はじめに
S3でのコンテンツ配信はクロスリージョンレプリケーション(CRR)を利用することで、比較的安易にマルチリージョン構成によるDR環境を構築可能です。本記事では、CloudFront+S3でWebサイトを提供する環境を前提に、CRRとCloudFront OriginFailoverを利用したマルチリージョン構成の構築例を記載します。
本記事で説明する内容
- CRRとOriginFailoverによるマルチリージョン構築時の検討ポイント
- CRRの設定方法
- OriginFailoverの設計ポイントと設定方法
- OriginFailoverの動作確認方法
- 複数のCloudFrontによるマルチリージョン構成が実現できない理由
想定読者
- CloudFrontとS3でWebサイトやSPAのホストを行っている方
- AWSのマルチリージョン化を簡単に試してみたい方
- CloudFront OriginFailoverやCRRの設定方法を知りたい方
マルチリージョン化対象の構成
下記の構成でWebサイトを提供しているシステムにおいて、マルチリージョン構成をどのように実現できるかを考えます。
- Clientからはカスタムドメインでアクセス
- CloudFront+Amazon S3でWebサイトをホスト
- S3へのアクセスはOACを利用して制御

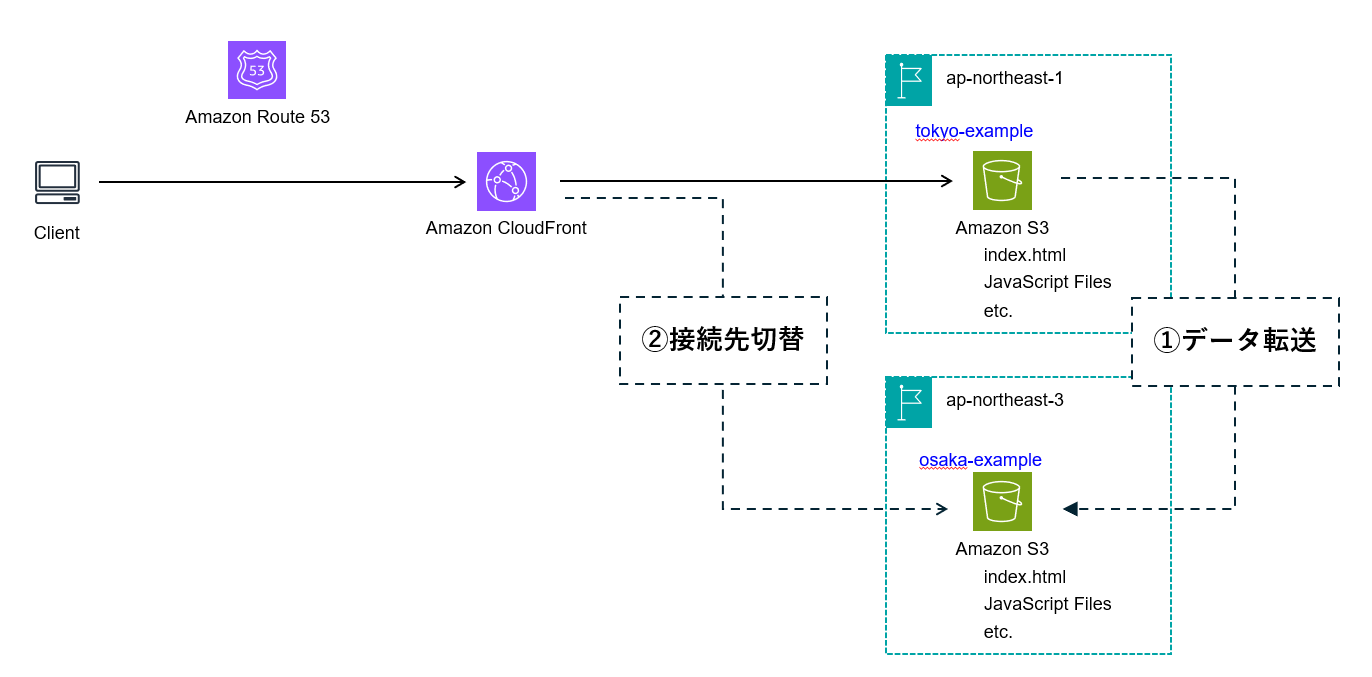
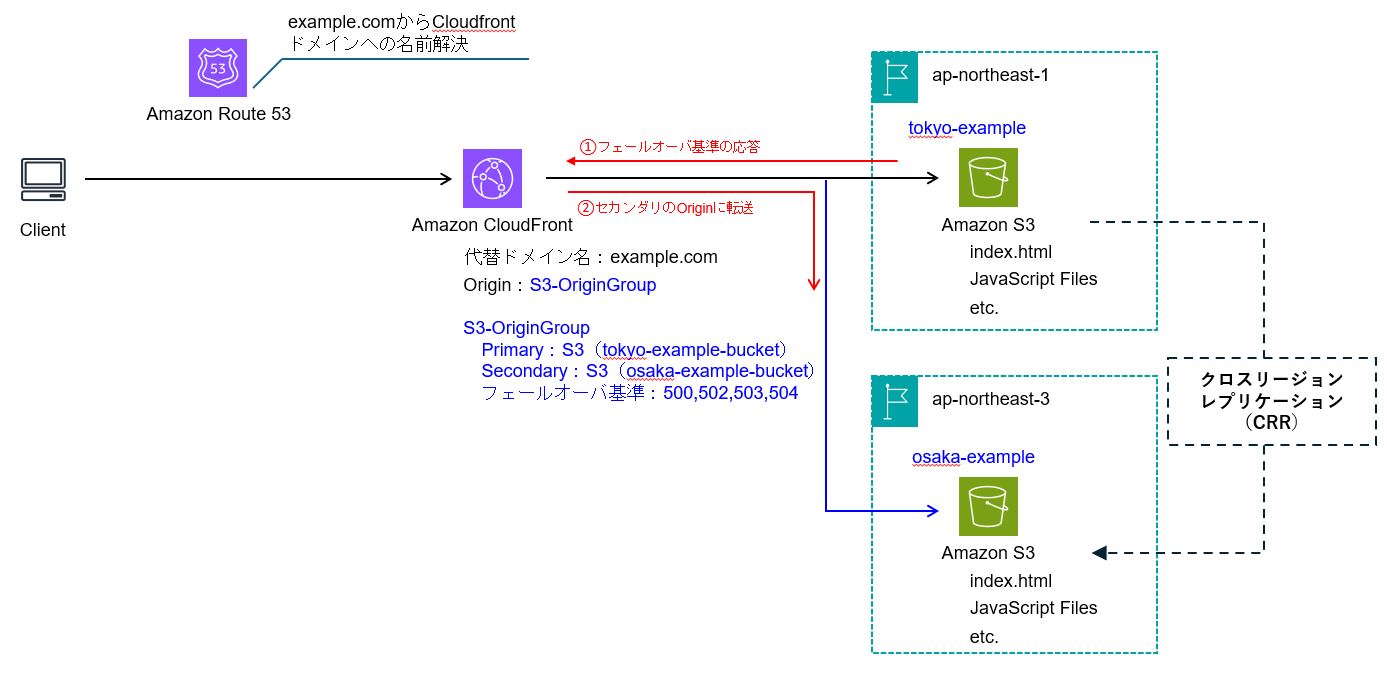
マルチリージョン化の構成イメージ
①データ転送の後に②接続先切替を行うことで、マルチリージョン化を実現します。本記事では①のデータ転送にCRRを利用し、②の接続先切替にOriginFailoverを利用します。また、東京をプライマリリージョン、大阪をセカンダリリージョンとしています。
マルチリージョン構成でのDR方針の考慮点
マルチリージョン構成においてDR戦略をどのように考えるかは非常に重要です。本章では、CloudFront+S3構成におけるDR方針のポイントについて記載します。DR戦略の詳細については記載しませんので、検討の際には下記のドキュメントをご参照ください。
①データ転送や②接続先切替の実現方法について確認したい方は本章を飛ばしてください。
DR環境を構築する際には、RPO,RTOやコストに基づいて、バックアップリストアやウォームスタンバイ、ホットスタンバイなどの構成を検討します。通常、EC2などのサーバは、起動時間に応じてコストがかかるため、このコストが構成の検討に影響します。しかし、CloudFront+S3の構成では、コンテンツをS3に配置するのみでWebサイトを提供することができるためサーバの起動時間の考慮は不要です。
CloudFront+S3のマルチリージョン構成での検討ポイント
RPOをどのように調整するか
