こちらの記事は Houdini Advent Calendar 2023 21日目の記事です。
はじめに
Advent Calendar初参加です、よろしくお願いいたします。
皆さんはStable Diffusionのような画像生成AIを使用したことがあるでしょうか? 画像生成AIは主にWebUIで操作するのが主流になっていると思いますが、いろんな設定パターンで大量に画像を生成したり、複数の生成工程を組もうとするとプログラムによって管理したくなります。
本記事はPDGでStable Diffusion(Diffusers)を使用する方法について紹介します。それと最後に、最近流行りのMagicAnimateを使用して生成した画像を動かすところまでやってみます。
最終的にこんな感じになります。

仮想環境の構築
はじめに仮想環境を構築して、AI画像生成ライブラリのdiffusersをインストールする必要があります。
Houdini 20.0からPython Virtual Environment TOPが追加されていたので、使用してみます。
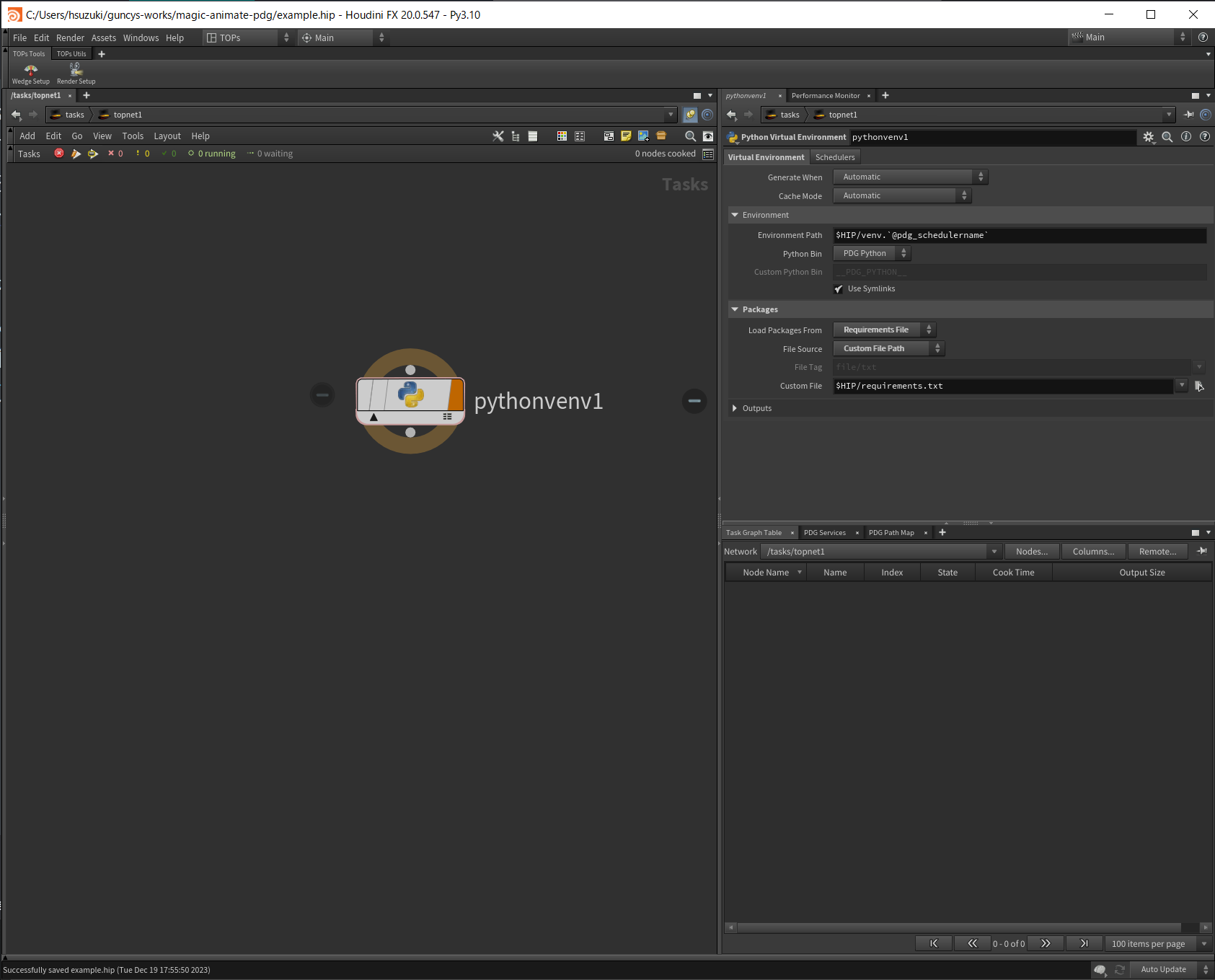
