GraphQLをRailsアプリケーションで使う場合、graphql-rubyという強力なGemがあります。
https://github.com/rmosolgo/graphql-ruby
GraphQLはページネーションを実現するためにconnectionsと呼ばれる仕組みを持っています。
connectionsでは、取得件数や取得を開始する位置を指定することができます。
詳細は公式サイトを参照してください。
https://facebook.github.io/relay/graphql/connections.htm
graphql-rubyを使ってページネーションを実装してみたら、ほぼコードを書くことなく実装できて感動したのでgraphql-rubyが何をしているかコードを覗いてみることにしました。
環境
動かした環境は下記です。
Ruby: 2.6.5
Rails: 6.0.0
graphql-ruby: 1.9.12
Mysql: 5.7.27
実装
Rails自体の実装方法などconnectionsの実装に直接関係ない部分は省略しています。
graphql-rubyインストール
Gemfileに追加してインストールします。詳細はGithubのREADMEなどに記載されています。
gem 'graphql'
bundle install
rails generate graphql:install
上記コマンドを実行すると、graphqlで使用するベースファイルが作成されます。
この時、/graphiqlというエンドポイントも同時に追加されます。
こちらは開発環境での動作確認を簡単に行えるWeb画面を提供してくれます。
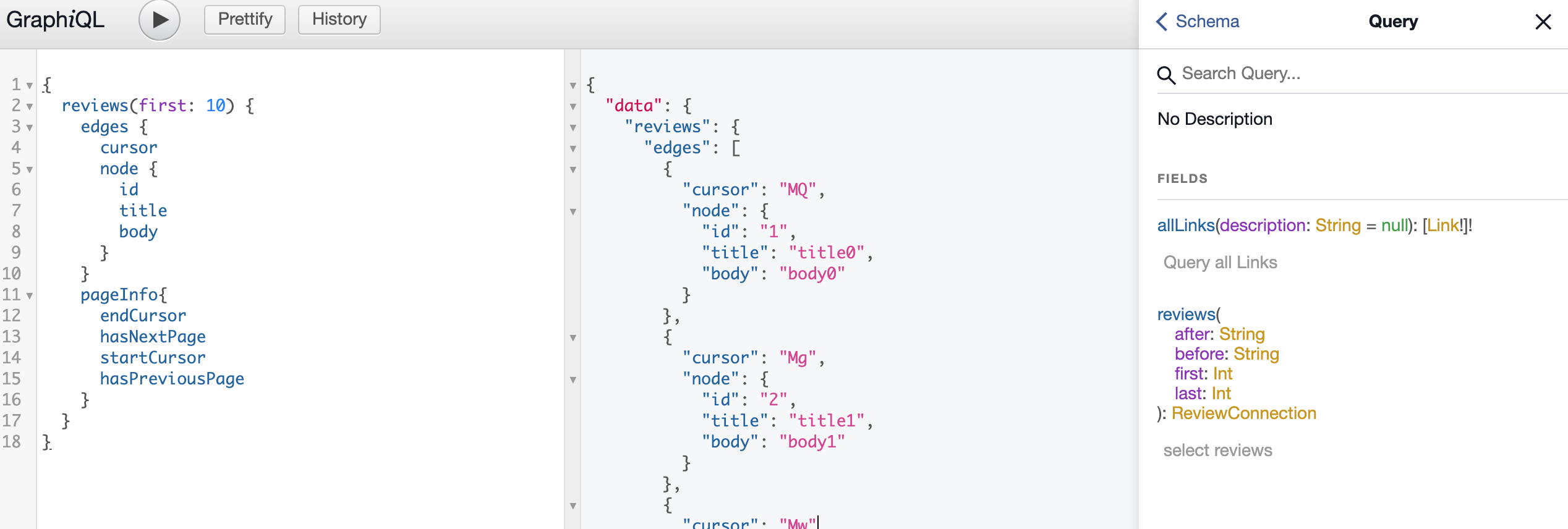
graphiqlを開くと左にクエリーエディター、真ん中はレスポンス、右にスキーマ定義が表示されます。
クエリーエディターにクエリーを書いて▶︎を押せば実行されて、真ん中のフィールドにレスポンスが表示されます。
クエリーエディターは補完機能もあり、右にはスキーマ情報もでているのでかなり便利です!