プライマリリージョンのS3のデータは、CRRで別リージョンのバケットにレプリケーションされ、このレプリケートの時間がRPOに直結します。通常、PUTされたオブジェクトは非同期に転送され、ほとんどのオブジェクトは15分以内にレプリケートされますが、場合によっては数時間以上かかる場合があります。厳格な要件があるときはS3 Replication Time Control(S3 RTC)を利用することで15分以内に99.9%のデータ転送を行うことができます。
本記事では、RPOへの対応としてS3 RTCを利用した構成で構築を行います。
S3のデータ削除についてのリカバリを対象とするか
この方針に沿って、後述のCRRやOriginFailoverの設計が変わります。誤操作によるデータ削除に対しても復旧できるようにする場合は、次の二つを考慮する必要があります。
-
CRRで削除マーカーのレプリケーションを無効化
削除マーカーのレプリケーションを無効にすることで、プライマリリージョンのバケットで誤ってデータを削除しても別リージョン側のデータは削除されなくなります。
#バージョニングをしているためプライマリリージョンのデータも復旧可能です。 -
OriginFailoverのトリガーに5xxエラーだけではなく4xxエラーも追加
OriginFailoverのトリガーは、4xxエラーと5xxエラーから必要なものを指定します。誤ってファイルが削除されたことをトリガーにFailoverする場合は、4xxエラーを対象とする必要があります。
#OAC設定時はファイルが存在しない場合も403エラーとなります。
本記事では、誤操作のデータ削除によって切り替わりが発生することで誤操作に気づけなくなることを考慮し、データ削除系の4xxエラーは切り替えの対象に含めません。
データ転送:CRRによるリージョン間のレプリケーション
S3のCRRは、異なるリージョンのAmazon S3バケット間でオブジェクトを自動で非同期的にコピーする機能です。CRRを利用することで、複数のリージョンにS3オブジェクトのバックアップを作成することができます。
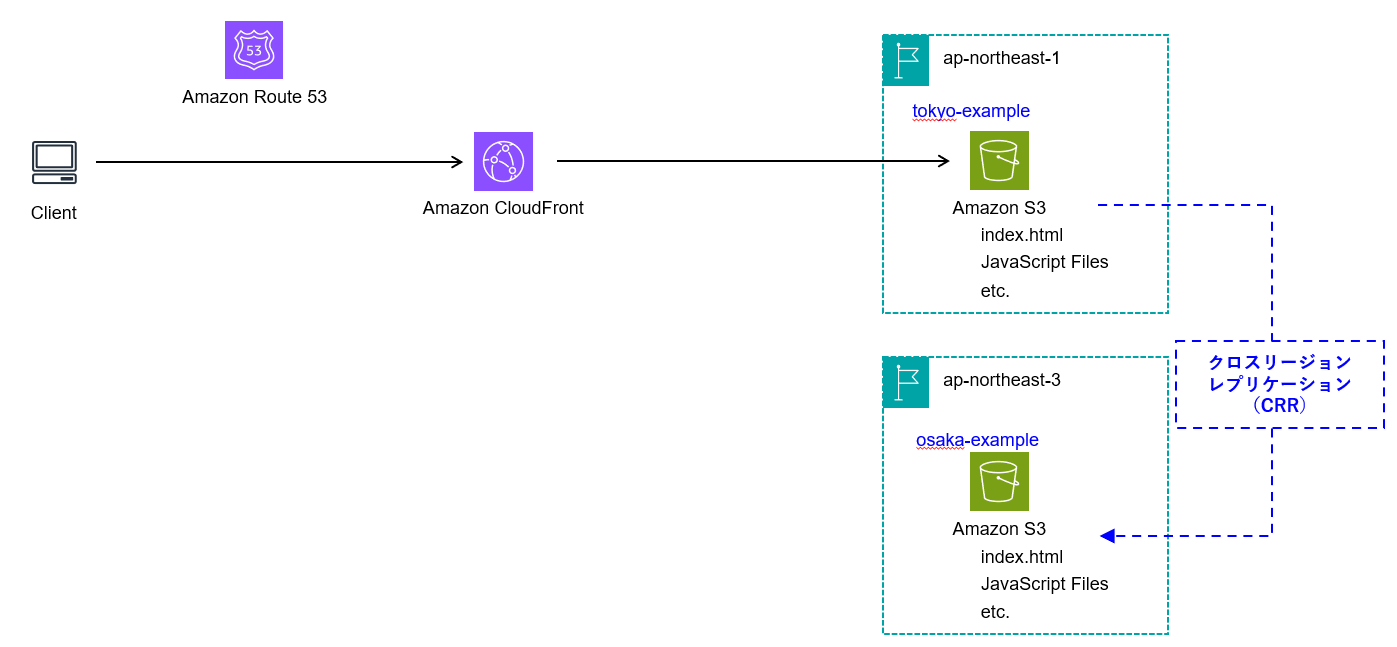
CRRに関するドキュメントは以下になります。
CRRの利用には、宛先として選択したS3ストレージクラスのストレージのS3料金、プライマリコピーのストレージの料金、レプリケーションPUTリクエストの料金、および該当する低頻度アクセスストレージの取得料金と、S3から各送信先リージョンへのリージョン間データ転送OUT料金がかかります。詳しくは、下記をご確認ください。
CRRの構築手順
CRRを構築する手順を示します。
-
送信元のバケットと送信先のバケットの決定(送信元:東京→送信先:大阪とします。)
-
送信元と送信先のバケットでバージョニングの有効化
