はじめに
2019年、東大松尾研究室のデータサイエンティスト育成講座(全5日間)を受けて、テレビゲームの売上データセットを分析する記事をQiitaに投稿しました。
あの時は、Google Colab(Jupyter Notebook)で、Pandasの使い方をググりながら、試行錯誤を繰り返して、約1ヶ月かけて回帰モデルや分類モデルを作りました。コーディング自体に苦手意識があった私にとっては、なかなかの挑戦でした。
あれから7年。2026年の今、Claude Codeを使って同じようなことをやってみたら、ものの10分で終わりました。
いい時代になったなあ、と思った一方、AIに任せることの落とし穴もあったので記事にします。
2019年にやったことの振り返り
まず、当時やったことを簡単に振り返ります。
使ったもの
- Python(pandas、NumPy、scikit-learn、matplotlib、seaborn)
- Google Colaboratory(Jupyter Notebook)
- Kaggleのビデオゲーム売上データセット(約16,000タイトル、11カラム)
やったこと
- データの読み込み・前処理: 欠損値の除外、日本で発売されたタイトルに絞り込み、発売年を年代にまとめる
- データの可視化: メーカー別の売上グラフ、ジャンル別の地域比較、seabornでpairplot
- 回帰モデル: One-hotエンコード → 重回帰で「日本の販売本数」を予測(線形回帰、Ridge回帰など)
- 分類モデル: ロジスティック回帰で「任天堂が発売したゲーム」を当てる(混同行列、F1スコアで評価)
