2020年4月1日から約1ヶ月間、機械学習(ディープラーニング含む)を学習したので、習作としてPerfume AI画像診断を開発しました!
→Perfume AI画像診断
初めてのAIアプリ『Perfume AI画像診断』を開発しました〜🎉
— ぐるたか (@guru_taka) April 30, 2020
機械学習を学んで1ヶ月の習作です
Perfumeの画像をアップロードすると、メンバーを識別してくれます!!
Perfume以外の画像だと、カオスな結果になりますwhttps://t.co/YHfeQxvUIy
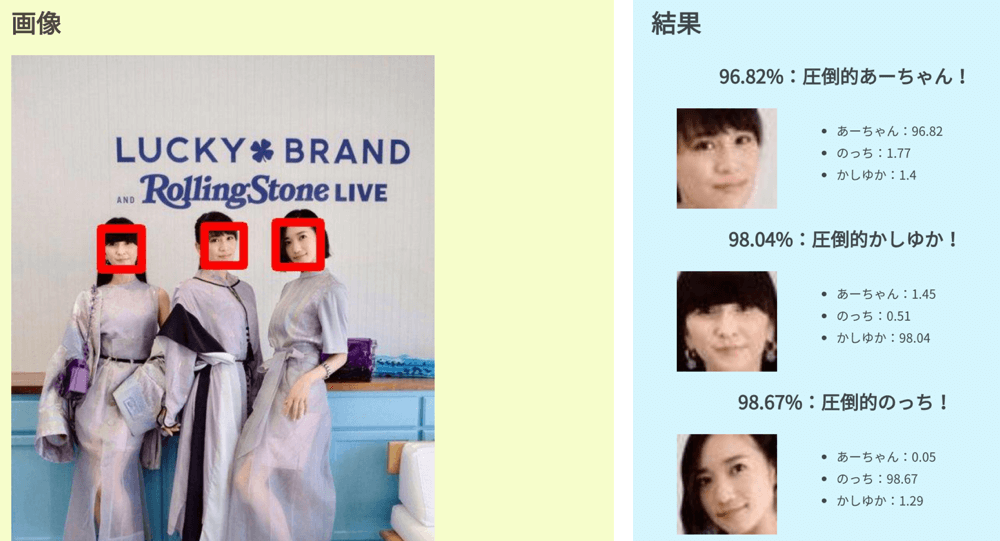
Perfume以外の画像をアップロードすると、カオスな結果が出てきますが、ご容赦ください。笑

ここではデータ集め・AI開発に焦点を当て、コード含めて技術的な話をまとめていきます。ザックリとした技術的なまとめは社内ブログに書いているので、そちらもチェックして頂けますと嬉しいです!
初めてのAIアプリ『Perfume AI画像診断』を開発!使用した技術をまとめてみる | キカガク公式ブログ
アーキテクチャ
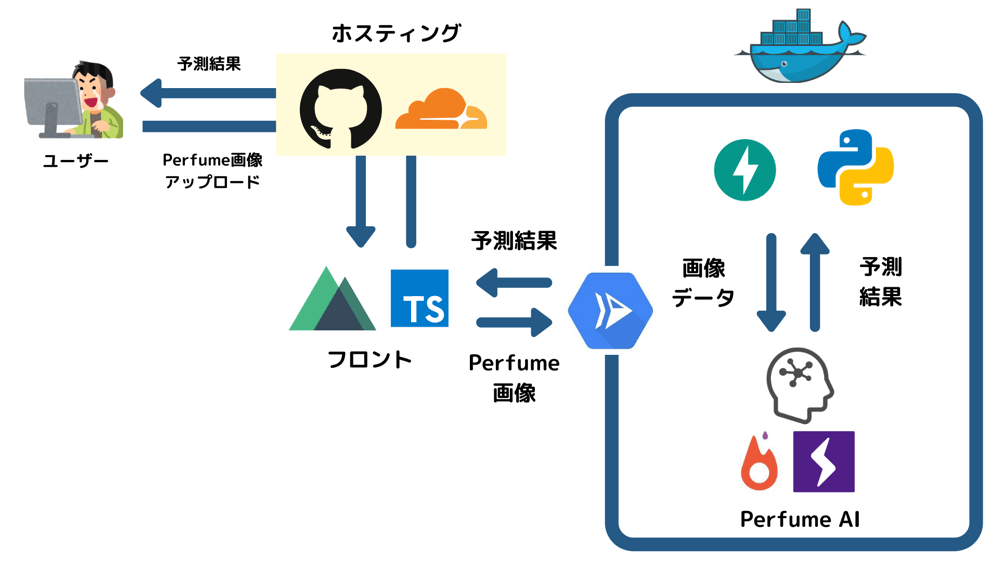
- フロントエンド:Nuxt(Typescript)
- 学習済みモデル:PyTorch・PyTorch Lightning(Python)
- APIサーバー:Cloud Run・FastAPI(Python)
- ホスティング:GitHub Pages
- CDN:Cloudflare
ここでは学習済みモデルについて話していきます。
Perfumeの画像データ集め

まずはPerfumeの画像集めについてですが、主に
- Goolgeから画像スクレイピング
- インスタ
から集めました。
Googleからの画像スクレイピングはGoogle Images Downloadを使っています。
→Joeclinton1/google-images-download at patch-1
使い方が簡単で、凄く助かりました。
$ git clone https://github.com/Joeclinton1/google-images-download.git
$ python3 google-images-download/google_images_download/google_images_download.py -k 取得したいキーワード
オススメの検索キーワードは以下3つです。
- Perfume
- Perfume メンバー名
- Perfume 壁紙
良質な画像データが少なかったので、インスタからも集めました。スクレイピングしようとしたんですが手間がかかりそうだったので、こっちは勢いに任せて自力でやっています。おじさんとかの画像だったら、確実に病んでいました。
顔の画像データ抽出
次に顔だけ抽出していきます。こちらの記事が参考になりました。
→ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編) - Qiita
顔用のカスケード分類器は公式のhaarcascade_frontalface_alt.xmlを使用しました。
→opencv/haarcascade_frontalface_alt.xml at master · opencv/opencv
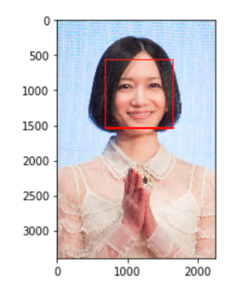
画像取得のコードはこちらになります。
import cv2
import numpy as np
import matplotlib.pyplot as plt
import glob
import os
origin_path = './imgs/original'
cut_face_path = './imgs/cut_face'
cascade_path = './opencv/haarcascade_frontalface_alt.xml'
