Abstract
情報系研究者のための研究ノート を書いて、もう三年もたってしまいました。やべ〜な〜。博士号を取って就職し、アレ以来だいぶ環境が変わって、使える計算資源が増えたので(400並列でGPUのジョブを投げたりできる)、だいぶ心持ちは異なりますが、改訂版を書いてみたいと思います。(ここの内容は所属組織の見解ではありません)
振り返ると、前回の投稿では瑣末な事柄(git-auto-commitとか)に触れすぎたような気がします。従って、今回はもうちょっとハイレベルな点にフォーカスしたい。結果、本記事からは実験ノートに関する記事という性格はだいぶなくなっていますので、ご了承ください。とはいうものの、大体の内容は前回から変わっていません。以前と変わってキカイガクシウの実験もやるようになりましたが、実際のところあまり勘所は変わりませんでした。ターゲットとなる読者も以前と変わらず学部・修士生など。
学部・修士生のみなさまにおかれましては、まあ今年度の卒業生はもうどうしようもないので、次年度に卒業研究を始める学部生、および修士新1,2年両方をターゲットにしたいと思います。
Introduction
本記事は、締め切りの明確に定まっている文章(上位国際学会論文、国際学会論文のrebuttal(反論)データ、学位論文)のための実験を円滑柔軟に行う工夫について論じる。ここにある内容は、筆者が自分の経験から学んだものもあるが、先人・指導教官の智慧から学んだものが多くを占める。感謝。
時間配分
**卒業駆動開発(例:修論,卒論ベース)をすると、始めの1年間は確実に仕事をしない。**締切がないと動けないというのは、人間の真理である(Ariely and Wertenbroch, 2002)。忘れがちだが20代は短い。 もう半分過ぎちゃった。 あと一年で終わりそうだ。若いうちに実績を積まなくては死ぬ。**ので、査読つき海外論文投稿を第一目的とする学会駆動開発にしよう。**一年に何度もチャンスがあるから。特に研究者タイプに多いADHD傾向の人の場合、だらだらと一度も過集中を使えずに二年間を過ごして卒論・修論直前に過集中を使うより、毎3ヶ月-最大6ヶ月の短期間のうちに過集中を用いて全力で決着をつけるほうが、はるかに生産的。
全体の時間配分について。ターゲットとなる deadline に対して、最後の1ヶ月は論文執筆だけで良いようにする。なるべく実験はしなくていいように。逆算して、実装は一ヶ月前時点でほぼ完成・バグ取りが終了していないといけない。実験・実装は、個人の能力・時間的余裕によるが、多めに見積もって一ヶ月ずつぐらいかかるだろう。すると、アイディアは三ヶ月前に固めなくてはいけない。
ほぼ同様の内容を述べているのだが、松尾ぐみの論文の書き方:英語論文の記述は真実。ただ、現在はGrammarlyなどのサービスもあるし、普段から英語Redditで自分の好きな板(例えばr/carsとかr/lispとか)で交流していれば、英語校正に出して一日待つなんて悠長なことをせずに、締め切りの30分前まで自分の英語力で論文を修正し続けられる。
一本でもちゃんとした国際学会に通れば、それは心配せずとも十分に卒論・修論に値するだけの成果になっている。修論は適当に日本語訳して出せばおk。
新分野に飛び入って半年で業績を作るにはでも述べたが、学部から修士で別の研究室に移り、学部の研究結果を使えない状態でなお一年目から絶対に業績を作りたい人(海外PhD留学志望など)は、取れる限りの授業を1学期目に終わらせて、いわゆる査読ラダー、つまり 1st tier 締め切り→査読→結果通知→rejectの場合→2nd tier 締め切り→査読→結果通知→... に対応する時間が取れるようにしよう。
指導教員
研究Advisor(教授,上司)あるいは共同研究者との密な連絡は、研究の効率を上げるのにとても重要。なにか大きな進歩があり次第skypeなどでチャット・報告が望ましい。Advisorはそれまでの研究経験と知識の量において生徒を大幅に上回っている。
ただ、Advisorが伝えたことを全部聞いて/覚えて/理解しているとは期待しないほうがよい。教授と1vs1で相談できる時間が確保されているだろうが、それ以外の時間は、教授は他の雑務に忙殺されており、あなたの研究内容はswap outされている。相談のときには、前回の復習からはじめるのがいい。