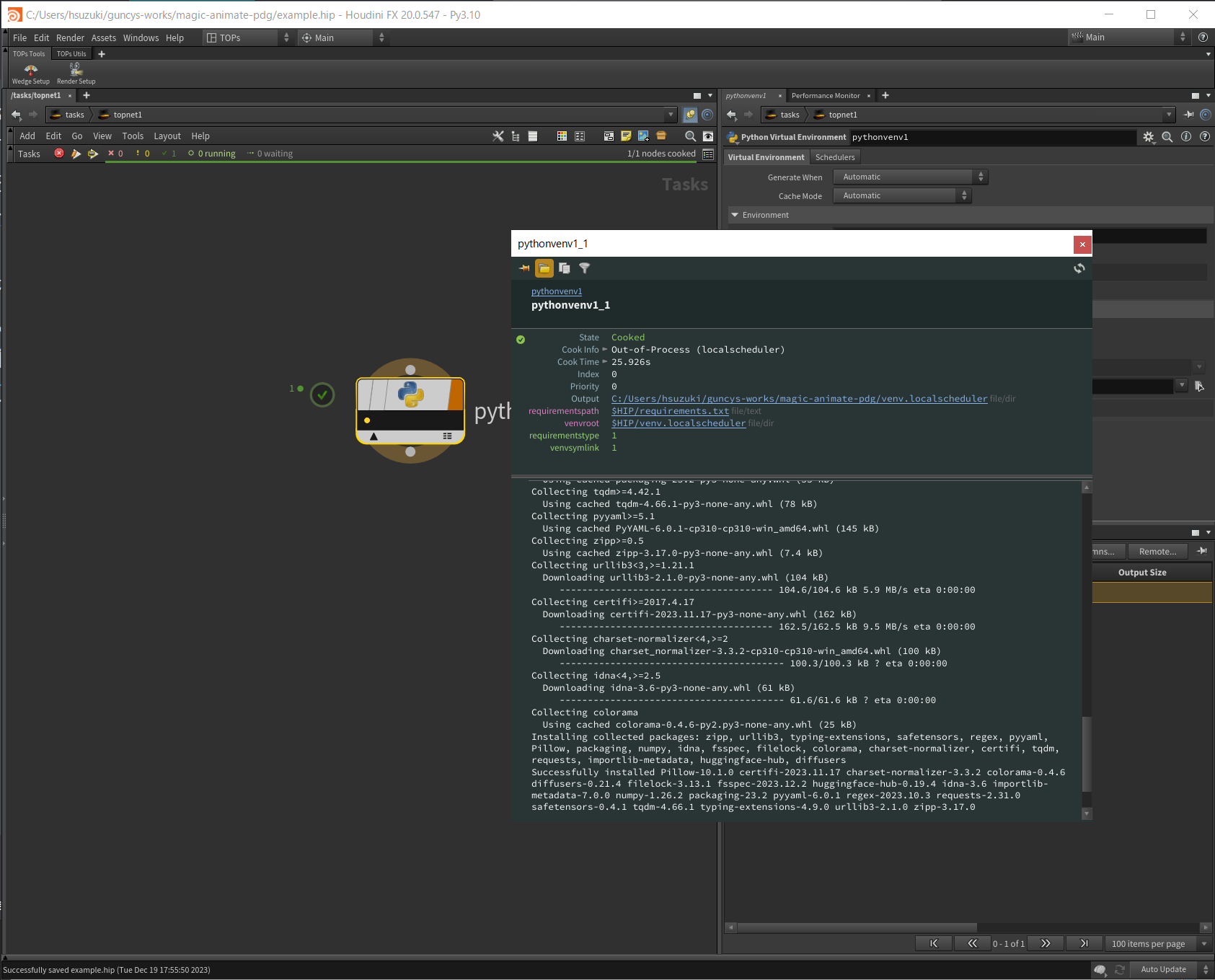
requirements.txtで必要なライブラリを指定します。
--extra-index-url https://download.pytorch.org/whl/cu118
accelerate==0.22.0
diffusers==0.21.4
huggingface-hub==0.16.4
omegaconf==2.3.0
transformers==4.32.0
torch==2.0.1
ノードをクックすることで、仮想環境が構築され必要なパッケージがインストールされるようです。
TOPs上で画像生成する
ここからは実際にdiffusersライブラリを使用して画像生成を行います。
Python Script TOPでdiffusersライブラリを動かしてみます。
Python BinをVirtual Environmentにすることで先ほどの仮想環境下でpythonを実行してくれます。
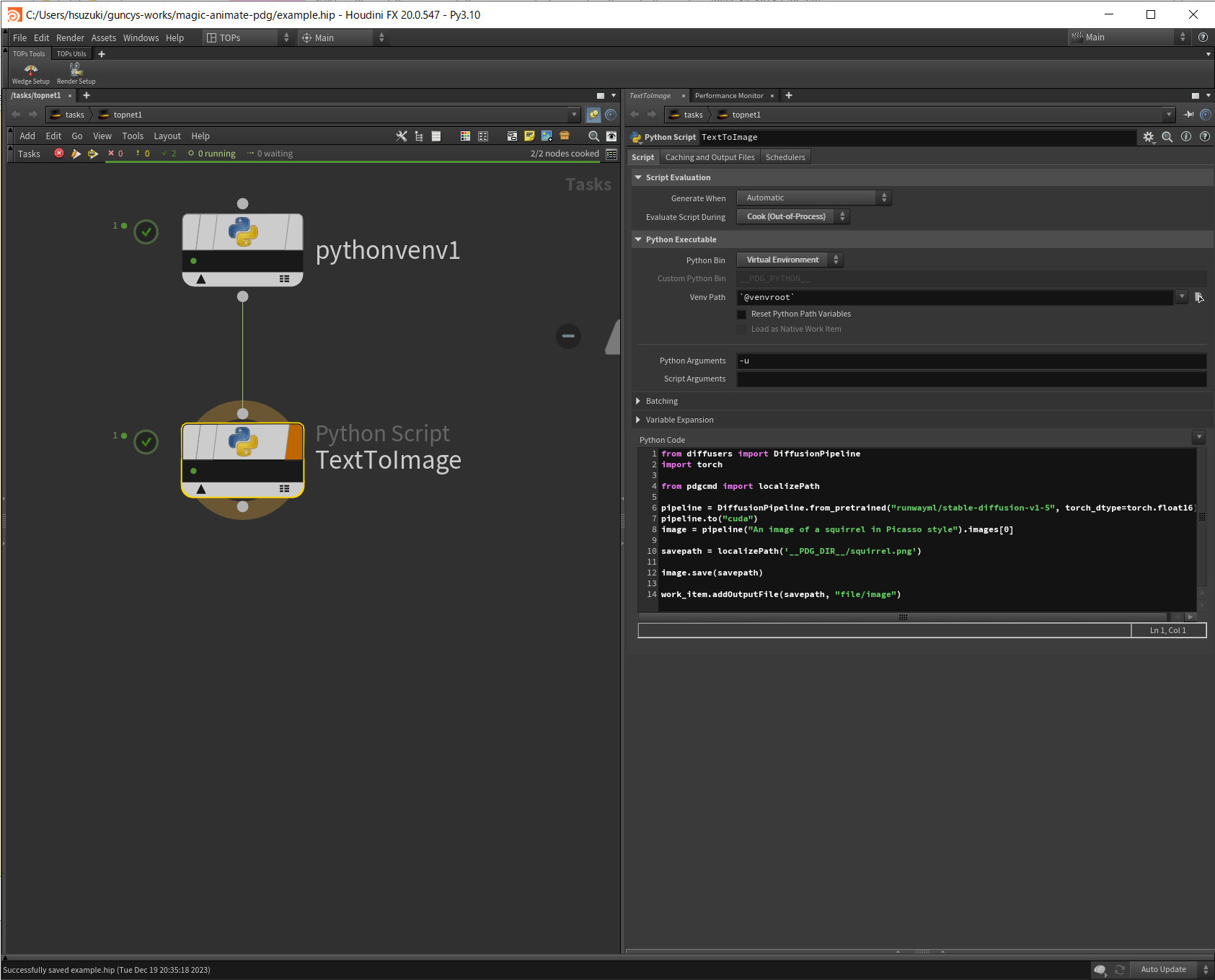
Codeはdiffusersのサンプルコードをもとに実装しています。
from diffusers import DiffusionPipeline
import torch
from pdgcmd import localizePath
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline.to("cuda")
image = pipeline("An image of a squirrel in Picasso style").images[0]
savepath = localizePath('__PDG_DIR__/squirrel.png')
image.save(savepath)
work_item.addOutputFile(savepath, "file/image")
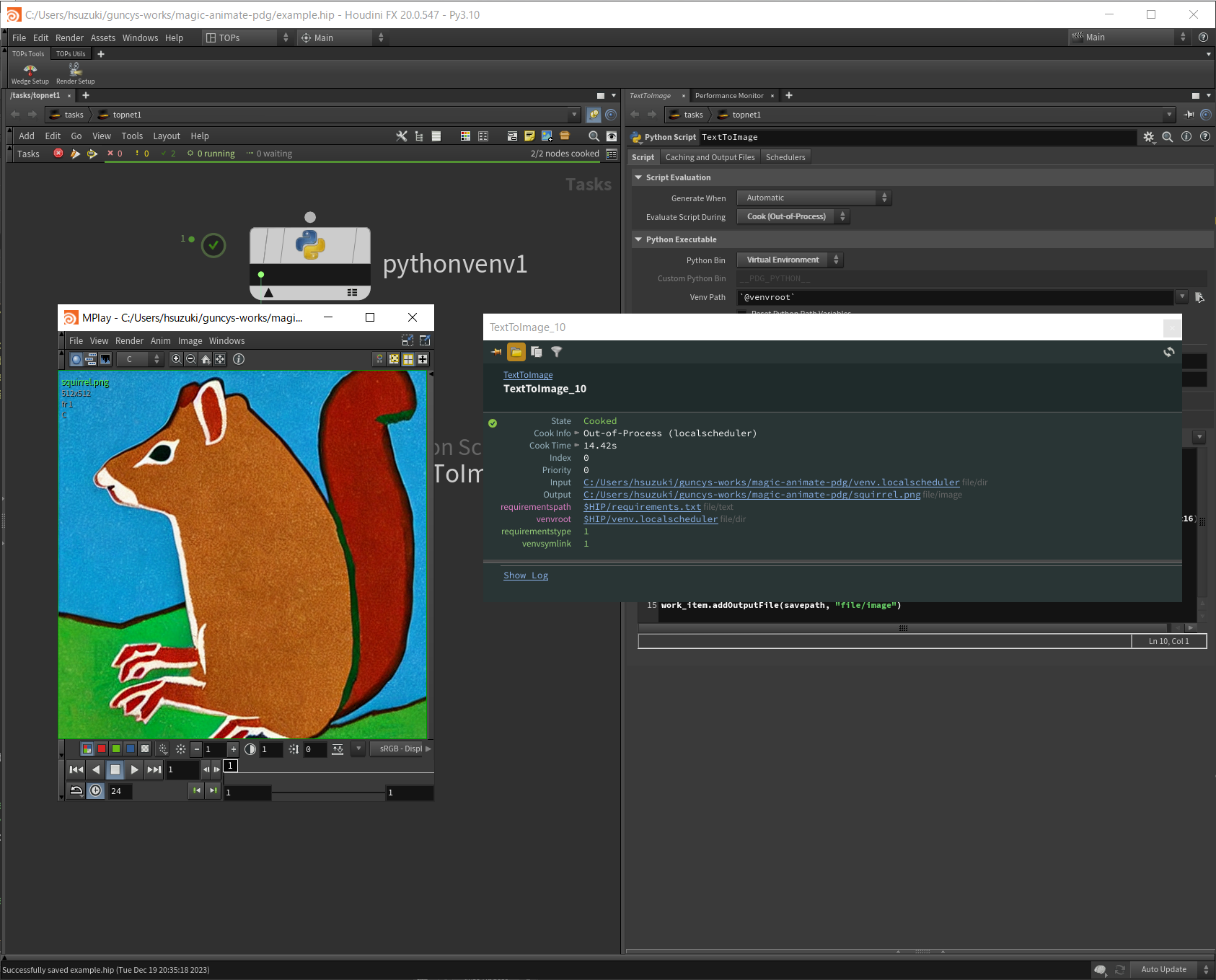
ノードをクックすると画像が生成されます。ワークアイテムのOutputから画像を確認できます。ここではpython上で指定したピカソ風のリスの画像が出力されました。
Civitaiのカスタムモデルを使用する
ひとまず、PDG上で画像生成を行うことができました。最後に行うMagicAnimateでは人の画像からアニメーションを生成するため、ここからはカスタムモデルを使用して元となる女の子の画像を生成していきたいと思います。
Civitaiはstable diffusionのモデルを共有するサイトです。カスタムモデルを使用することでよりハイクオリティな画像を生成できます。
ただし、後述しますがdiffusersから使用するには少し工夫が必要になります。
まずはCivitaiからモデルファイルをダウンロードします。本記事ではmajicmix-realisticというモデルを使用します。
TOPsからはFile Pattern TOPで取得します。
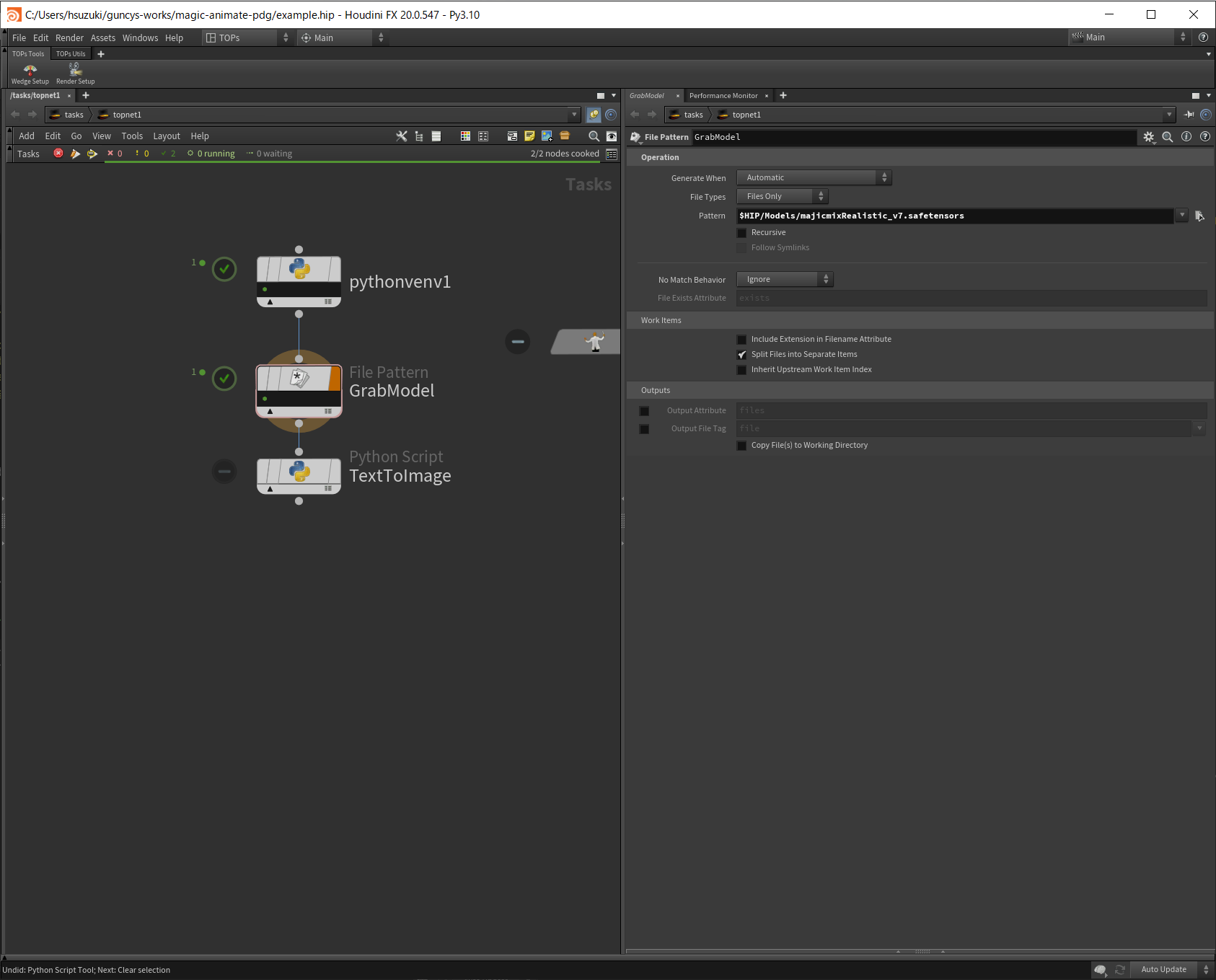
ダウンロードしたモデルファイルはこのままでは使用できません。
.safetensorsファイルで配布されるため、diffusersパッケージから使用できるように変換する必要があります。
変換用のスクリプトはdiffusersのGithubレポジトリで提供されているため、参考にしてPython Script TOPを作成します。
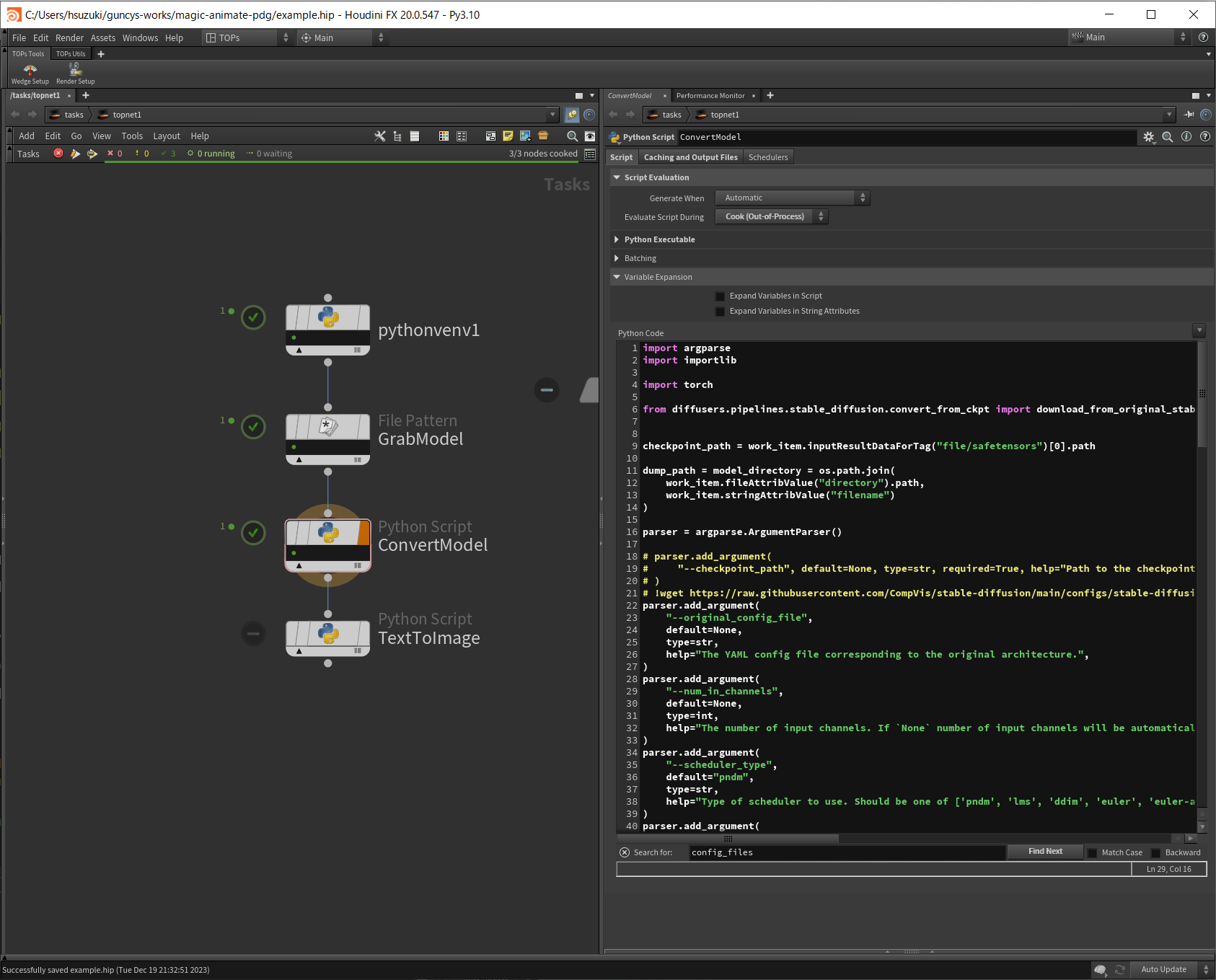
ノードをクックするとModels/majicmixRealistic_v7/フォルダー以下に変換後のモデルファイルが保存されます。
Houdini上で変換したカスタムモデルを読み込んで画像生成を行います。
一枚の画像生成を行う場合は先ほどと同じPython Script TOPで十分ですが、せっかくPDGを使用しているのでseed値違いで複数の画像を生成したいです。
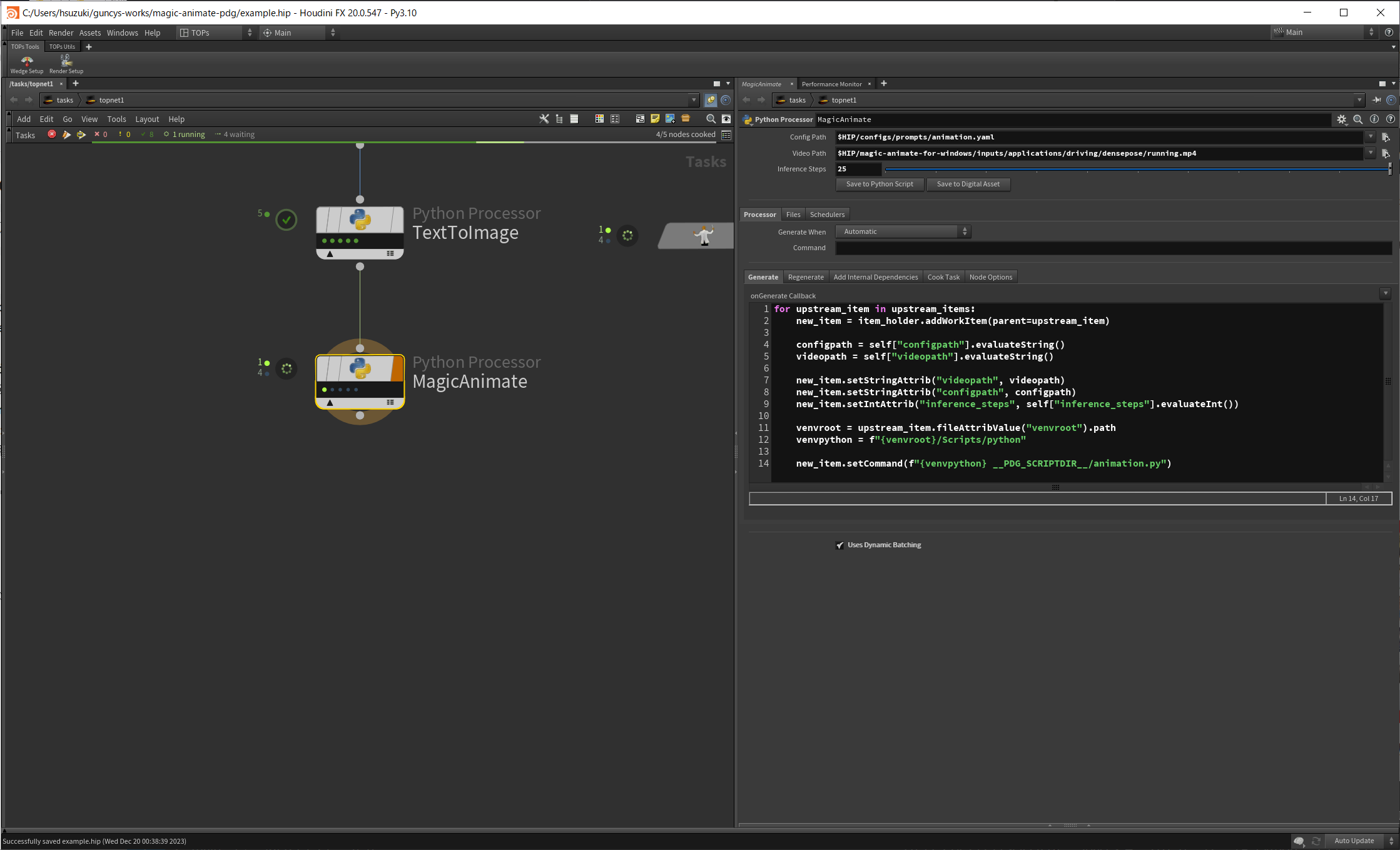
Python Processer TOPを使用してBatch Sizeパラメーターで指定した数だけワークアイテムを生成して画像生成を行います。
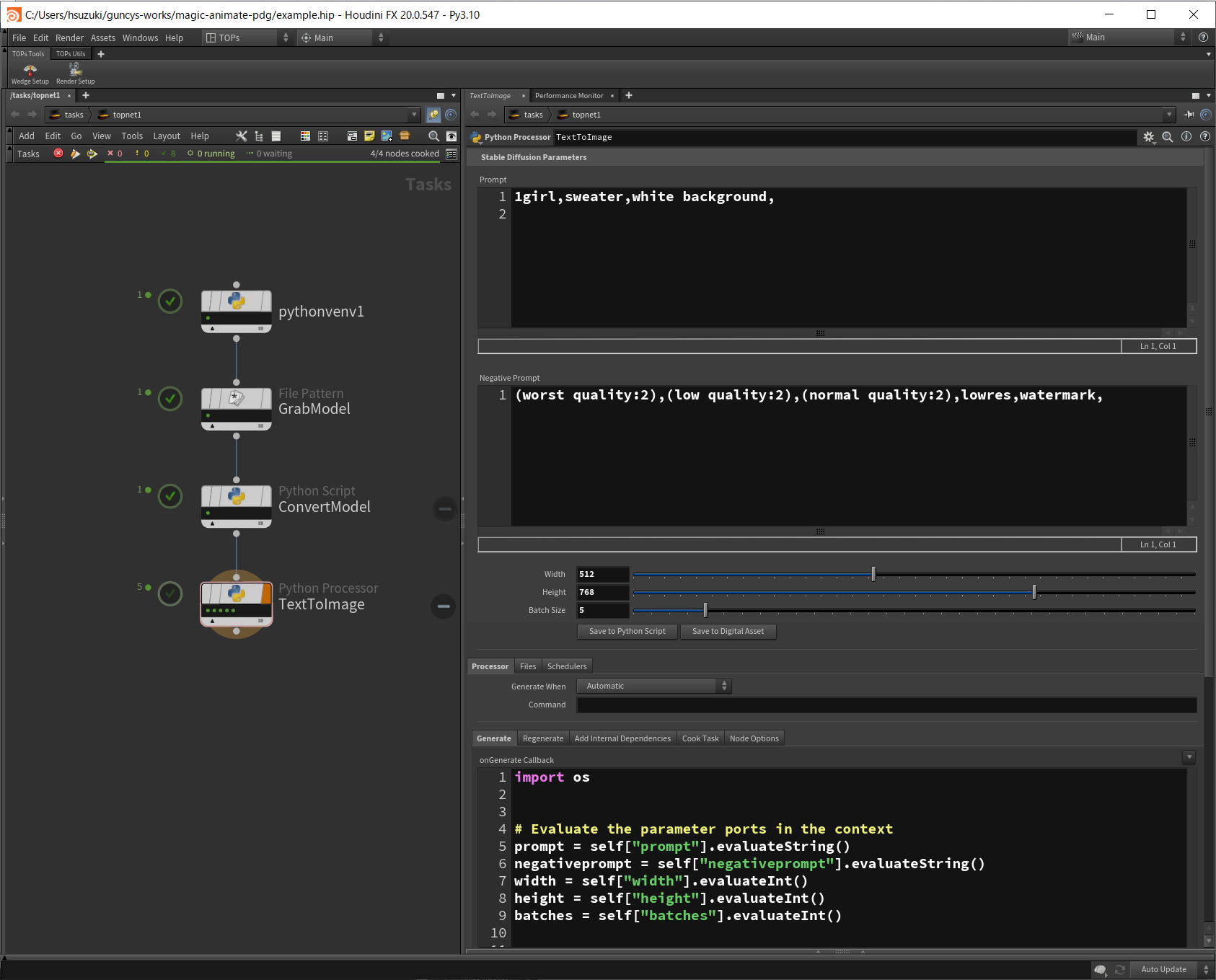
Python Processer TOPではPython Script TOPのようにノードのインターフェースから仮想環境を指定できません。
Generate Callback中でwork_item.setCommand()を仮想環境のPythonからワークスクリプトを実行するように指定します。
# Evaluate the parameter ports in the context
prompt = self["prompt"].evaluateString()
negativeprompt = self["negativeprompt"].evaluateString()
width = self["width"].evaluateInt()
height = self["height"].evaluateInt()
batches = self["batches"].evaluateInt()
for upstream_item in upstream_items:
venvroot = upstream_item.fileAttribValue("venvroot").path
venvpython = f"{venvroot}/Scripts/python"
for idx in range(batches):
new_item = item_holder.addWorkItem(index=idx, parent=upstream_item)
new_item.setStringAttrib("prompt", prompt)
new_item.setStringAttrib("negativeprompt", negativeprompt)
new_item.setIntAttrib("width", width)
new_item.setIntAttrib("height", height)
new_item.setCommand(f"{venvpython} __PDG_SCRIPTDIR__/text_to_image.py")
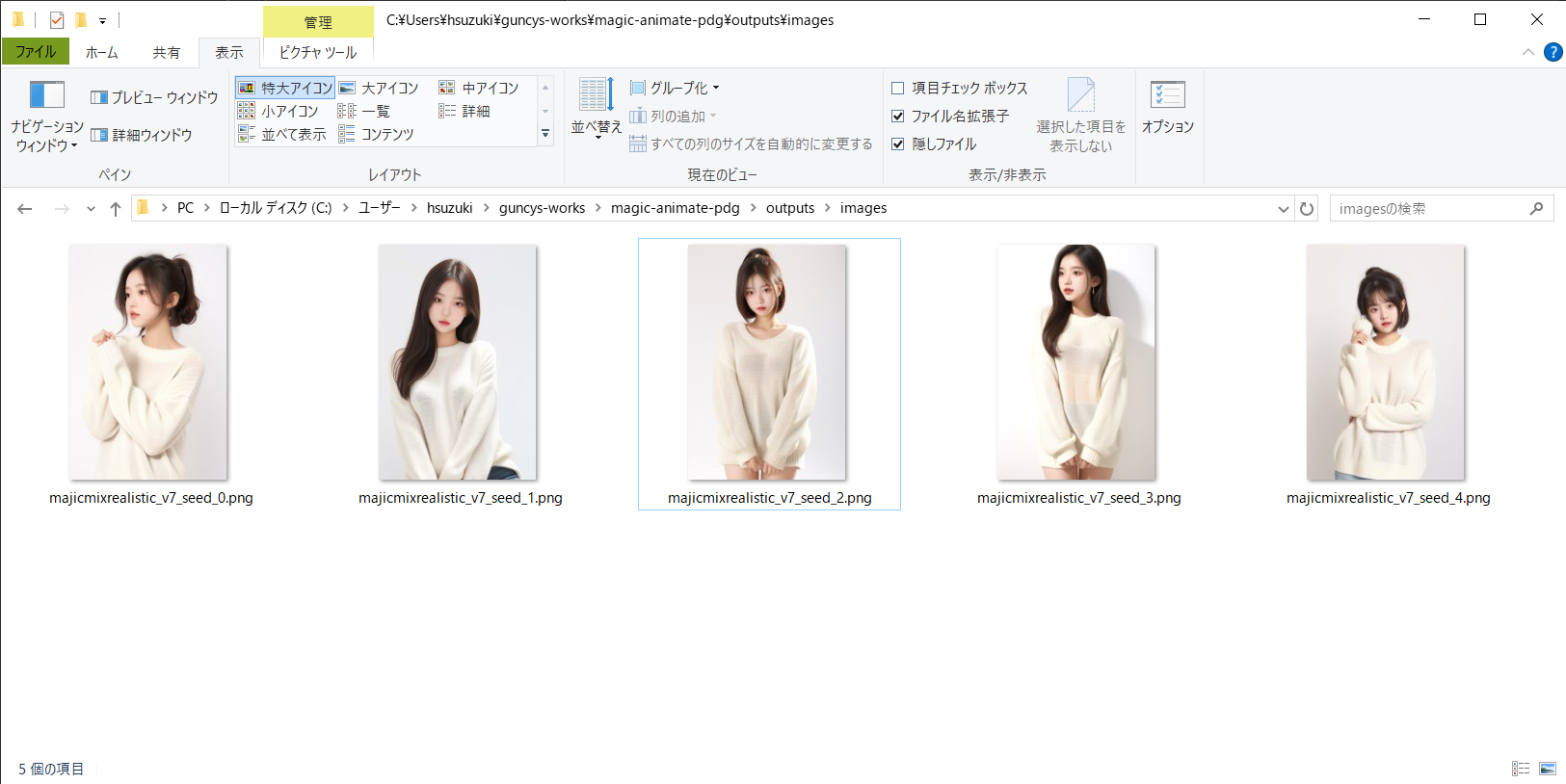
ノードをクックすることで複数の画像が生成されました。
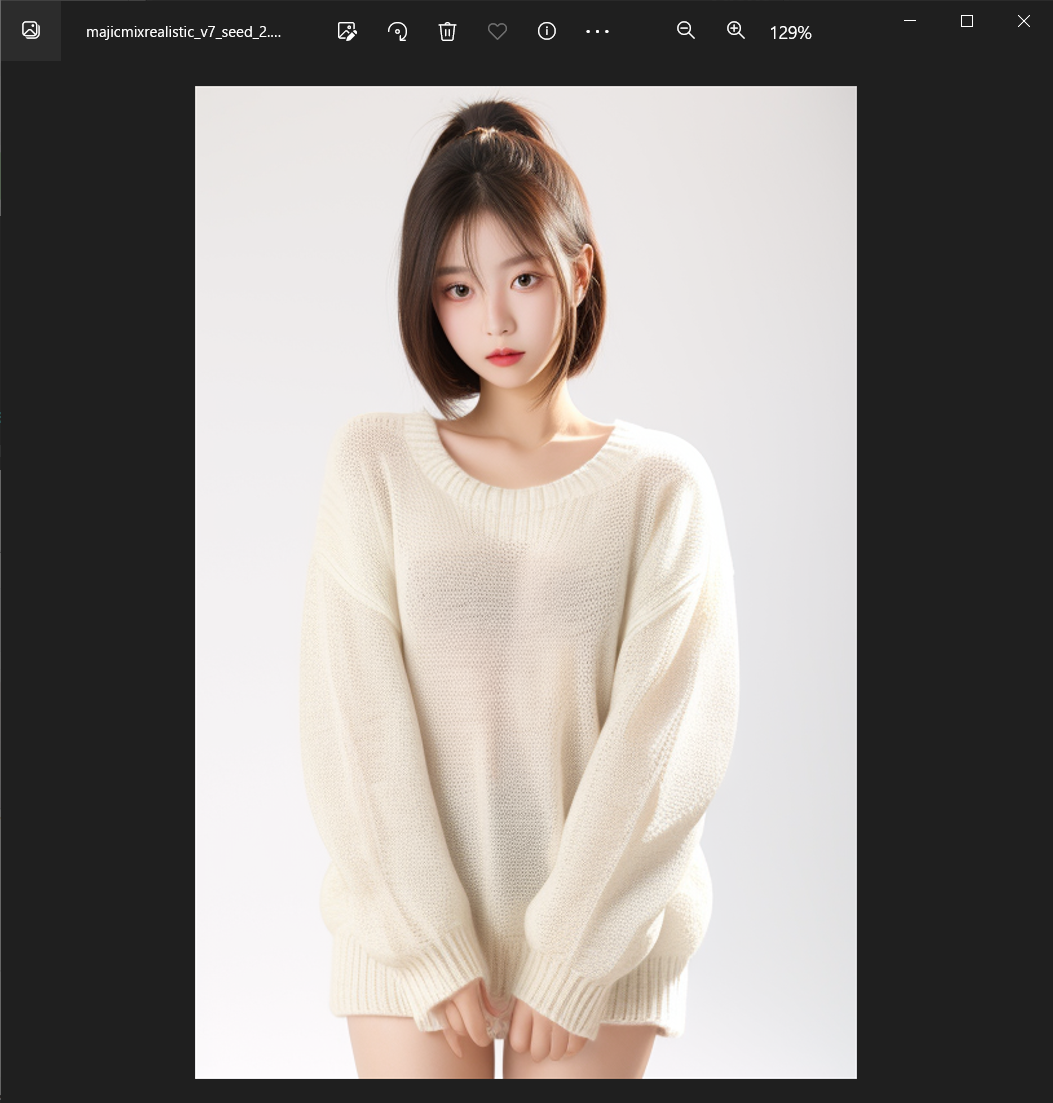
MagicAnimateで画像を動かす
上で生成した画像をさらにMagicAnimateで動かしてみます。
MagicAnimateにはWindows版のフォークがあるのでそちらを使用します。
Readmeのインストールの手順に従ってインストールを行ってください。