バケットのバージョニングの編集をクリック(東京・大阪リージョンで実施)
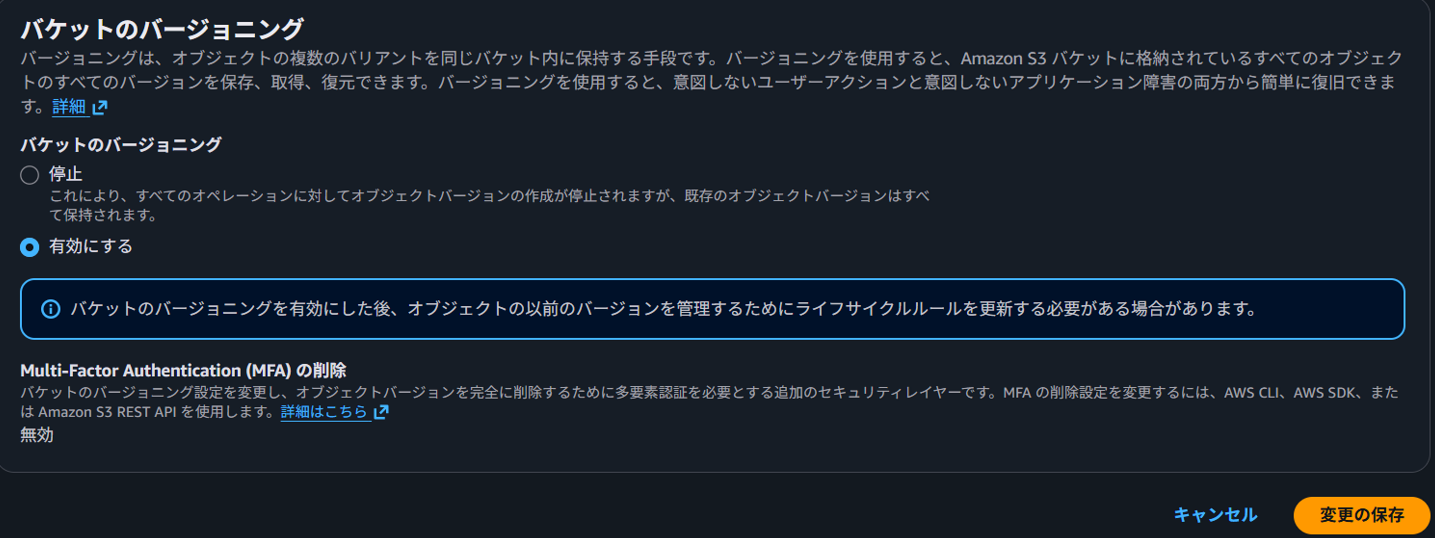
バケットのバージョニングを有効にするを選択し、変更の保存をクリック
-
送信元のバケットでレプリケーションを設定
- レプリケーションルール名を設定してステータスを有効化
- ソースバケットからCRRを適用するスコープを決定
- 送信先のバケットを設定
- IAMロールを設定(自動で作成されたロールを利用します。)
- 暗号化(KMSで暗号化されたオブジェクトをレプリケートする場合は選択します。)
- 送信先ストレージクラス(バックアップとして利用するため変更は行いません。)
- RTCを選択(RPO要件によって利用有無を決定します。[後述])
- 削除マーカーのレプリケーション(オブジェクトの削除もレプリケートするかで決定します。[後述])
- レプリカ変更の同期(レプリカ側のメタデータ更新を送信元に同期する場合に利用します。レプリカ側のメタデータを更新することは無いため、今回は利用しません。)

-
バッチオペレーションによるレプリケート
既存で配置されているオブジェクトのレプリケートを行う場合は、バッチオペレーションジョブを有効にしてレプリケートを行います。

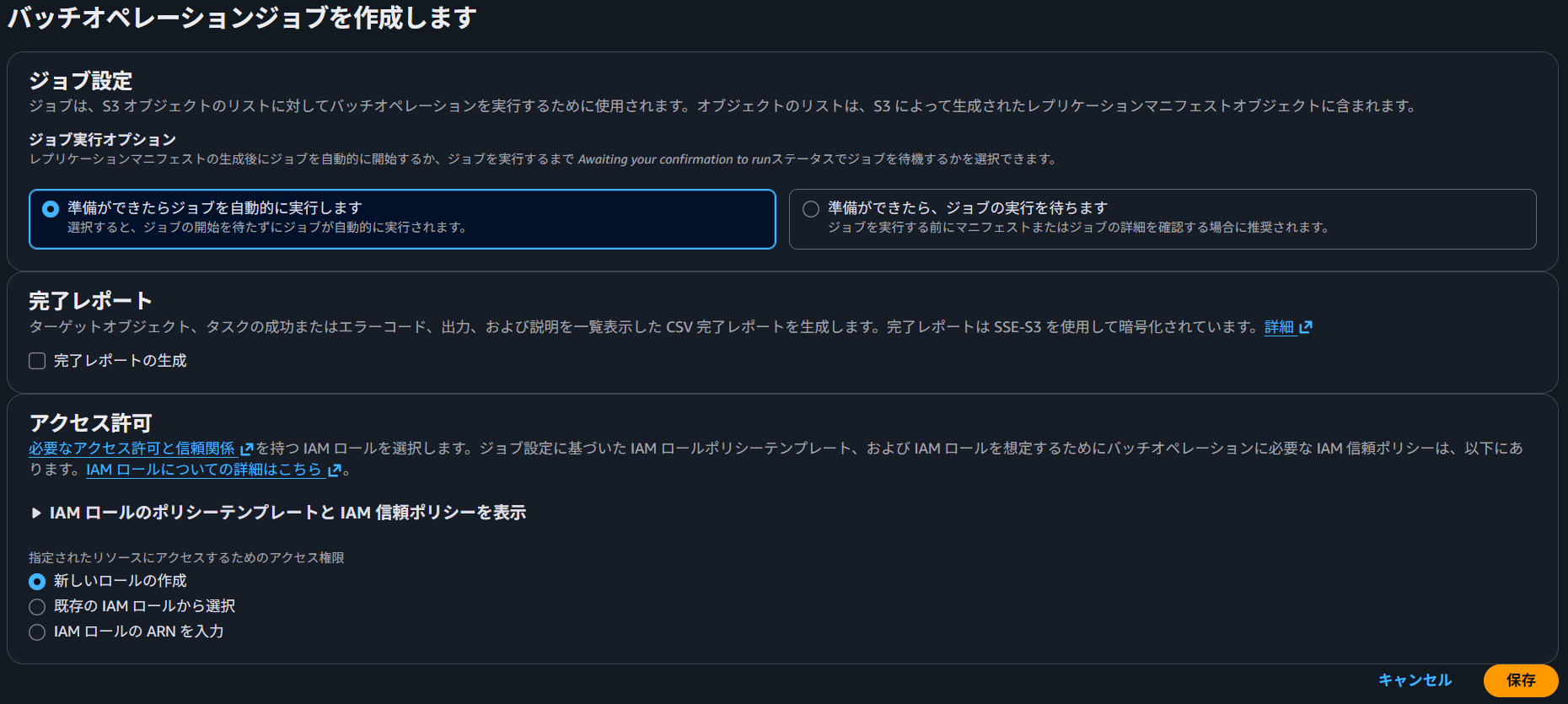
以上でCRRの設定は完了です。バケットにファイルをPUTしてレプリケートされるかをご確認ください。
マルチリージョン構成時のCRRの設計ポイントの一例
S3 RTCの利用有無
CloudFront+s3のマルチリージョン構成での検討ポイントで記載しましたが、RPO要件に基づいて、S3 RTCの利用を検討します。S3 Replication Time Control(S3 RTC)を利用することで、新規に登録されたオブジェクトの99.9%を15分以内にレプリケートできます。つまり、SLA99.9で、RPO15分を実現できることになります。
また、レプリケーションが 15 分のしきい値を超えた場合に、AmazonS3から通知を受け取ることができます。通知を受け取る動作の確認はできておりませんが、通知に基づいた対策を行うことでRPOに更に厳密に対応できると考えられます。
RTCを利用する場合、追加のデータ転送料金とAmazonCloudWatchカスタムメトリクスと同じレートで課金されるS3レプリケーションメトリクス料金が必要になります。
データ削除のレプリケート有無
東京リージョン(プライマリ)のS3でのデータ削除を大阪側にも反映するかどうかを決定します。東京側で誤って削除した際に、大阪側に切り替えることでRTOを短く復旧させる場合は、大阪側のデータを残しておいたほうが有用です。代わりに、誤って削除したことに気づけなくなる可能性があります。