一対一面談とチャットは目的別に使い分けよう。経験的には、面談は大きな戦略を練るのに向いている気がする。チャットは、共同執筆のときなどの細かな調整に使える。面談は必要がなければキャンセルすればいいし、必要なときにはたくさんすればいい。目的/アジェンダを決めて面談し、無駄な面談はしない。
第三者の意見があること自体に意味がある。必要な仕事、つまり実験&実装&執筆を同時並行でしていると、そればかりに頭が行ってしまい、一人では大局的な判断をし辛くなる。百戦錬磨の指導教官というのは、研究をやり始めて数年の学生では思いもしない、それはすごい(というか正直トリッキーな)大局的な判断ができる。それは例えば、セクションを上下逆にするとか、同じ実験結果から全く別のストーリーを創りだすとか、あるいは前日まで血の出る思いで出していた結果の表を削除し(読解力0の査読者の混乱を避けるため)、将来の論文にとっておく決定をするとか。はたして、目の前の論文に全力を費やしている時に、数年先のキャリアを見通した決定ができるだろうか。
アイディアは上司の方が豊富なので、もしも分野に入って初めての研究だったりするばあいは、相談するしかない。ここで変にオリジナリティなどを出そうとしてもそれは無謀というもの。オリジナリティは一本目で知識が広がるから二本目以降で十分出せる。(おや、二本目なんて夢のまた夢?ご冗談を、十分できますよ。)また、スーパーオリジナルなものはちょっと待った!博士まで行くつもりなら途中で考えればいいし、しかもその内容を博士論文にする必要もない。いわゆる上司が最も詳しい分野(==研究内容だけでなく査読者メンバーやその考え方などを熟知している分野)で当面頑張り、博論にできるだけの分量を仕上げてから、一段落させて別のテーマとして始めればいい。そうすれば、博論審査は安心して受けられるし、博士後のキャリアを狙っているならそこで書く申請書のアイディアにも事欠かない。
研究開始前の工夫
研究開始前に工夫もなにもあるわけない? 否否否、いま話しているのはテーマ選びの話。
世の中には、半年や一年立っても研究テーマが決まらない学生というのが多いらしい。個人的にはあまり信じられなくて、よくわからない。テーマというのはたいてい、所属研究室でだいたい決まっている。2つ以上の分野をやっている研究室もあるかもしれないが、7つも8つも別の分野の研究をしている研究室なんてあるのだろうか?ゆえに一つ選ぶのはさして難しいことではないハズ。一つの分野を選んだあと、その分野の中でもいくつかサブ分野というのはある。しかしそれも、どれか適当にビビッとキたものを選べば良い。それがハズレでも、時間はある。
選んだあと、次にベースライン実装を手に入れる。もしベースライン実装がその分野でよく使われるライブラリとして実装されていなければ、自分で作るしかない。ここで残酷な話だが、実装が得意でない人は大変である。自分は理論よりの人間ではないので、実装を他の人に任せて共著、というのがどれだけ学部・修士レベルで可能なのかはよく分かっていないのだが、もしかしたら欧米では一般的かもしれない。まあただ、アメリカでは学部・修士は研究はしないらしいけど。
ベースライン実装を作り、そこそこ動くことが分かったら、それに新規性を足さないといけない。が、この新規性は何から出てくるのだろうか?それは思うにずばり、(ほかのCS分野、あるいは数学や物理、はてはSFの)教養である。アイディアのうち本当に新しいものというのはほとんどなくて、たいていは他の分野の知識との組み合わせである。だから、他の分野の知識に常にアンテナを張っていないといけない。かっこよさそうなもの。美しいもの。ワケワカランもの。エッジの効いた、トガッた物。組み合わせたら学会で目立ちそうなもの。たまたま本で読んだもの。たまたま教科書に乗っていたもの。趣味。もし仮に研究者を目指しているなら、それが自然にできないとつらい。
