前置き
この記事は [OPENLOGI Advent Calendar 2017- Qiita] (https://qiita.com/advent-calendar/2017/openlogi) の12日目です。

こんにちは。株式会社オープンロジの@guai3 です。
前回の考察編に引き続き実装編です。
読者の皆様はスマートスピーカーを毎日使っていますか❓️
使っている人はわかると思いますが、音声認識はまだまだな部分が多いです。
数年前に比べて日本語の音声認識はずいぶん良くなりましたが、万人が快適に使えるようなレベルには未だに到達していません。
私は Google Home mini と Amazon Echo dot を毎日使っていますが、両者ともに、「すみません、お役に立てそうにありません」と結構な頻度で何かと謝罪してきます。
無理難題を言っている訳でもないのにそんな返しをされると、自分がひどい人間になったようで嫌な気持ちになりますよね。
日本語は英語に比べて同音異義語が多い分、おそらく、英語よりも誤認識が多いのでしょう。
しかし、実際に運用する業務システムにおいてそんな音声認識の精度では使い物になりませんし、導入しても、使われなくなってしまいます。
何度も、同じ事を言わされると恥ずかしいですからね。
方針
という訳で、今回は原則的にはエラーを吐かないシステムを作りたいと思います。
我々人間はコンピュータには常に「Yes sir 答えはこちらです」とスムーズに答えてくれることを求めているのです。
では、具体的にはどういうアプローチをとるのかと言うと、フロントで形態素解析や色々処理をしてくれる Dialogflow には処理を任せず、すべての音声入力をDialogflow からフォールバック先のサーバーに落として、無理矢理似た単語と一致させてしまって、解決する方法をとります。
工場や倉庫などで、使う業務システムは使用する単語が決まっているはずなので、この方法をとったほうが結果的にはユーザーの求める答えを提示できるはずです。
Googleが推奨する方法ではないと思いますが、Googleアシスタントの耳が遠いから仕方がありませんね。
トークスクリプトについては、前回のインタラクティブな内容は今回の趣旨から外れるので、一問一答方式に変更します。
ユーザー 「OK google 倉庫管理と話す」
google 「こんにちは。在庫管理です。探したい商品の名前を言ってください。」
ユーザー 「ピカチュウ」
google 「ピカチュウのぬいぐるみは倉庫の奥にあります。」
ユーザー 「ありがとう」
google 「どういたしまして」
いちいち○○してと言うと、音声認識が後ろの単語に引っ張られて間違った認識をすることが多いので、ユーザーには単語のみを発声してもらうようにします。
環境構築
Actions on google → Dialogflow → AWS Lambda
Acitons on Google の推奨言語はNode.jsなので、それを使っても良かったのですが、Pythonの標準ライブラリに今回やりたいことが簡単にできるライブラリがあったので、でフォールバック先のサーバーには AWS Lambda を使います。
AWS Lambda は 最近になって Python3が使えるようになったので、もちろんPythonは3を使います。バージョンは 3.6.3です。
DialogFlowで作るGoogleAssistant Agent - Google スライド
DialogFlowについてはいくつか記事を読みましたが DialogFlow についてはこの記事が網羅的かつわかりやすいです。
なので、この記事だけ読めば大丈夫です。
[Actions on Googleでapi.aiを使ってGoogle Homeに何か言わせてみる]
