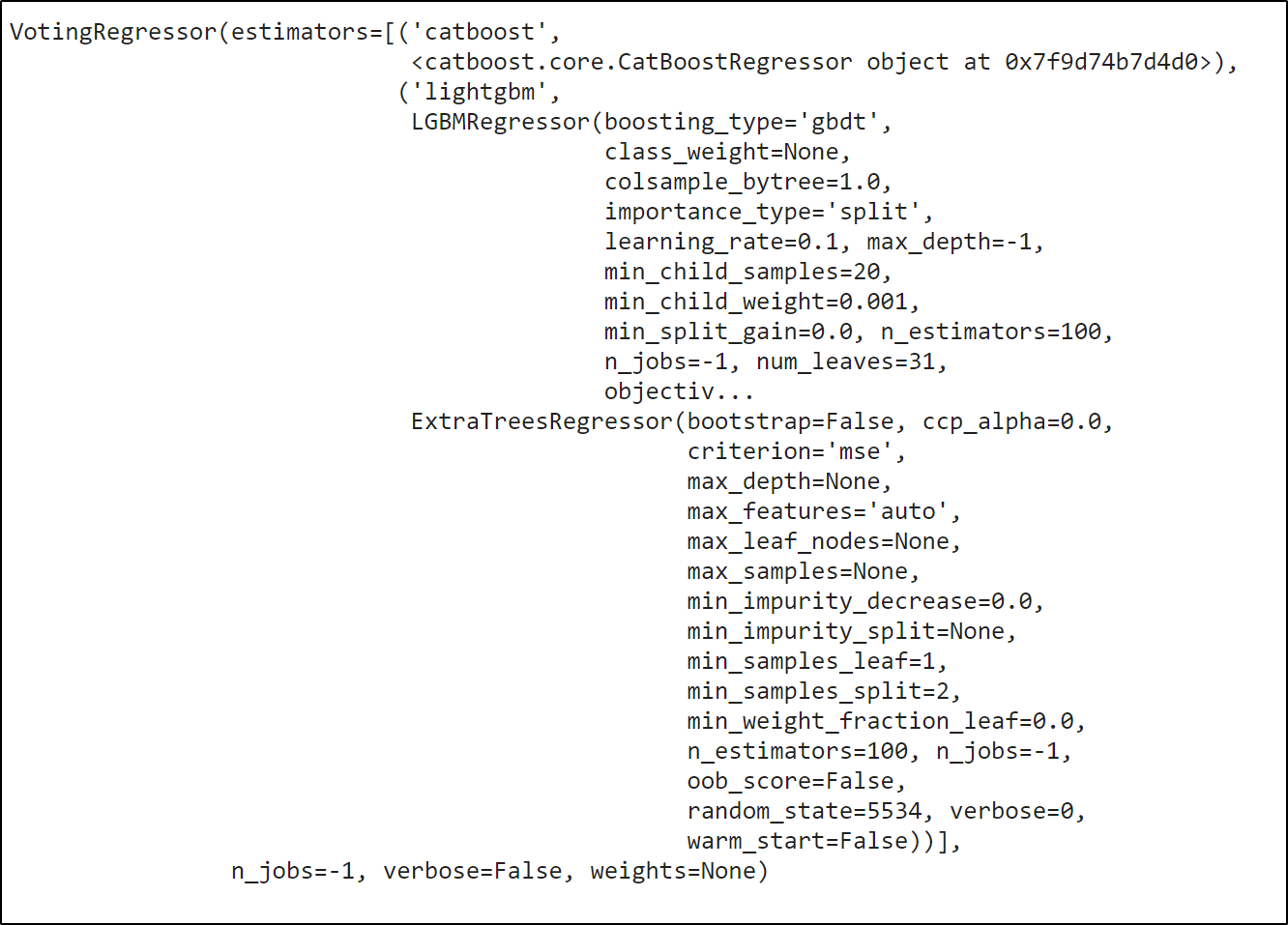
tune_model()
tuned_blended = tune_model(blended)
比較
左がハイパーパラメーターの実行前、右が実行後です。チューニングを行ったことで、重み(Weights)のパラメーターが変わっていることが確認できます。


plot_model()
モデルの性能をビジュアライズをして解析できます。様々な種類のグラフを引数を変えるだけでかき分けることができます。
- ‘residuals_interactive’ - Interactive Residual plots
- ‘residuals’ - Residuals Plot
- ‘error’ - Prediction Error Plot