face_cascade = cv2.CascadeClassifier(cascade_path)
for fold_path in glob.glob('./imgs/original/*'):
imgs = glob.glob(origin_path + '/*')
# フォルダがなかったら作成
if not os.path.exists(cut_face_path):
os.mkdir(cut_face_path)
for i, img_path in enumerate(imgs,1):
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(img_gray, 1.1, 3)
if len(faces) > 0:
for j, face in enumerate(faces,1):
x, y ,w, h =face
save_img_path = cut_face_path + '/' + str(i) +'_' + str(j) + '.jpg'
cv2.imwrite(save_img_path , img[y:y+h, x:x+w])
else:
print ('image' + str(i) + ':NoFace')
├── cutted_imgs
├── imgs
│ ├── cut_face # 顔だけ切り取った画像
│ └── original # スクレイピングで保存した画像
└── opencv
└── haarcascade_frontalface_alt.xml
ソースはこちらのリポジトリにおいています。
→gurutaka/cut_face_imgs_script
顔画像の抽出ができた後、のっち、あーちゃん、かしゆか、と手動でラベリングていきます。またノイズになる画像(Perfume以外の顔)も自分で除きました。
最終的に、各メンバーそれぞれ164枚の良質な顔画像をゲットできました。
学習済みモデル
続いて、学習済みモデルを作っていきます。今回はファインチューニングという手法を使いました。ファインチューニングとは、他の学習済みモデルから使って、モデル全体像を再学習する方法になります。
実は、もともと自作CNNで学習済みモデルを構築したのですが、データ数が少ないこともあって、試行錯誤しても75%ぐらいの精度しか出せなかったのです。
なのでファインチューニングを使って、良い精度が出てほしい思いでやってみました。
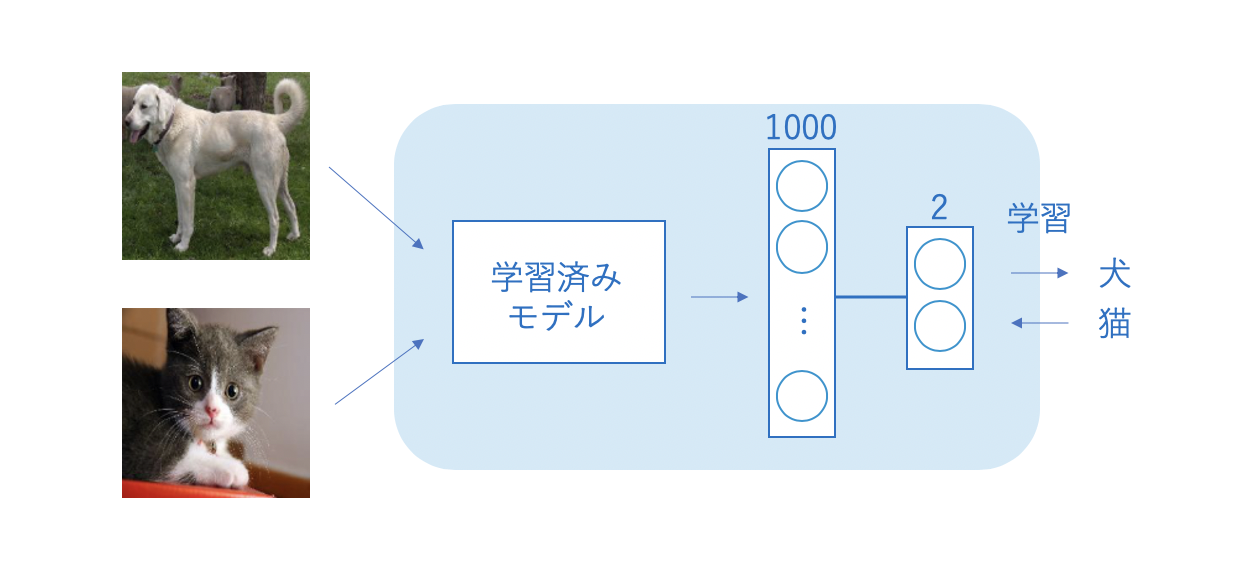
開発環境はGoogle Colaboratoryで無料GPUを使用。またPyTorch、PyTorch Lightningを使っています。
まずは、事前準備として、画像をアップロードしていきます。
├── content
│ ├── imgs
│ └────└── あーちゃん
│ └────└── のっち
│ └────└── かしゆか
└── opencv
└── haarcascade_frontalface_alt.xml
そして必要なパッケージをインポートし、画像データを読み取ります。
!pip install pytorch_lightning
# モデル学習
import torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
import pytorch_lightning as pl
from pytorch_lightning import Trainer
import torch.nn.functional as F
from PIL import Image
import glob
# 画像読み取り
fold_path = './imgs/'
imgs = []
for imgs_path in glob.glob(fold_path + '*'):
imgs.append(glob.glob(imgs_path + '/*'))