苦労したこと
- Pandasの操作を都度ググっていた
- One-hotエンコードでカラムが爆発した(メーカー303社...)
- 全特徴量でモデルを作ったら精度がボロボロで、相関を見ながら手動で特徴量を選び直した
- 分類モデルで正解率0.9が出て喜んだら、クラス不均衡のせいでF1値がダメだった
- バンダイナムコやスクウェア・エニックスなど合併前に発売されたタイトルの名寄せをどうするか悩んだ(結局断念)
要するに、講座で学んだことを活かして手探りでやってみた というのが当時の記事です。それでも時間を忘れて熱中して、楽しかったです。
2026年にやったこと — Claude Code編
今回使ったもの
- Claude Code (モデルはClaude Opus 4.6)
- vgchartz-2024.csv(約64,000タイトル、14カラムの2024年版ビデオゲーム売上データ)
データセットは2019年当時のものより新しく、タイトル数は約4倍。カラムも developer(開発会社)や critic_score(批評スコア)が追加されていて、より分析しがいのあるデータになっています。
やったこと
Claude Codeに以下のように伝えました。
「このディレクトリに、テレビゲームの売上に関するCSVと、過去に別のデータセットで回帰モデルとかを作った時のJupyter Notebookがあります。この新しいCSVに対して、ノートブックのようなこと(分析、モデル作成)をやって、HTMLのレポートにまとめてください。」
以上です。
Claude Codeがやってくれたこと