テーブル作成
title, bodyのカラムを持ったReviewテーブルを使います。
モデルとマイグレーションファイルを生成してテーブルを作ります。
rails g model Review title:string body:text
ページネーションの動作を見たいので、テーブルにはコンソールで適当にデータを作っておきます。
200.times do |i|
Review.create!(title: "title#{i}", body: "body#{i}")
end
GraphQL関連の実装
先ほど作成したreviewsテーブルに対応するreview_typeを作成します。
module Types
class ReviewType < BaseObject
field :id, ID, null: false
field :title, String, null: true
field :body, String, null: true
end
end
続いて、reviewsを取得するquery_typeを作成します。
module Types
class QueryType < Types::BaseObject
field :reviews, Types::ReviewType.connection_type, null: true do
description 'select reviews'
end
def reviews
Review.all.order(id: :desc)
end
end
end
fieldのタイプを指定する箇所にReviewType.connection_typeと書くだけで先ほど定義したReviewTypeを複数返却するconnectionsタイプが指定できます。
データ取得にはfield名と同じ名前のreviewsメソッドに書いた処理が呼ばれます。
ページネーションに必要なlimitなどは自動で付加してくれるのでここではベースとなる取得処理を記載します。
今回は全てのレビューをidの降順で取得する仕様にしました。
これだけで終わりです。え、簡単すぎ!
それでは次の章で動作をみていきましょう。
動作確認
graphiqlを使って動作確認してみます。
まずは先頭の10件を取得してみます。
{
reviews(first: 10) {
edges {
cursor
node {
id
title
body
}
}
pageInfo{
endCursor
hasNextPage
startCursor
hasPreviousPage
}
}
}
reviews(first: 10)はquery_typeを指定しています。firstは先頭から取得する件数です。
reviewsの返却してほしい項目はedges>node配下に指定します。サンプルなのでid, title, body全部指定していますが指定した項目だけ返却してくれます。
ちなみに項目名はキャメルケースで指定する必要があります。rubyで書いているとスネークケースで書いてしまうことがあると思うのでご注意ください。
(サンプルにそういう項目入れればよかった・・・)
cursorとpageInfoはconnectionsで付与される項目です。レスポンスをみながら説明します。
{
"data": {
"reviews": {
"edges": [
{
"cursor": "MQ",
"node": {
"id": "200",
"title": "title199",
"body": "body199"
}
},
# ...(略)
{
"cursor": "MTA",
"node": {
"id": "191",
"title": "title190",
"body": "body190"
}
}
],
"pageInfo": {
"endCursor": "MTA",
"hasNextPage": true,
"startCursor": "MQ",
"hasPreviousPage": false
}
}
}
}
cursorは各項目に付与される一意な値です。次に紹介する2ページ目以降の取得で使います。
pageInfoはその名の通り、現在のページ情報が返却されます。こちらも不要な場合は省略できます。
名前から推測できると思いますが、各項目も簡単に説明します。
endCursor:取得した最後の項目のcursorが設定されます。
hasNextPage:取得したデータより後にデータがあるか?今回はまだデータがあるのでtrueが設定されています。
startCursor:取得した最初の項目のcursorが設定されます。
hasPreviousPage:取得したデータより前にデータがあるか?今回は先頭を取得したのでfalseが設定されています。
次に2ページ目を取得します。
afterに1ページ目の最後のcursorを指定することで指定したcursorの次の項目から取得できます。
{
reviews(first: 10, after: "MTA") {
edges {
cursor
node {
id
