今回つくるもの
Amazonによく出てくる『この商品を買った人はこんな商品も買っています』機能を作ってみよう。

要素技術と実装方法
一般的にレコメンド機能(オススメ機能)と呼ばれる機能。レコメンドの実装方法は大きく2つ『協調フィルタリング』と『コンテンツベースフィルタリング』。
コンテンツベースフィルタリングは、例えば上記例の『老人と海(ヘミングウェイ)』のお勧め商品をコンテンツベースで実装する場合は、事前に商品に属性のタグを打っておく。例えば作者という属性でタグを打っておけば、同じヘミングウェイが記した本をお勧めとして表示する。
協調フィルタリングは、この商品を買った他の人が買った商品をお勧めとして表示する。
今回は『協調フィルタリング』を実装する。
redisとpython使います。
redisはKVS
redisのSortedSetを利用する。
redisインストール手順
MacPorts:http://blog.katsuma.tv/2010/03/start_redis.html
HomeBrew:http://qiita.com/items/3d2a2fc683ae19302071
redisを利用する理由
オススメ商品を都度計算するのは計算量の観点から現実的ではなく、事前に計算しておき取り出しやすい形で記録しておくことが必要だったからです。(取り出しやすく記録できるならばRedis以外を利用しても問題ない)
SortedSetとは
データ入れると自動で(redis側で)並び換えるリスト
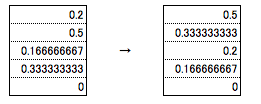
協調フィルタリングの実装
商品Xに対する各商品の類似度を値として取得できれば実装できる
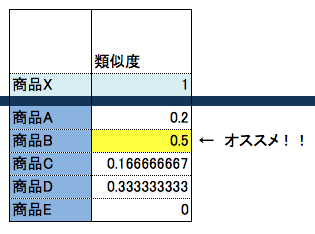
類似度の計算式
いろいろあるけど、Jaccard指数(ジャッカールしすう)を使うのが一般的。
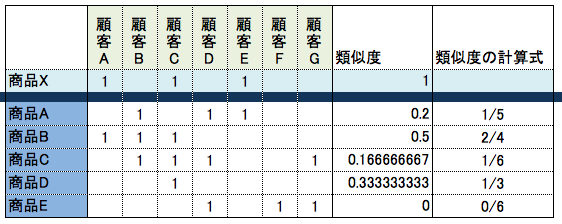
下記のサンプルデータだと商品Aの計算式は 1÷5 となる。
1は商品Xと商品Aを両方購入した顧客が1名ということ。つまり積集合
5は商品Xと商品Aのどちらかを購入した顧客の総数。つまり和集合
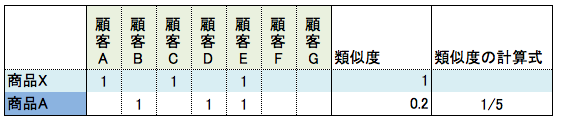
今回利用するサンプルデータ
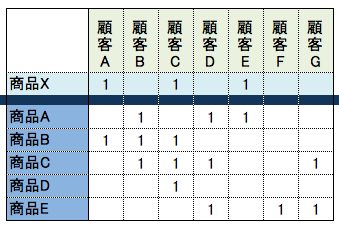
実装
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import unicode_literals
def jaccard(e1, e2):
"""
ジャッカード指数を計算する
:param e1: list of int
:param e2: list of int
:rtype: float
"""
set_e1 = set(e1)
set_e2 = set(e2)
return float(len(set_e1 & set_e2)) / float(len(set_e1 | set_e2))
def get_key(k):
return 'JACCARD:PRODUCT:{}'.format(k)
# 商品Xを購入した顧客IDが1,3,5ということ
product_x = [1, 3, 5]
product_a = [2, 4, 5]
product_b = [1, 2, 3]
product_c = [2, 3, 4, 7]
product_d = [3]
product_e = [4, 6, 7]
# 商品データ
products = {
'X': product_x,
'A': product_a,
'B': product_b,
'C': product_c,
'D': product_d,
'E': product_e,
}
# redis
import redis
r = redis.Redis(host='localhost', port=6379, db=10)
# ジャッカード指数を計算して商品毎にredisのSortedSetに記録する
for key in products:
base_customers = products[key]
for key2 in products:
if key == key2:
continue
target_customers = products[key2]
# ジャッカード指数を計算
j = jaccard(base_customers, target_customers)
# redisのSortedSetに記録する
r.zadd(get_key(key), key2, j)
# 例1 商品Xを買った人はこんな商品も買っています。
print r.zrevrange(get_key('X'), 0, 2)
# > ['B', 'D', 'A']
# 例2 商品Eを買った人はこんな商品も買っています。
print r.zrevrange(get_key('E'), 0, 2)
# > ['C', 'A', 'X']
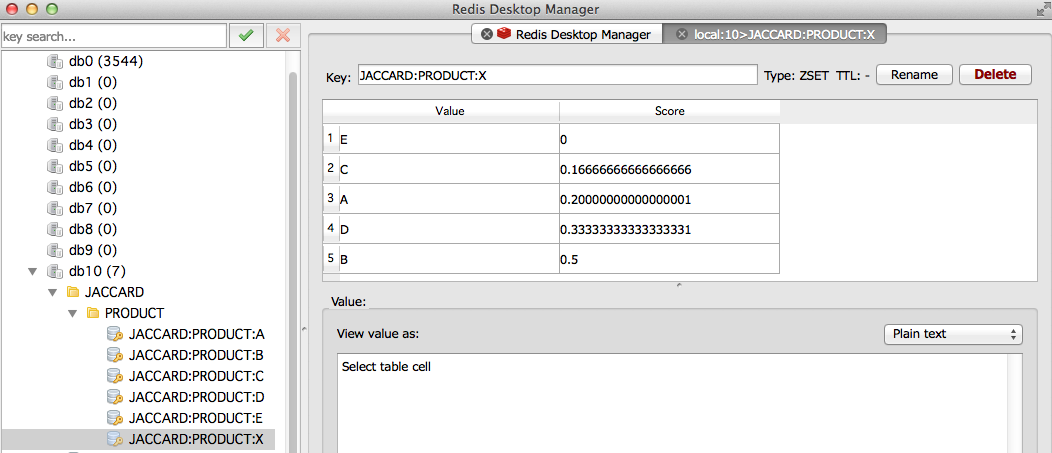
redisに入った値をみてみよう
検算してみよう
商品Xを買った人には商品B,D,Aがオススメされています。
検算すると、それぞれ0.5, 0.33, 0.2の類似度なので適切にレコメンドされているみたいですね。
この方法の問題点
顧客数と商品数が増えると計算量が爆発して死ぬ
解決方法
転置インデックス作りましょう by Amazon
http://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf