ヴィルト先生のエッセイを翻訳しました。
鏡の国の「グッド・アイデア」
原文 Niklaus Wirth Good Ideas, Through the Looking Glass 2005年
要旨
我々はここに、過去数十年の計算機科学・技術から、さまざまなアイデアを拾い集めた。それらは昔は広く知られていたが、今日では色あせている。なぜだろうか。ほとんど忘れ去られたものもある。しかし、過去から学ぶためだけではなく、進歩のため、知的刺激や楽しみのためにも、そうしたアイデアを思い出すことには意義があると我々は信じる。
内容
- はじめに
- ハードウェア技術
- 計算機アーキテクチャ
- 数の表現
- データアドレッシング
- 式スタック
- 可変長データ
- リターンアドレスをコードに格納する
- 仮想アドレス
- メモリ保護とユーザクラス
- 複雑な命令セット
- レジスタ・ウィンドウ
- プログラミング言語機能
- 表記法と構文
- GO TO文
- switch
- Algolの文による複雑さ
- Algolの関数内のstatic変数
- Algolの名前渡し
- Algolの不完全な引数型指定
- 抜け穴
- その他のテクニック
- 構文解析
- 拡張可能な言語
- 入れ子になった手続きとDijkstra's display
- 木構造のシンボルテーブル
- 間違ったツールの使用
- ウィザード
- プログラミングパラダイム
- 関数型プログラミング
- 論理プログラミング
- オブジェクト指向プログラミング
- おわりに
1. はじめに
多くの優れた独創的なアイデアが計算機の歴史を推し進めてきた。登場時に素晴らしいと思われたアイデアがその輝きを失った、という事例は少なくない。多くの場合、技術によくあることだが、技術的環境の変化がそうした凋落を引き起こした。商業的な理由があることも多い。また単に、後から考えると、あるいはよく調べてみたところ、最初に思ったほど優れていなかった場合もある。流行に乗れずに忘れ去られた古いアイデア(おそらく時代を先取りしすぎたのだろう)が再来することもある。そして時には、すでに悪いとわかっているアイデアが再発明されることもある。
私がそういう グッド・アイデア (と最初は思われていたもの)を集めるようになったのは、チャールズ・タッカーとのある会話がきっかけだった。 廃れるアイデア ――時間とともに劣化していくアイデア。また私は、クヌースの「The Dangers of Computer-Science Theory」を再発見した。タッカーの講演は中国の壁の内側で、クヌースの講演は1970年に鉄のカーテンの向こうのルーマニアで行われたが、どちらも「西側批判」に損害を与えることのない安全な場所だった。特にクヌースの皮肉たっぷりな態度から勇気をもらい、このコレクションを発表するに至った。なお、このコレクションに遺漏がないとは言わない。
このコレクションは、計算機技術上の失敗したコンセプトに始まり、計算機アーキテクチャ上の胡乱なアイデアへと続く。時代背景からして十分に正当化できるが現在では廃れた、というものも含む。次いでプログラミング言語の領域、特に初期の提案を取り上げる。最後に、プログラミングパラダイムからソフトウェア(コンパイラ)技術の話題に触れる。
2. ハードウェア技術
今も昔も一般に、計算機エンジニアは、速度に注目する。そのために既存の技術をさらに高度にするか、あるいは別の方法を探す。そうした試みのうち、失敗した事例のいくつかを、ここに集めた。
磁気コアメモリの時代、 磁気バブルメモリ というアイデアが現れて、大きな期待を集めた。それは、機械的に回転する装置(故障と低信頼性の元凶)をすべて置き換えることになっていた。磁気バブルはフェライト素材の磁場の中をやはり回転するのだが、機械的に動く部品はなかった。ディスク同様、シリアル(訳注:シーケンシャル?)デバイスだった。しかし磁気バブルメモリは結局、十分な記憶容量を達成することがなかった。ディスク技術は容量だけでなく速度でも磁気バブルメモリより優位だった。数年間の研究ののち、このアイデアは静かに葬られた。
数十年前に大きな期待を集めていた新技術といえば、 超伝導 である。特にHPCでの利用が想定されていた。超高速で動作するはずだったが、大規模な計算機部品を絶対零度に近い温度で運用することは無茶だった。PCがあなたの机に登場すると、超伝導の夢は蒸発・凍結した。
トランジスタのかわりに トンネルダイオード を使う、というアイデアもあった。トンネルダイオード特有の負性抵抗という性質を利用すると、2つの安定状態を作れる。トンネルダイオードはゲルマニウム素子であり、シリコン素子にはそういうものはない。ゲルマニウム素子は動作温度範囲が比較的狭い。シリコントランジスタが速く安くなるにつれて、研究者たちはトンネルダイオードのことを忘れていった。
GaAsトランジスタは、シリコントランジスタとは違って、速く安くなることはなかった。シリコン酸化物は理想的な絶縁体であるため、シリコントランジスタは製造工程を簡単にできた。GaAsのような他の素材は今日、計算機で使われることは稀で、超高周波通信の領域で使われている。
かつては支配的だったバイポーラトランジスタも、今は滅びようとしている。電界効果トランジスタは極度に薄い酸化物層で作れるので、バイポーラトランジスタよりもさらに速く、小さく、安くなっている。しかしこの結末は、バイポーラトランジスタが悪いアイデアだったということを意味しない。
3. 計算機アーキテクチャ
i. 数の表現
「グッド・アイデア」を探そうと思ったら、計算機アーキテクチャの領域がお勧めだ。数の表現(特に整数)は、かつては大問題だった。焦点は底の選択にある。初期の計算機は、Konrad Zuseのもの以外すべて、学校で習うような10進法を採用していた。
しかし2進法のほうが経済的なのは明らかだ。整数 $n$ を表現するには、10進法では $log_{10}(n)$ 桁の10進数、2進法では $log_2(n)$ 桁の2進数を要する。10進数は1個4ビットを要するので、2進表現に比べて10進表現は約20%多く記憶容量を使うのだから、2進法は明らかに優れている。それでも、10進表現は長くその地位を保ち、今でもライブラリモジュールとして留まっている。
「すべての計算は正確でなければならない」という信念に凝り固まった人がいたのがその原因だ。しかし、誤差というものは、(たとえば除算後の)丸めが引き起こす。丸めの影響は数の表現によって異なることがあるので、2進計算機は10進計算機とは異なる結果を返すことがある。金融取引――まさに精度が問われる分野だ――では長らく人力で10進計算が行われてきたので、計算機もすべてのケースで同じ結果(すなわち、同じ誤差)を出すべきだと思われた。
一般的に2進法のほうがより正確な結果を返すのだが、10進法の結果は簡単に人力でチェックできることから、金融アプリケーションでは10進法が選ばれ続けた。これはよくわかる話だが、まったくの保守的なアイデアである。IBM System/360(2進法と10進法の両方が使える)が登場するまで、大手計算機メーカーは2つの製品ラインを持っていた。科学技術計算用の2進法計算機と、商用計算用の10進法計算機である。ムダな習慣だ!