- ‘cooks’ - Cooks Distance Plot
- ‘rfe’ - Recursive Feat. Selection
- ‘learning’ - Learning Curve
- ‘vc’ - Validation Curve
- ‘manifold’ - Manifold Learning
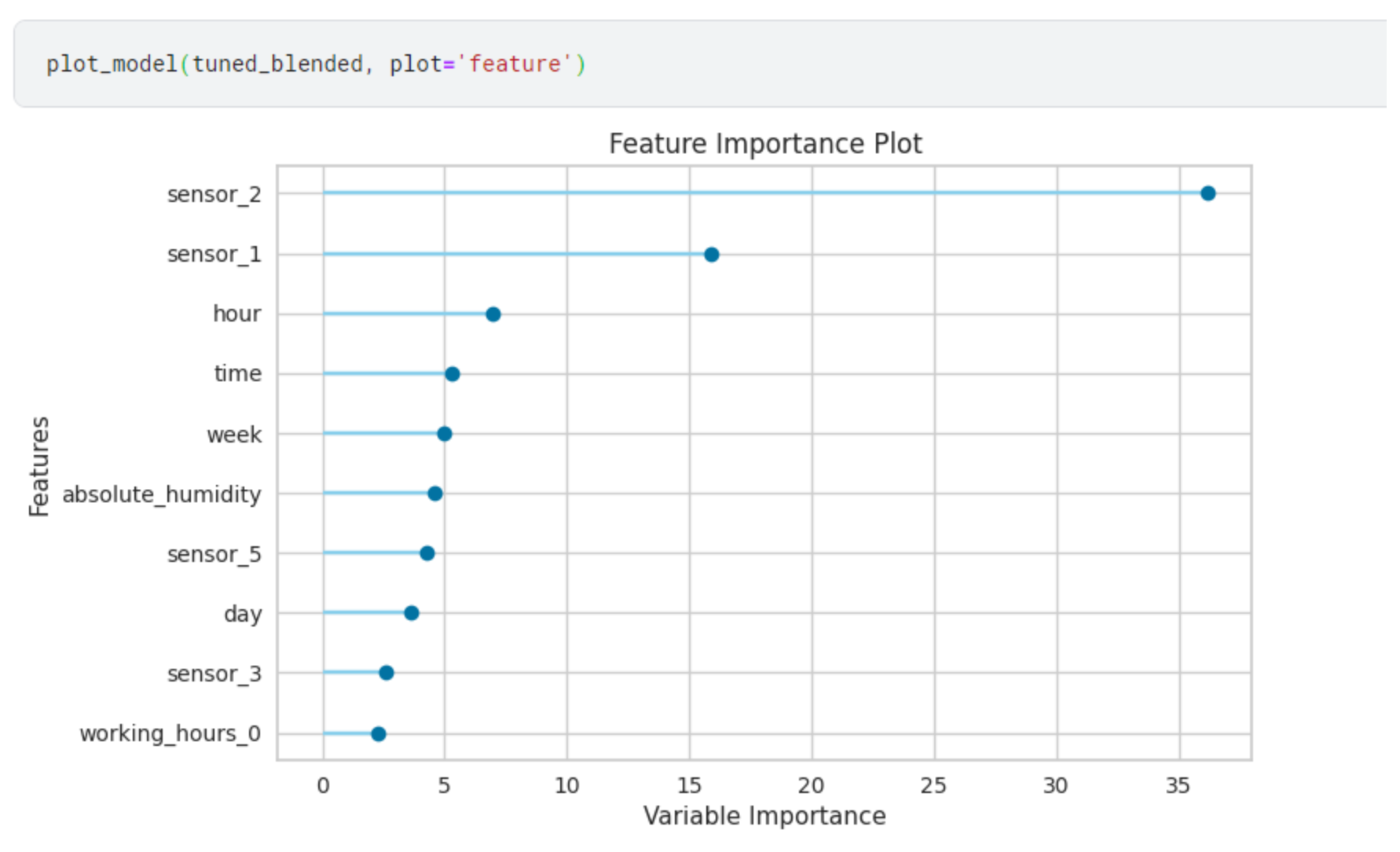
- ‘feature’ - Feature Importance
- ‘feature_all’ - Feature Importance (All)
- ‘parameter’ - Model Hyperparameter
- ‘tree’ - Decision Tree
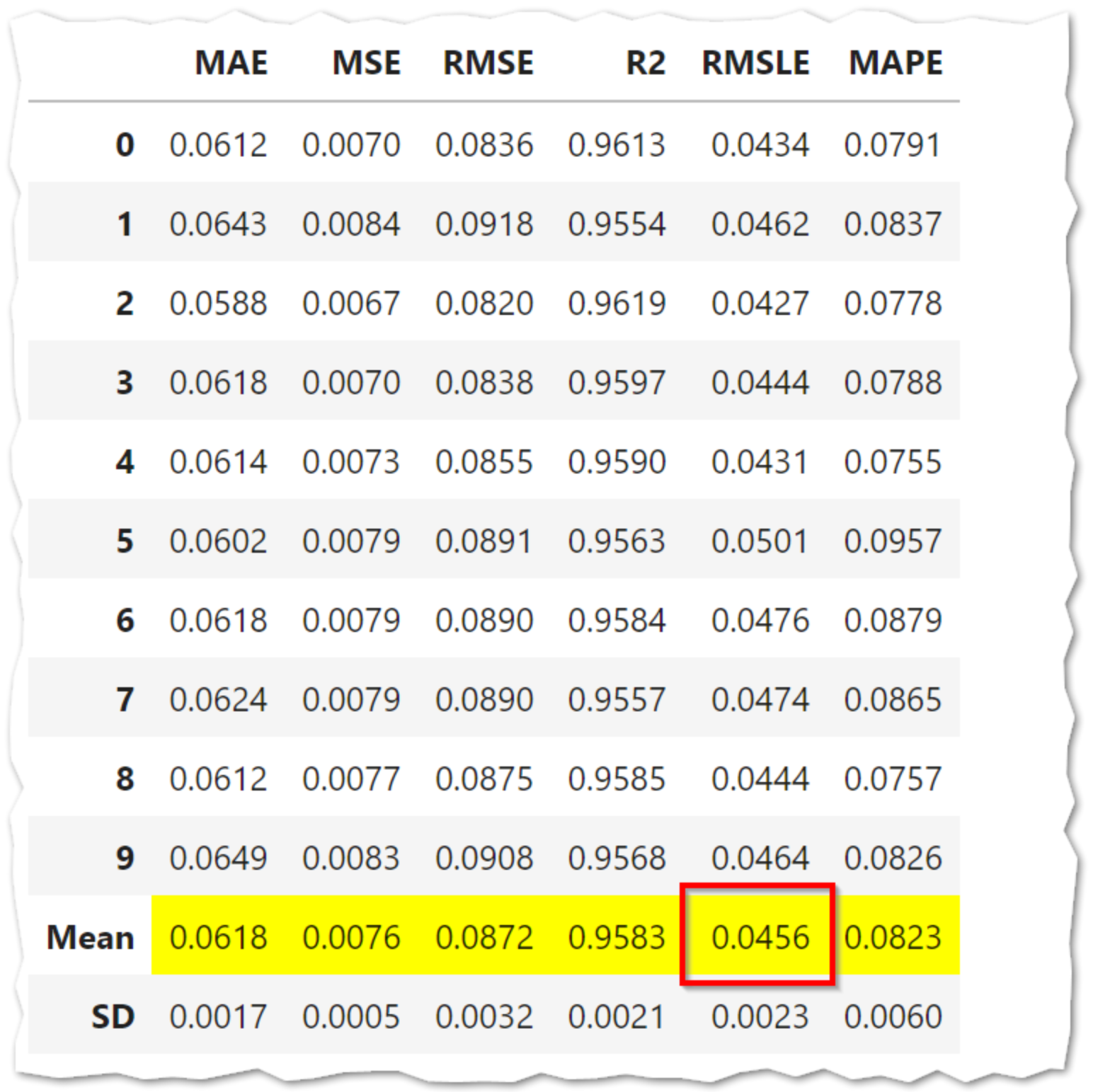