あるいは、アイディアが先にある場合もある。その場合によく犯す初歩的なミスが「コレは新しいのでベースラインは存在しません」と主張すること。たいてい指導教員と頻繁に情報交換できていない学生がやる。まず、指導教員とちゃんと相談するべき。 別のケースは、指導教員の専門でない分野でなにかしようとしたとき。指導教員が指導できる分野で研究するべき(じゃないと学費の無駄)。最後に、その主張は正しいのかもしれないが、査読者にしてみればそれと似て見えるものは多数あるので、主張の際には大変注意しなくてはいけない。時にはstraw-manであってもベースラインを作ることが必要であるし、また関連研究を網羅的に参照して違いを説明しなくてはいけない。提案手法Xと全く似て見えないY / Yの最低限の理解があればXとYは違うはずのY について査読者が 勝手に勘違い してX=YあるいはX≒Yと言い張ることすらある。そこをどう躱すかが研究をやっていくうえで重要な技術である。
(おそらく**ハードウェア系・ロボはこう簡単ではないと思う。本稿はソフトウェア・アルゴリズムの研究に絞って論じる。**正直ハード・ロボはつらみしか漂ってこないのであんまりおすすめしない…。)
研究開始段階での工夫
ここでいう研究開始段階というのは、やりたいテーマを決めるような段階ではなくて、ある程度のベースライン(ただし、洗練されていない)のプログラムが完成し、またそれの改善として使えそうな何かアイディアがあって、しかもそれがうまく行きそうな雰囲気の実験結果ができた段階のことを言っている。
何か作ったものがうまく動くっぽい雰囲気がしてきたら、まず論文のアブストラクトを書こう。今何が問題で、それをだいたいこうして、実験をやって、結果何が主張できるのか ---- アブストはそれがまとまったものである。今手元にあるものから一旦身をおいて、離れたところから俯瞰してアブストを書くことで、これから実験として何をするべきなのかが見えてくる。
また、Related Works や Background の整備を始めるのもこの時期だ。なぜなら、そこらへんを調べておかないと、一番最初に作ったtrivialなベースラインの他に、何が対抗馬で、何を実験的に比較しないといけないのかがわからないからだ。この際に、何か対抗場として候補になりそうなものを聞くのは、(自立するまでは)やはり指導教員である。先輩の博士学生もいるかもしれないが、その学生が適切な比較対象を教えてくれる保証はない。「自力で研究を遂行する能力が保証されていない」のが博士学生ですからね。まあ、指導教員の言うことなら正しいかというとそういうわけでもなくて、「改めて考え直してみるとこの比較はやっぱり必要なかった」ということもある。そこは研究なので、NPオラクルな予知能力者でない限り仕方ない。
次のセクションで述べる「実装段階の工夫」とは、この時点で手元にあるクソプログラムを、どう論文執筆の最終段階に適したものにリファクタリングしていくかという話である。
実装段階での工夫
実装プログラムをバージョン管理できていることを前提とする。実装のアイディア自体は既に十分吟味されているものとする。単体テストや統合テストを書くのも前提とする。その他ソフトウェア工学の知見はだいたい役に立つ。
プログラムはモジュラーに、より多彩なコンフィギュレーションを行えるように制作する。これは、論文を提出した後に求められる追加実験に対応するため。論文査読者は論文をきちんと読まないことも多い。腹はたつが、査読者は「お客様」投稿者は「店員」なので、理不尽な要求に多少耐えられる程度の柔軟性をプログラムに与えておく。
コマンドラインオプションは「機能をオンにする」 フラグを書き、「機能をオフにする」フラグは書かない。デフォルトで全てオンだと、実験の際に、どの機能が性能向上に寄与しているのか全くわからなくなる。論文のストーリー的にも、何か核心となる機能以外は全てオフの結果をまず出したほうが望ましい。学会論文では「性能がいい」だけでも通ることがあるが、論文誌では「なぜ性能がいいか」を見せなくてはいけない。
ハックはハックでもいいのだが、つねにライブラリを書いている気分でプログラムを書こう。今回の論文だけをターゲットにするのではなく、常に次の論文を書く時にも使えるような仕組みを整備するつもりでプログラムを書こう。研究のためのコードではなく研究を加速させるコードを書こう。可能であればgithub、次にパッケージマネジャー(PyPIとか)に公開しよう。個人的には、今の機械学習分野のNotebookで共有するスタイルは大嫌いで、彼らは手続き的なクソコードをダラダラ貼り付けて一回再現できればよいというスタイルを推し進めている。
クリーンな、読みやすい、正しい実装と、性能重視の黒魔術を使った実装を両方作る。早くても正しくないアルゴリズムは論文に使えない。まずクリーンな実装でバグをなくし、続いて性能を追求しよう。(cf. iterative development)