初期の計算機では、整数は、絶対値と符号ビットで表現されていた。シーケンシャルに1桁ずつ加算する機械では、符号ビットは最初に読み込むために最下位に置いてあった。(リップルキャリー加算器のような)並列処理ができるようになると、紙で計算するときのアナロジーにより、符号ビットは最上位に置かれた。しかしこの符号―絶対値表現は悪いアイデアだった。正の値と負の値で、違う回路が必要になってしまうからだ。「負の整数をその補数で表現する」というアイデアは実に優れている。こうすると、加算と減算を同じ回路でこなせる。ある設計者は1の補数( $n$ の全ビットを単純に反転させて $-n$ を表す)を採用し、別のある設計者は2の補数( $n$ の全ビットを反転させてから1を加えて $-n$ を表す)を採用した。前者には、0の表現が2つ(0...0と1...1)あるという欠点があった。適切な比較命令が使えない場合、これは特に面倒なことになった。たとえばCDC 6000計算機には、0かどうかを判定する命令があって、これは両方の表現を正しく認識したのだが、符号ビットだけを判定する命令は1...1を負と判定したので、比較という作業が面倒なものになっていた。これは、1の補数が悪いアイデアであることを示した、まずい設計だった。現在では、すべての計算機が2の補数で演算している。
| 10進法 | 2の補数 | 1の補数 |
|---|---|---|
| 2 | 010 | 010 |
| 1 | 001 | 001 |
| 0 | 000 | 000 or 111 |
| -1 | 111 | 110 |
| -2 | 110 | 101 |
小数点以下の部分を含む数は、固定小数点または浮動小数点で表現される。今日のハードウェアはたいてい浮動小数点演算を備えている。浮動小数点数は、指数部 $e$ と仮数部 $m$ という2つの整数によって、数 $x$ を $x=(B^e)*m$ として表現する。ある時期、指数の底 $B$ を何にすべきかについて議論がされた。慣習では $B=2$ だったが、バローズB5000は $B=8$ 、IBM 360は $B=16$ を採用した(どちらも1964年)。その狙いは、指数部の容量を節約することだったが、それだけではない。仮数部のシフト幅を3(または4)ビットにすることで、正規化を速くするという狙いもあった。しかし、これは悪いアイデアだったと判明した。丸めの影響がひどくなったのだ。その結果IBM 360では、小さな正の数 $ε$ に対して、$(x+ ε)×(y+ ε) < (x × y)$ になる数 $x$ と $y$ が存在した。乗算が単調ではない! そのような乗算は信頼できず、潜在的に危険でもあった。
ii. データアドレッシング
初期の計算機の命令は、単なるオペコードと絶対アドレス(またはリテラル値)で構成されていた。そのため、プログラムの自己書き換えをやらないわけにはいかなかった。たとえば、連続したメモリセル内の数をループで加算しようとすると、加算命令のアドレスに対してループ1回ごとに1を加えなければならない。実行時のプログラム書き換えは、ノイマン型計算機(プログラムとデータを同じメモリ内に格納すること)という深遠なアイデアの帰結のひとつとして歓迎されていたのだが、危険な技法であり無限の落とし穴製造機であることがすぐに判明した。実行によってプログラム自体が変化すると、そのエラーを探す作業は悪夢となる。プログラムの自己書き換えは極端に悪いアイデアであると認められた。
解決策は、新しいアドレッシングモードの導入だった。命令(の一部)がアドレスを指すのではなく、アドレスを変数の一種として扱えば、自己書き換えの必要はなくなる。この解決策はいわゆる 間接アドレッシング であり、変数としてメモリ上に格納されているアドレス値だけを書き換える。これは自己書き換えの危険性を取り除き、ほとんどの計算機の一般的な機能として1970年代半ばまで残っていたが、後から考えると、これは胡乱なアイデアだった。結局、これはデータアクセスのたびに2回のメモリアクセスを要するので、計算が無視できないほど遅くなった。
多段間接アドレッシング という 「賢い」アイデアが、事態をさらに悪くした。CPUがメモリ上のデータを読み込んだときに、「このデータは目的のデータなのか、それともアドレスなのか」を示すビットを見て、もし後者であれば再帰的にそのアドレスを読み込む(読み込んでみたら、それはまたしてもアドレスかもしれない)。そうした機械(例:HP 2116)は、間接アドレッシングのループで簡単にフリーズした。
解決策は インデックスレジスタ にある。命令内のアドレス(即値)と、インデックスレジスタの値を加算する。これはCPUにいくつかのインデックスレジスタ(加算器も)を加えることで実現できる。IBM 360はこれらを単一のレジスタバンクに付け加えた。これは現在の慣習となっている。
CDC 6000は奇妙な方式を採用していた:60ビットでデータを格納するレジスタX、18ビットでアドレスを格納するレジスタA、18ビットのインデックスレジスタB。命令が直接使うのは、これら3つのレジスタだけである。レジスタAを参照するたびに、AとBが加算されたアドレスへのメモリアクセスが発生する。おかしいのは、レジスタA0-A5の参照はメモリからレジスタX0-X5へのロードを意味していたのに対して、A6とA7の参照はX6とX7からメモリへのストアを意味していたことだった。この方式が大問題を引き起こすことはなかったが、後から考えると、「平凡なアイデア」に分類してもいいだろう。レジスタ番号が動作(データ転送の方向)を決めるのだから。この件は別にすると、主に単純さにおいて、CDC 6000にはいくつもの優れたアイデアが実現されていた。CDC 6000は1962年にシーモア・クレイによって設計されたものであり、RISCという用語が現れたのは1980年ごろだが、これこそが世界初のRISCマシンと言われていい。
バローズ B-5000は、きわめて手のこんだアドレッシング方式を採用していた。それはディスクリプタ方式といって、配列を示すものだ。 データティスクリプタ なるものは本質的には間接アドレッシングだが、それに加えてアクセス時にインデックス境界を検査する。自動インデックス検査は、優れた、先見性のある機能だが、ディスクリプタ方式は胡乱なアイデアだった。というのも、多次元配列を表現しようとすると、行(または列)ごとにディスクリプタの配列のディスクリプタが必要となる。 n 次元配列の要素にアクセスするたびに、 n 回の間接参照が発生する。間接参照による速度低下だけでなく、ディスクリプタのために余計な行が必要となる。にもかかわらず、このまずいアイデアを、1995年にはJavaの、2000年にはC#の設計者が採用した。
iii. 式スタック
Algol 60は、その後のプログラミング言語の発展に深遠な影響を与えただけでなく、はるかに限定的なものではあるが、計算機アーキテクチャにも影響を与えた。コンパイラと計算機は不可分の複合体なのだから、驚くほどのことではない。
これについてはまず、式の評価がある。Algolでは部分式がカッコで囲まれ、演算子がそれぞれの結合強度(訳注:優先順位?)を持つので、その複雑さは任意である。部分式の結果は一時的に保存する必要がある。例として、この式を見てみる:
$$ (a/b) + ((c+d)*(c-d)) $$
これは次のように、各段階で一時的な結果 t1...t4 を生成しながら評価される:
t1 := a/b; t2 := c+d; t3 := c-d; t4 := t2*t3; x := t1 + t4
F. L. BauerとE.W.Dijkstraは独立に、任意の式を評価する方法を提案した。優先順位とカッコに従いつつ左から右へと評価すると、最後に保存された要素が常に最初に必要とされることを二人は指摘した。そのため、一時的な結果はプッシュダウンリスト(スタック)に置くと都合がいい:
t1 := a/b; t2 := c+d; t3 := c-d; t2 := t2*t3; x := t1 + t2
この単純な戦略をレジスタバンクで実装する(トップレジスタのインデックスを保持し、暗黙で増減するカウンタも加える)というアイデアには、なにも意外なことはない。そのようなスタックを使えば、メモリアクセスの回数を減らし、命令が明示的にレジスタを指定することも避けられる。つまり、スタックマシンは素晴らしいアイデアに見えた。この方法は、English Electric KDF-9とバローズB-5000に採用された。それによって当然、ハードウェアの複雑さも増大した。
スタックはどれくらい深くすべきなのか? 結局、レジスタは高価なリソースである。B-5000は2つのレジスタだけを使い、それより多くの中間結果がプッシュされたときは自動的にメモリに保存することを選んだ。これはうまくいきそうに見えた。クヌースが多くのFortranプログラムを解析して指摘したように、ほとんどの式は、1つまたは2つのレジスタしか使わない。それでも、特に1960年代半ばにレジスタバンクが登場した後には、このアイデアはどちらかというと胡乱なものであることが確かめられた。新しい時代においては、コンパイルの単純さは実行速度のために犠牲にされるようになった。スタック機構は、貴重なリソースと特定の戦略を結びつけてしまい、柔軟性がない。それに対して、手のこんだコンパイラのアルゴリズムは、個々の命令がそれぞれ別のレジスタを指定できる柔軟性を生かして、より経済的にレジスタを使えることが確かめられた。
iv. 可変長データ
EDP(electronic data processing)市場向けの計算機にはたいてい10進演算の機能があったが、可変長データも提供していた。それらのアプリケーションにおいて、文書(文字列)と数(10進数字)は主なデータだった。IBM 1401は文字列処理を強く指向しており、その製造台数はとても多かった。IBM 1401のワード長は8ビットではなく――当時は1文字を6ビットで表現するのが一般的だった――9ビットだった(byteという単語が知られるようになったのは1964年)。ワード内の1ビットは、文字列か数の終わりを示すもので、 ストップビット と呼ばれていた。移動・加算・変換命令は1ワードずつシーケンシャルに行われ、ストップビットが来ると終わった。
可変長データを扱うこの方法は、猛烈に悪いアイデアに見える。結局、ストップビットのために約11%の記憶容量が ムダ になる。後の計算機はハードウェア支援なしにソフトウェアだけで問題を解決している。たいてい、文字列の終端を示すためにゼロを置くか、先頭に長さを置く。これも記憶容量を使うのだが、文字列にだけ使うので、メモリ内のすべてのワードで使うわけではない。
v. リターンアドレスをコードに格納する
サブルーチンへのジャンプ命令はD. Wheelerが発明したものだが、プログラムカウンタはどこかに保管しておき、サブルーチンが終了したときに取り出せるようにしておかなければならない。問題は、「どこかに保管するって、どこに?」だ。ミニコンや、メインフレームでもCDC 6000では、場所 d へのジャンプ命令はリターンアドレスを d に保管し、場所 d+1 から実行する:
mem[d] := PC+1; PC := d+1
これは少なくとも2つの理由から、まったくの悪いアイデアだった。第一に、これではサブルーチンは再帰的に呼び出せない。すでに呼び出されているサブルーチンを再び呼び出すと、元のリターンアドレスが上書きされるからだ。再帰はAlgolで導入されたが、この単純な方法が使えなくなるため、大きな論争となった。よってリターンアドレスは、ハードウェアが指示する特定の場所からフェッチして、手続きの実体(手続きは実行時に呼び出されるたびに実体化するというアイデア)それぞれに対応する場所に保管しなければならない。この オーバーヘッド は多くの計算機設計者とユーザにとって受け入れがたいものに思えたため、再帰を望ましくない、不要の、禁止されるものだと述べるに至った。彼らは、まずい呼び出し命令が問題を起こすとは知りたくなかった。
これが悪いアイデアである理由の第二は、マルチプロセッシングができないことだ。並行動作するプロセスがそれぞれコードのコピーを持たなければならない。これは、コードとデータを混ぜるという誤りの単純な結果だ。プログラムカウンタを保管した後&プログラムカウンタが d+1 になる前に割り込みが発生したらどうなるか、という疑問もあるが、それは置いておこう。
1990年代のRISCアーキテクチャなど、のちに登場したハードウェア設計は、リターンアドレスを保管するための専用のレジスタ(MIPSの$raなど)で手続きの再帰に対応している。この話題については後でまた触れる。最善のアイデアはおそらく、レジスタバンクが使えるのなら、(専用レジスタではなく)汎用レジスタにリターンアドレスを保管することだろう。基本的なサブルーチン命令の効率を高め、コンパイラ設計者に選択の自由を残すためである。
(訳注:RISC-Vはリターンアドレスを保管するレジスタを選べるが、これを活用したオブジェクトコードを吐くコンパイラは存在するのだろうか?)