title
body
}
}
pageInfo{
endCursor
hasNextPage
startCursor
hasPreviousPage
}
}
}
{
"data": {
"reviews": {
"edges": [
{
"cursor": "MTE",
"node": {
"id": "190",
"title": "title189",
"body": "body189"
}
},
# ...(略)
{
"cursor": "MjA",
"node": {
"id": "181",
"title": "title180",
"body": "body180"
}
}
],
"pageInfo": {
"endCursor": "MjA",
"hasNextPage": true,
"startCursor": "MTE",
"hasPreviousPage": false
}
}
}
}
ほぼ想定通りの結果が返ってきましたが、前のページがあるのにhasPreviousPageがなぜかfalseになっています。予想ですがパラメーターでfirst+afterを指定しているときは前ページがあることは明白なので機能していない可能性が高そうです。
気になるので次の章でソースを見てみましょう。
ソースを読む
ReviewType.connection_type
ReviewType.connection_typeと書くだけでReviewTypeのconnection_typeが使えるようになる処理をみてみます。
connection_typeメソッドからソースを辿ってみました。
def connection_type
@connection_type ||= define_connection
end
def define_connection(**kwargs, &block)
GraphQL::Relay::ConnectionType.create_type(self, **kwargs, &block)
end
↓
def self.create_type(wrapped_type, edge_type: nil, edge_class: GraphQL::Relay::Edge, nodes_field: ConnectionType.default_nodes_field, &block)
custom_edge_class = edge_class
# Any call that would trigger `wrapped_type.ensure_defined`
# must be inside this lazy block, otherwise we get weird
# cyclical dependency errors :S
ObjectType.define do
type_name = wrapped_type.is_a?(GraphQL::BaseType) ? wrapped_type.name : wrapped_type.graphql_name
edge_type ||= wrapped_type.edge_type
name("#{type_name}Connection")
description("The connection type for #{type_name}.")
field :edges, types[edge_type], "A list of edges.", edge_class: custom_edge_class, property: :edge_nodes
if nodes_field
field :nodes, types[wrapped_type], "A list of nodes.", property: :edge_nodes
end
field :pageInfo, !PageInfo, "Information to aid in pagination.", property: :page_info
relay_node_type(wrapped_type)
block && instance_eval(&block)
end
end
ObjectType.defineでedges, nodes, pageInfoのフィールドを持ったconnection_typeを定義しているようです。
本来であれば同等のfieldを定義しなければいけないところをReviewType.connection_typeの1行で使えるようにしてくれているこの実装ステキです。
cursor
cursorには一意の文字列が入っていますが、どのように生成しているのでしょうか?
corsorを返却しているメソッドからソースを辿ってみました。
def cursor
@cursor ||= connection.cursor_from_node(node)
end
↓
def cursor_from_node(item)
item_index = paged_nodes.index(item)
if item_index.nil?