Python Processer TOPで先ほど生成した画像から動画を生成するよう実装します。
クックが完了するとOutputから動画を確認できます。
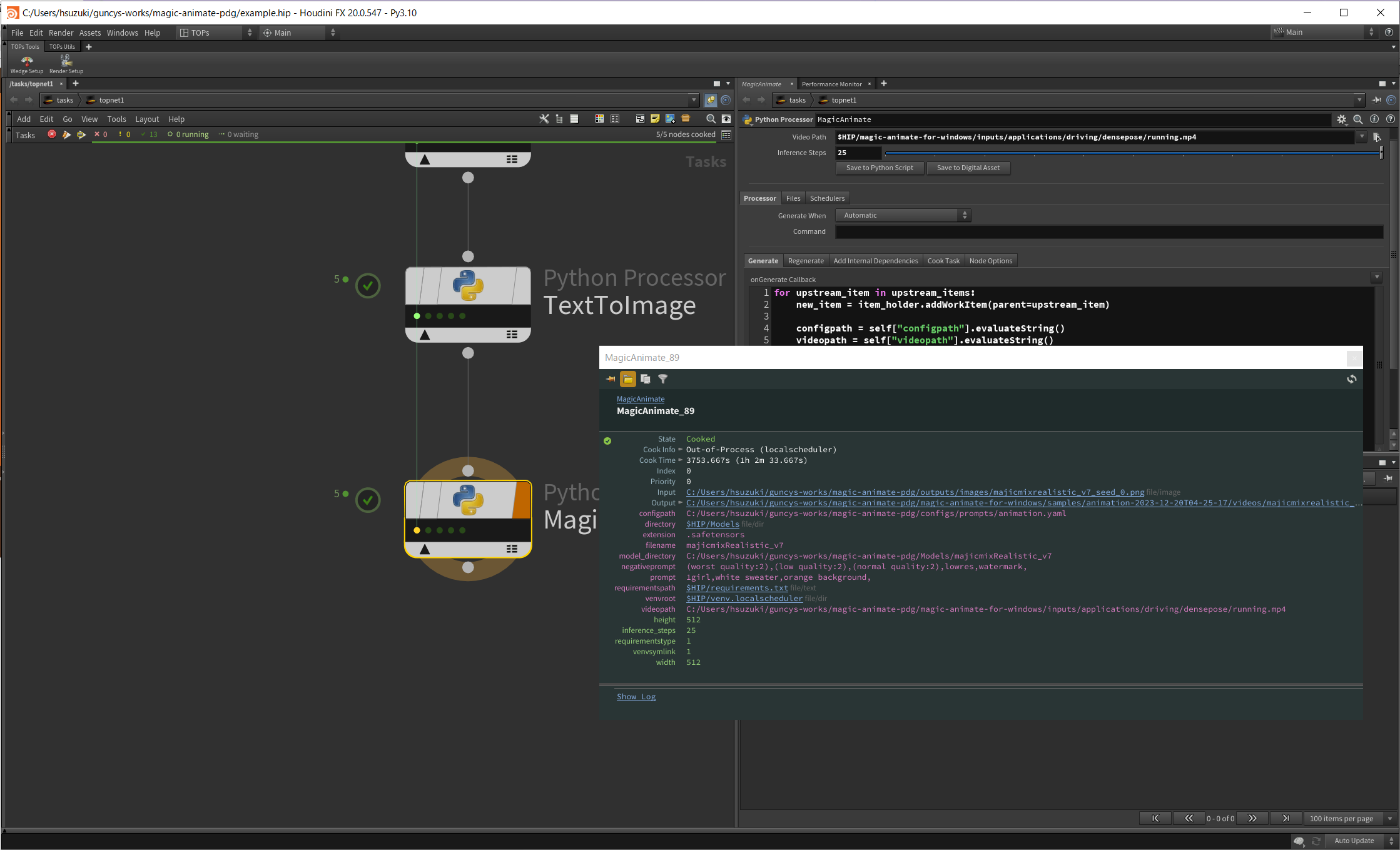
若干目の部分などおかしいですが走っているアニメーション動画を生成できました。


さいごに
diffusersをPDG上で使う方法についてでした。
- カスタムモデルの変換
↓ - 画像生成
↓ - アニメーション生成
のフローをPDGで作ってみました。ここからさらに、
- 複数モデルから画像を出力する
- Wedge TOPによってプロンプトテキスト、ステップ数などにバリエーションを作る
- アニメーションソースを複数にする
など、いろいろとカスタマイズすることができそうです。
MagicAnimateは重すぎて、自分の環境では本記事のデモを動かすだけでめちゃめちゃ時間がかかりました。。
あと本題とは関係ないですが、記事を書きながら初めてPython Vertual Environment TOPを使いました。Houdini上で仮想環境のセットアップから行えるのはかなり便利でした。