Claude Codeは、まず過去のノートブックを読み込んで、当時何をやったのかを理解してくれました。その上で、新しいCSVのカラム構成との差分を把握し、以下を全自動で実行しました。
- データ読み込みと確認 — 64,016件のデータの基本統計量、欠損値、ユニーク数を確認
-
前処理 — 不要列の除外、
release_dateからの年代抽出、critic_scoreの欠損補完、欠損行の除外(最終的にモデルには6,726件を使用) - EDA(探索的データ分析) — 相関行列ヒートマップ、ジャンル別/パブリッシャー別/コンソール別/年代別の売上チャート、日本市場の分析
- 特徴量エンジニアリング — One-hotエンコード、jp_salesとの相関Top25の抽出
- 回帰モデル — 線形回帰(全特徴量/選択特徴量)、Ridge回帰を比較
- 分類モデル — ロジスティック回帰で任天堂タイトル判別、任天堂ハードフラグの追加による改善
- HTMLレポート生成 — 全グラフ埋め込み・CSS付きの見やすいレポートを1ファイルで出力
さらに驚いたのが、scikit-learnがインストールされていない環境だった にもかかわらず、Claude Codeが回帰・分類のアルゴリズムをNumPyの行列演算で自前実装して対処したことです。 「ライブラリがないならアルゴリズムを書けばいいじゃない」 というマリー・アントワネットのような発想。人間だったら諦めてpip installを試みるところですが、AIは違いました。
かかった時間
約10分。 指示出しから、レポートがブラウザで開かれるまで。
生成されたレポートの紹介