vi. 仮想アドレス
コンパイラ設計者はハードウェアのアーキテクトに対して、あんな機能やこんな機能が必要だから作ってくれと要求してきた。OS設計者も、人気のアイデアを推進するために、同じように要求してきた。OSというものはマルチプロセッシングとタイムシェアリングを実現するために生まれたので、OS設計者はそのための機能を要求した。入出力などの作業のために実行をブロックされた場合のプログラムの切り替え(コンテキストスイッチ)を素早く効率的に行いたい、というのが基本的なアイデアだった。そのため、多様なプログラムが細かく分割されて、インターリーブで疑似並行的に実行された。その結果、メモリのアロケーション(と解放)の要求は、予測不可能な、任意のシーケンスとなった。しかも、個々のプログラムはリニアなアドレス空間の連続したメモリブロックを想定してコンパイルされていた。悪いことに、マルチプロセッシングが有益といえるほど多くのプロセスを動かせるような物理メモリ容量は一般的ではなかった。
間接アドレッシングが、今度はプログラマには見えない形で、このジレンマに対する解決策として浮上した。メモリは一定のサイズ(2の累乗)に分割され、ブロックまたはページという単位で扱われる。(仮想)アドレスは、ページテーブルによって物理アドレスにマップされる。これにより、個々のページはメモリのどこにあっても、連続した空間に見える。さらに良いことに、ページは常に物理メモリ上にある必要はなく、大容量のディスクという裏庭にも置いておける。ページテーブルエントリ上の1ビットで、そのページがディスクにあるか主記憶にあるかを示せばいい。
この賢く複雑な方法は、当時は役に立った。しかし困難と問題もあった。この方法は、新しいハードウェアのすべてに、ページテーブルとアドレスマッチングの機能を、そして間接アドレッシングのコストを(無警戒のユーザから)隠すことを要求した。もちろん、ページイン・ページアウトはいつ起こるか予想できない。今日でも、ほとんどのCPUはページマッピングを使い、ほとんどのOSはマルチユーザモードで動いている。しかし今日では、これは胡乱なアイデアとなっている。半導体メモリだけでプログラムの要求量を満たすことができるので、ページングという技はもはや有益ではないからだ。間接アドレッシングとその複雑な機構から生じるオーバーヘッドは、今も我々にのしかかっている。
皮肉なことに、仮想アドレッシングは今は、元々の意図とは違う目的のために用いられている:存在しないオブジェクトへの参照、NILポインタ参照をトラップするためだ。NILは0で表され、アドレス0のページはけっして割り当てられない。このやっつけな技は、重い仮想アドレッシング方式の誤用であり、筋のいいやりかたで解決されるべきだ。
vii. メモリ保護とユーザクラス
メモリ保護 というコンセプトは一見、マッピング機構を正当化しそうに思える。複数のユーザが並行して使えるシステムは必ず、異なるユーザのあいだでプログラムとデータが相互に干渉しないことを保証しなければならない。そのような方法はどうしても、一部のユーザに「特権」を与えることを必要とする。基本的には、アクセス制限のかかっている「普通」のユーザプログラムと、プログラム終了後の後片付けなどをする「管理者」プログラムの2種類のクラスがあれば足りる。もしユーザプログラムが未割り当てのメモリにアクセスしようとしたら(おそらくプログラムの間違いだ)、それをトラップして管理者プログラムに制御を戻す(管理者プログラムには間違いがないものとする)。アクセス権限をページテーブルに登録しておくのは簡単だ。
よく考えてみると、未割り当てのメモリや、(OSを介さず)直接操作してはならないデバイスにアクセスしようとすることが可能であるがゆえに、こうした間違いが可能であり、メモリ保護が必要になる。もしすべてのプログラムが、適切なプログラミング言語(処理系が正しく実装されているものとする)で書かれていれば、名前のないリソースを参照することはそもそも不可能になる。メモリ保護は、コンパイルされたプログラムの絶対条件でなければならない;それはソフトウェアで保証されるべきものだ。
もしこの要求がナンセンスではないかと疑うなら、現代の言語処理系が自動ガベージコレクションによる記憶域管理に依存していることを考えてみてほしい。自動ガベージコレクタは、マルチユーザシステムが必要としているものと完全に同じアクセス安全性を必要としている。もしこの安全性がなければ、たとえシングルユーザのシステムだろうと、自動ガベージコレクタはいつでも「事故で」データを破壊しうる。真に安全なシステムでは、すべてのコードは正しいコンパイラの出力であり、またその出力は書き換え不可能であることが要求されるはずだ。この要求は、フォン・ノイマンの輝かしいアイデア、「プログラムとデータは共通の記憶域でアクセスされる」のほぼ完全な放棄である、と言っておきたい。
よって、ハードウェアによるメモリ保護は、まるで松葉杖のようなものだ。それは、起こりうる違反の小さな一部しかカバーしない。もしソフトウェアによる安全性が実装されれば不要となる。かつてはよいアイデアだったもの(訳注:マッピング機構)が、後に他のアイデアに凌駕される、という事態が起きているように見える。
viii. 複雑な命令セット
初期の計算機は、回路という高価なリソースの必要量を最小限で済ませるために、小さく単純な命令セットを備えていた。ハードウェアが安価になるにつれて、より複雑な性質の命令を実装したいという誘惑が生じた。たとえば、3つのターゲットへの条件付きジャンプ、インクリメント・比較・条件分岐の3つを行う単一の命令、複雑な移動・変換命令である。高級言語が登場すると、特定の言語構造に特化した命令を乗せたいという欲望が生じた。Algolのfor文や、(再帰的な)手続き呼び出しの命令がよい例である。機能特化型の命令は、当時においては賢いアイデアだった。当時は、メモリが貴重なリソースだった(64KB以下しかない)ので、こうした命令でコード密度を高めることは重要だった。
この潮流は1963年にまで遡れる。バローズB5000は、Algolの複雑な機能をたくさん乗せていた(後に触れる)だけでなく、科学技術計算と文字列処理の両方の機能を兼ね備えており、そのために異なる2つの命令セットを持っていた。高速なROMにマイクロプログラムを格納する技法によって、こうした無駄遣いが可能になった。この機能(訳注:マイクロプログラム方式)は、計算機ファミリというアイデアを現実的なものにした:IBM 360シリーズの計算機は、プログラマに見えるかぎりでは、すべて同じ命令セットとアーキテクチャを持っていた。しかし内部的には機種ごとにまったく異なっていた。ローエンドのマシンは、マイクロプログラムによって機械語を逐次実行していた。しかしハイエンドのマシンは、すべての命令をハードウェアで直接実装していた。この技術は、Intel 8086、Motorola 68000、NS 32000のようなシングルチップのマイクロプロセッサでも使われた。
NSのプロセッサは、複雑な命令セット(CISC)の格好の例である。頻出する命令パターンを単一の命令に固めることで、コード密度は大いに高まり、メモリアクセスの回数が減り、実行速度が高まる。
NSのプロセッサは、例えば、モジュールと分割コンパイルの新しいコンセプトを備えていた。コンパイラが用意しておいたリンク情報テーブルを使って、コードセグメントはロード時にリンクされる。これは確かに、リンク作業(リンクテーブルへの参照を絶対アドレスに置き換える)のステップ数を少なくするにはよいアイデアだ。リンカの仕事を簡単にするこの方式では、すべてのモジュールのストレージ構成を把握することになる。
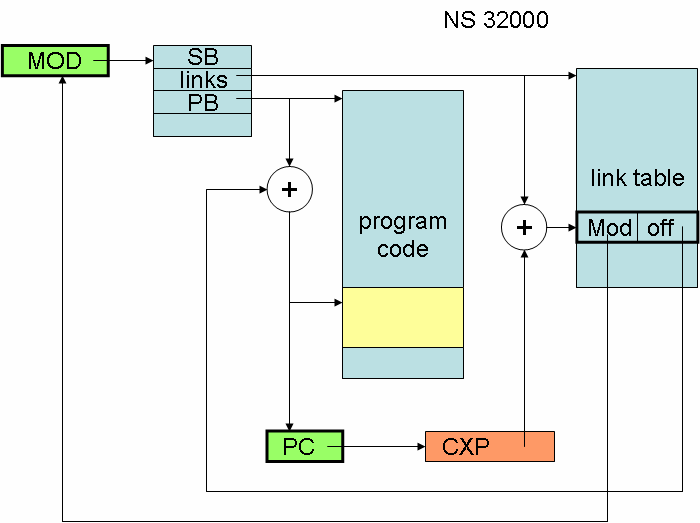
MODという専用レジスタは、モジュールMのディスクリプタを指し、そのモジュールMは現在実行中の手続きPを含む。PCレジスタは通常のプログラムカウンタである。SBレジスタはモジュールMのデータセグメントのアドレスを保持する。データセグメントとは、モジュールの静的グローバル変数である。これらのレジスタは、外部の手続きが呼ばれるたびに値を変える。このプロセスを高速化するために、通常のBSR (branch subroutine) 命令に加えてCXP (call external procedure) 命令がある。もちろん、それぞれ対応するリターン命令は異なる:RXP、RTS。