今回お借りする学習済みモデル「ResNet」をインポートします。
# 学習済みモデル「resnet18」をインポート
from torchvision.models import resnet18
# ResNetを特徴抽出器として使用
resnet = resnet18(pretrained=True)
続いてresnet18の特徴抽出器で浸かるように、画像データの前処理する関数を準備します。また画像の水増しとして左右反転も入れました。
→ResNet | PyTorch
transform = transforms.Compose([
# リサイズ
transforms.Resize((224, 224)),
# torch.Tensor 形式に変換
transforms.ToTensor(),
# 学習済みモデルで使用されていた平均と標準偏差を用いて標準化 (RGBの3チャネル)
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
transform_horizontal = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(1),
# torch.Tensor 形式に変換
transforms.ToTensor(),
# 学習済みモデルで使用されていた平均と標準偏差を用いて標準化 (RGBの3チャネル)
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
左右反転の画像データを水増しした理由は、顔の向いている方向でメンバーを判断することを防ぐためです。
最初は画像データを水増ししませんでした。精度も良かったのですが、テストしてみると、あーちゃんの顔方向が右向きが多く、左向きのあーちゃん画像を予測すると、著しく精度が悪化したのです。
なので、顔の向きに左右されないよう、左右反転の画像データを水増ししました。
labels = []
img_datas = torch.tensor([])
# 画像データを配列に格納
# torch型に変更
for i,imgs_arr in enumerate(imgs):
for img in imgs_arr:
im = Image.open(img)
# データの前処理
tensor_img = transform(im.convert('RGB'))
# バッチサイズ追加: バッチサイズ, チャンネル,
tensor_img = tensor_img.unsqueeze(0)
# ラベル
labels.append(i)
# バッチサイズ, チャンネル
img_datas = torch.cat([img_datas, tensor_img],dim=0)
## 追加
## 左右反転の画像
# データの前処理
tensor_img = transform_horizontal(im.convert('RGB'))
# バッチサイズ追加: バッチサイズ, チャンネル,
tensor_img = tensor_img.unsqueeze(0)
# ラベル
labels.append(i)
# バッチサイズ, チャンネル
img_datas = torch.cat([img_datas, tensor_img],dim=0)
これでimg_datasに前処理を終えた画像データが格納されます。
# サイズ確認
img_datas.shape
>>> torch.Size([984, 3, 224, 224])
次に、画像データとラベルを1つのデータセットにまとめていきます。
# ラベル→torch int64に変更
labels = torch.tensor(labels, dtype=torch.int64)
img_datas.dtype, labels.dtype
# データセットにまとめる
datasets = torch.utils.data.TensorDataset(img_datas, labels)