raise("Can't generate cursor, item not found in connection: #{item}")
else
offset = item_index + 1 + ((paged_nodes_offset || 0) - (relation_offset(sliced_nodes) || 0))
if after
offset += offset_from_cursor(after)
elsif before
offset += offset_from_cursor(before) - 1 - sliced_nodes_count
end
encode(offset.to_s)
end
end
↓
def encode(data)
@encoder.encode(data, nonce: true)
end
↓
def self.encode(unencoded_text, nonce: false)
Base64Bp.urlsafe_encode64(unencoded_text, padding: false)
end
↓
def urlsafe_encode64(bin, padding:)
str = strict_encode64(bin).tr("+/", "-_")
str = str.delete("=") unless padding
str
end
cursor_from_nodeメソッドで当該ノードのoffsetを計算してbase64でエンコードしているようです。
一意の文字列をどうやって作っているのだろうと思ったら先頭からの連番を文字列に変換しているだけだったんですね。
ちなみに実装をみる限りcursor生成ロジックは簡単に差し替えることができそうなのでbase64が気に入らない場合はカスタマイズできそうです。
取得処理
取得処理は下記のように書きました。
def reviews
Review.all.order(id: :desc)
end
これだけしか書いていないのですが、例えば2ページ目の10件を取得すると下記のようにlimitやoffsetが付加されたSQLと巨大な数値がlimitに設定されたSQLが発行されます。
SELECT `reviews`.* FROM `reviews` ORDER BY `reviews`.`id` DESC LIMIT 10 OFFSET 10
SELECT COUNT(*) FROM (SELECT 1 AS one FROM `reviews` LIMIT 18446744073709551615 OFFSET 10) subquery_for_count
このクエリーはどのように発行されているのかソースを辿ってみました。
発行処理にたどり着くまでの道のりが複雑で書ききれないのでピンポイントで当該箇所のみ載せています。
まずは1つ目のSQLです。
def paged_nodes
return @paged_nodes if defined? @paged_nodes
items = sliced_nodes
if first
if relation_limit(items).nil? || relation_limit(items) > first
items = items.limit(first)
end
end
if last
if relation_limit(items)
if last <= relation_limit(items)
offset = (relation_offset(items) || 0) + (relation_limit(items) - last)
items = items.offset(offset).limit(last)
end
else
slice_count = relation_count(items)
offset = (relation_offset(items) || 0) + slice_count - [last, slice_count].min
items = items.offset(offset).limit(last)
end
end
if max_page_size && !first && !last
if relation_limit(items).nil? || relation_limit(items) > max_page_size
items = items.limit(max_page_size)
end
end
# Store this here so we can convert the relation to an Array
# (this avoids an extra DB call on Sequel)
@paged_nodes_offset = relation_offset(items)
@paged_nodes = items.to_a
end
def sliced_nodes
return @sliced_nodes if defined? @sliced_nodes
@sliced_nodes = nodes
if after
offset = (relation_offset(@sliced_nodes) || 0) + offset_from_cursor(after)
@sliced_nodes = @sliced_nodes.offset(offset)
end
if before && after
if offset_from_cursor(after) < offset_from_cursor(before)
@sliced_nodes = limit_nodes(@sliced_nodes, offset_from_cursor(before) - offset_from_cursor(after) - 1)
else
@sliced_nodes = limit_nodes(@sliced_nodes, 0)
end
elsif before
@sliced_nodes = limit_nodes(@sliced_nodes, offset_from_cursor(before) - 1)
end
@sliced_nodes
end
connection_typeのパラメータfirst, last, after, beforeの有無を判定してlimitやoffsetをつけていることがわかります。
パラメータはfirst+after(afterの位置からxx件)かlast+before(beforeの位置より前のxx件)の組み合わせで使うことが想定されますが、処理をみる限りではfirstとlastなど相反するパラメーターが共存していることも考慮して実装されているように見えます。
ただ実装されているからといって相反するパラメータを同時に指定すると理解しづらい挙動になるので使わない方がよいと思います。
例えばfirst: 5, after: "MTA"と指定した時に下記を返却する場合に追加でlast: 3やlast: 10を指定したときの挙動は下記の通りです。
# first: 5, after: "MTA"
[{ id: 11, }, { id: 12, }, { id: 13, }, { id: 14, }, { id: 15, }]