出力されたHTMLレポートから、主な結果を紹介します。
EDA(探索的データ分析)の主な発見
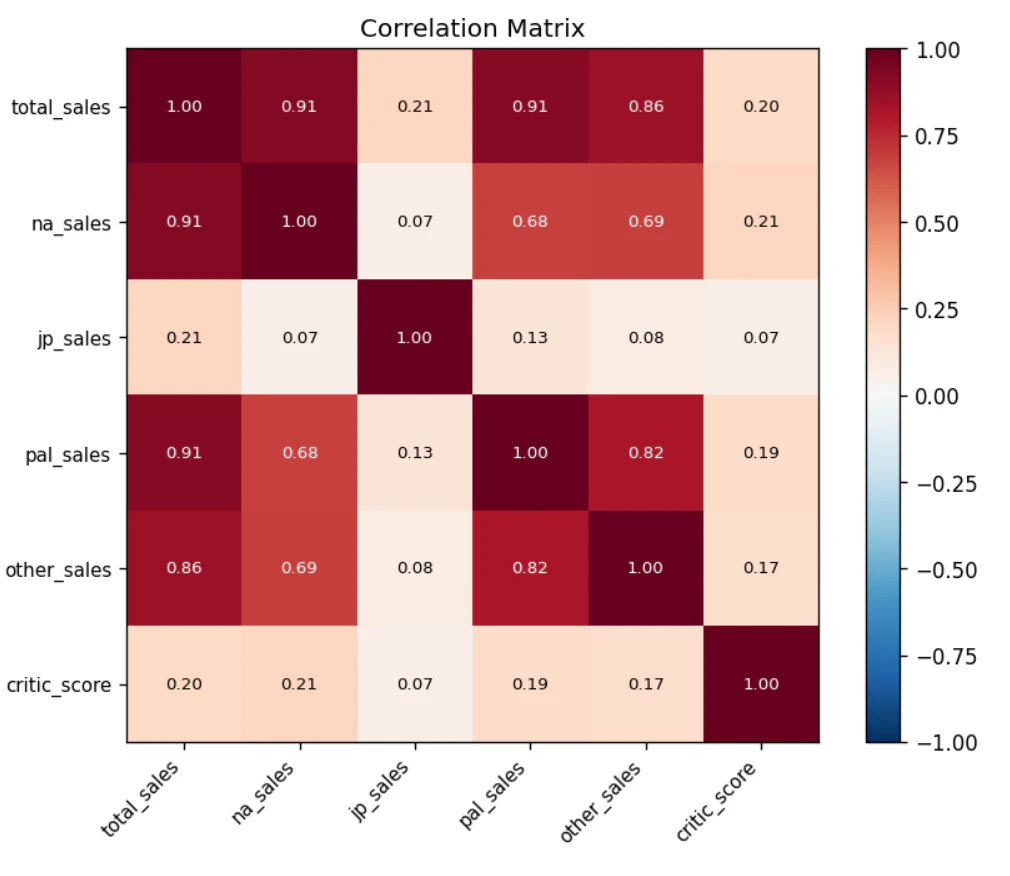
2019年の分析と概ね同じ傾向が確認できました。
- 日本市場は他地域との相関がやや低い — NA(北米)とPAL(主に欧州)は相関が高いが、JP(日本)は独自の傾向
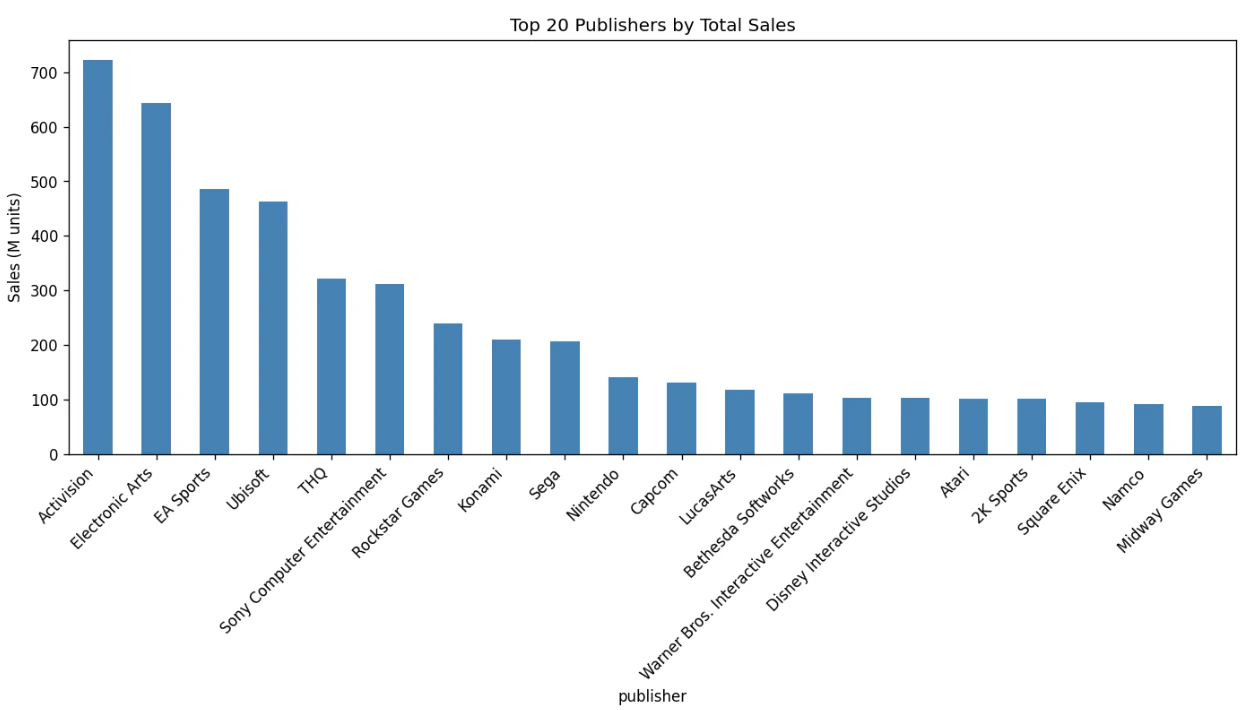
- 売上Top20パブリッシャー — グローバルではActivision、Electronic Artsが上位。日本市場ではKonamiが1位、Nintendoが2位で、2019年版データ(Nintendo 1位)から順位が逆転
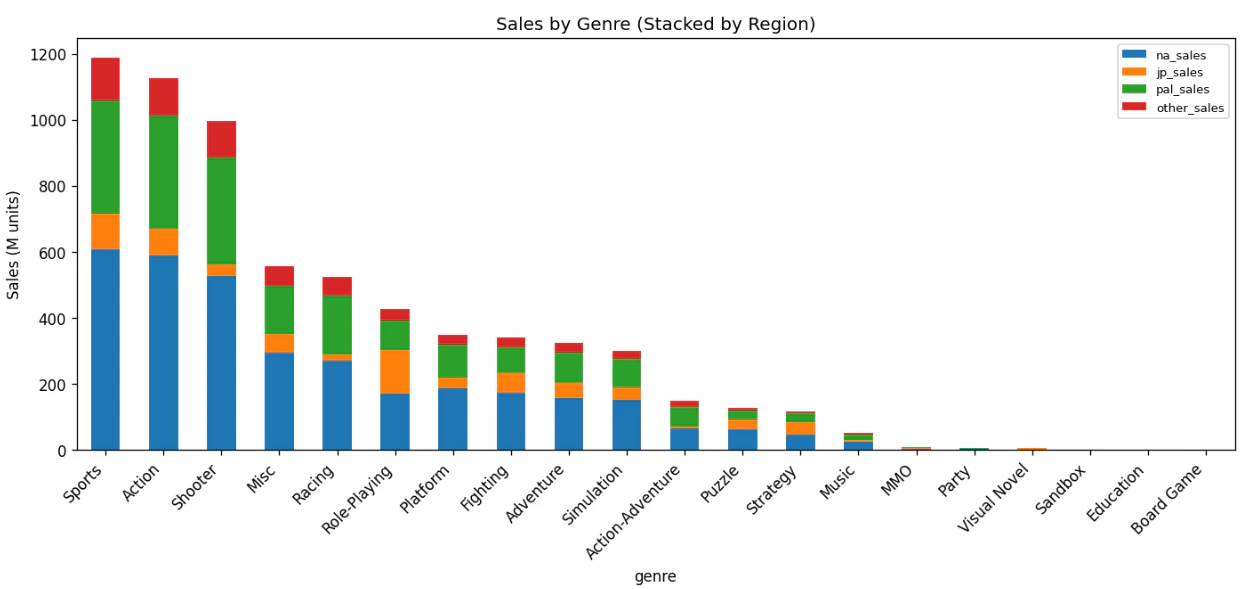
- ジャンル — グローバルではSports > Action > Shooterの順に人気。日本ではRPGが売上1位で存在感が大きい
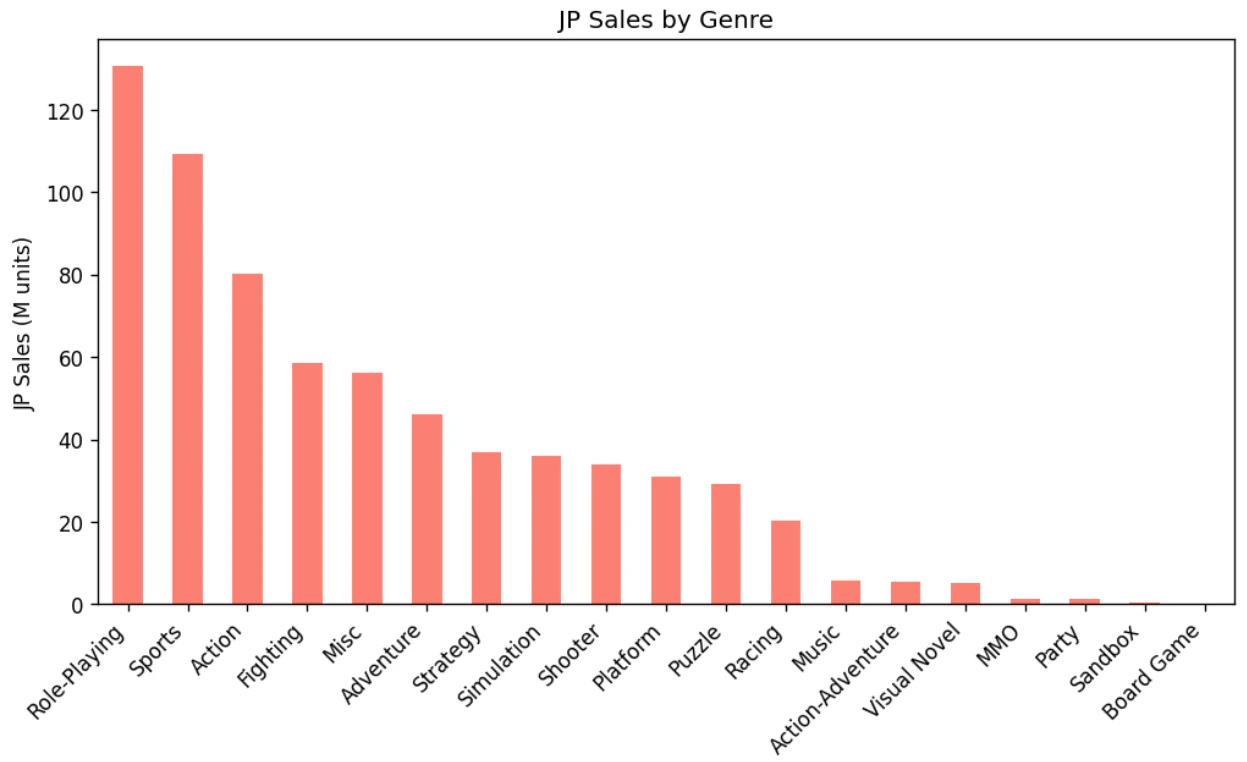
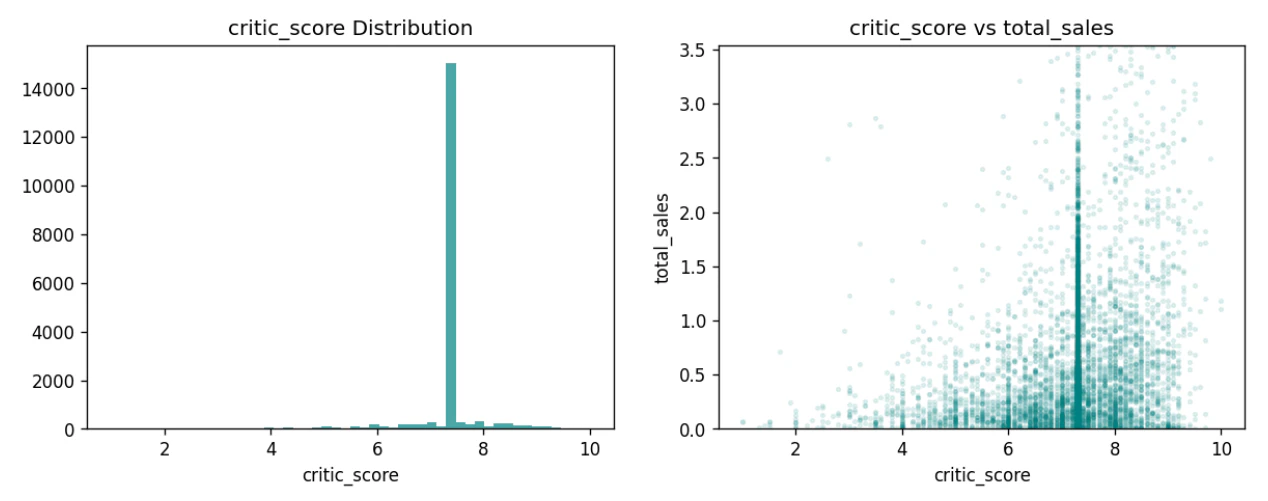
- critic_score — 批評スコアと売上に正の相関。特にスコア8以上のタイトルに高売上が集中
回帰モデル(日本の販売本数予測)
| モデル | R²(test) | RMSE |
|---|---|---|
| 線形回帰(全特徴量) | 0.3041 | 0.1258 |
| 線形回帰(選択特徴量) | 0.0424 | 0.1483 |
| Ridge回帰 | 0.3042 | 0.1258 |