個人的な考えとなりますが、データ削除などの誤操作は対象外とし、リージョン障害などに限定しておくことでバケットの整合性が取れるため、削除マーカーのレプリケートは有効化することを推奨します。その場合は、データのリカバリ方法の整理と、DR要件として誤操作は切替対象外とすることを合意しておく必要があります。
大阪から東京へのレプリケーション(双方向レプリケーション)の有無
東京から大阪へのレプリケートに加え、大阪から東京へのレプリケートを行うかどうかも検討のポイントになります。通常は東京リージョン側のみで操作を行い大阪側に反映すると思いますので、この設計のポイントは、東京リージョン障害で大阪に切り替わった状態で、大阪のS3に追加作業が入るかどうかです。リージョン障害時は、リリース作業を行わないなどの運用ルールを決めておけば不要かと思いますので、DR要件と合わせて整理が必要です。
実装する場合は、大阪側で東京と同様にレプリケートの設定を行います。
接続先切替:CloudFront OriginFailover構成 (Active/Standby)
CRRでデータのレプリケートを行いましたので、障害時の接続先切替について記載します。
CloudFrontのOriginFailover構成はCloudFront+S3をマルチリージョンとする場合の一番シンプルな切替構成であり、まずはこの構成の利用を検討いただくことを推奨します。
2つのOriginをOriginGroupとして登録し、プライマリ側のOriginから特定の応答コードがあった場合に、セカンダリ側のOriginに転送する動作となります。
OriginFailoverの構築手順
OriginFailover構成の構築手順を記載します。
-
CloudFrontのOriginとして
ap-northeast-1のS3とap-northeast-3のS3を登録(本構成では、S3へのアクセス制御としてOACを利用します。)
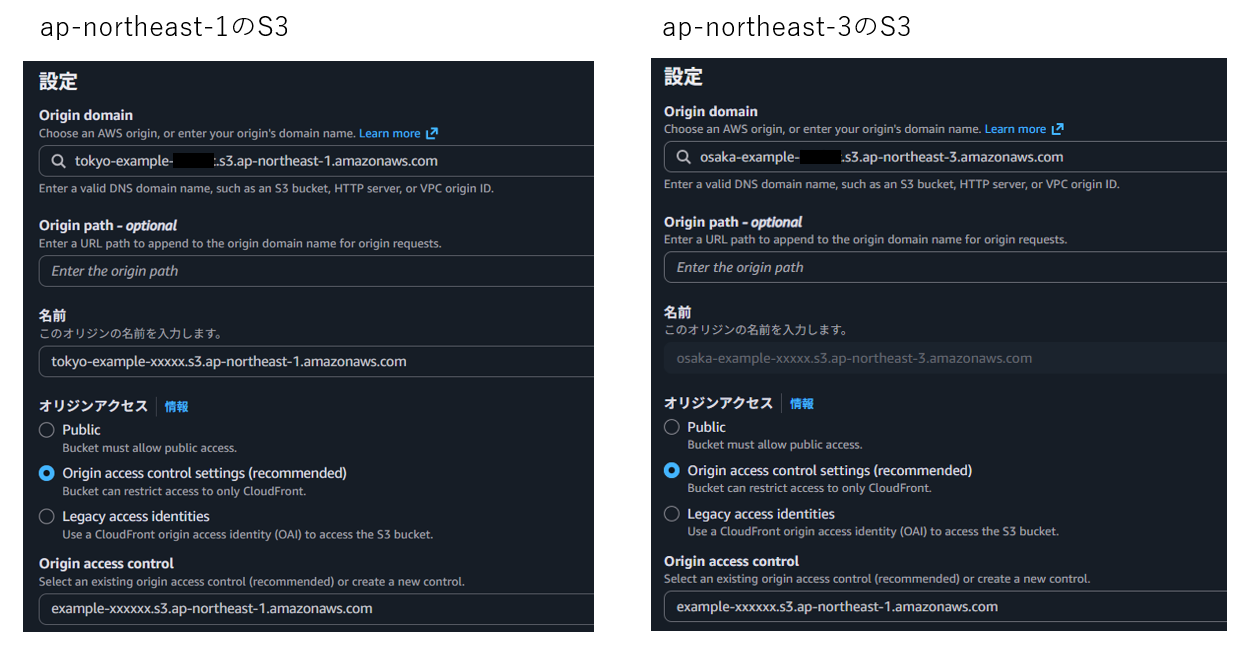
-
OAC設定のため、S3のバケットポリシーを更新
CloudFrontのorigin側でポリシーをコピー

S3のバケットポリシーに設定(東京・大阪で実施)
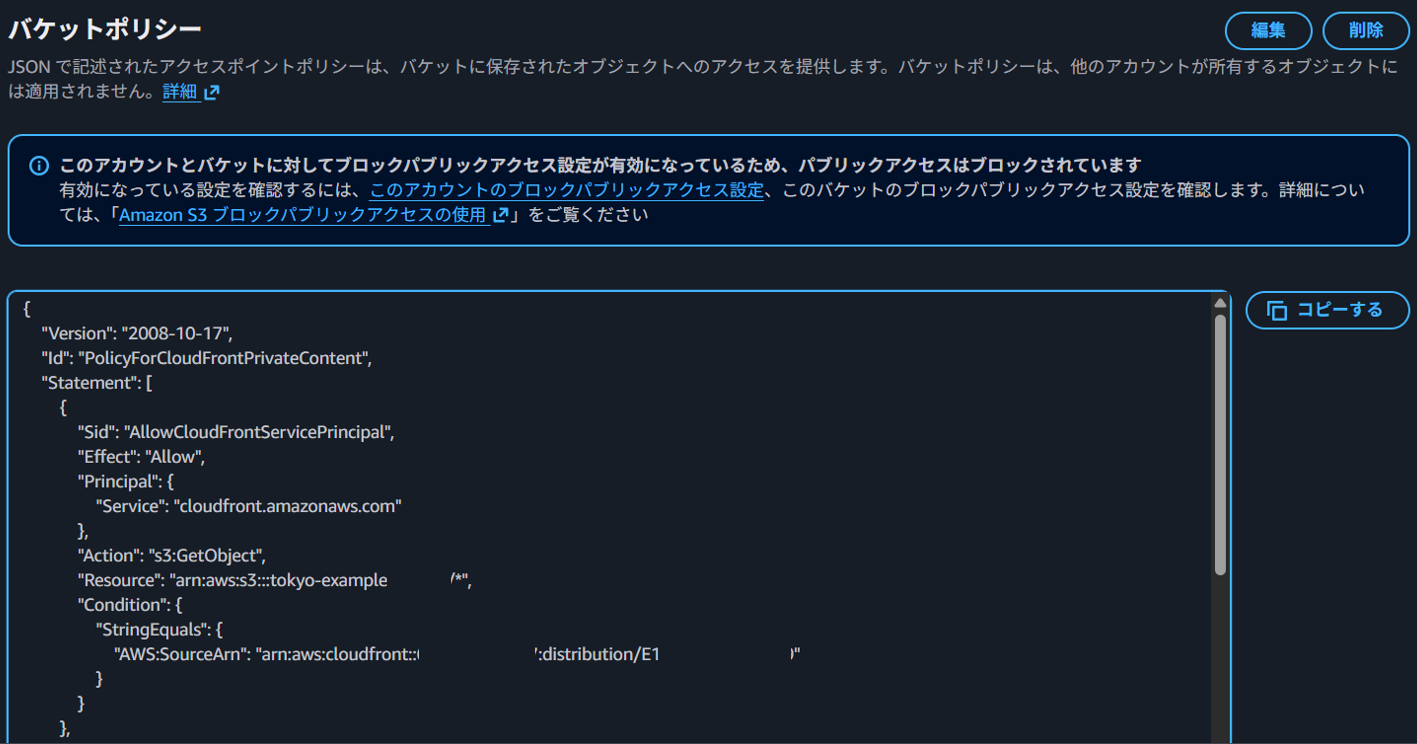
-
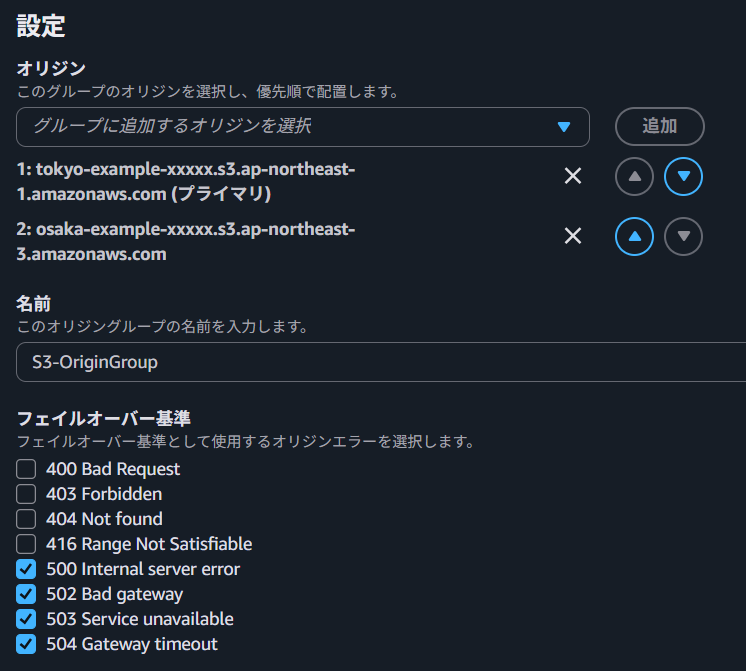
OriginGroupとして、東京・大阪のOriginを登録
プライマリ側が通常アクセスするOriginとなり、フェールオーバ基準の応答コードが返ってきた際に他方のOriginに接続を行います。フェールオーバ基準は、先述の通り5xxエラーのみとします。
-
Behavior設定でOriginGroupを登録
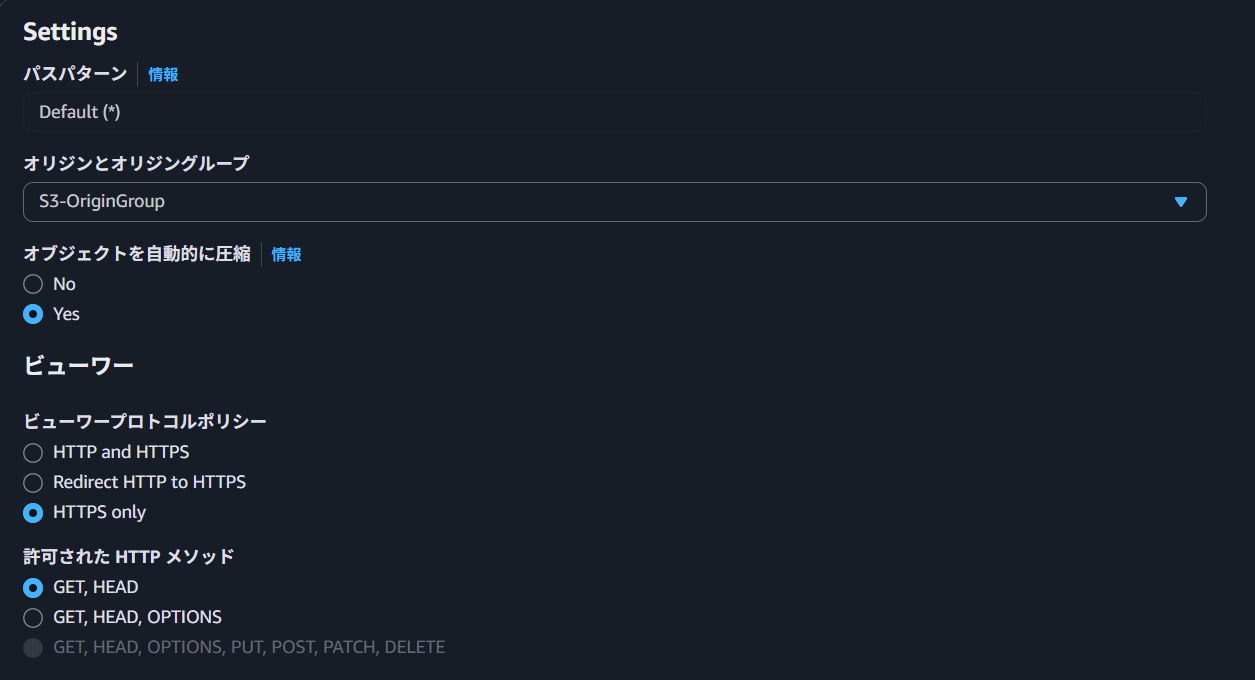