Prediction Error Plot 予測誤差
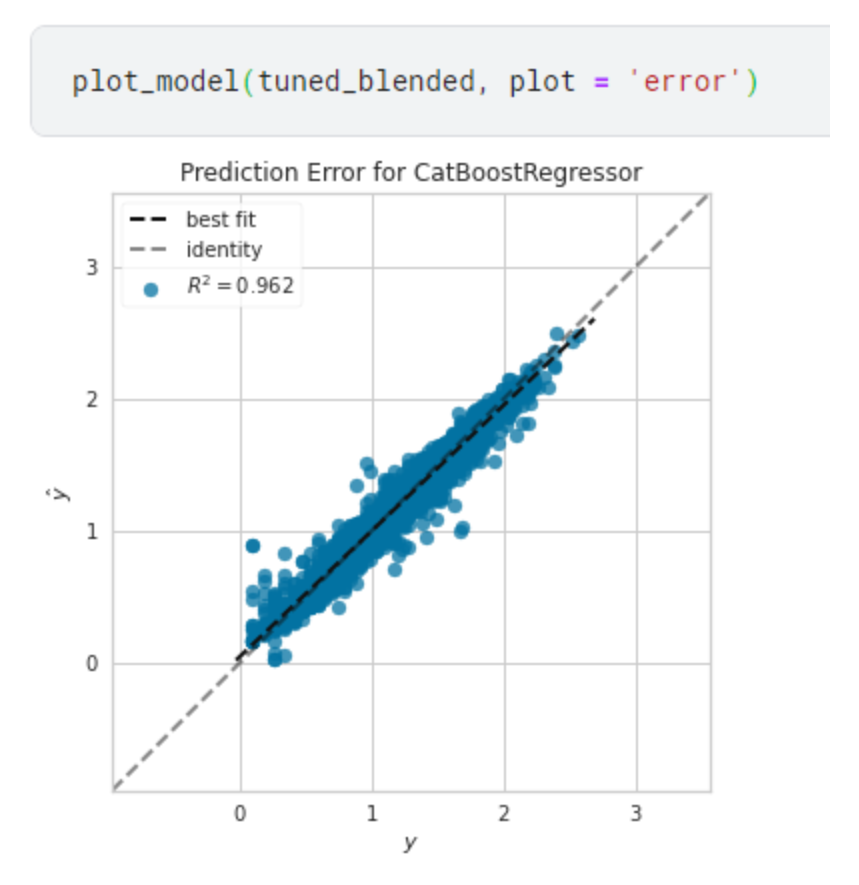
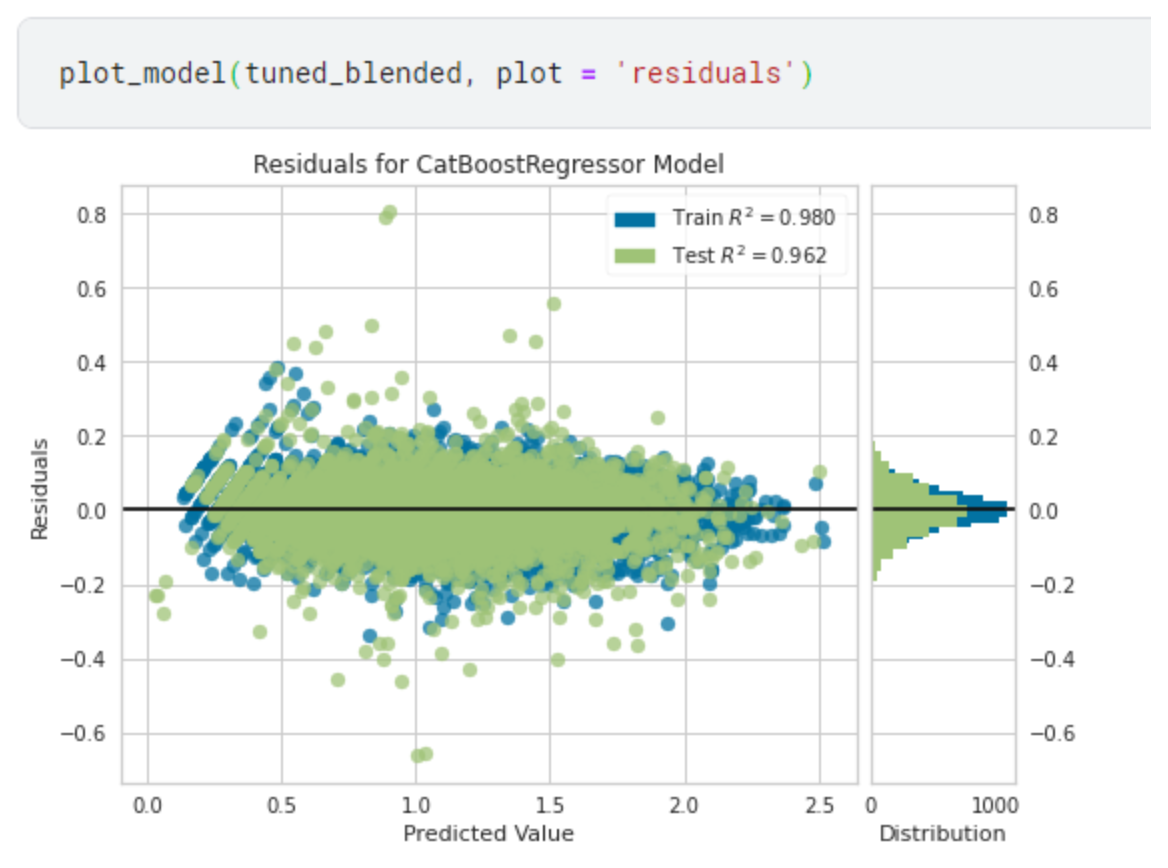
Residuals Plot 残差プロット
Cook's Distance Plot クックの距離
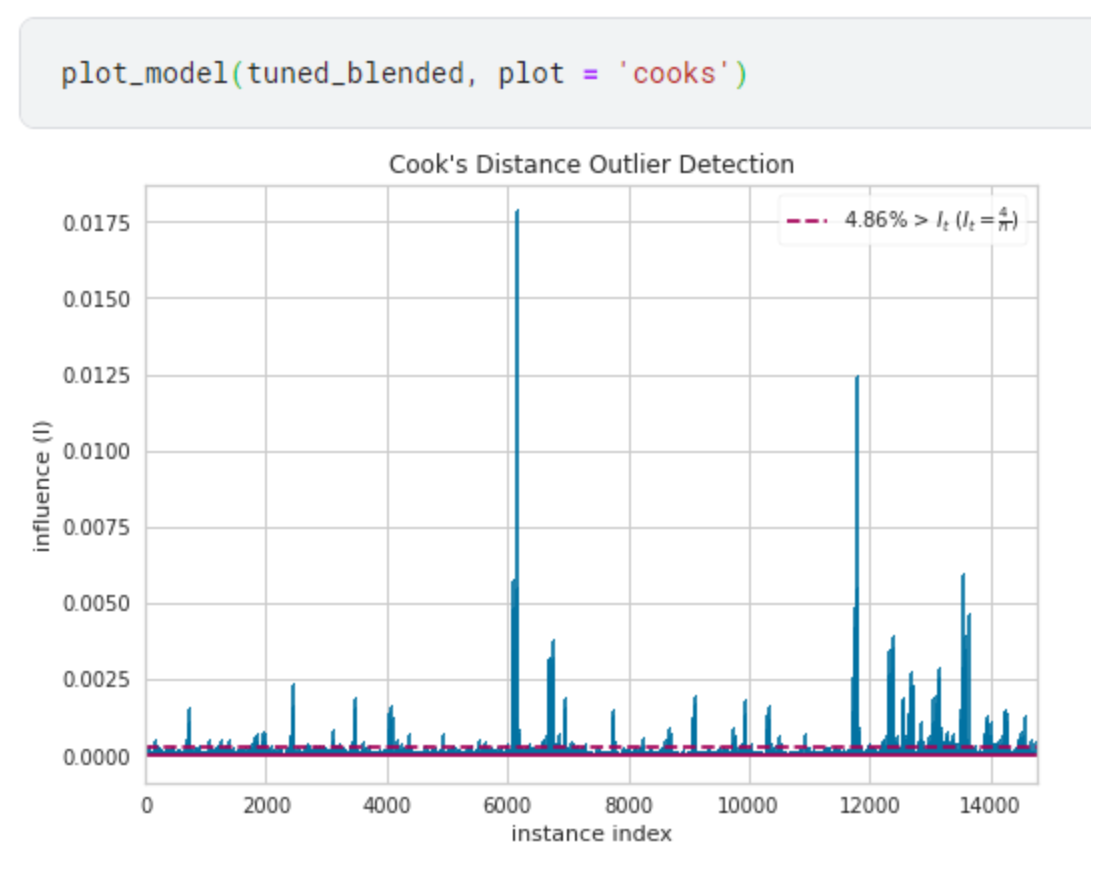
Feature Importance
evaluate_model()
学習済みモデルの性能を分析するためのユーザインタフェースを表示します。内部でplot_model関数を呼び出しています。ボタンを押したときに計算を実行するので、データ量や選ぶグラフによっては結果表示に時間がかかる場合があります。
evaluate_model(tuned_blended)
