はじめに
インフルで1週間潰しました。辛かった。。。
ということで、クローリングについてです。
Pythonでクローリングするとなると、Scrapyはかなりよく出てくると思います。
僕も初めて触ってからかれこれ2年以上経っているように思います。
弊社Liaroでも使ってますし、何と言っても3系対応したのが嬉しいですね。
何を書くか
チュートリアルとかは散々落ちてますので、TwitterをクローリングするときにAPIとどう連携させたかを書こうかと。どこか参考にしたはずなのですが忘れてしまい。。。見つけ次第リンク貼っておきます。
やってみた
方針
基本的には下図で言うMiddlewareをTwitter用に書いて、settingsを書いておく感じです。
Pythonバージョンは3.5.1で、Twitterライブラリはpython-twitterを使いました。
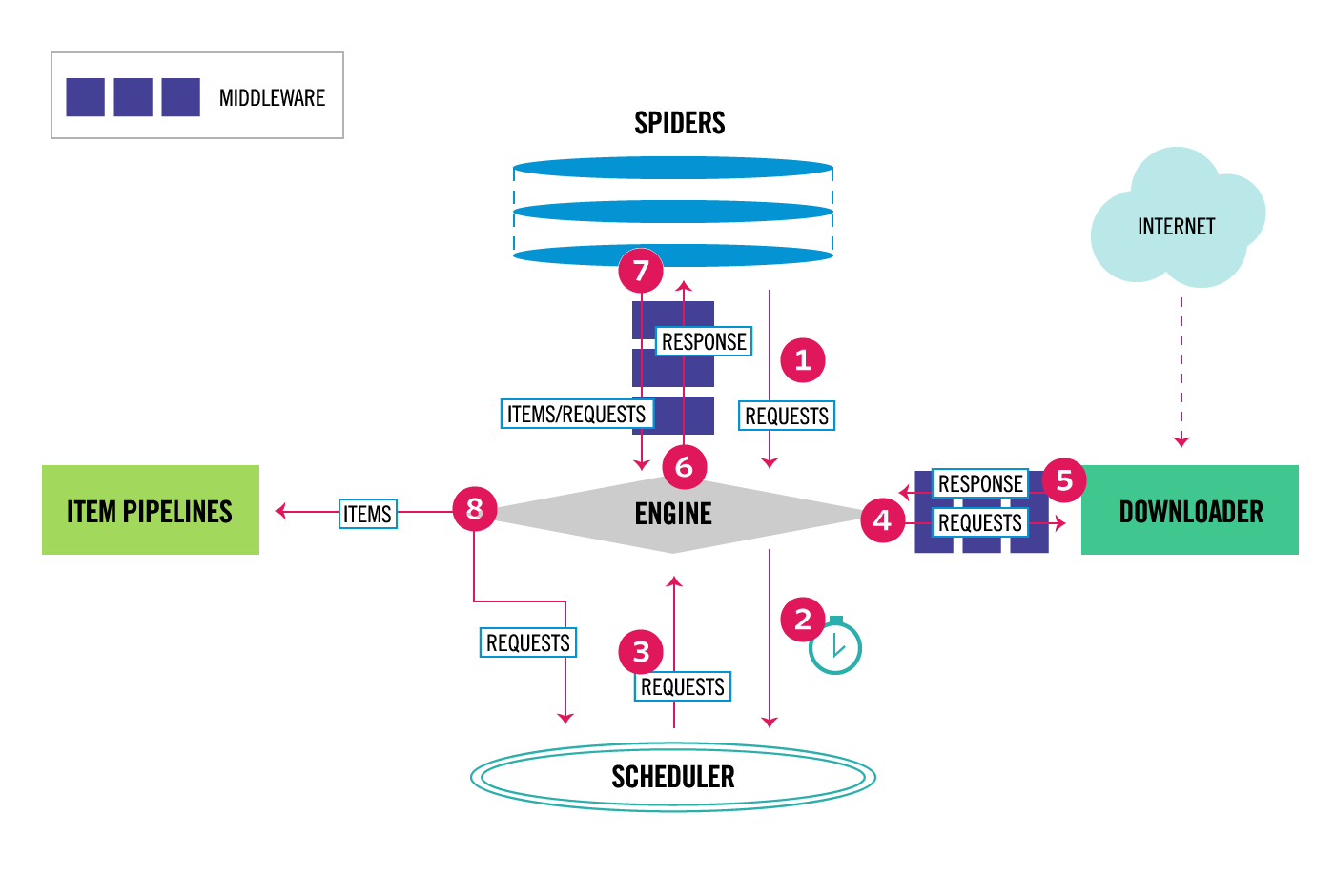
Middleware
TW_CONSUMER_KEYとかはsettings.pyに書き込んでます。
trackに書かれているキーワードでself.api.GetStreamFilter(track=request.track)で実際に検索をかけて、レスポンスを返している形です。
twitter_middleware.py
from scrapy.http import Response, Request
import twitter
TWITTER_URL = "https://twitter.com"
class TwitterStreamRequest(Request):
def __init__(self, *args, **kwargs):
self.track = kwargs.pop('track', None)
super(TwitterStreamRequest, self).__init__(
TWITTER_URL, dont_filter=True, *args, **kwargs
)
class TwitterResponse(Response):
def __init__(self, *args, **kwargs):
self.tweets = kwargs.pop('tweets', None)
super(TwitterResponse, self).__init__(TWITTER_URL, *args, **kwargs)
class TwitterDownloadMiddleware:
@classmethod
def from_settings(cls, settings):
return cls(
settings.get('TW_CONSUMER_KEY'),
settings.get('TW_CONSUMER_SECRET'),
settings.get('TW_ACCESS_KEY'),
settings.get('TW_ACCESS_SECRET'),
)
def __init__(self, TW_CONSUMER_KEY, TW_CONSUMER_SECRET,
TW_ACCESS_KEY, TW_ACCESS_SECRET):
self.api = twitter.Api(
consumer_key=TW_CONSUMER_KEY,
consumer_secret=TW_CONSUMER_SECRET,
access_token_key=TW_ACCESS_KEY,
access_token_secret=TW_ACCESS_SECRET
)
def process_request(self, request, spider):