(https://qiita.com/syarihu/items/53ea1a65f481f8121109)
しかし、今回はこちらの記事の方が初期設定の部分においては詳細なので、こちらも読んでおきましょう。
まず始めに Python3でAWS lamda で関数を作成し、API gatewayを用いて APIを公開します。
実装については後で行うので、現時点では、postメソッドを受け付けるようになっていればOKです。
Dialogflowはあまり設定することはないのですが、
Agent名は GoogleHomeTest で作ります。Intent は特に追加せずデフォルトのままにします。
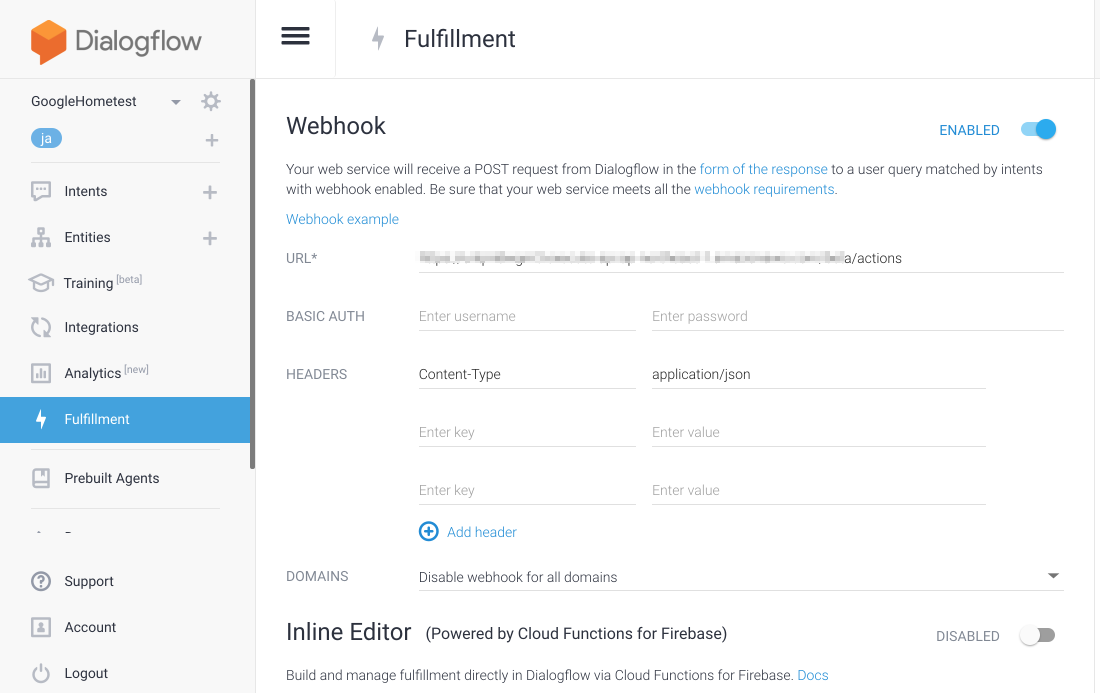
Fulfilment については 以下の様に POST先のURLとヘッダーを入力します。
下の方にスクロールすると Save というボタンが隠れているので忘れずに押しましょう。
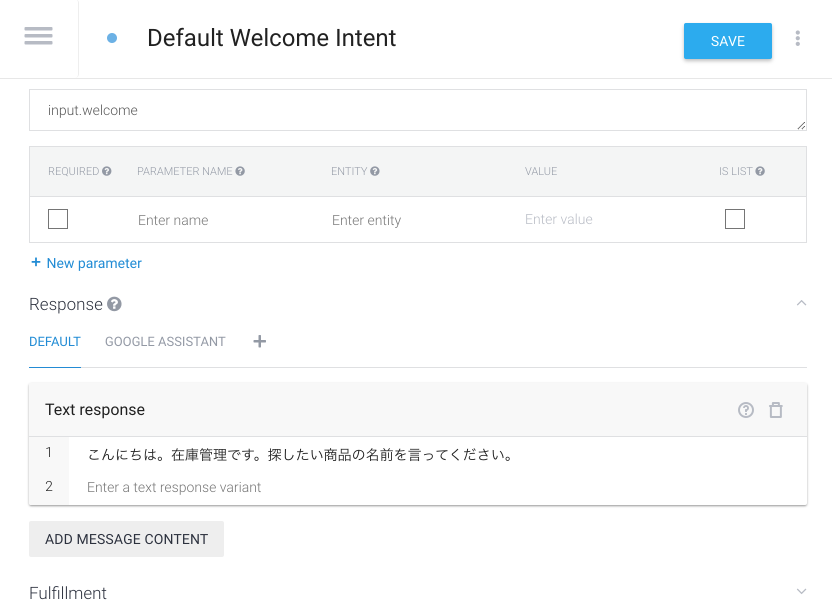
そのあと、intentsに戻り Default Welcome intent に以下の様に入力します。
これはアプリを起動させた時に、発話される内容です。
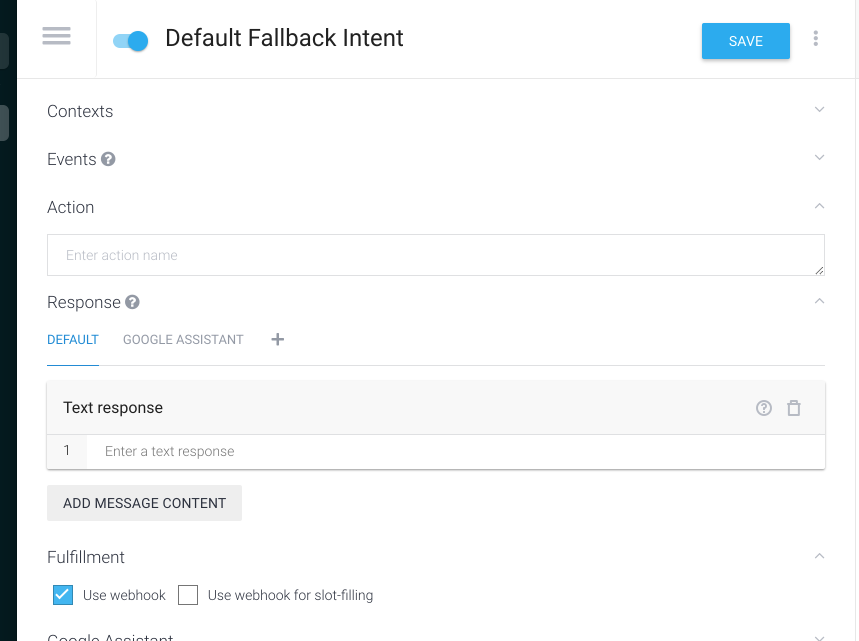
Default Fallback intent で Use webhook という項目ができているので、こちらにチェックをします。
通常はエラー処理に使うようになっているようですが、今回はここですべての発話をフォールバックサーバーに渡します。
これで環境構築が終わりました。
次は実装していきましょう。
実装
以下の内容をlambda 関数に入力します。
AWS は起動時に lambda_handler という関数が呼ばれ、
第1引数にpostされたjsonを受け取ることができるので、
そちらから Dialogflowから渡された、発話データを受け取ることができます。
event['result']['resolvedQuery'] というところに発話内容がそのまま代入されています。
lambda_handler で return した 値が jsonとして、Dialogflow に渡されます。
最低限以下の3つの値を返せば良いそうです。
{"speech": speech,
"displayText": speech,
"source": "Cloud"}
処理した結果をspeech に代入すると、Google Assistant が発話してくれるので、そこにユーザーに返したい答えを代入します。
尚、在庫データについては本来はS3に置くかDBにアクセスするかAPIを叩くか等をした方が良いですが、テストということで、ハードコーディングしています。
import difflib
import sys
import json # AWS lambda では不要だが、ローカルでの確認用にインポートする
# 在庫名はユニークにする
inventory = {
"ピカチュウのぬいぐるみ": "A-1",
"マイメロディのぬいぐるみ": "B-2",
"ピカチュウのフィギュア": "C-4",
"ドラえもんの貯金箱": "D-12",
}
def check_inventory_name(name):
"""
発話された内容と在庫名の一致をチェックしてヒットした在庫名のリストを返す
"""
real_names = []
# 完全一致チェック。ここで該当した場合、複数アイテムは返さない
if name in inventory:
real_names.append(name)
else:
# 部分一致チェック。複数アイテムが該当する可能性がある
for key in inventory.keys():
if name in key:
real_names.append(key)
if real_names == []:
# 部分一致しない場合でも、単語の類似度でチェック
# 類似度が0.5以上の場合は、探している在庫と一致することにする
for key in inventory.keys():
ratio = difflib.SequenceMatcher(None, name, key).ratio()
if ratio > 0.5:
real_names.append(key)
return real_names
def check_inventory_quantity(real_names):
result_items = {}
for real_name in real_names:
result_items[real_name] = inventory[real_name]
return result_items
def lambda_handler(event, context):
name = event['result']['resolvedQuery']
real_names = check_inventory_name(name)
result_items = check_inventory_quantity(real_names)
speech = ""
for i, result_item in enumerate(result_items):
if i == 3: # 3アイテム以上の結果を聞くのは長いので3アイテムで終わりにする
break
speech += result_item + "は" + str(inventory[result_item]) + "にあります。"
if not real_names:
speech = str(name) + "の在庫はありません。"
response = {"speech": speech,
"displayText": speech,
"source": "Cloud"}
return response
if __name__ == '__main__': # 以下はAWS lamda では動かない。
event = json.loads(sys.argv[1])
res = lambda_handler(event, "test")
print(res)
ソース上にもコメントしていますが、完全一致しない場合は部分一致で複数の結果を返す。
それでも一致しない場合は、Pythonの標準ライブラリである difflib を用いて
在庫データと発話内容の単語の類似度を計測して、一定以上の類似度になる在庫データを返すようにしています。類似度は0から1の間の値で1が完全一致です。なので、半分くらい一致しているならば、ユーザーが探している商品だと類推することにしました。
この点は運用して、良い感じの値に変えていくのがいいかもしれませんね。
このライブラリについてはこちらのページがくわしいので参照してください。
以上のような処理を行い、エラーをできるだけ返さないようにしてるのですが、それでも一致しない場合はただ「わかりません。すみません」と返すのではなく、ユーザーの発話内容をそのまま返す事で、何故エラーだったのかをわかる様にしています。
人間っぽくいうと耳が遠いんだなってわかれば、そんなにいらつきませんよね?
使ってみよう
こちらが言ったことを必ず検索してくれるし、エラーの場合も音声認識した結果を返してくれるので、かなり便利で、わかりやすくなりました!
さすが、コンピューターですね。
最後に
結構無理矢理な実装でしたが、いかがでしたでしょうか?
フォールバック先の負担が増えるとは思いますが、この程度のやり方でも、結構使い勝手がアップします。
本当はもっとスマートな方法が良いと思うので、知っている方は是非とも教えて下さい![]()