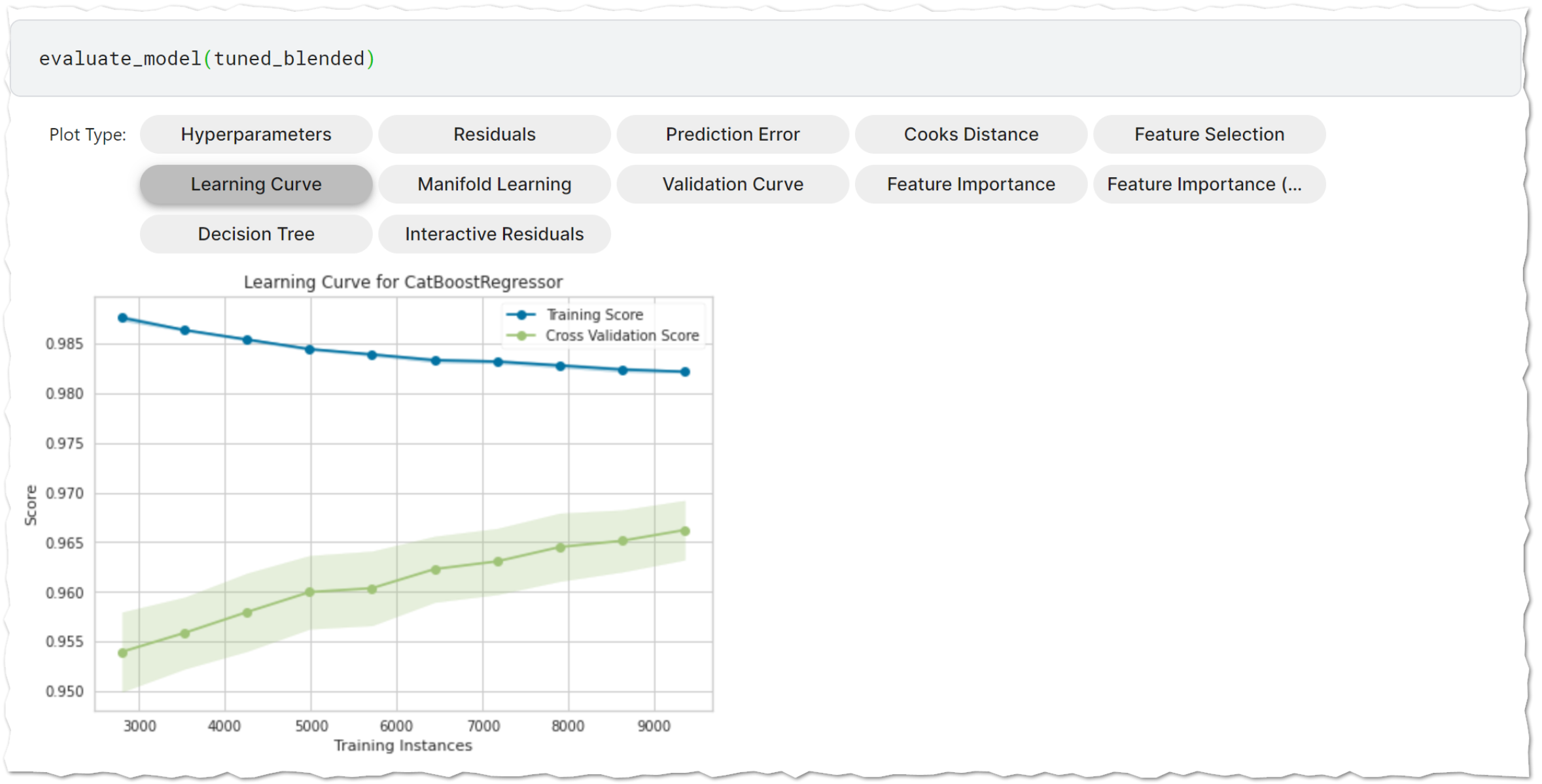
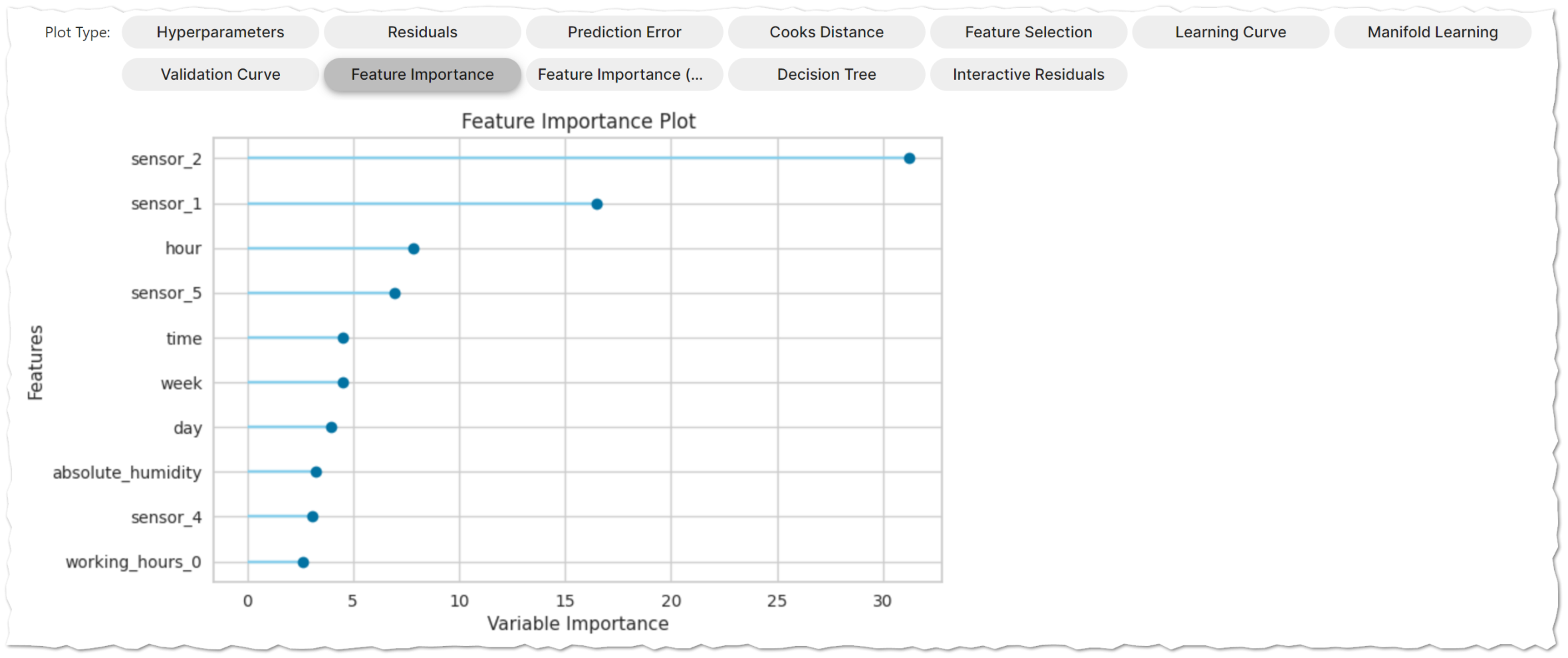
finalize_model()
データセット全体に対して学習させます。
final_model = finalize_model(tuned_blended)
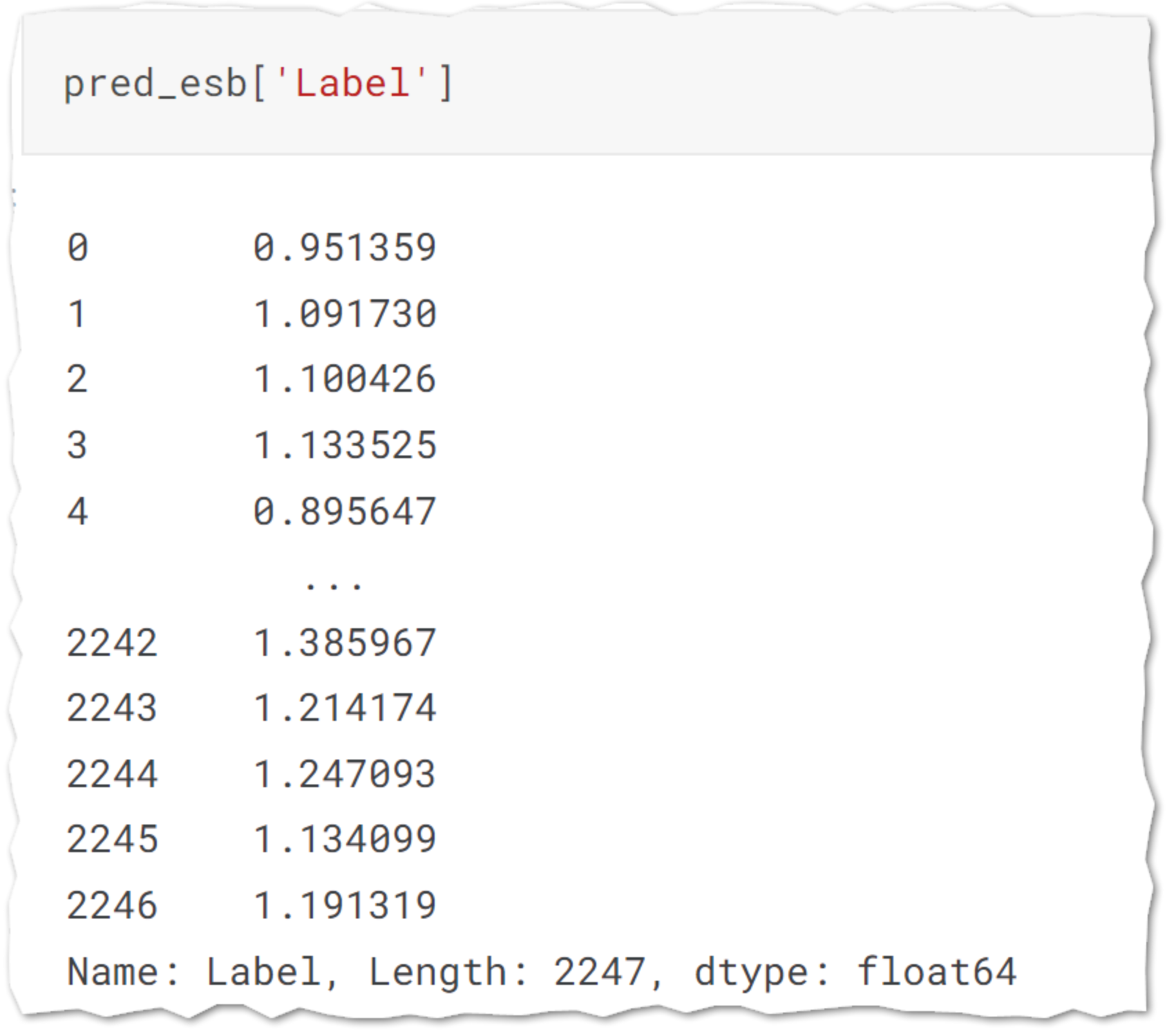
predict_model()
学習されたモデルを用いてLabel列に予測を入れる。
pred_esb = predict_model(tuned_blended)
submit
サブミット用データの作成をします。
対数を元の数値に変換するため、np.exp関数を使用。
sub = pd.read_csv('../input/tabular-playground-series-jul-2021/sample_submission.csv')
sub['target_carbon_monoxide'] = np.exp(pred_esb['Label'])-1
AutoMLの関数化
上記まで書いたのがPyCaretを使用したAutoMLの一連の流れですが、KaggleやGoogleColabのNotebook上でそれぞれ実行を繰り返すのが少し手間がかかります。ですので、これらの手順をまとめて関数にし、必要な引数を入力すれば自動で予測まで実行してくれるようにします。
def pycaret_model(train, target, test, n_select, fold, opt, exclude):
print('Setup Your Data....')
