デスクトップPCのGPUを RTX 3070 Ti → RTX 5070 Ti に換装したので、性能のチェックを兼ねてMetaのUMAポテンシャルを動かしてみる。以前の記事に倣い、最新のfairchem-coreライブラリを導入する。
本稿ではWSL-Ubuntuのセットアップ等には触れていないので、必要に応じて他の記事を参考にされたい。
fairchem-core 2.12 では dependencies に "torch~=2.8.0" とあるので、PyTorchは 2.8.0 のバージョンを入れる必要がある。
インストールの流れ
- conda仮想環境を Python 3.12 で作成
- PyTorch 2.8.0 のGPU対応版をインストールする
- fairchem-core 2.12 をインストールする
GPUドライバのバージョンについて
現バージョンの fairchem-core は CUDA 13 が必須ではない。nvidia-smi コマンドで CUDA Version: 12.9 などと表示されるので、これ以下のバージョンのCUDAに対応していれば問題ない。
GPUドライバのバージョンが古いと cu130 対応の PyTorch が動作しないことがある。このような場合は12.x系対応のPyTorchを入れるか、システムのGPUドライバを更新することで対応する。
ただし、システムのGPUドライバを更新すると他の仮想環境に影響が及ぶ可能性があるので注意。
【参考】fairchem-core 2.12 の依存関係
[build-system]
requires = ["hatchling", "hatch-vcs", "hatch-fancy-pypi-readme>=24"]
build-backend = "hatchling.build"
[project]
name = "fairchem-core"
description = "Machine learning models for chemistry and materials science by the FAIR Chemistry team"
license = {text = "MIT License"}
dynamic = ["version", "readme"]
requires-python = ">=3.10, <3.14"
dependencies = [
"torch~=2.8.0",
"numpy>=2.0,<2.3",
"lmdb==1.6.2",
"numba>=0.61.2",
"e3nn>=0.5",
"huggingface_hub>=0.27.1",
"ase>=3.26.0",
"ase-db-backends>=0.10.0",
"monty>=v2025.1.3",
"clusterscope==0.0.18",
"requests",
"orjson",
"tqdm",
"submitit",
"hydra-core",
"torchtnt",
"pyyaml",
"wandb",
"websockets",
]
[project.optional-dependencies] # add optional dependencies, e.g. to be installed as pip install fairchem.core[dev]
dev = ["pre-commit", "pytest", "pytest-cov", "coverage", "syrupy", "ruff==0.5.1"]
docs = ["jupyter-book", "jupytext", "sphinx","sphinx-autoapi==3.3.3", "astroid<4", "umap-learn", "vdict", "ipywidgets", "jupyter_book==1.0.4"]
adsorbml = ["dscribe","x3dase","scikit-image"]
extras = ["ray[default]", "pymatgen", "quacc[phonons]>=0.15.3", "pandas"]
[project.scripts]
fairchem = "fairchem.core._cli:main"
[project.urls]
repository = "https://github.com/facebookresearch/fairchem"
home = "https://opencatalystproject.org/"
documentation = "https://fair-chem.github.io/"
[tool.hatch.version]
source = "vcs"
[tool.hatch.version.raw-options]
root = "../../"
git_describe_command = 'git describe --tags --match fairchem_core-*'
[tool.hatch.build]
directory = "../../dist-core"
[tool.hatch.build.targets.sdist]
only-include = ["src/fairchem/core", "src/fairchem/experimental"]
[tool.hatch.build.targets.wheel]
sources = ["src"]
only-include = ["src/fairchem/core", "src/fairchem/experimental"]
[tool.hatch.metadata.hooks.fancy-pypi-readme]
content-type = "text/markdown"
fragments = [
{ path = "src/fairchem/core/README.md" },
{ path = "src/fairchem/core/LICENSE.md" },
]
[tool.pytest.ini_options]
minversion = "6.0"
addopts = "-p no:warnings -x --quiet -rxXs --color yes"
filterwarnings = [
'ignore::UserWarning',
'ignore::FutureWarning',
'ignore::RuntimeWarning'
]
testpaths = ["tests"]
[tool.coverage.run]
source = ["fairchem.core"]
[tool.hatch.metadata]
allow-direct-references = true
仮想環境の作成
bash環境で実行する。
conda create -n "uma212" "python=3.12" -y
仮想環境名は任意。ここでは fairchem-core 2.12 に合わせて
uma212とした。
以下、仮想環境 uma212 内で作業する。(本稿ではインストール時の詳細なログは省略する)
conda activate uma212
GPU版PyTorchの導入