BehaviorでOriginGroupをOriginとして設定すると、許可できるメソッドはGET,HEADかGET,HEAD,OPTIONのいずれかになります。PUTやPOSTではOriginFailoverしないため、設定を制限しているものと思われます。
OriginFailover設計のポイントの一例
フェールオーバ基準のステータスコード
CRRの設計ポイントでも触れましたが、データを誤って削除した際もフェールオーバするかが考慮のポイントになります。
切り替わりのステータスコードに4xxを含めるかどうかは設計のポイントとなります。東京リージョンのデータを誤って消した際もフェールオーバによって救いたい場合は、4xxも含めるとよいと思います。しかし、プライマリ側の作業ミスに気づきにくくなるため、5xxエラーのみを対象とする設計を推奨します。
Originごとの接続試行回数とタイムアウト
下記のドキュメントに記載がありますが、Originごとに接続タイムアウトや試行回数が設定されており、セカンダリのOriginへフェールオーバするための応答コードが返ってくるまでの時間に影響する可能性があります。切り替え時間を考慮してタイムアウトも調整する必要があります。この切り替わり時間がOriginFailoverを利用した際のRTOとなります。
デフォルトでは、CloudFront は、セカンダリオリジンにフェイルオーバーする前に 30 秒間 (それぞれ 10 秒間の接続試行が 3 回)、オリジングループ内のプライマリオリジンへの接続を試行します。
よりすばやくフェイルオーバーするには、接続タイムアウトを短くするか、接続試行回数を減らすか、またはその両方を行います。
動作確認(5xxエラーでのFailoverテスト)
OriginFailoverの設定を行った場合の動作確認方法を説明します。
リージョン障害を想定して4xxエラーではなく5xxエラーのみをFailoverのトリガーにした場合の動作確認では、Originから5xxエラーを返す必要があります。しかし、S3で5xxエラーを発生させるのは非常に難しいです。そこで、Primaryのバケットへのアクセスのみ503応答を行うLambda@edgeを利用することでの動作確認を実現しました。
検証のために4xxエラーをフェールオーバの基準に一時的に設定することも一つの方法です。今回は、OriginFailoverの設定を変えずに5xxでの動作を検証する方法として、Lambda@edgeを利用しました。Lambda@edgeはus-east-1で作成する必要があります。
CloudFront functionはViewerRequestとViewerResponseのみに対応しており、Originへの制御を行うためにはLambda@edgeの利用が必要です。
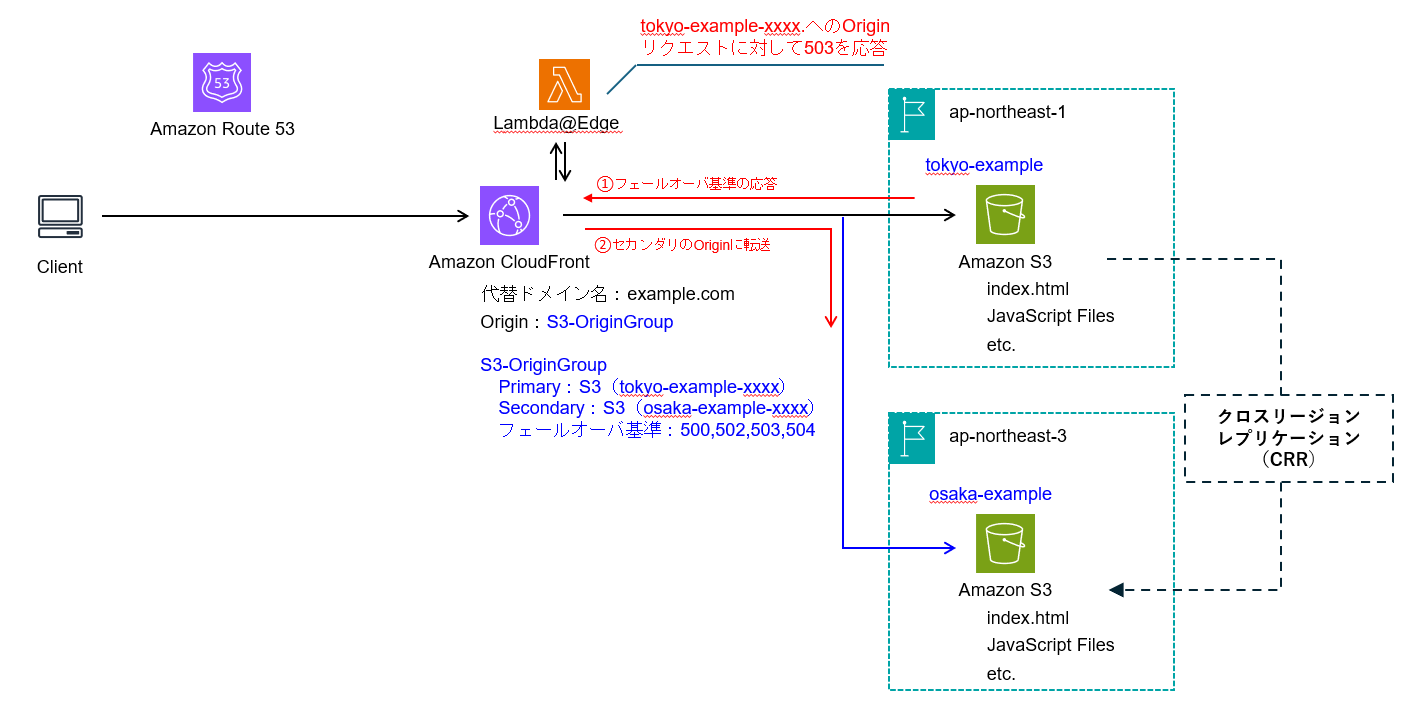