データのスケールが異なるためRMSEを2019年版と単純比較はできませんが、R²(決定係数)は0.30程度で、予測としてはまだ改善の余地がありそうです。
なお、CSVの64,016件のうち、total_salesやjp_salesの欠損除外後は6,726件でモデルを構築しています。
分類モデル(任天堂タイトル判別)
| モデル | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| ロジスティック回帰(ベース) | 0.9385 | 0.4545 | 0.2564 | 0.3279 |
| +任天堂ハードフラグ | 0.9385 | 0.4615 | 0.3077 | 0.3692 |
2019年と同じく、Accuracy(正解率)は高いがF1値は課題が残る結果になりました。
モデル用データ6,726件中、任天堂タイトルは306件(4.5%)しかなく、クラス不均衡の問題がより顕著です。
「正解率が高い=良いモデル」ではない という、2019年に学んだ教訓がここでも確認できます。
2019年 vs 2026年
| 2019年 | 2026年 | |
|---|---|---|
| ツール | Google Colab(Jupyter Notebook) | Claude Code |
| データ規模 | 約16,000タイトル | 約64,000タイトル |
| 作業時間 | 約1ヶ月(研修5日間 + 自習) | 約10分 |
| コーディング | 全て自分で書いた | 自然言語で指示しただけ |