tweets = self.api.GetStreamFilter(track=request.track)
return TwitterResponse(tweets=tweets)
def process_response(self, request, response, spider):
return response
Spider
trackでキーワード設定していて、start_requestsで動的にスタートのURLを設定できるのでそこで、Twitterにリクエストを送っています。
twitter_spider.py
from scrapy.spiders import CrawlSpider
from twscrapy.twitter_middleware import TwitterStreamRequest
class TwitterStreamSpider(CrawlSpider):
name = "twitter_stream"
allowed_domains = ["twitter.com"]
track = ['PPAP']
# dynamically start_urls
def start_requests(self):
return [TwitterStreamRequest(track=self.track)]
def parse(self, response):
for tweet in response.tweets:
print(tweet["text"])
settings
settingsの一部です。自分で書いた書いたMiddleware名を記述しておかないと読み込んでくれないので。
settings.py
DOWNLOADER_MIDDLEWARES = {
'twscrapy.twitter_middleware.TwitterDownloadMiddleware': 590,
}
# twitter key
TW_CONSUMER_KEY = ""
TW_CONSUMER_SECRET = ""
TW_ACCESS_KEY = ""
TW_ACCESS_SECRET = ""
結果
RT @talk2tomozuki1: มิน่าทึกถึงบอก ใครเห็นสภาพนี้แล้วยังรักกันคือแฟนตัวจริง😂เราว่าเอลฟ์รับได้อยู่แล้ว เอสเจเคยไม่บ้า เคยไม่ตลกด้วยเหรอ😂…
RT @joker_budou: 3兄弟でPPAP。 https://t.co/Bm9byeXKBK
RT @rolling_milk: 皆さん、忘年会の出し物で若手男性社員たちがピコ太郎の格好でPPAPをやらされてスベり倒し、若手女性社員たちがかわいこぶって恥ずかしがりながらグダグダな恋ダンスを踊ってニヤニヤするオジサンたちをよそにオバサンたちの目に殺意が宿る季節が、やって来…
RT @TeukBar: 20161205 ELF Japan #leeteuk #이특 오사카 팬미팅 back to Seoul at Kix airport 고생 많았어요 ^^ PPAP 대박 ㅋㅋㅋㅋ https://t.co/brCi2D2ksR
@K_tori0106 PPAP https://t.co/QAndR4oV7u
RT @goo1105: PPAP✒🍎🍍✒
サッカーマン瑞貴編 https://t.co/3fZiB0Dovx
RT @19861015donghae: ジョンスのPPAP🖊🍍🍎🖊
ステップが完璧のようですww
恥ずかしがってる割に罰ゲームで1部2部ともにやっていて、ヤツは絶対気に入ってるwwww
個人的には髪型大仏にしか見えない件←
# Leeteuk #PPAP #Osaka…