n_train = int(len(datasets) * 0.85)
n_val = len(datasets) - n_train
# 擬似乱数のシード固定
torch.manual_seed(0)
# データセット分割
train,val = torch.utils.data.random_split(datasets,[n_train,n_val])
後はKIKAGAKUのファインチューニングのコードを参考に書いていきます。
→ファインチューニング - KIKAGAKU
class TrainNet(pl.LightningModule):
@pl.data_loader
def train_dataloader(self):
# ミニバッチ
return torch.utils.data.DataLoader(train, self.batch_size,shuffle=True)
def training_step(self, batch, batch_nb):
# 入力と目標値を分割
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
tensorboard_logs = {'train_loss': loss}
results = {'loss': loss, 'log': tensorboard_logs}
return results
class ValidationNet(pl.LightningModule):
@pl.data_loader
def val_dataloader(self):
return torch.utils.data.DataLoader(val, self.batch_size)
def validation_step(self, batch, batch_nb):
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
results = {'val_loss': loss, 'val_acc': acc}
return results
def validation_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['val_acc'] for x in outputs]).mean()
tensorboard_logs = {'avg_acc': avg_acc}
results = {'val_loss': avg_loss, 'val_acc': avg_acc, 'log': tensorboard_logs}
return results
class FineTuningNet(TrainNet, ValidationNet):
def __init__(self, batch_size=128):
super().__init__()
self.batch_size = batch_size
# 使用する層の宣言
self.conv = resnet18(pretrained=True) # 学習済みモデルを利用
self.fc1 = nn.Linear(1000, 100)
self.fc2 = nn.Linear(100, 3)
# 学習済みのパラメータを固定
for param in self.conv.parameters():
param.requires_grad = False
def lossfun(self, y, t):
return F.cross_entropy(y, t)
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=0.01)
def forward(self, x):
x = self.conv(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
後はGPUを使って、訓練させるのみ!
