背景
音声をクライアントからサーバーにストリーミングするという案件があり、調査をしていました。
ストリーミングの方法として websocket と grpc を候補にしており今回は、処理のレイテンシでそれぞれを比較してみたのでそのメモです。
実験
手順
- クライアントから疑似音声を送る
- 100msごとに長さ3200のバイト配列を送る
- 実際の中身にはそれが生成されたタイムスタンプが含まれている
- サーバーは送られたバイト配列を文字にしてただ返す
- クライアントで返ってきたデータのタイムスタンプを見て往復に何秒かかったか見る
環境
- クライアント:会社の Macbook Pro
- 数は一台
- サーバー:AWS@TokyoRegion
結果
まず GRPC / WebSocket それぞれ30秒計測しました。(GRPC / WebSocket)
結果 WebSocket のみ一部の時間で妙に時間がかかっていたのでその後それぞれ60秒取り直しました。 (GRPC2 / WebSocket2)
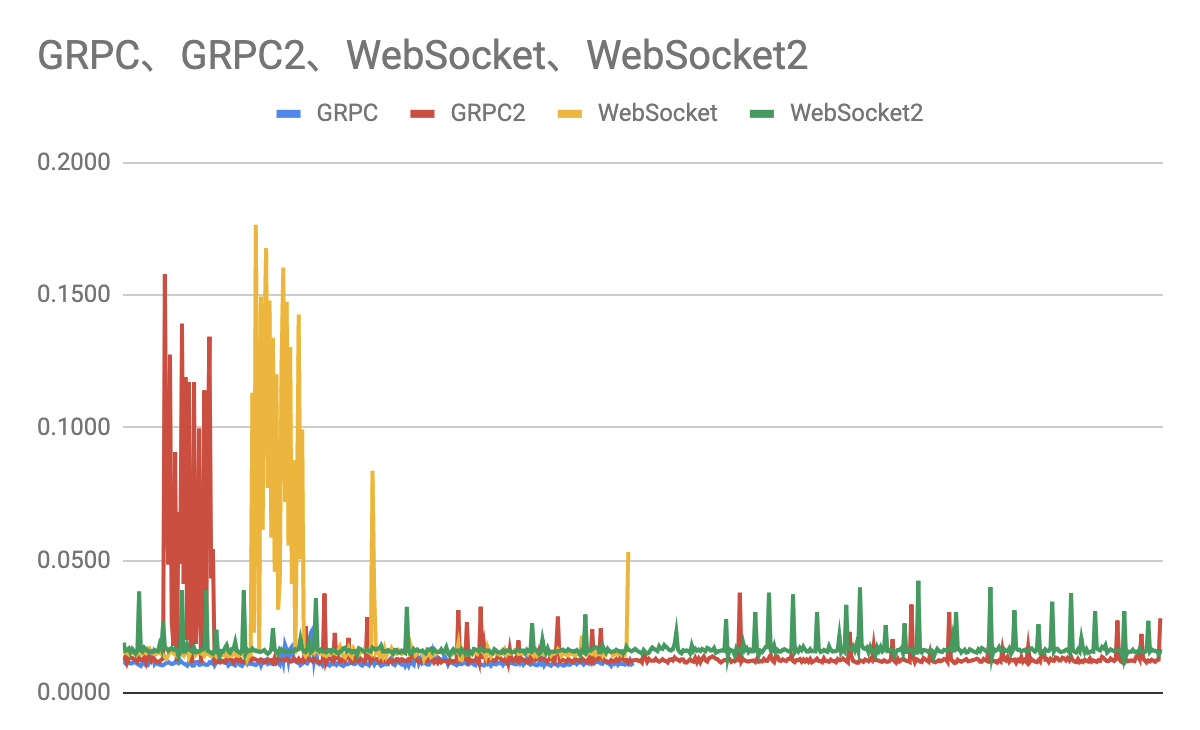
GRPC / WebSocket それぞれ遅くなっていた時間を切り取ってグラフ化すると下記のようになります。
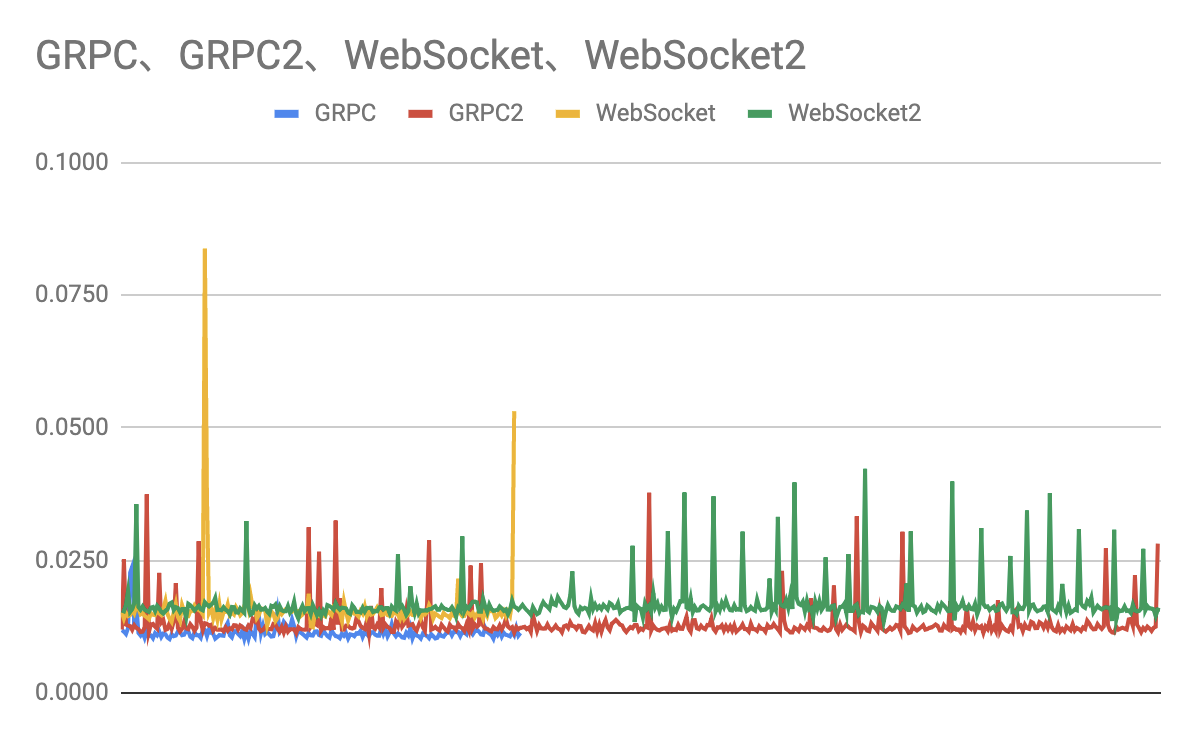
この状態での平均が
- GRPC: 0.012sec
- WebSocket: 0.016sec
程度なようです。
あまり大きなデータで実験していなかったり、複数のコネクションを張ったときにどうなるかの実験はできていないのですが、この実験設定の場合は全体に GRPC のほうが多少早く、またレイテンシの振れ幅もこころなしか GRPC のほうが安定しているように見えます。
実験に使ったコード
(を適宜公開できるよう削ったもの)
MicrophoneStream は Google Speech to Text のコード相当のものです。
といっても0.1秒に1回処理が回ってくるだけでいいので time.sleep(0.1) をループの中に入れるだけでも良いかもしれません。
GRPC
client
import os
import time
import grpc
from myproject.grpc import voice_rpc_pb2, voice_rpc_pb2_grpc
HOST = 'XXXXXX'
PORT = 50051
class VoiceClient:
def data_generator(self):
sample_rate = 16000
chunk = int(sample_rate / 10) # 100ms
with MicrophoneStream(sample_rate, chunk) as stream:
for wave in stream.generator():
wave = str(time.time())
wave = wave + '|' + '-' * (3200 - len(wave) - 1)
wave = wave.encode('utf-8')
yield voice_rpc_pb2.SendVoiceRequest(wave=wave)
def run(self):
with grpc.insecure_channel('{}:{}'.format(HOST, PORT)) as channel:
stub = voice_rpc_pb2_grpc.VoiceRPCStub(channel)
response_iter = stub.SendVoice(self.data_generator())
for response in response_iter:
send_time = float(response.text.split('|')[0])
print(time.time() - send_time)
if __name__ == '__main__':
VoiceClient().run()
import time
import grpc
from concurrent import futures
from myproject.grpc import voice_rpc_pb2, voice_rpc_pb2_grpc
_ONE_DAY_IN_SECONDS = 60 * 60 * 24