第二に、配列境界チェックの命令にも同様の例がある。配列インデックスを配列の上限・下限と比較する命令で、インデックスが範囲内にない場合にはトラップを起こす。つまり、1個の命令のなかに、2つの比較命令と2つの分岐命令が含まれている。
我々がOberonコンパイラを制作・公表してから数年のうちに、(そのNSのプロセッサの)新しい高速なバージョンが現れた。頻繁に使われる単純な命令をハードウェアで実装し、複雑な命令は内部マイクロコードで逐次実行するものだった。そのため、こうした高級言語指向の命令は、単純な命令に比べて遅くなった。そのため私は、新しいバージョンのコンパイラでは、こうした手のこんだ命令を使わないようにした。その結果は衝撃的だった! 新しいコードは前のよりもかなり速かった。計算機アーキテクトと我々コンパイラ設計者は、間違ったところに「最適化」されていたように見える。
1980年代初頭から、高度なマイクロプロセッサは古いメインフレーム(非常に複雑で非正規な命令セットを持つ)と競合しはじめた。(訳注:メインフレームの)命令セットがあまりにも複雑なので、ほとんどのプログラマは実際には、その一部しか使えなかった。同様にコンパイラも、使える命令全体ではなくそのサブセットだけを使うようになっていた。これはハードウェア設計者がやりすぎたことの明白な兆候である。その反応は、1990年ごろに、縮小命令セットコンピュータ(RISC)、特にArm、Mips、Sparcアーキテクチャのマニフェストだった。それらは単純な命令の小さなセットを備え、命令はすべて単一サイクルで実行され、単一のアドレッシングモードだけを持ち、かなり大きな単一バンクのレジスタを備えていた。端的に言うと、高度に正規化された構造である。これらのアーキテクチャは、CISCが悪いアイデアだったことを示した。
ix. レジスタ・ウィンドウ
手続きが呼び出されたときには、そのローカル変数のための記憶領域が割り当てられる必要がある。手続きが終了したときには、その記憶領域は解放される。そのためのもっとも便利な方式はスタックである。スタックの解放は、ただレジスタのスタックポインタをリセットするだけで済む。
「もっとも頻繁にアクセスされる変数をレジスタに割り当てる」というコード最適化技法はよく使われる。理想的には、すべての変数はレジスタであってほしい。しかし、少数の手続きブロック(訳注:手続きブロックとはたとえば、関数の先頭から末尾までのこと)のローカル変数が、(他の手続きを呼び出すときに)レジスタ上にとどまるだけでも、有意義な速度の向上が得られる。これは レジスタ・ウィンドウ というアイデアをもたらした。手続きが呼び出されるとき、現在のレジスタのセットは(スタックのように)プッシュダウンされ、呼び出し先の手続きブロックのための新しいレジスタのセットが提供される。将来メモリは高速に、大きく、安価になると予想されていたので、レジスタの数(訳注:すなわちメモリ上に退避せずに済むスタックフレームのサイズ)は増えるだろうが、そのときプログラムを変更する必要はない。このアイデアはスケーラブルである。こうしてレジスタ・ウィンドウを組み込んだ Sparcプロセッサ が生まれた:スタックの一番上(ウィンドウ)だけにアクセスできるレジスタスタックである。手続き呼び出しのたびに新しいウィンドウを開き、終了のたびにスタックをポップする。
これはかなり賢いアイデアに見える。しかし、SparcアーキテクチャがRISCの成功例として生き延び、しかも後にはIntelのItaniumプロセッサにも採用されたにもかかわらず、それは胡乱なアイデアであることが判明した。開いているウィンドウのレジスタは頻繁にアクセスされるが、そうでないレジスタはほぼ休眠状態にあるにもかかわらず、貴重で高価なリソースを専有しているからである。レジスタ・ウィンドウは、もっとも高価なリソースのお粗末な利用を意味している。
(訳注:事態はもう少し複雑である。CPUが最適化を行うレジスタ・リネーミングの登場により、コンパイラが最適化を行うレジスタ・ウィンドウは「早すぎる最適化」になった。レジスタ・ウィンドウはレジスタ・リネーミングの効率を損なう)
4. プログラミング言語機能
プログラミング言語の分野は、論争を招くアイデアの沃土である。胡乱なだけでなく、最初から悪いと知られていたアイデアもある。我々は個々の言語のメリットと非道については論じないよう務める。それよりも、複数の言語に見られるようなコンセプトと構造に注目する。ほとんどの議論は、1960年のAlgolや、その後継者が提案した機能についてのものになる。1
個々の機能の話の前に、審査の前提について説明しておきたい。ほとんどの人はプログラミング言語のことを、計算機で「動く」ソフトウェアを構成するためだけのものだと考えている。我々は、言語とは計算モデルであり、プログラムとは数学的な理論に従う形式的なテキストだと考えている。このモデルは、実装(物理的にも抽象的にも)を参照することなくセマンティクスを定義するものでなければならない。何巻ものマニュアルで説明される複雑な機能のセットは、はっきりと悪いアイデアとなる。E. W. Dijkstraいわく、プログラマにとってもっとも困難な日課とは、物事をダメにしないことだ。この永遠の苦闘を助けることは、言語の第一の高貴な義務であろう。
i. 表記法と構文
表記法を、個人の好みによる小さな問題だとみなすことが流行っている。ある意味ではこれは正しい;しかし表記法の選択はなんでもいいわけではない。その選択は重要であり、言語の性格を明らかにする。
悪いアイデアとして悪名高いのは、「イコール記号で代入を表す」という選択だ。これは1957年のFortranにさかのぼり、言語設計者連合軍によって盲目的に採用されてきた。これはなぜ悪いアイデアなのか? 「イコール記号は等価性を表し、その式は真か偽である」という百年の伝統を投げ捨てるものだからだ。しかしFortranはイコール記号を代入(assignment)、等価性を 強制 するという意味で用いた。この場合、右辺と左辺は立場が異なる:左辺(変数)は右辺(式)と等しくされる。 x=y は y=x と同じ意味ではない。この間違いを、Algolは簡単なやりかたで解決した:代入を「 := 」で表したのだ。
イコール記号で代入を表すことに慣れたプログラマにとっては、これはあら捜しに見えるかもしれない。しかし代入と比較を混ぜることは真に悪いアイデアである。伝統的にイコール記号で表されてきたことに、別のシンボルが必要になるからだ。等価性の比較は2文字の「 == 」で表されるようになった(最初にやったのはC)。これはugly kindがもたらしたものであり、同様の悪いアイデア「 ++」「 -- 」「 && 」などを呼び起こした。
C、C++、Java、C#では、「 ++ 」や「 -- 」は副作用を持つが、これはプログラミングミスの根源として悪名高い。たとえばもし、 ++ がインクリメントだけを表し、インクリメントされた値(これからインクリメントされる値?)を表さないとしたら、問題はない。しかし両方を表すので、これは副作用を持つ式となる。トラブルの核心は、文と式の原理的な区別を廃したことにある。前者は命令であり、 実行 される;後者は計算で得られる値を表し、 評価 される。
他の言語機能と組み合わせると、構造のまずさが明らかになることが多い。Cでは、たとえば、 x+++++y と書ける。式というより謎々であり、手のこんだパーサへの挑戦でもある! どうなるだろうか? その値は ++x+++y+1 と等しいだろうか? もしくは、以下は正しいか?
x+++++y+1==++x+++y x+++y++==x+++++y+1
新しい代数なのだと想定したくなる! どんな阿頼耶識のゆえか、この表記法の怪物が全世界のプログラマのコミュニティに受け入れられていることは実にまったくの驚きである。
1962年にAPLは演算子の右結合を提唱した。これも同様に、確立された慣行を破っている。 x+y+z は今や突然 x+(y+z) となり、 x-y-z は x-y+z の意味になる。なんと不実な落とし穴か!