# 再現性の確保
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 学習
fine_net = FineTuningNet()
trainer = Trainer(gpus=1, max_epochs=100)
trainer.fit(fine_net)
学習が終わったら、結果をみてみます。
trainer.callback_metrics
>>> {'avg_acc': tensor(0.9883, device='cuda:0'),
'epoch': 99,
'loss': tensor(0.0212, device='cuda:0'),
'train_loss': tensor(0.0212, device='cuda:0'),
'val_acc': tensor(0.9883, device='cuda:0'),
'val_loss': tensor(0.0646, device='cuda:0')}
98%と良い数字がでました!過学習な気もしますが、このまま良しとしちゃいました。ちなみに精度の試行錯誤の結果はこんな風になっています。
- 自作CNN:75%
- 水増しなしファインチューニング:90%
- 水増しありファインチューニング:98%
**ファインチューニングの強さを実感できますね…。**折角なので、tensorboardでグラフ化してみます。
%load_ext tensorboard
%tensorboard --logdir ./lightning_logs/version_1
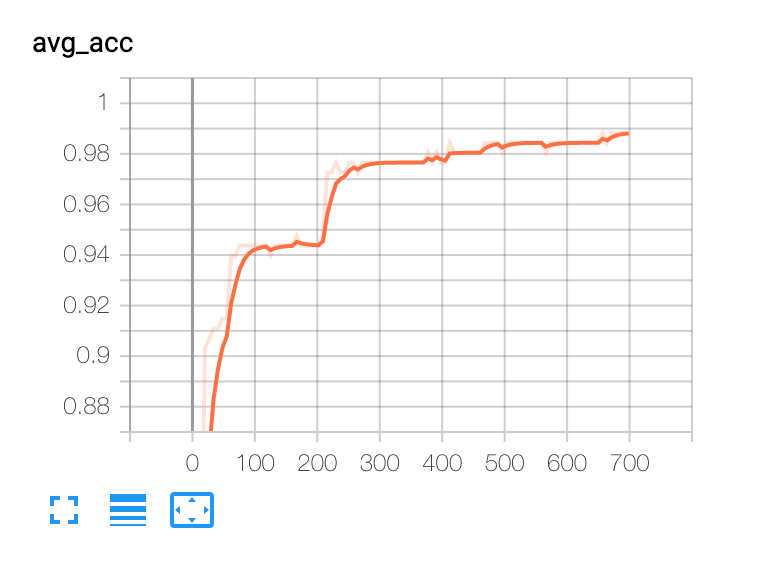
最後に学習済みモデルを保存。また保存したモデルで推論もしてみます。
# 学習済みモデルの保存
torch.save(fine_net.state_dict(), 'model.pt')
# モデルの定義
fien_net_pred = FineTuningNet()
# 推論モード
fien_net_pred.eval()
fien_net_pred.freeze()
# 重みの読み込み
fien_net_pred.load_state_dict(torch.load('model.pt'))
# 推論
x = train[1][0].unsqueeze(0)
y_predict = fien_net_pred(x)
F.softmax(y_predict), train[1][1]
>>> (tensor([[0.0803, 0.8861, 0.0336]]), tensor(1))
配列の1番目の要素が88%、ラベル1となっていて、良い感じに推論できていることがわかります。
後はこれをAPIサーバーに使えばOK!
最後に
以上になります。簡単なAI開発ではありますが、Web開発とはまた違った感じで面白かったです。
ただ、データ集めから精度あげるための試行錯誤が想像以上に大変でした…。
今後も機械学習やディープラーニングの知識や実装力を深めて、より高度なものを作っていこうと思います!