ログ
プログラムの途中経過はなるべく多く出力する。生成した中間構造の内容すべて。これも、rebuttalで実験せずとも提示できるデータを多くするため。通常、学会論文の反論期間は、査読文が読めるようになってから反論を返すまで3-4日の猶予しかない。この期間に行う実験の量はできるだけ少ないほうがよい。
忘れがちだが、プログラムのバージョン・ビルド日時をログに出力する。入出力ファイル名もプリントする(間違えて別のファイルを入力しているというボンミスは多い)。あるいは、実験スクリプトでバイナリのmd5ハッシュを記録。
出力ファイル名、あるいはディレクトリ名に、実験設定をすべて記載しよう。なるべく、中を見ずとも概要が把握できるようにする。略称をある程度用いることは許容されるが、一貫していなくてはならない。
そのような記載を行うとき、新たにできたばっかりのコードに名前をつけないといけないかもしれない。そのようなとき、名前の後ろに 1 を追加しておこう。Mymethod1とか。なぜらなら、開発途中では様々な派生版・修正版を作らなくてはいけないから。そういうとき、いちいち名前を付け替えるのも馬鹿らしいし、派生版には適当にMymethod2とか名前をつけることがあるだろうけど、そのとき1つめのメソッドがMymethodだけだったら、実験結果のパーサーで追加のロジックを実装しないといけなくなる。
ログに多くを出力することは必須だが、できれば同時に、明らかに後にパースする必要があるだろうと見込まれるデータは、jsonファイルに出力するのが良いだろう。jsonファイルはgrepしにくいが、最近jqというコマンドラインから簡単にjsonを読み出せるプログラムができた。これを使えば、ファイルを簡易的なデータベースとして扱える。jqはapt-getで入る。また同時に、コマンドラインオプションから得られたメタデータもこのjsonファイルに書き出そう。これで、表やグラフ作成時のログ解析の手間が大幅に削減できる。ログへの出力をなるべくたくさんするというのは、将来何のデータが役に立つかなんてわからないからだ。万が一そのデータが必要になったときにも再実験無しで読み込めるように、一番手軽な方法が printf 等である。
実験結果のディレクトリは下手に階層化させない。これはシンプルに、階層化するとログの取り出し作業などで手間が増えるから、そして一覧性に劣るからである。例えば、一つの実験が5つのパラメータ A={1,2,3}, B={0.1,0.01,0.001},... E={Method1,Method2,Method3}をもつとする。この実験データを A/B/C/D/E/result.log というふうに置くとしよう。すると、lsで出てくるのはAの階層だけだし、EmacsのDiredでも、Eまで開くのに計5回操作しないといけない。なぜ代わりにA-B-C-D-E/result.log というディレクトリにしないのか?という問題。この場合、シェルスクリプトから実験をフィルタリングするのにも、 ls -d | grep -0.01- と書けば一発でB=0.01なものが出てくる。一方ディレクトリ階層にする場合、ls */0.01/*/*/* と、今回関係ないA,C,D,Eのぶんまで毎回正しく指定しなくてはならないので、認知コストが高まってしまう。(zshとかだと */0.01/**/ って書けるのかな?)
すべてをファイルシステムで表現すれば十分という考え方は、 Paul Graham が Viaweb で全くデータベースを使っていなかったことをヒントにしている。ベンチャーでウェブサービスを作るのと研究を行うのは全く違うようで似ていると思う。なぜなら、どちらもアジャイルで、一番のボトルネックは人間だから。私達はそのデータを締め切り前の疲れた頭で操作しないといけない。それゆえ保存されるデータはそれが一番直感的な、簡単な形になっていないといけない。そしてそれはファイルシステムである。一時期実験データをsqliteに貯めることもやってみたことがあるんだけど、結局並列作業が遅いし、クエリを考えないと/sqliteビューワを開かないと中身が見えないので、やはり良くないと結論づけた。
What database did you use?