class VoiceRPC(voice_rpc_pb2_grpc.VoiceRPCServicer):
def SendVoice(self, request_iterator, context):
for request in request_iterator:
wave = request.wave
yield voice_rpc_pb2.SendVoiceResponse(
text=wave.decode('utf-8'),
)
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
voice_rpc_pb2_grpc.add_VoiceRPCServicer_to_server(VoiceRPC(), server)
server.add_insecure_port('[::]:50051')
server.start()
try:
while True:
time.sleep(_ONE_DAY_IN_SECONDS)
except KeyboardInterrupt:
server.stop(0)
if __name__ == '__main__':
serve()
WebSocket
client
import websocket
import time
from multiprocessing import Process
URL = 'ws://XXXXX:12345/voice'
class VoiceClient:
def run(self):
self.ws = websocket.WebSocketApp(
URL,
on_open=self.on_open,
on_message=self.on_message,
)
try:
self.ws.run_forever()
except KeyboardInterrupt:
self.ws.close()
def listen_voice(self):
sample_rate = 16000
chunk = int(sample_rate / 10) # 100ms
with MicrophoneStream(sample_rate, chunk) as stream:
for voice_data in stream.generator():
wave = str(time.time())
wave = wave + '|' + '-' * (3200 - len(wave) - 1)
wave = wave.encode('utf-8')
self.ws.send(wave, opcode=websocket.ABNF.OPCODE_BINARY)
def on_open(self):
self.listen_process = Process(target=self.listen_voice)
self.listen_process.start()
def on_message(self, message):
send_time = float(message.split('|')[0])
print(time.time() - send_time)
if __name__ == '__main__':
VoiceClient().run()
server
from flask import Flask
from flask_sockets import Sockets
from gevent import pywsgi
from geventwebsocket.handler import WebSocketHandler
if __name__ == '__main__':
app = Flask(__name__)
sockets = Sockets(app)
@sockets.route('/voice')
def voice(ws):
while not ws.closed:
wave = ws.receive()
ws.send(wave.decode('utf-8'))
if __name__ == '__main__':
wsgiserver = pywsgi.WSGIServer(('0.0.0.0', 12345), app, handler_class=WebSocketHandler)
wsgiserver.serve_forever()