単にシンボルの選択がまずかったというよりシンタックスが不幸だったケースとして、Algolの条件文がある。これには2つの形式があり、 S0 と S1 は文である:
if b then S0
if b then S0 else S1
この定義は、後にdangling elseとして知られるようになる曖昧さを不可避的に生じさせた。たとえば、この文
if b0 then if b1 then S0 else S1
には2種類の解釈ができる。つまり
if b0 then (if b1 then S0 else S1)
if b0 then (if b1 then S0) else S1
まったく異なる結果になる可能性がある。次の例はさらに危険に見える:
if b0 then for i := 1 step 1 until 100 do if b1 then S0 else S1
なぜならこれは、まったく異なる計算を行う2つの方法でパースできる:
if b0 then [for i := 1 step 1 until 100 do if b1 then S0 else S1]
if b0 then [for i := 1 step 1 until 100 do if b1 then S0] else S1
対策は、しかし、きわめて単純である:明示的なendシンボルをすべての再帰的な構造の末尾に置き、先頭にif、white、for、caseのような明示的なシンボルを置くのだ:
if b then S0 end
if b then S0 else S1 end
ii. GO TO文
悪いアイデアのリストの筆頭として、これよりふさわしいものがあるだろうか? 多くの批評家がgo to文を悪者にしてきた。ジャンプ命令に直接対応する言語機能である。これは条件分岐にも、文の繰り返しにも使える。プログラムの流れを迷路や反吐にするのにも使える。正規化された構造をすべてぶち壊し、そうしたプログラムが不可能でないとしても困難であることの構造化された根拠を与える。
なぜgo to文は「プログラミング言語における悪いアイデア」の原型となったのか。複雑な対象を把握・制御するうえで我々のもっとも重要なツールは、構造と抽象化である。あまりにも複雑な対象はパーツへと分割される。そうしたパーツの仕様は、複雑な対象全体を反映したものではなく、パーツ固有のものである(訳注:たとえば、ほとんどのプログラムは32ビット整数のintを使う)。これにより、パーツの仕様とインターフェイスに限定された知識で、複雑な対象全体の設計を進めることができる。
すると当然、プログラミング言語は、パーツの性質から複雑な対象全体の性質を作り出せるように、ネストした構造の形式化を、許可し、推奨し、強制もしなければならない。たとえば、文 $S$ の繰り返し $R$ の仕様を考えてみる。 $S$ は $R$ の一部として現れるものとする。2つの形式がありうる:
R0: while b do S end
R1: repeat S until b
適切なネストの背後にある鍵は、 $S$ の既知の性質が、 $R$ の性質を生成するのに使えることである。例えば、 $S$ の実行中に常に成り立つ(不変)条件 $P$ があるとする。 $P$ は $S$ が繰り返されるあいだも不変であるといえる。これはホーア論理の法則によって形式的に表現できる:
{P & b} S {P} implies {P} R0 {P & ¬b}
{P} S {P} implies {P} R1 {P & b}
しかし、もし $S$ がgo to文を含んでいると、 $S$ についてのこうした不変条件は成り立たない。 $R$ の効果についての推論もできない。これは重大な損失である。経験によれば、go toのない大きなプログラムはずっと理解しやすく、その性質について保証することもずっと容易である。
この非-機能が悪いアイデアの最大の例であることについては、今さら言うまでもない。Pascalの設計者はgoto文を外さなかった(同様に、endシンボルなしのif文も外さなかった)。明らかに彼には、慣習を破る勇気がなく、伝統への間違った譲歩をしてしまったのだ。しかしそれは1968年のことだった。今では誰もが問題を理解しているが、最新の商用プログラミング言語の設計者は例外だ。たとえばC#。
iii. switch
もし、ある機能が悪いアイデアなら、その機能の上に作られた機能はさらに悪いアイデアだ。switchのコンセプトには、この法則がよくあてはまる。switchは本質的にはラベルの配列である。たとえば、Algolにおけるラベル L1,...L5 とswitch宣言の例を示す:
switch S := L1, L2, if x < 5 then L3 else L4, L5
明らかに単なるgoto文の S[i] は、以下と等価である:
if i = 1 then goto L1 else
if i = 2 then goto L2 else
if i = 3 then
if x < 5 then goto L3 else goto L4 else
if i = 4 then goto L5
gotoを使うとプログラミングは反吐になりやすいが、switchを使うとそれは必然となる。
switchを代替する機能として最適のものは、1965年にC. A. R. ホーアが提案した:case文である。
case i of
1: S1 | 2: S2 | ……….. | n: Sn
end
しかし、近年のプログラミング言語の設計者は、この簡潔な解決策を無視し、Algolのswitchと構造化case文の合体事故を好んでいる:
switch (i) {
case 1: S1; break;
case 2: S2; break;
… ;
case n: Sn; break; }
breakシンボルは、連続した文 Si の区切りを示すだけでなく、switch構造への末尾へのgotoとしても働く。区切りとしては余計であり、変装したgotoでもある。悪い表記法を使った悪いコンセプト! この例はCによる。
iv. Algolの文による複雑さ
Algolの設計者は、ある種の繰り返し制御は頻出するので、goto文の組み合わせよりも簡潔に表現できるほうがいいと理解していた。彼らはfor文を導入した。これは配列で用いると特に便利である。例:
for i := 1 step 1 until n do a[i] := 0
stepとuntilという語の選択は不幸だったが、それを措けば、これは素晴らしいアイデアに見える。不幸にも、このよいアイデアは、「想像上の一般性」という悪いアイデアによって汚染されていた。制御変数 i は、値のシーケンスによって指定することができる:
for i := 2, 3, 5, 7, 11 do a[i] := 0
さらに、これらの要素は一般的な表現でもよかった:
for i := x, x+1, y-5, x*(y+z) do a[i] := 0
まだある。リスト要素の形式が要素ごとに異なっていることも許可されていた:
for i := x-3, x step 1 until y, y+7, z while z < 20 do a[i] := 0
となると、賢い人はただちに病的なケースを調合し、コンセプトの馬鹿らしさを示すことができる:
for i := 1 step 1 until i do a[i] := 0
for i := 1 step i until i do i := - i
Algolのfor文の一般性は、未来の言語設計者に対して、「構造の主な目的を常に念頭に置け」という警告を発している。クソデカな一般性と複雑さのために消耗すべきではない。それはすぐに非生産的なものになる。
v. Algolの関数内のstatic変数
Algolは 局所性 というコンセプトを導入した。すべての手続きはそれ自体のスコープを持つ。手続き内で宣言された識別子はローカルであり、手続きの外からは見えない。これは、Algolで導入された革新のなかで、おそらくもっとも重要なものだろう。とはいえ、ある種の状況では、これは完全に妥当な設計とは言えないことがわかった。具体的には、手続きに入るとき、すべてのローカル変数はフレッシュである。これは、手続きに入るときに新しい記憶領域を割り当て、出るときに解放することを意味している。ここまではいい。しかし、手続きを出るときに記憶領域が解放されず、次に入るときまで値が保存されているようなローカル変数が欲しいケースもある。Algolでは、変数宣言に単にownとつけることで、こうした変数が使える。疑似乱数を生成する手続きは、よくある例だ:
real procedure random; own real x; begin x := (x*a + b) mod c; random := x end
この単純な例がすでに罠を示している:変数 x の初期値はどうなっているのか? どんな解決策もかなり面倒であることがわかった。再帰におけるownの意味も、未解決の疑問である。明らかに、問題はもっと深いところにある。ownシンボルを単純に導入することで、解決した問題よりも大きな問題を作り出してしまった。
問題は、識別子のスコープというコンセプトとオブジェクトの寿命を結びつける、Algolの賢い表記法にある。オブジェクトが存在しはじめるのと同時に、そのオブジェクトの識別子が見えるようになる(ブロックに入るとき)。存在をやめるのと同時に、識別子が見えなくなる(ブロックを出るとき)。可視性と存在の密接な関係は、断ち切らなければならなかった。これは後に(Mesa、Modula、Adaで)モジュール(またはパッケージ)のコンセプトを導入することで行われた。モジュール変数はグローバルだが、モジュール内で宣言された手続きからのみアクセスできる。こうすれば、手続き(モジュール内でのローカル呼び出しであれ、モジュール外からであれ)の実行が終了したとき、モジュールの変数は存在し続け、再び手続きが呼び出されたときには古い値が再び現れる。モジュールは変数をプライベートにし(情報隠蔽)、かつモジュールがロードされた際に変数を初期化する。