こちらの設定を行うことで、下記の通りOriginFailoverの動作を確認できました。
※本来はCRRを利用しているため同じコンテンツが表示されますが、動作検証用に別のファイルにしています。
上記の動作確認をしたサンプルコード(生成AIにより作成)を参考として記載します。
targetDomainを変更してご利用いただけると思います。
// index.mjs
export const handler = async (event) => {
const request = event.Records[0].cf.request;
const targetDomain = 'tokyo-example-xxxxxx.s3.ap-northeast-1.amazonaws.com';
// オリジンのドメインが対象と一致するか確認
// (カスタムオリジン等の場合も考慮して ?.domainName で受ける)
if (request.origin?.s3?.domainName === targetDomain) {
return {
status: '503',
statusDescription: 'Service Unavailable',
headers: {
'cache-control': [{ key: 'Cache-Control', value: 'no-store' }],
'content-type': [{ key: 'Content-Type', value: 'text/plain' }]
},
body: 'OriginFailover-test Mode',
};
}
// 対象外ならそのまま処理を継続
return request;
};
S3のファイルを削除して404エラー(OACを設定している場合は403エラー)を発生させ、CloudFrontのカスタムエラーで404から5xxに変更する方法も考えられます。しかし、カスタムエラーは直接クライアントに5xxエラーを返すため、OriginFailoverの動作検証は行えません。
CLoudFrontのカスタムエラーとOriginFailoverを同じ403を設定している場合は、プライマリOriginから403応答が返るとOriginFailoverが発生します。セカンダリOriginからも403が返ってきた場合はカスタムエラーをクライアントに応答します。
接続先切替:Route53FailoverRouting+複数CloudFront構成(NG構成)
下記の構成は実現できません。ですが、検討される方も多いのではと思い、CloudFrontの動作の説明も含めて記載します。CloudFrontを2つ用意しRoute53のFailoverRoutingやLatencyBaseRoutingで切り替える方法であり、青線が想定する切り替え経路です。この構成はCloudFrontでは実現できませんが、CloudFrontの代わりにALBを利用する場合は実現可能です。
