ベクトル検索における量子化とは
ベクトル検索は、セマンティック検索やマルチモーダル検索、画像検索やレコメンドなど様々な用途で使われる技術です。最近では RAG のコンテキストを取得する際にも採用されることの多い技術となっています。このベクトル検索はクエリベクトルと類似したベクトルを類似度が高い順に返すことが要求されますが、この処理は計算量が重く、かつ高速に処理をすることが求められるため様々な工夫が行われています。HNSW を代表とする近似 k-NN (Approximate k-NN, ANN) はデータ量が増えた場合でも効率的に近傍のベクトルを検索する手法であり、データ量が大きいユースケースでは近似 k-NN の利用は欠かせません。ただしこの近似近傍探索では (愚直な k-NN でもそうですが)、基本的に全てのベクトルデータをメモリ上に展開しておかないと高速な検索は実現できません (ストレージから逐一ベクトルデータを読み込んでいると遅延が発生する)。つまり、大規模なデータに対して高速なベクトル検索を実現しようとした場合、大規模なメモリが必要になります。
そこで登場するのが「量子化 (Quantization)」です。量子化とはデータ圧縮の手法のことで、高精度の形式から低精度の形式に変換する処理のことを指します。この量子化を行うことで、精度をやや犠牲にしつつも消費メモリを抑えることが可能になり、コストの最適化が可能です。量子化にはいくつかの手法がありますが、ここではスカラー量子化 (Scalar Quantization, SQ) と直積量子化 (Product Quantization, PQ) について触れます。