# first: 5, after: "MTA", last: 3
# first > lastの場合、5件取得したものの後ろ3個が取得される。
[{ id: 13, }, { id: 14, }, { id: 15, }]
# first: 5, after: "MTA", last: 10
# first <= lastの場合、結果は変わらない。
[{ id: 11, }, { id: 12, }, { id: 13, }, { id: 14, }, { id: 15, }]
続いて2つ目のSQLです。
def relation_count(relation)
count_or_hash = if(defined?(ActiveRecord::Relation) && relation.is_a?(ActiveRecord::Relation))
relation.respond_to?(:unscope)? relation.unscope(:order).count(:all) : relation.count(:all)
else # eg, Sequel::Dataset, don't mess up others
relation.count
end
count_or_hash.is_a?(Integer) ? count_or_hash : count_or_hash.length
end
取得するクエリーに対して.count(:all)してカウントを取得してoffsetの計算に使っているようです。
巨大なLIMITが気になりますが、offsetだけ指定されたクエリーをcountするとRailsが勝手に付加するみたいです。やりたいことはoffset以降のレコード数のカウントっぽいですね。
コンソールでも挙動を確認してみました↓
irb(main):018:0> Review.all.order(:id).offset(10).count(:all)
(1.7ms) SELECT COUNT(*) FROM (SELECT 1 AS one FROM `reviews` ORDER BY `reviews`.`id` ASC LIMIT 18446744073709551615 OFFSET 10) subquery_for_count
=> 190
pageinfo
pageinfoの項目の計算方法をみてみます。
"pageInfo": {
"endCursor": "MjA",
"hasNextPage": true,
"startCursor": "MTE",
"hasPreviousPage": false
}
endCursor
# Used by `pageInfo`
def end_cursor
if end_node = (respond_to?(:paged_nodes_array, true) ? paged_nodes_array : paged_nodes).last
return cursor_from_node(end_node)
else
return nil
end
end
これはわかりやすいですね。ページ内最終ノードのcursorを返却しているだけです。
hasNextPage
def has_next_page
if first
if defined?(ActiveRecord::Relation) && nodes.is_a?(ActiveRecord::Relation)
initial_offset = after ? offset_from_cursor(after) : 0
return paged_nodes.length >= first && nodes.offset(first + initial_offset).exists?
end
return paged_nodes.length >= first && sliced_nodes_count > first
end
if GraphQL::Relay::ConnectionType.bidirectional_pagination && last
return sliced_nodes_count >= last
end
false
end
firstが指定されている場合は、今のページの次の項目があるか判定して結果を返却しているようです。
lastが指定されている場合の分岐もありますが、GraphQL::Relay::ConnectionType.bidirectional_paginationはデフォルトfalseのようなのでデフォルトだとこの分岐には入りません。ちなみにbidirectional_paginationは直訳すると双方向ページネーションですね。どういう使い方をするのか気になりますが本題からずれるので今回は無視することにします。
それ以外の場合は次ページがあるかどうか確認せずに一律falseを返すようです。firstを指定している時以外は使わないようにしましょう。
startCursor
# Used by `pageInfo`
def start_cursor
if start_node = (respond_to?(:paged_nodes_array, true) ? paged_nodes_array : paged_nodes).first
return cursor_from_node(start_node)
else
return nil
end
end
これもわかりやすいですね。ページ内先頭ノードのcursorを返却しているだけです。
hasPreviousPage
def has_previous_page
if last
paged_nodes.length >= last && sliced_nodes_count > last
elsif GraphQL::Relay::ConnectionType.bidirectional_pagination && after
# We've already paginated through the collection a bit,
# there are nodes behind us
offset_from_cursor(after) > 0
else
false
end
end
lastが指定されている場合は、offsetをみて前のページがあるか判定して結果を返却しているようです。
それ以外の時はfalseを返却しているのでlastを指定している時以外は使わないようにしましょう。
ちなみに賛否両論ありそうですが、意味がない場合はfalseではなくてnilにして欲しいと個人的には思ったりします。
おまけ
graphiqlで異常なクエリーを実行してしまうと、画面がリロードしても表示されなくなることがあります。
直前で実行したクエリーをlocalStorageに保存しているようで、画面表示時にそこのクエリーを読み込む時にjsエラーになってしまうようです。
このエラーの時、ChromeのコンソールにはError: Mode graphql failed to advance stream.と表示されていました。
こうなってしまった場合は下記コマンドでlocalStorageをクリアすると直ります。
localStorage.clear(); localStorage.setItem = () => {}