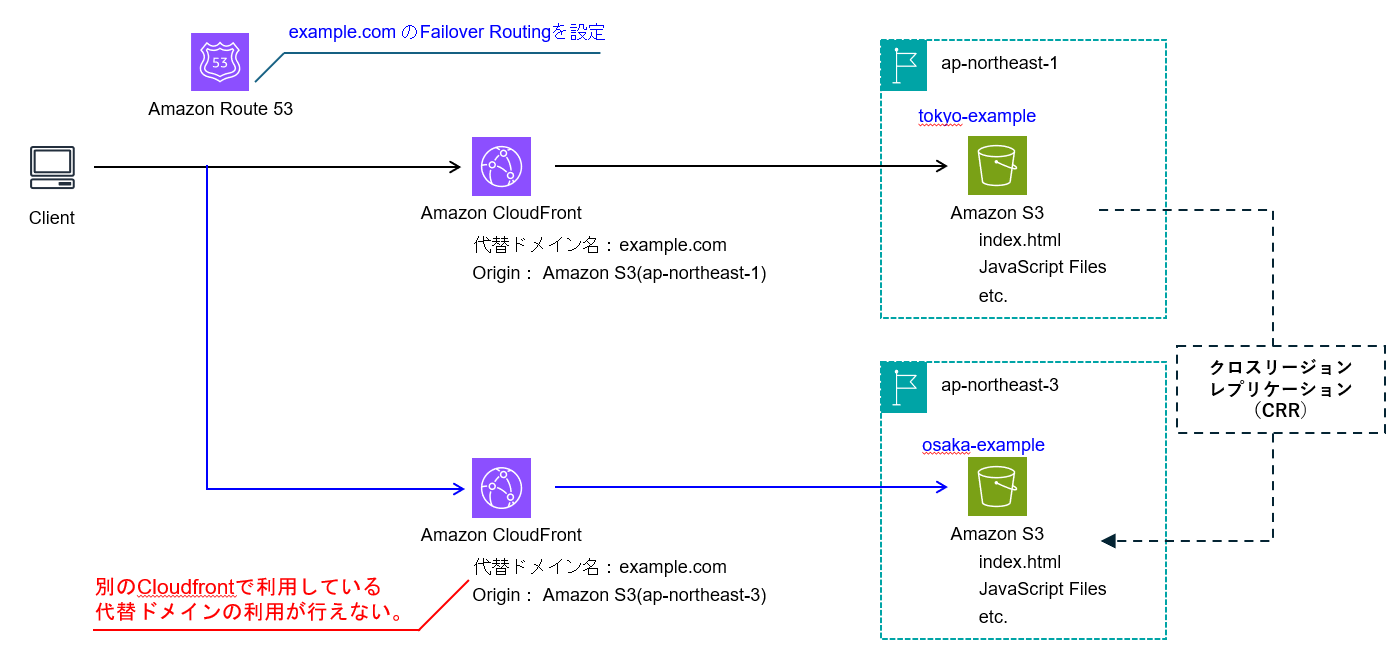
Cloudfrontのリクエスト処理動作と上記構成の問題
- CloudFrontでは、ホストヘッダに基づいて処理を行います。どのホストヘッダを処理するかは代替ドメイン名(CNAME)という項目で設定します。
- そのため、複数のCloudFrontで同じ代替ドメイン名を設定することができません(CNAMEAlreadyExistsというエラーが発生します)。 CloudFront#1とCloudFront#2で同じ代替ドメイン名example.comを設定できてしまうと、ホストヘッダexample.comのリクエストがあった時にどちらのCloudFrontで処理したらよいか分からなくなってしまうためです。
CloudFront#1とCloudFront#2で、DNSで名前解決するIPが別なので別々に処理ができるのではと思われた方いるかもしれません。CloudFrontのディストリビューションのDNS名を解決したIPはエッジロケーションのIPとなり、解決されたIPごとに処理が行われるわけではありません。ALBであれば実現可能である理由は、この違いになります。(ALB経由のS3アクセスについては、バケット名に合わせたホストヘッダでのアクセスが必要です。別リージョンでも同じバケット名を付けられないため、リージョン切り替え時にホストヘッダ変換を行うなどの工夫が必要です。)
他のシステムで代替ドメイン名を設定されてしまったらどうなるのかという点にも補足しておきます。CloudFrontでは、自身が管理しているドメイン以外の設定ができないように、代替ドメイン名と同一のSSL証明書(wildcard証明書を含む)を持っていないと登録できないようにしています。#証明書でドメイン検証を行っています。
代替ドメイン名をWildcardで設定すれば共存できるのではという疑問についても補足します。CloudFrontの代替ドメイン名を別のCloudFrontに移行する際に下記のように設定することができます。
旧CloudFront:test.example.com
新CloudFront:*.example.com
一見、共存できているように見えますが、この状態でDNSを新CloudFrontに向けても、処理は旧CloudFrontで行われます。(サブドメインまで長くマッチする代替ドメイン名側で処理を行う仕様によるものとなり、共存することはできません。)
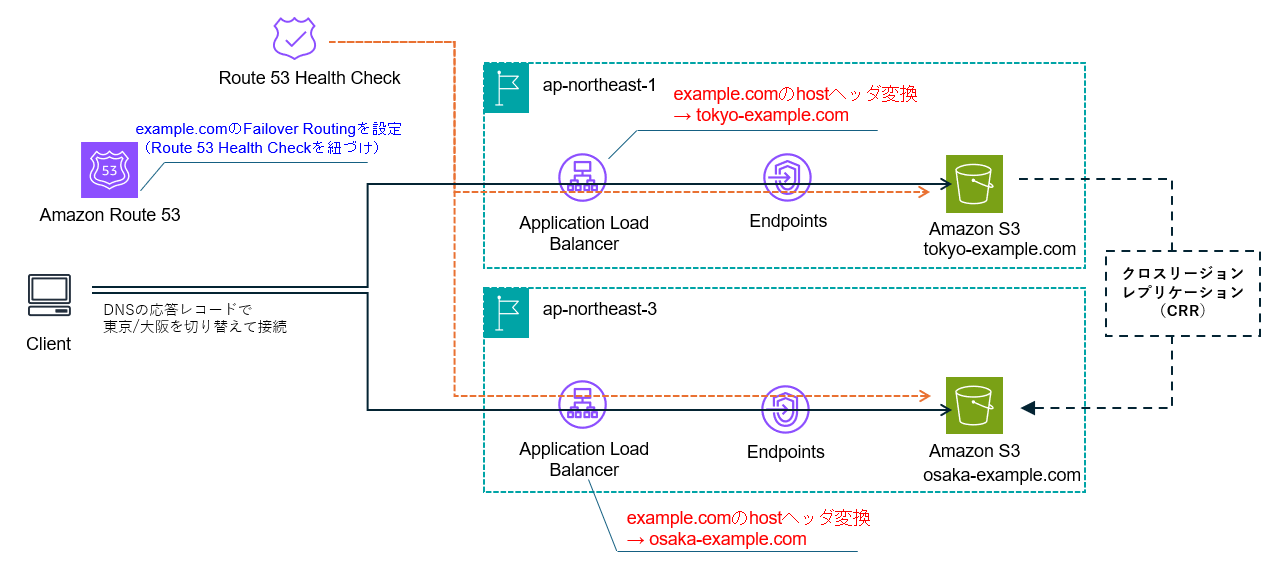
ALBで実現する構成(ご参考)
こちらは実装できていないため参考情報となりますが、ALBで実現する場合は下記のような構成が可能だと思います。
- ALB からS3 Interface Endpoint経由でS3に接続