We didn't use one. We just stored everything in files. The Unix file system is pretty good at not losing your data, especially if you put the files on a Netapp.
It is a common mistake to think of Web-based apps as interfaces to databases. Desktop apps aren't just interfaces to databases; why should Web-based apps be any different? The hard part is not where you store the data, but what the software does.
実験デザインでの工夫
自分の現在の分野・現在の実証内容に対して、一つの実験インスタンスのパラメータが何次元なのか考える。そしてこれを2+1次元まで落とす。
- 二次元以上は人間が視覚的に効率よく管理できない。
- どちらにせよ論文に載せられるのは二次元プロット、あるいは表(=二次元)。(やりようはあるが...)
- パラメータの例:コンフィグ1,コンフィグ2,データセット,メモリ制限,時間制限 ...
次元を落とすには、データベース設計の知識(正規化など)を応用すればいい。例:
- ある次元を別の実験セットとする。(例:一つのインスタンス内ではメモリ・時間は統一。実質的に3次元目)
- カテゴリ内を無視する。(例:一つのドメイン内の問題インスタンスらは、後に合計・平均をとるから無視)
- カテゴリ内を直積としてアンロールする。(例:100/200秒と1000/2000MBのメモリ設定の組み合わせを
<100,1000>,<200,1000>,<100,2000>,<200,2000>の4つにする)
無尽蔵の計算資源がある場合(例:とてもお金持ちの研究所や会社に就職する)や、実験の時間が十分にある場合(もちろん、その間に論文を書く)は、結局のところ、全パラメータの組み合わせを実行することができる。ただし、流石に無駄なので、ある程度の枝刈りは行っておこう。クラスタの他の利用者にも迷惑。
実験~論文執筆での工夫
修羅場で命運を分けるノウハウ
バグつぶし
フルの実験を行う前に、ファイル読み込み段階のバグなどを検知するため、5分の実験をまず行う。それがパスしたら10分,20分と2倍ごとに増やす。すると、最後の本番実験は実験全体の時間の半分以下になる。(cf. $\sum_1^\infty 1/2^n = 1)$ 高負荷・大規模実験でしか出てこないバグもあるが、短い実験でそれより早期に発見できるバグもある。
サイズの小さな問題インスタンスに絞って実験を行う。テストはより広い問題ドメインに対して行い、時にRandom-pick testing を行う。
parallel
parallelはいいぞ。 使いこなそう。
べき等性
これは他のいろいろなところでも言われていると思うが、Makeなどで実験コードにべき等性をもたせるのはかなりよいアイディア。これは、結果がすでに存在する場合には再実行しないような工夫をコードに入れておくということ。例えばMethod1,Method2,Method3の実験があって、Method3だけにバグがあったとき、実験コードがべき等であれば、実験結果ディレクトリからMethod3のぶんだけ削除し、元の実験と同じジョブ投稿スクリプトをそのまま実行してやれば良い。一方コードがべき等でない場合は、スクリプトからMethod1/2を削除してからスクリプトを実行しなくてはいけない。
微妙なのが、ジョブの計算資源設定が足りなくて途中で止まってしまったようなケース。300エポック回したかったのに200エポックで止まってしまって、しかもその時点でエラーハンドラーがファイルをセーブしてしまうので、ファイルを見ただけでは最後まで終わったのかどうか分からない、みたいな。汎用の答えはないのだけど、気をつけよう。エラー無しで完了したら completed って名前のファイルをtouchするとか・・・?
進捗管理
このノウハウは、超並列で実験を実行できて全実験が1時間ぐらいで終わるような効率的な環境ではあまり関係がない。従って、効率的な研究のために必要なのは、やはり強力なクラスタを比較的自由に使える研究環境である。文科省財務省さん、聞いてますか??????