| 試行錯誤 | 特徴量選択・モデル調整を手動で繰り返し | AIが一発で構成を決めて実行 |
| ライブラリ不足時 | pip installで解決 | アルゴリズムを自前実装して回避 |
| 出力形式 | Notebookのセル出力 | CSS付きのHTMLレポート |
Claude Codeを使ってみて思ったこと
ここがすごい
-
過去のノートブックを読んで意図を汲み取ってくれた。
- 「このノートブックみたいなことをやって」という曖昧な指示で通じた
-
データ前処理〜モデル構築〜レポート生成まで一気通貫。
- これを人間がやったら、それぞれのステップでググったり試行錯誤したりで時間がかかる
-
環境の制約にも柔軟に対応。
- ライブラリがなければ自分で実装するという力技
-
レポートのデザインまで面倒を見てくれた。
- グラフのスタイルやHTMLのCSS含めて、そのまま人に見せられるクオリティ
一方で思ったこと
-
2019年の経験があったから、適切な指示が出せた
- 「回帰モデルで日本の売上を予測」「分類モデルで任天堂タイトルを判別」という発想は、当時自分で手を動かしたから出てきたもの
-
結果の解釈は人間の仕事
- F1値が低い理由がクラス不均衡にあることや、日本市場が独自の傾向を持つことの意味づけは、ドメイン知識がないとできない
-
「何を分析したいのか」を決めるのもまだ人間の仕事
- AIは「やって」と言えばやってくれるが、「何をやるべきか」は自分で考える必要がある
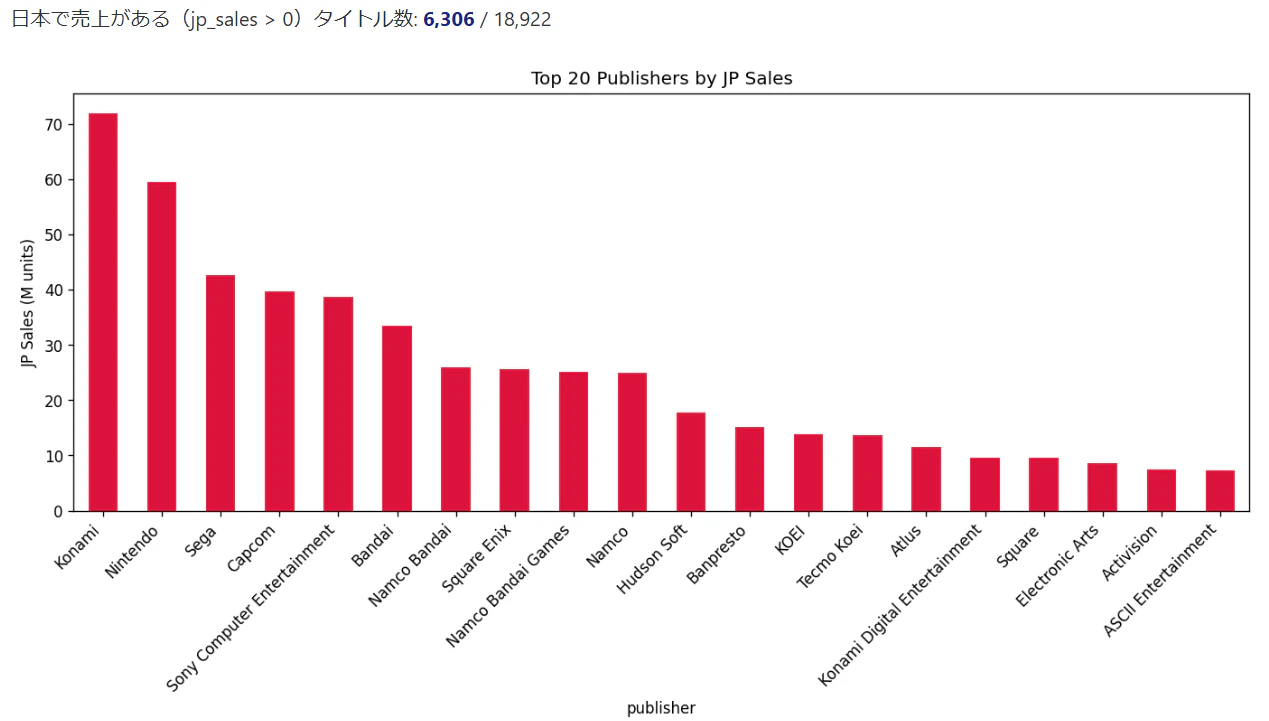
「日本市場でコナミが1位、任天堂が2位」は本当か?