この例は、異なるコンセプト――情報隠蔽とオブジェクトの寿命――を単一の言語構造として表現した際に生じる問題を示している。解決策は、個々のコンセプトをそれぞれの構造で表出することである。モジュールは情報隠蔽に、手続きはオブジェクトの寿命に使う。同様の不幸な結婚は、いくつかのオブジェクト指向言語にも見られる。(1)ポインタとオブジェクト、(2)型とモジュール(クラスと呼ばれる)の結合である。
vi. Algolの名前渡し
Algolは、それ以前の言語(Fortran)で知られていたものよりもずっと一般的な手続きと引数を導入した。特に、引数は伝統的な数学の関数とみなされたので、仮引数は テキスト的に 実引数に置換された2。たとえば、この宣言
real procedure square(x); real x; square := x * x
square(a) の呼び出しは文字通り a*a と解釈され、 square(sin(a)*cos(b)) は sin(a)*cos(b) * sin(a)*cos(b) と解釈される。これはサインとコサインが2度評価されることを求めるが、それがプログラマの意図であることはまずない。この頻出するミスリーディングなケースを防ぐため、この 名前渡し に加えて第二の方法、 値渡し が提唱された。値渡しでは、仮引数はローカル変数となり、実引数の値で初期化される。
real procedure square(x); value x; real x; square := x * x
上の呼び出しは次のように解釈される
x’ := sin(a) * cos(b); square := x’ * x’
これで、実引数を2回評価するという無駄は回避される。名前渡しはとてつもなく柔軟なデバイスであり、その例を次に示す。以下の宣言を考える
real procedure sum(k, x, n); integer k, n; real x;
begin real s; s := 0;
for k := 1 step 1 until n do s := x + s;
sum := s
end
これにより、 a1 + a2 + … + a100 の総和は単に sum(i, a[i], 100) と書ける。ベクトルaとbの内積は sum(i, a[i]*b[i], 100) 、調和関数は sum(i, 1/i, n) となる。一般的には、これは簡潔で洗練されているように見えるが、しかし対価が伴う。少し考えてみると、名前渡しの仮引数は常に、無名の、引数を取らない手続きとして実装されなければならない。不用心なプログラマは、隠れたオーバーヘッドを喜んで負担するのではないか? 当然、賢い設計のコンパイラはそうしたケースを「最適化」するだろう。利口な設計者は、愉快な機能がもたらすこうした挑戦を喜んで受ける。
読者はこう尋ねたくなるだろう:「この大騒ぎはなんのつもりだ?」。言語から名前渡しの機能を外したほうがいい、というだけの話ではないかと。しかしこの処置はあまりにも過激であり受け入れられない。たとえば、手続きの結果を返すための引数を割り当てる方法がなくなる。名前渡しのかわりに参照渡しを入れる、という解決策が必要となる。これはAlgol W、Pascal、Adaなどで行われた。今日では、教訓は次のとおり:過度に洗練された機能には懐疑的になるべし。最低でも、言語がリリース・出版・宣伝される前に、そうした機能がユーザに課するコストを調べなければならない。このコストは、その機能がもたらす利益と釣り合うものでなければならない。
vii. Algolの不完全な引数型指定
この問題は引数に関するものなので、ほとんど前項の続きである。この問題は、Algolが仮引数の完全な型指定を要求しなかったことで起きた。ただの見落としのように見えるが、由々しき結果をもたらした。たとえばAlgolは、次のような宣言を許していた:
real procedure f(x, y); f := (x-y)/(x+y)
以下の変数を考える
integer k; real u, v, w
次のような呼び出しができる:
u := f(2.7, 3.14); v := f(f(u+v), 10); w := f(k, 2)
とりあえずは(まだ)いい。次の例はややこしい:
real procedure g; g := u*v + w;
u := f(g, g)
fの仮引数を置換するのが、値なのか式なのか関数なのかわからないし、そもそも有効な数と型なのかさえも、コンパイル時に推論することはできない。こうした仮引数にアクセスするときには、実引数が値か式か関数かを実行時に検査することになる。これはほとんどの実用アプリケーションにとって受け入れられないオーバーヘッドである。
学術的な関心だけで話が終わっていれば、つまりこの話の続きがなければよかったのだが、残念ながら、この話には続きがある。これを技術上の挑戦と受け取り、ハードウェアで解決しようとした試みのうち、もっとも遠くまで行ってしまったのが、バローズのB5000である。B5000が配列アクセスのためのデータディスクリプタを備えていることについてはすでに触れたが、ここでは手続きのためのプログラムディスクリプタについて述べる。データとプログラムのディスクリプタは、(訳注:主記憶のワード内にある)タグフィールドの値によってデータから区別される。通常のロード命令が(主記憶上の)プログラムディスクリプタにアクセスすると、単なるメモリアクセスだけではなく、手続き呼び出しが発生する。つまり、コンパイル時の検査では(実引数の型が)決まらなければ、実行時にやるしかない。ひとつの命令が、アクセスされたワードのタグによって、単なるデータのロードをすることもあれば、複雑な手続き呼び出しをすることもある。
しかしこれはいいアイデアなのか、悪いアイデアなのか? どちらかといえば後者だ。この計算機は複雑で高価だったために市場では成功しなかった、という理由だけではない。些細な速度向上のために非常に複雑な命令を備えることは賢明ではない、という理由もある。結局、こうした混乱を招いた言語機能は、誤りであり、設計の欠陥であると見なすべきである。有能なプログラマは、プログラムを明快にするために、引数型を完全に指定する。Algolの仕様を一文字残らず満たしたいという衝動は、胡乱な知恵からくるアイデアである。
この話題の最後に、ある手続き宣言の例を示す。個々の機能としては明らかに無害なものを組み合わせるとパズルになることを示すものだ。
procedure P(Boolean b; procedure q);
begin integer x;
procedure Q; x := x+1;
x := 0;
if b then P(¬b, Q) else q;
write(x)
end
P(true, P) を呼び出したとき、 write() される値は何か? 0, 1か、それとも1, 0か?
viii. 抜け穴
抜け穴は最悪の機能だ。かくいう筆者は心穏やかならず、皮肉をこめて、これを書いている。筆者は自分の言語であるPascal、Modula、さらにはOberonにさえ、この死のウイルスを感染させたからだ。
抜け穴は、コンパイラによる型チェックをプログラマに突破させる。プログラマいわく「俺にかまうな、俺は型検査よりも賢い」。抜け穴はさまざまな形をとる。もっとも一般的なのは、明示的な型転換関数である。たとえば
x := LOOPHOLE[i, REAL] Mesa
x := REAL(i) Modula
x := SYSTEM.VAL(REAL, i) Oberon
抜け穴はほかにも、絶対アドレス指定や、Pascalの可変レコードを使って変装することがある。上の例では、整数iの内部表現が浮動小数点数として解釈されているが、これは数の表現についての知識がなければできないことであり、言語の提供する抽象レベルでの記述はそうした知識を前提にしてはならない。PascalとModulaでは3、抜け穴は正直に表示されている。Oberonでは疑似モジュール System の少数の関数内にのみ存在するので、抜け穴のような低レベルの機能を使っていることが明示される。これは言い訳に聞こえるだろうが、それでもなお抜け穴は悪いアイデアである。
では、抜け穴はなぜ導入されたのか? それは、全システムをひとつの同じ(システムプログラミング)言語で実装したいという欲望のためだ。たとえば、記憶領域マネージャは、記憶領域をデータ型のないフラットな配列として扱える必要がある。記憶領域マネージャは、型の制約とは独立して、ブロックを割り当てて回収する必要がある。抜け穴が必要なもうひとつの例はデバイスドライバだ。初期の計算機では、デバイスは特殊な命令でアクセスされた。後には、かわりに特定のメモリアドレスに配置されるようになった。これが「メモリマップドI/O」である。ある種の変数で絶対アドレスを指定するというアイデア(Modula)はここから生じた。しかしこの機能は、多くの陰謀めいたトリッキーな方法で乱用された。
明らかに、「普通の」ユーザは記憶領域マネージャやデバイスドライバをプログラミングしない。当然、こうした抜け穴の必要もない。しかし――これが抜け穴を悪いアイデアにするのだが――「普通の」プログラマは七つ道具のなかに抜け穴を入れている。経験が示すところでは、普通のプログラマは抜け穴を使うのをためらうどころか、素晴らしい機能だと熱狂して、使えそうなところでは必ず使う。マニュアルがその危険を警告している場合には、特にだ!