pip install torch==2.8.0+cu128 --index-url https://download.pytorch.org/whl/cu128
index-urlオプションはあった方が無難である。
fairchem-coreの導入
pip install fairchem-core==2.12.0
最新版を入れるだけであればバージョン指定は不要。ここでは念のために指定している。
UMAの重みファイルの取得
Hugging Faceから重みファイルをダウンロードする(アカウントが必要なので無ければ登録・作成する)。
ここではUMAのSmallモデルを利用する。2025年11月現在最新のバージョンはuma-s-1.1である。
uma-s-1p1.pt をローカル環境の適当なところに置く。ファイル容量は 1 GB程度。
興味のある方はMediumモデルもダウンロードしておく。こちらのファイル容量は 10 GB程度。
テスト計算
以前の記事で取り扱った、4ユニットのシクロパラフェニレン(CPP)からなる712原子の系(下図)について、同様に構造最適化をしてみた。閾値は 0.03 eV/Å(fmax=0.03)とした。
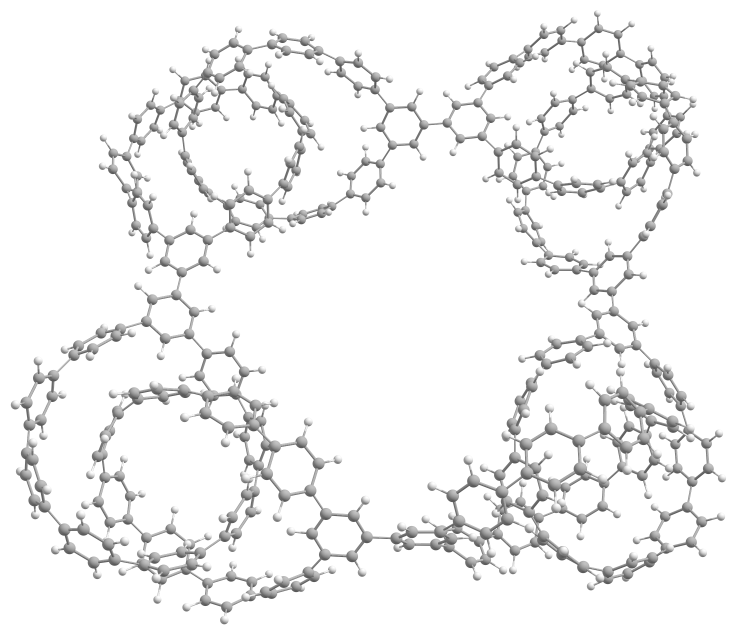
所用時間は次の通り。GPU利用時はCPU利用時に比べて桁違いに速いが、RTX3070Ti→RTX5070Tiでも1.5倍程度の加速が確認できた。
| CPU a, b | RTX3070Ti b | RTX5070Ti c | |
|---|---|---|---|
| 所要時間 | 46分31秒 | 1分41秒 | 1分08秒 |
| ステップ数 | 276 | 276 | 275 |
| エネルギー値(eV) | -452542.746219 | -452542.742874 | -452542.700321 |
a AMD Ryzen 7 5800X3D (8-Core Processor) で実行。
b fairchem-core 2.2.0, PyTorch 2.6.0 で実行。ポテンシャルは uma-sm.pt を使用。
c fairchem-core 2.12.0, PyTorch 2.8.0 で実行。ポテンシャルは uma-s-1p1.pt を使用。
最適化構造のエネルギーに約 4.1 kJ/mol の差が生じているのは、UMAポテンシャルもしくはPyTorchのバージョン違いによるものと考えられる。
以下の通り、GPUのメモリ使用量は7.6 GBで、温度は最高で60-61℃程度であった。原子数が2倍になっても計算は回りそうである。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.64.01 Driver Version: 576.88 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5070 Ti On | 00000000:2B:00.0 On | N/A |
| 31% 60C P1 206W / 300W | 7762MiB / 16303MiB | 83% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
【参考】利用したスクリプト
from ase.io import read, write
from ase.optimize import LBFGS
from fairchem.core import FAIRChemCalculator
from fairchem.core.units.mlip_unit import load_predict_unit
uma_predictor = load_predict_unit(
path="/path/to/uma-s-1p1.pt",
device="cuda",
)
calc = FAIRChemCalculator(
uma_predictor,
task_name="omol", # options: "omol", "omat", "odac", "oc20", "omc"
)
mol = read('cpp.xyz')
mol.info = {"charge": 0, "spin": 1}
mol.calc = calc
energy = mol.get_potential_energy()
print("Initial energy [eV]:", energy)
opt = LBFGS(mol, trajectory='cpp.traj', logfile='cpp.log')
opt.run(0.03, 1000)
energy = mol.get_potential_energy()
print("Final energy [eV]:", energy)
write("cpp_opt.xyz", mol, format="xyz")
【参考】Mediumモデルを利用した場合
上記の系でMediumモデルを利用すると、GPUメモリがほぼ枯渇し、最適化の100ステップを過ぎた辺りからPyTorchのCUDAメモリアロケータが断片化(fragmentation)を起こし、テンソルの再割り当てに時間がかかるようになった。
結果として、1点あたり約 1.3 秒で進んでいた計算が、途中から約 1 分近くかかるようになり急激に遅延した。
nvidia-smiで確認すると、GPU使用率はともに100%近くまで達しているが、遅延発生時では消費電力と温度が大幅に低下しており、GPUが実際の計算ではなくメモリの割り当て待ちによってビジー状態になっていることが分かる。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.64.01 Driver Version: 576.88 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5070 Ti On | 00000000:2B:00.0 On | N/A |
| 52% 63C P1 265W / 300W | 15186MiB / 16303MiB | 97% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.64.01 Driver Version: 576.88 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5070 Ti On | 00000000:2B:00.0 On | N/A |
| 31% 36C P1 58W / 300W | 15848MiB / 16303MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
特に後者ではGPU温度がidle時とほとんど変わらないくらいまで下がっている(=GPUがほとんど働いていない)。
一方、100〜200原子程度の系ではMediumモデルでも問題なく動作した。
DFTレベルで検算可能なサイズ(数百原子以下)であれば、RTX 5070 Ti でも安定して UMAのMediumモデルを扱えると思われる。