レポートの結果レポートの結果を眺めていて一つ引っかかりました。日本市場の売上ランキングで Konamiが1位(71.97M)、Nintendoが2位(59.39M) となっていたのですが、体感的にはどう考えても任天堂のほうが売れているはずです。ポケモン、マリオ、どうぶつの森、スプラトゥーン...日本で爆発的に売れたタイトルは任天堂が多いし、売上も桁が少ない気がします。
気になったので、これもClaude Codeに原因を調べてもらいました。
結果、データセットの欠損が原因 でした。
- Nintendoの全1,476タイトル中、1,170タイトル(79%)の
jp_salesがNaN(欠損) だった - ポケモン本編(赤緑、金銀、ダイパ、剣盾、SV)→ 全てNaN
- どうぶつの森、Wii Sports、スプラトゥーン、スーパーマリオブラザーズ(初代)→ 全てNaN
- つまり、日本で大ヒットした任天堂の主力タイトルの売上データがごっそり抜けていた
Konamiも同様に多くの欠損がありますが、ウイニングイレブンやダンスダンスレボリューションなど jp_sales が入っているタイトルが相対的に多かったため、合算するとKonami > Nintendoという見かけ上の結果になっていたわけです。
「Konamiが日本市場1位」はデータの欠損によるバイアスであり、事実を反映した結論ではありません。
AIはもっともらしい分析結果を出してくれますが、データ自体に偏りがあるかどうかまでは教えてくれません。人間がファクトチェックしないと、間違いがそのまま通ってしまいます。10分で分析は終わっても、確認作業は省略できない。 これが今回いちばんの学びでした。
さいごに
2019年の記事の「さいごに」で、私はこう書きました。
PythonでNumPy・Pandasなどを使いましたが、もう少し素早く扱えるようになりたいです。
データの加工処理を都度ググりながらやってたので、なかなか効率があがりませんでした。
7年後の答えがこれです。もうググらなくていい。コードも書かなくていい。AIに「やって」と言えばいい。
もちろん、当時手を動かして学んだことは無駄ではありませんでした。基礎があるからこそ、AIへの指示が出せるし、出てきた結果の妥当性を判断できます。
ハルシネーションに気づけるのも、コナミが1位なのはおかしいと思えるのも、2019年に自分で手を動かした経験があるからです。
2019年に「Amazon Machine Learningを使えばGUIポチポチでモデルが作れる、便利!」と感動していた私が、2026年には「自然言語で指示するだけで分析からレポートまで全部出てくる」世界にいます。
ただし、AIが出した結果を鵜呑みにせず、ドメイン知識で検証できる人間の目は、まだしばらく必要そうです。
次の7年後は、何がどうなっているんでしょうね。
余談
なお、この記事の下書きもClaude Codeに作ってもらいました。
下書き自体は数分で出来上がって、微修正して投稿できそうな感じだったのですが、結局ファクトチェックしたり、記事の構成を考え直したり、コナミの謎を追いかけたりしていたら、完成まで数時間かかりました。
速く作れるようになった分、確かめる力のほうが問われる時代なのかもしれません