論文を書きながら裏で実験を走らせていると、書いているうちに何の実験をしていたか忘れてしまうので、進捗管理する。(ひょっとして、ADHDだけ?)管理には excel を使ってもいいし、 Org-mode や markdown などに付いている表管理機能でも良い。Redmine自分で立ててる人はそれでもいいが、効果的なUIがあるか微妙。
実験セットx1次元目x2次元目 に落としたものを、表の形で管理。一つの表が実験セット、横が一時限目、縦が二次元目。
ひとつのセルには、どのフォルダで実験しているのか、想定される計算時間、実験の進行状況など、好きなことを書き入れる。いつ実験開始したのか、何時頃終わりそうかも書く。理由があって中断したら(torque qhold etc.)それも書いておく。
例: (org-mode)
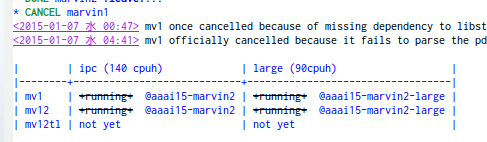
進捗管理表は、セーブのたびに自動コミット+自動pushなどができるようにしておくといい。締め切り間近は、いちいち手で管理しているような時間がない。ついでに、同期のし忘れ問題も避けられる。それに、なるべく細かくログが残っていたほうが、実験ノートとして有効だと思う。
実験スクリプト
実験スクリプトと問題データセットは別のリポジトリで管理しよう。 本来別のものであるから。git submoduleは、バージョン固定のためにデザインされた機能なので、相互に頻繁に更新されるような2つのリポジトリに対しては手間が増えるだけなので使ってはいけない。一方実験スクリプトをコピーするのは、たとえば複数の問題データセットように別のディレクトリを使いたい時に同期されず危険である。従って一番良いのはsymlink。 また、同じスクリプトをずっと使うのなら、~/.local/bin あたりにsymlinkしてpathを貼っておくのでもよし。
また別に、qsubなどジョブスケジューラ用の追加スクリプトを書く場合、これも別のリポジトリで管理しよう。ジョブを投げる実験スクリプトに、実験開始時刻と予想終了時刻を自動記録する機能をつけてもいいかもしれない。
ジョブを投げるときには、それが何のためのジョブだったかをちゃんと記録しておこう。実験スクリプトに、git commit で -m を忘れると怒られるのと同じような仕組みを追加して、EDITOR環境変数からエディタが呼び出されるような設定も悪くない。
古いバージョンのプログラムを使ったデータも、なるべく削除せずに取っておこう。アーカイブ名には実験設定が明記されるようにする。このアーカイブはむやみに削除しない。バグ/incompatble changesがあっても論文に使える結果もある。論文締め切り間近など、実験の時間が制限されている時には大変重要。例:
- postprocessingのみにバグがある場合。preprocessingの時間計測は正確だから使えるはず。
- バージョン違いでログ形式だけ異なるが、出力データの中身自体は正しい場合。
データの同期
自宅と実験サーバーなどを、DropboxやNFSなど なるべく最小限のアクションで同期出来るようにしよう。徹夜で溶けた脳でも、コマンド一つで同期されるようにしておけば大丈夫。同期先はなるべく多く。これはHDDが死んだ場合のバックアップ。ただし、Dropboxは一箇所で削除されると全ての場所で削除されるので注意。
これらが使えない場合でも、rsync等を使ってで実験結果をワンコマンドで転送するスクリプトを作っておこう。
Bittorrent sync も一つの手段であるかもしれない。巨大なデータに対してはDropboxは有効ではない。Bittorrent sync はサーバーを使用しないP2Pベース、かつネットワーク大域を有効に使うので、期待できる。rsyncとcronでうんにゃらするのは時間ラグがあるので嬉しくない。大学内ネットワークではbtsyncは使えない(特に東工大)。
その他
- エラーがあったら単体テストをメインのプログラムに追加することを忘れない。
- 全実験結果に対して、結果の正しさの検証ができるスクリプトを用意しておく。
- 実験結果が巨大な場合でも、Git Large File Storage があれば気にせずコミットできるらしい。
- サーバにログインするときには SCREEN / tmux / byobu (screenかtmuxのラッパ, おすすめ) に mosh を組み合わせるのが一番生産性が高い。
Conclusion
本記事では、研究を効率的に行う上での心がけに対するいち知見を述べた。ここに書いてあるのが絶対のあれだとは思わないが、結構役立つと思う。
追加ノウハウがあればどしどし送ってください。
最後に、自分の Ph.D Advisor のさらに Ph.D Advisorの言:
"Your computer should always be running experiments, since there's no reason that you should be working harder than your computer... On the other hand, just because your computer is running, it doesn't mean that actual progress is being made on the research, if your code/scripts have bugs!"