setup(data=train,
target=target,
silent= True)
print('Comparing Models....')
top3 = compare_models(sort=opt, n_select=n_select, fold = fold, exclude = exclude)
print('Blending Models....')
blended = blend_models(estimator_list= top3, fold=fold)
print('Tuning Models....')
tuned_blended = tune_model(blended)
print('Finallizing Models....')
final_model = finalize_model(tuned_blended)
print('Done...!!!')
pred_esb = predict_model(final_model, test)
re = pred_esb['Label']
return re
'target_benzene' と 'target_nitrogen_oxides' の予測
自作関数を使用して残り2つを予測していきます。関数化したので、コードもシンプルです。
sub['target_benzene'] =
np.exp(
pycaret_model(
train_be, 'target_benzene', test_3, 3, 10, 'RMSLE', ['knn', 'xgboost'])
)-1
sub['target_nitrogen_oxides'] =
np.exp(
pycaret_model(
train_no,
'target_nitrogen_oxides', test_3, 3, 10, 'RMSLE', ['xgboost'])
) - 1
後処理
後処理してます。
仕上げ ①
leak_sub =
pd.read_excel(
'../input/air-quality-time-series-data-uci/AirQualityUCI.xlsx'
)
[7110:].reset_index(
drop = True
)
仕上げ ②
co_out = leak_sub[leak_sub['CO(GT)'] == -200].index
be_out = leak_sub[leak_sub['C6H6(GT)'] == -200].index
ni_out = leak_sub[leak_sub['NOx(GT)'] == -200].index
leak_sub.loc[co_out, 'CO(GT)'] = sub.loc[co_out, 'target_carbon_monoxide']
leak_sub.loc[be_out, 'C6H6(GT)'] = sub.loc[be_out, 'target_benzene']
leak_sub.loc[ni_out, 'NOx(GT)'] = sub.loc[ni_out, 'target_nitrogen_oxides']
sub['target_carbon_monoxide'] = leak_sub['CO(GT)']
sub['target_benzene'] = leak_sub['C6H6(GT)']
sub['target_nitrogen_oxides'] = leak_sub['NOx(GT)']
submit 用の csv を作成
sub.to_csv('sub.csv', index = 0)
これでサブミット用のCSVを作成すれば基本は作業終了です。
が、ここから、各関数の引数をいろいろいじくってみようと思います。
試行錯誤の開始
setup() 引数追加
exp = setup(data=train_co,
target='target_carbon_monoxide',
normalize = True, # 数値列を標準化
numeric_imputation = 'mean', # 欠損値の穴埋め
silent= True) # データ型の確認なし
blend_models() 引数追加
blended = blend_models(