- 東京・大阪経由の通信の切り替えのためRoute53ヘルスチェックをALBに直接実施
- Route53ヘルスチェックを紐づけたFailoverRoutingをRoute53で設定(Act/Actにしたい場合はLatencyBaseRoutingも可能)
- AmazonS3のバケット名と同じホストヘッダになるようにALBでホストヘッダ変換を実施
※ ALB経由でのアクセスは、ホストヘッダとS3バケット名を合わせる必要があります。
※ S3のバケット名は、全リージョンで一意にしなくてはならないため、同一のアクセスを切り替える場合は、ホストヘッダ変換が必要になります。(ALBでホストヘッダ変換が対応したため、こちらの構成が実現可能となりました。)
まとめ
本記事では、CloudFront OriginFailoverとS3のCRRを利用してマルチリージョン構成を実現する上でのポイントと構築手順について説明しました。いくつかの設計ポイントの考慮は必要ですが、それが決まれば、実装は容易に行えると思います。こちらの記事を参考にマルチリージョン化をしてみたいと思う方がいればありがたいです。
最後に、記事で記載した設計のポイントを整理します。
CRRの設計ポイント
| 設計要素 | 動作仕様と設計ポイント |
|---|---|
| S3 RTCの利用有無 | S3 RTCを利用することで、99.9% のオブジェクトが15分以内にレプリケートを完了し、レプリケートできなかったものを検知することが可能となる。RPO要件など、確実にレプリケートしたい際に有効にする。 |
| データ削除のレプリケート有無 | プライマリリージョンで削除したオブジェクトをセカンダリリージョンでも削除するかどうかを決定する。誤操作によるデータの削除などに備えて利用有無を検討。データの削除でFailoverをする際にはOriginFailiverのフェールオーバ基準のステータスコードも4xxを対象とすることが必要。 |
| 双方向レプリケーションの利用有無 | セカンダリリージョンからプライマリリージョンへのレプリケーションを行う。通常セカンダリに更新が入ることは少ないと思うので、フェールオーバー時のセカンダリをメインに利用しているタイミングでリリースが入る場合などに利用。 |
OriginFailoverの設計ポイント
| 設計要素 | 設計ポイント |
|---|---|
| フェールオーバ基準のステータスコード | 4xxエラーと5xxエラーからファールオーバーのトリガーとするコードを決定。データ削除などの4xxエラーでフェールオーバーさせたい場合は、4xxエラーを対象に追加。 |
| Originごとの試行回数とタイムアウト | Originへの接続が行えない場合にNGと判定するまでのタイムアウトとリトライ回数。切り替わりまでの時間を短くしたい場合などに調整。 |