抜け穴の背後にはたいてい、言語の本質における欠陥がある。その言語が、なにか重要なものを表現できないので、抜け穴が必要になるのだ。Modulaのaddress型はその例である。これは型が異なる要素を指すデータ構造を作るためのものだった。Modulaでは、コンパイル時にポインタが特定の型を持っていなければならず、ポインタが指すデータも同様だった。ポインタがアドレスだと知っていれば、無害に見える形転換関数によって、ポインタ変数はどんな型のオブジェクトでも指せるようにできる。もちろん、こうした代入の正しさをチェックできるコンパイラがないことが欠点だ。型チェックシステムは破棄され、存在しなかったことになった。教訓:鎖の強さはその一番弱い環で決まる。
Oberonは 型拡張 (オブジェクト指向言語の 継承 )というコンセプトで、クリーンな解決策を与えた。これによって、拡張元の型のポインタが、拡張先の型のオブジェクトを指すことができる。これは、信頼性のある型検査システムのもとで安全なinhomogeneousなデータ構造を構築できる。検査は、コンパイル時に不可能な場合に限って、実行時に行われる。
1960年代の言語で書かれたプログラムは抜け穴を使いまくっている。そのため、こうしたプログラムは極度にエラーを起こしやすい。しかし代案はなかった。Oberonのような言語で、(記憶領域マネージャとデバイスドライバを除いて)抜け穴を使わずにスクラッチからシステム全体をプログラムできるという事実は、過去40年間における言語設計の進歩のなかで特に目覚ましいものである。
5.その他のテクニック
最後の章は、広くソフトウェアの慣習一般、あるいは筆者のある種の経験にもとづく。後者の一部は40年前の話だが、そこから学べるものは、当時も今日も有用である。一部は近年の慣習や傾向だが、たいていは富豪的なハードウェア能力に支えられている。
i. 構文解析
1960年代は構文解析の10年だった。言語定義とコンパイラ構築を科学の一分野へと転換させるうえで、Algolの形式的な構文定義は不可欠な支柱だった。これは構文主導のコンパイラというコンセプトを確立し、厳密な数学的基礎にもとづいて構文解析を自動化しようという試みを数多く生み出した。トップダウン・ボトムアップへの理解、再帰下降法、シンボルの先読みとバックトラッキングが発明された。同時に、言語のセマンティクスをより厳密に定義しようとする努力もなされたが、それはセマンティクスに対応する構文規則との抱き合わせ販売という形で行われた。
新しい研究領域が現れたときには、開拓時代におけるニーズを超えたところを研究してしまうものである。より一般的な、より複雑な文法を扱える、より強力なパーサジェネレータが次々と開発された。これは確かに知的達成ではあったが、その結果はあまり喜ばしいものではなかった。言語設計者は、「どんな構文構造であれ、自動ツールが確実に曖昧さを検出し、強力なパーサがパースしてくれるだろう」と信じるようになった。これはミスリーディングなアイデアだった! 自動ツールは、どうすれば構文がよくなるのかを示してくれるものではなかった。設計者が無視したのは、効率の問題だけではない。言語とは、自動パーサだけでなく、人間が読むものでもあることをも無視した。パースするのが難しい言語は常に、人間が読んで理解するのも難しい。設計者が単純なパーサを強制されたほうが、言語はクリーンになる。
これはまさに私が経験したことでもある。1960年代に順位構文文法のパーサについての研究をして、その実装をEuler言語とAlgol W言語に用いたあと、私は転換を決断した。Pascalのパーサを、もっとも単純なトップダウン再帰下降法にしたのだ。これで私は自信を深め、それからずっと同じ選択を喜んで続けている。
代償(優位と言いたいが)は、発表や実装に先立って、構文の設計にもっと用心深く考える必要があることだ。この労力は、後に言語とコンパイラを使う際に、お釣りがついて返ってくる。
ii. 拡張可能な言語
1960年代の計算機科学者のドリームは無限だった。自動構文解析とパーサ生成の成功に勢いづいて、柔軟(少なくとも拡張可能)な言語というアイデアが提案された。プログラム本体の前に構文規則が置かれ、パーサに構文規則を適用した上でプログラム本体を解釈する、というものだった。もう一歩進めよう:構文規則はプログラム本体の前だけでなく、テキスト全体のどこに散在していてもいい。たとえば、特殊でファンシーでprivateな形のfor文を欲するなら、簡潔に手に入る。しかも、同じコンセプトのさまざまなバリエーションをひとつのプログラムのあちこちのセクションに用いることさえできる。言語は人間同士の意思疎通に使うもののはずだが、そのことはまったくどうでもよくなり、誰もが作業中に自分自身の言語を定義できるようになった。この大志は、しかし、こうしたprivateな構造の意味を規定することの難しさに挫かれた。こうして、拡張可能な言語という愉快なアイデアはすみやかに消えていった。
iii. 入れ子になった手続きとDijkstra's display
(訳注:この章は内容が理解できなかったので訳さなかった)
iv. 木構造のシンボルテーブル
コンパイラはシンボルテーブルを構築する。これらは宣言の処理中に作成され、文の処理中に検索される。ネストされたスコープを許可する言語では、すべてのスコープが独自のテーブルで表される。
従来、これらのテーブルは高速検索を可能にするために二分木だった。また、この長年の伝統を静かに守ってきた筆者は、Oberon コンパイラを実装する際に木の利点をあえて疑うことにした。いったん疑いを抱いてみると、木構造はローカルスコープにとって価値がないとすぐに確信することになる。ほとんどの場合、手続きに含まれるローカル変数は1ダースもない。リンクされた線形リストを使用すると、より簡単かつ効果的になる。
30~40年前のプログラムでは、ほとんどの変数がグローバルに宣言されていた。このため木構造は適切だったのかもしれない。しかし当時から今までのあいだに、グローバル変数の価値に対する懐疑的な見方が高まった。最近のプログラムはあまり多くのグローバルシンボルを持たないため、木構造のテーブルはとうてい奨められない。
現代のプログラミングシステムは多くのモジュールで構成されており、それぞれのモジュールにはおそらくいくつかのグローバルシンボル(ほとんどが手続き)が含まれているが、数百ではない。太古のプログラムが持っていたような多数のグローバルシンボルは、今ではモジュールに分散されており、単一の識別子ではなく、M.x のような名前の組み合わせによって参照される。
洗練されたデータ構造をシンボルテーブルに使うのは明らかに悪いアイデアだった。かつてはバランス木を検討したことさえあった!
v. 間違ったツールの使用
間違ったツールを使用することは、明らかに本質的に悪いアイデアである。問題は、多くの場合、ツールを構築して理解するために多大な労力を費やし、そのツールが「価値のある」ものになった後でのみ、そのツールの不適切さに気づくことだ。これは、1969年に最初のPascalコンパイラを実装したときに、筆者とそのチームに起こった。
プログラムを作成するために利用できるツールは、アセンブラ、Fortran、およびAlgolコンパイラだった。Algolは実装があまりにもお粗末で、それに依存するのは無謀であり、アセンブラを使用するのは不名誉だと考えられていた。残ったのはFortranだけだった。
したがって、私たちの幼稚な計画は、Fortranを使用してPascalの有用なサブセットのコンパイラを構築し、完成したらそれをPascalに翻訳することだった。その後、古典的なブートストラップ手法により、コンパイラが完成、改良、改善された。
しかし、この計画は現実の前に挫折した。約1人年の労力をかけてステップ1が完了したとき、FortranコードをPascalに翻訳するのはまったく不可能であることが判明した。そのプログラムはFortranの機能、あるいはむしろその機能の欠如によって大きく左右されていたため、コンパイラを新たに作成する以外に選択肢はなかった。 Fortranにはポインタとレコードの機能がなかったため、シンボルテーブルを不自然な形式の配列に押し込む必要があった。Fortranには再帰的サブルーチンはなかった。したがって、複雑なテーブル駆動のボトムアップ解析手法を、配列と行列で表される構文とともに使用する必要があった。つまり、Pascalの利点は、完全に書き直され、再構築された新しいコンパイラによってのみ利用できた。
この「事件」は、一見して一番簡単な方法が必ずしも正しい方法ではないこと、しかし困難には利点もあることを明らかにした:Pascalで書かれたこの新しいコンパイラは、まだPascalコンパイラが利用できなかったため、開発中にテストできなかった。Pascalの有用なサブセットをコンパイルするためのプログラム全体は、テストからのフィードバックなしで作成する必要があった。これは非常に健康的なエクササイズだったが、迅速な試行と対話型のエラー修正の時代では、さらに健康的だろう。コンパイラが「完成した」と私たちが信じた後、チームのメンバーの1人が、コンパイラが利用可能な、シンタックスシュガーのある低水準言語にプログラムを翻訳するために缶詰めになった。彼は2週間の集中労働を終えて戻り、数日後、最初のテストプログラムがPascalで書かれたコンパイラによって正しくコンパイルされた。入念なプログラミングのエクササイズは、非常に有益であることが判明した。デバッグ・ツールが使えないときほど、バグが少ないプログラムはない!
その後、ブートストラップによって、より多くのPascalの構造を扱い、より洗練されたコードを生成する新しいバージョンを得ることができた。最初のブートストラップの直後、私たちは補助言語で書かれた翻訳を破棄した。その性質は、1年後に発表された不吉な低レベル言語Cとよく似ていたからだ。この経験の後、ソフトウェア工学のコミュニティが、C言語の代わりに高水準で型安全な言語を採用することの利点を認識していないことを理解するのは難しかった。
vi. ウィザード
これまで、1960年代に端を発する構文解析技術の飛躍的進歩について述べてきた。その成果は当時から今に至るまでずっと目の前にある。現在、手作業でパーサを構築する人はほとんどいない。そのかわりに、パーサ・ジェネレーターを購入し、必要な構文を入力する。
これが、現在では「ウィザード」と呼ばれている自動ツールの話題につながる。ウィザードとはブラックボックスであり、ユーザーはその内部を理解する必要はない;ウィザードは、単純なルーチンワークを自動化し、計算機のユーザを煩わしさから解放する、というアイデアだ。ウィザードは、忠実で献身的な召使いとして、ユーザの手助けをしてくれるはずだ。そしてここが肝心なのだが、ユーザが頼まなくても、ウィザードは手助けをする。
素晴らしいウィザードに対して十字軍を始めるのは賢明ではないが、筆者のウィザードとの体験はたいてい不幸なものだった。テキストエディタでウィザードと対峙するのを避けることは不可能である。最悪なのは、頼んでいないのに自動的にインデントや行番号付けをしたり、特定の文字や単語を特定の位置で大文字にしたり、一連の文字を特殊記号に結合したり、一連のマイナス記号を自動的に実線に変換したりと、常にユーザの作文作業を邪魔するウィザードだ。せめて簡単に無効化できればいいのだが、たいてい、それらは悪魔のように頑固で不死身だ。馬鹿のための賢いソフトウェア:悪いアイデア!