estimator_list= best,
fold=10, # 交差検証の回数
optimize='RMSLE', # 評価指数
choose_better = True # 結果がよくなるときのみブレンドされたモデルを返す
)
サーチライブラリの変更
ハイパーパラメーターのチューニングにoptunaを使用。
デフォルトはscikit-learn
# !pip install optuna
tuned_blended = tune_model(
blended,
optimize='RMSLE',
search_library="optuna", # optuna の使用
choose_better = True,
n_iter=30
)
tune_model()の使用順を変更
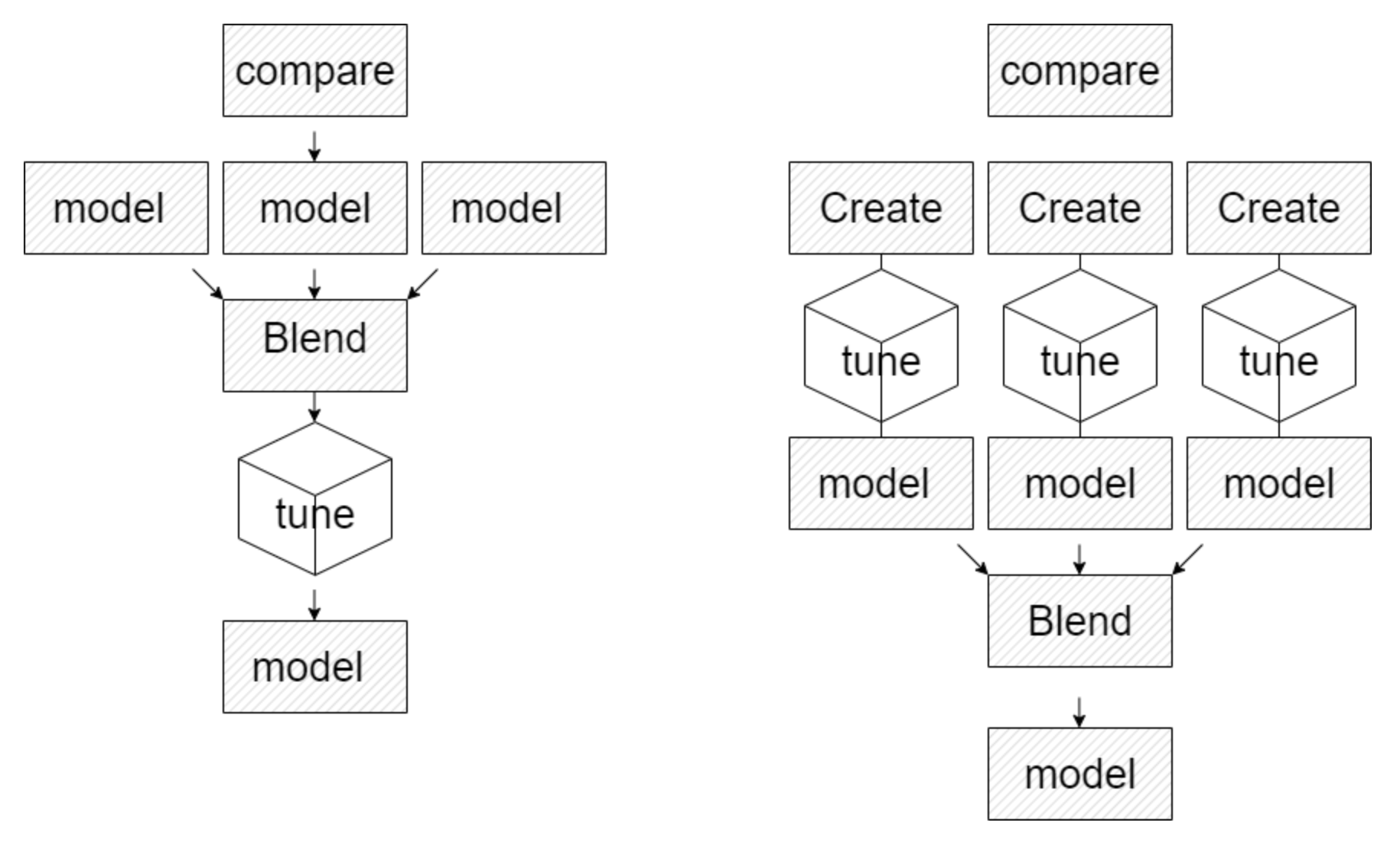
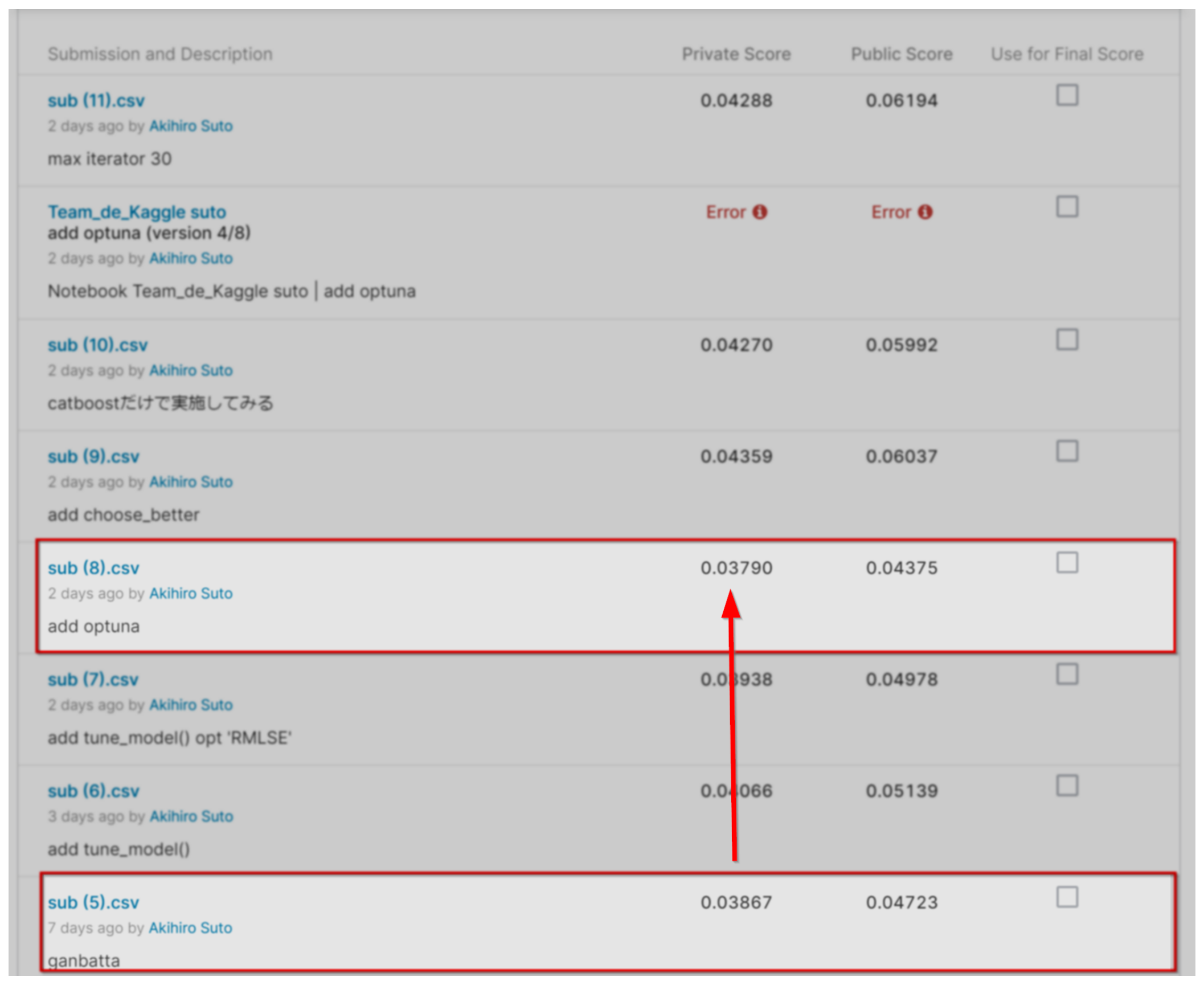
SCORE
試行錯誤してみたものの、やればやるほどスコアがあがっていくわけではありませんでした。いいスコアがでたり、でなかったり。一筋縄ではいかないなぁ・・という感じ。
作成したNoteBook
実際に作成したNoteBookのリンクを貼ります。自分の環境にコピーして実行してみてください。
まとめ
PyCaretは導入から実行までかんたん便利![]()
ドキュメントを読み、
- 各関数の使用順
- 引数でできること
頭の整理に役立つなぁと思いました。
appendix
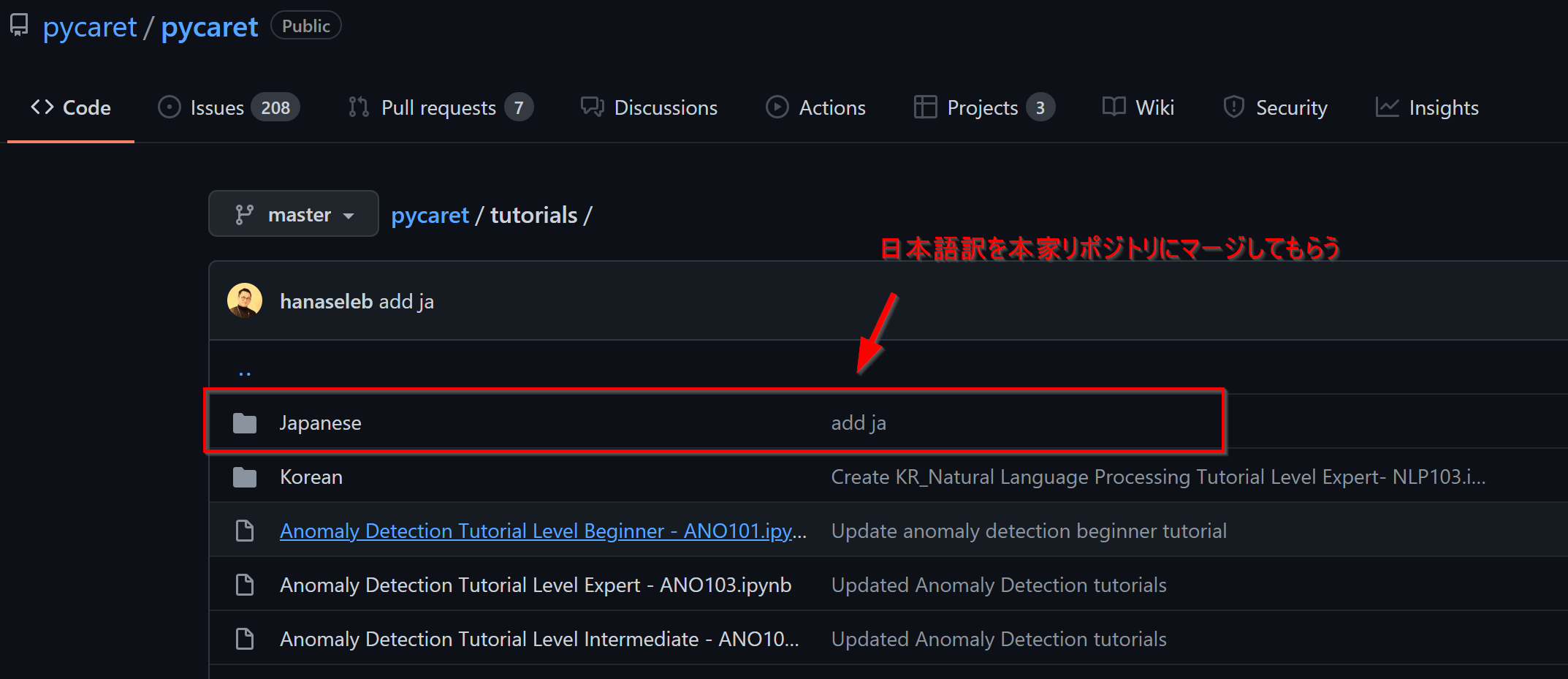
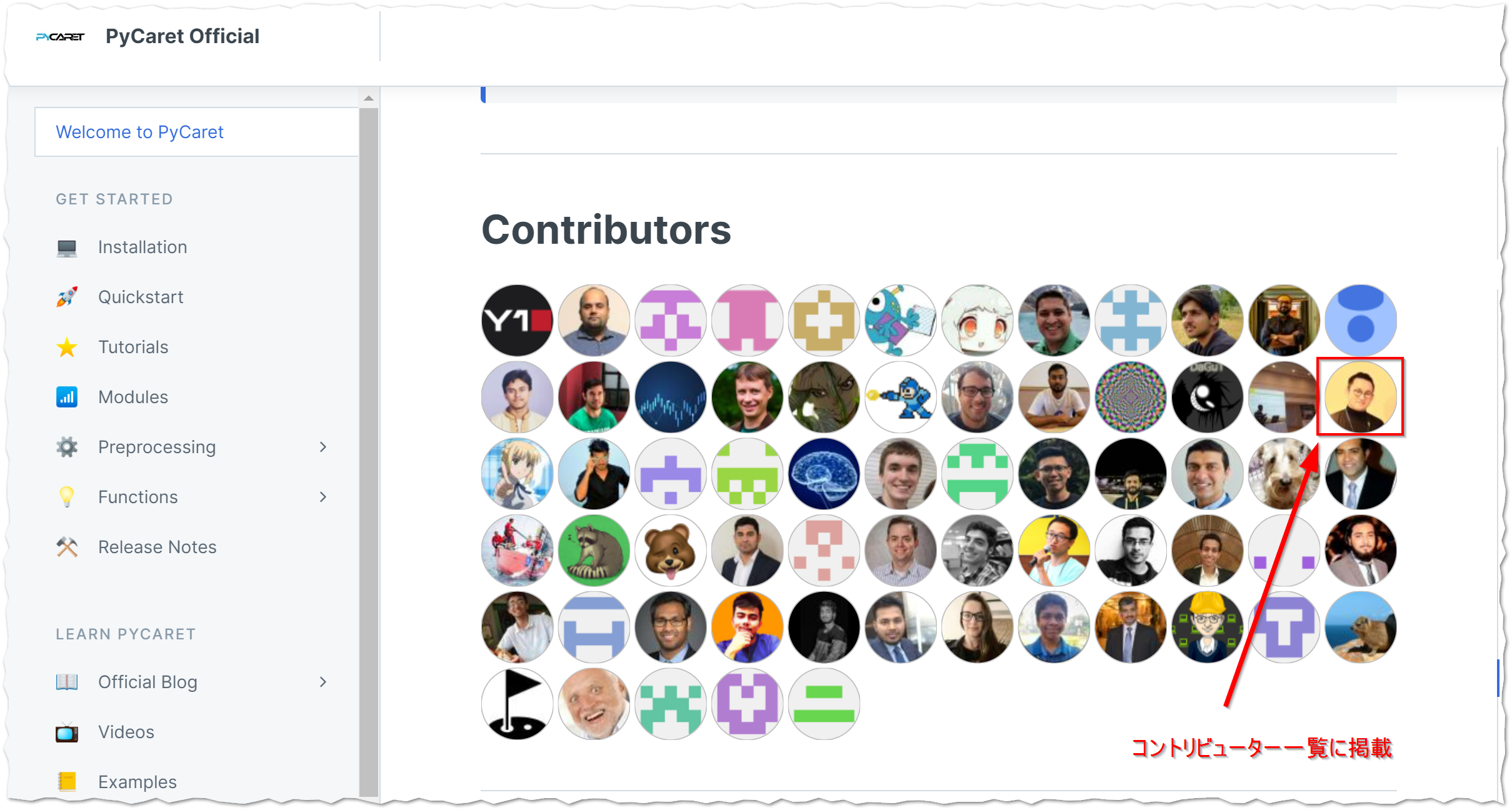
PyCaret公式のチュートリアルがボリュームも有りわかりやすかったので、日本語に翻訳をして公式リポジトリにプルリクを送ってみました。見事マージされ、コントリビューター一覧にも掲載![]()
チュートリアルの翻訳はまだ回帰しかやっていないのですが、いずれ他も取り組みたいと思います!協力してもらえる人も大募集![]()