6. プログラミングパラダイム
i. 関数型プログラミング
関数型言語の起源はLisp 4である。関数型言語は多くの開発と変更を経て、大小のソフトウェア・システムの実装に使われてきた。筆者はこのような取り組みに対して常に批判的な態度を保ってきた。なぜか?
関数型言語とは何なのだろうか? どんな特徴があれば関数型言語なのか? それは形式にある、と常に思われてきた:プログラム全体が関数評価、入れ子、再帰、パラメトリックなどで構成されていることが条件なのだと。だから 関数型 という言葉がある。しかし、この考え方の核心は、関数は本質的に状態を持たないということだ。つまり、変数も代入もない。変数の代わりになるのは、不変の関数パラメータ(数学の意味での変数)である。その結果、新しく計算された値を同じ変数に再代入して、古い値を上書きすることはできない。これが、繰り返しを再帰で表現しなければならない理由である。データ構造はせいぜい拡張できる程度で、古い部分に変更を加えることはできない。この性質は、(訳注:関数型言語の処理系に)きわめて高度な記憶領域リサイクルをもたらす;ガベージ・コレクタは必要不可欠な要素である。自動ガベージ・コレクションのない実装は考えられない。
状態を最大の特徴とする機械の上に、状態のない計算モデルを仮定するのは、控えめに言っても奇妙なアイデアだ。モデルと機械のあいだの隔たりは大きく、その橋渡しにはコストがかかる。どんなハードウェア・サポート機能も、これが実践するには悪いアイデアだという事実を覆い隠すことはできない。このことは、やがて関数型言語の推進役たちにも認識されるようになった。彼らはさまざまなトリッキーな方法で状態(および変数)を導入してきた。その結果、純粋に関数的な特徴が損なわれ、犠牲になってしまった。古い用語は欺瞞に満ちたものとなった。
関数型プログラミングを振り返ってみると、それが真に貢献したのは、状態を使わないことではなく、明確な入れ子構造と、厳密にローカルなオブジェクトを使うことのの強制だった。もちろん、この規律は、入れ子構造、関数、再帰の概念をとっくに受け入れている従来の命令型言語でも実践できる。もちろん、関数型プログラミングが意味するのは、goto文を避けることだけではない。また、ごく少数のグローバルな状態変数を除いては、ローカル変数への制限も意味する。また、おそらく手続きの入れ子も望ましくないと考えられている。B5000計算機が、厳密にローカルな変数と厳密にグローバルな変数のみにアクセスを制限したのは、どうやら正しかったようだ。
関数型言語は、専門用語とカテゴリーだけの話なのだろうか? その関数というのは形式的な話で、実質はないのだろうか? それとも、関数型パラダイムの実質は、単に「副作用がない」というだけなのだろうか?
何年も前から、「関数型言語は並列性を導入するための最良の手段だ」という主張が増えてきている。その主張は、「コンパイラがプログラムを並列化する機会を検出しやすくするため」と言った方が的を得ている。結局のところ、式のどの部分が同時に評価されるかを判断するのは比較的簡単である。より重要なのは、副作用が禁止されていること (真の関数型言語では発生しない) を条件として、呼び出された関数のパラメータを同時に評価できることだ。これは事実かもしれないが、おそらくわずかなメリットしかないだろう。システムが並列処理を有効に利用できるより効果的な方法は、各オブジェクトが「プライベート」プロセスの形式で独自の動作を表すオブジェクト指向によって提供されると筆者は信じている。 。
ii. 論理プログラミング
プログラミング・パラダイムのもう一つの例として、論理プログラミングが広く注目されている。実は、このパラダイムを代表する言語として有名なものは1つしかない:Prologである。その主なアイデアは、変数への代入のような動作の指定を、状態に対する述語の指定に置き換えることである。述語のパラメータの1つまたはいくつかが未指定のままであれば、システムは述語を満たすすべての可能な引数値を探索する。これは論理文の解を探す検索エンジンの存在を意味する。このメカニズムは複雑で、しばしば時間がかかり、時には介入なしでは進めない。この介入の必要性は本質的なもので、この場合、ユーザーはヒント(カット)を提供することによってシステムをサポートしなければならず、したがって、何が起こっているのかを理解しなければならず、論理推論のプロセスを理解しなければならない。まさにそこを計算機にやらせるはずなのに。
興味深い知的エクササイズにすぎないものが、過大な期待を抱かされ、大衆に売り込まれたのではないか、と疑わざるを得ない。コミュニティは、より良い、より信頼性の高いソフトウェアを作る方法を切実に必要としており、万能薬ができるかもしれないと聞いて喜んだ。しかし、約束は実現しなかった。私たちは、日本の第五世代コンピュータのプロジェクト、Prologの推論マシンを煽った誇張された期待を、悲しみとともに思い出す。大量の資源がつぎ込まれた。それは賢明ではなく、今では忘れ去られたアイデアになっている。
iii. オブジェクト指向プログラミング
関数型プログラミングや論理プログラミングとは対照的に、オブジェクト指向プログラミング(OOP)は従来の手続き型プログラミングと同じ原則に基づいている。その特徴は命令型である。プロセスは、状態の変換のシーケンスとして記述される。新規な点は、グローバルな状態を個々のオブジェクトに分割し、状態変換(メソッドと呼ばれる)をオブジェクト自体に関連付けることである。オブジェクトはアクターとみなされ、メッセージを送ることで他のオブジェクトの状態を変化させる。オブジェクト・テンプレートの記述はクラス定義と呼ばれる。
このパラダイムは 「現実世界における」システムの構造を忠実に反映しているため、複雑な振る舞いをする複雑なシステムをモデル化するのに適している。驚くことではないが、OOPの起源はシステム・シミュレーション(Simula, Dahl and Nygaard, 1966)の分野にある。ソフトウェア・システム設計の分野での成功は、それを物語っている。そのキャリアはSmalltalk言語5で始まり、Object-Pascal、C++、Eiffel、Oberon、Java、C#と続いた。オリジナルのSmalltalkの実装は、その適性の説得力のある例となった。ウィンドウ、メニュー、ボタン、アイコンなど、上記の意味での(目に見える)オブジェクトの完璧な例を初めて提供したのである。これらの例は、成功と隆盛のきっかけとなった。アクターを直接モデリングすることで、プログラムの正しさを分析的に証明することの重要性が減少した。元の仕様が入力と出力の静的な関係ではなく、振る舞いの1つであるためだ(訳注:よくわからない)。
とはいえ、注意深い観察者は、新しいパラダイムの核心はどこに隠れているのだろう、従来のプログラミングの見方と本質的に何が違うのだろう、と思うかもしれない。結局のところ、手続き型プログラミングの古い基礎は、新しい用語に埋め込まれたとはいえ、再び登場する:オブジェクトはレコードであり、クラスは型であり、メソッドは手続きであり、メッセージを送信することは手続きを呼び出すことと同じである。確かに、レコードはデータ・フィールドに加えてメソッドで構成されるようになった。また、継承と呼ばれる機能によって、ヘテロジニアスなデータ構造を構築できるようになった。これらはオブジェクト指向と無関係に有用である。この用語の変更は、本質的なパラダイムシフトを表現しているのだろうか、それとも注目を集めるための手段、「売り込みの手口」だったのだろうか?
7. おわりに
計算機科学の広い範囲から生まれ、当時広く称賛されたアイデアのコレクションを紹介した。様々な理由から、詳しく調べてみると、なんらかの弱点が明らかになった。いくつかのアイデアは、基礎となる技術の変化や進歩により、現在ではほとんど意味をなさないものであり、他のいくつかは、もはや重要ではない局所的な問題を解決する巧妙なアイデアであった。
私たちは、時の彼方にあるアイデアを分析することで、さらに多くのことを学ぶことができると信じている。悪いアイデアや過去の失敗からだけでなく、良いアイデアからもである。このトピック集は偶然に見えるかもしれないし、確かに不完全である。また、計算機科学は、より頻繁な分析、批判、特に自己批判から恩恵を受けるだろうという思いにより、一個人の視点から書かれている。結局のところ、徹底的な自己批判は、科学であることを主張するあらゆるテーマの特徴である。
参考文献
原文筆者のアドレス
Niklaus Wirth, Langacherstr. 4, CH-8127 Forch Switzerland wirth@inf.ethz.ch
訳者より
「問題は、多くの場合、ツールを構築して理解するために多大な労力を費やし、そのツールが「価値のある」ものになった後でのみ、そのツールの不適切さに気づくことだ」を実行してしまったのではないかと思うRISCかな配列をご賞味ください。
-
P. Naur (Ed). Report on the Algorithmic Language ALGOL 60. Comm. ACM 3 (May 1960), 299-314. ↩
-
D. E. Knuth. The Remaining Trouble Spots in ALGOL 60. Comm. ACM 10 (Oct. 1967), 611-618. ↩
-
N. Wirth. Programming in Modula-2. Springer-Verlag, 1982. ↩
-
J. McCarthy. Recursive Functions of symbolic Expressions and their Computation by Machine. Comm. ACM 5, (1962) ↩
-
A. Goldberg and D. Robson. Smalltalk-80: The Language and its Implementation. Addison-Wesley, 1983. ↩