- スカラー量子化
スカラー量子化は文字通りベクトルの各次元のスカラー値を低い精度の値に変換する量子化方法です。例えば、float32 → float16 へ変換したり、float16 → int8 へと変換したりするのがスカラー量子化です。スカラー量子化では、実装が単純で計算コストが比較的低く、また事前の学習などは必要ありません。
- 直積量子化
直積量子化はスカラー量子化よりも高い圧縮率を実現可能な量子化手法です。直積量子化では、各ベクトルを m 個のサブベクトルに分割し、各サブベクトルを、コードブックのベクトルに置き換えて表現します。コードブックのベクトルとは、サブベクトルを量子化するための代表ベクトルの集合のことです。この量子化手法ではデータに基づいてコードブックを作成するために事前に学習が必要となります。
直積量子化の処理の流れのイメージは以下の通りです(一例です)。
まず学習対象のベクトルをサブベクトルに分割します。それらのサブベクトルを k-Means クラスリングのようなクラスタリング手法を用いてクラスタリングし、そのセントロイドを代表ベクトルとします。
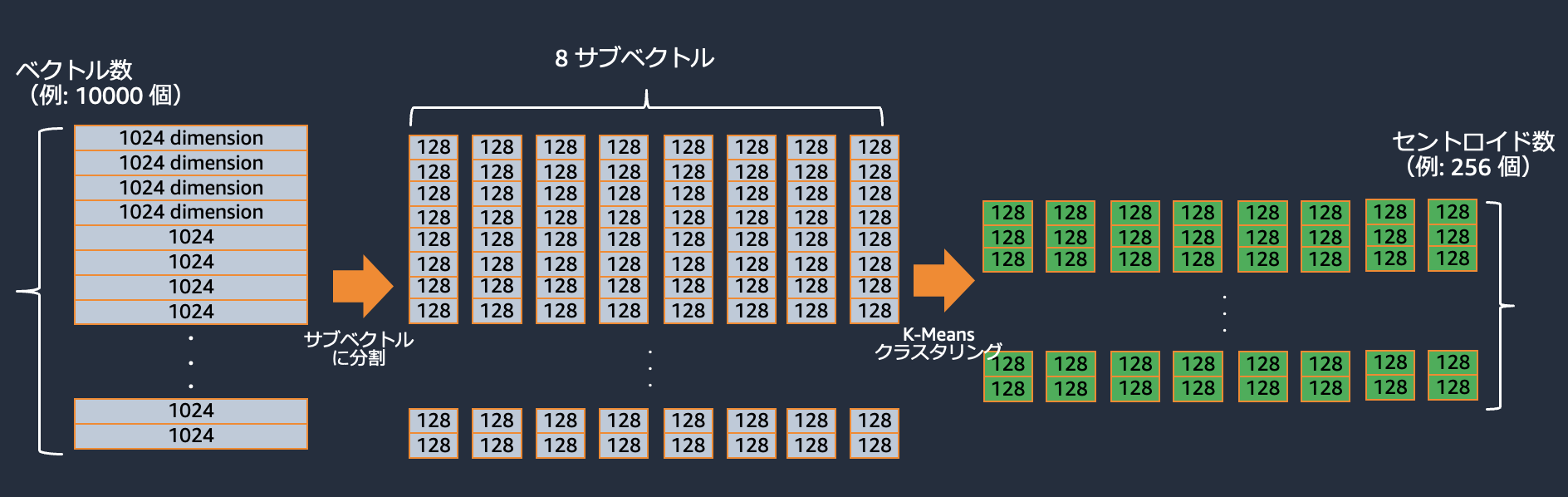
代表ベクトルの集合であるコードブックから、各ベクトルを表現します。
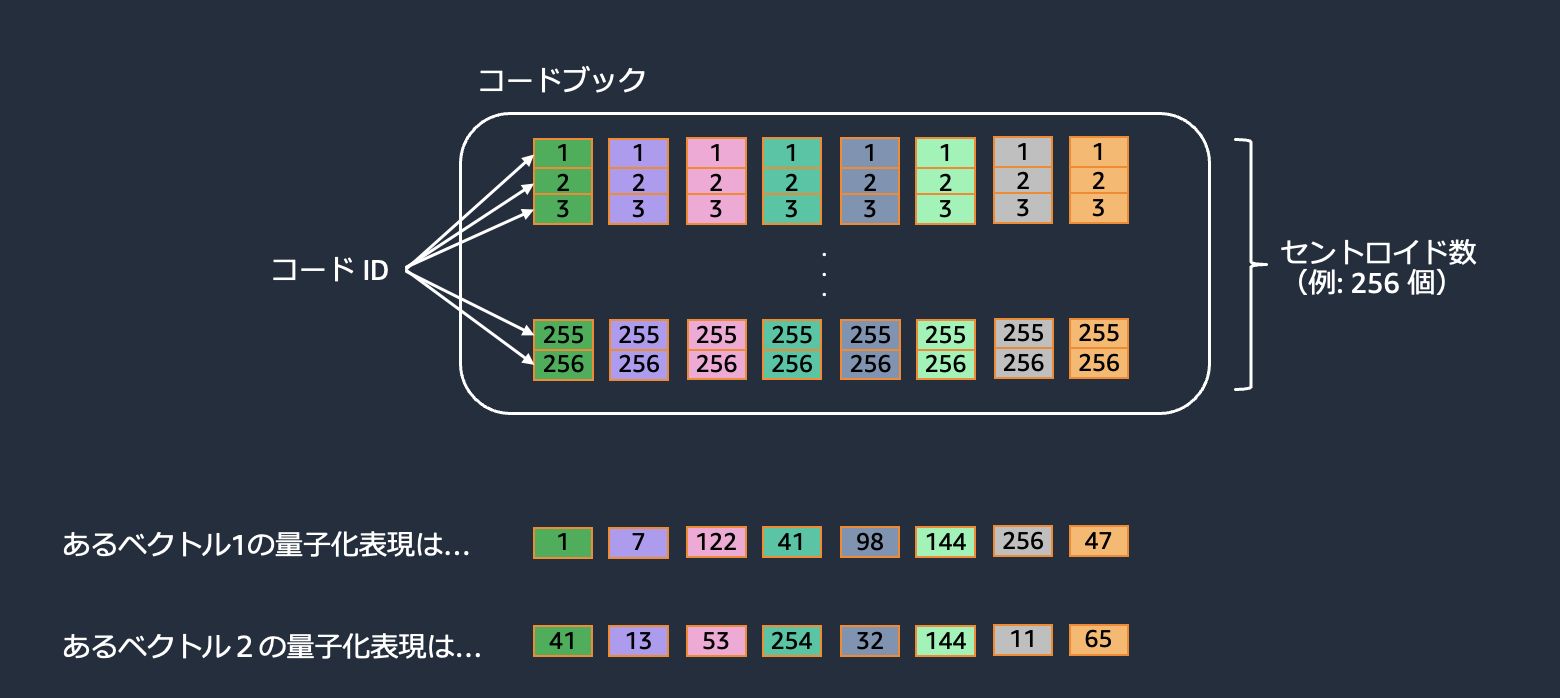
この手法ではそれぞれのベクトルを表現するために、ベクトルの値を持つ代わりにコードブックの ID 番号だけを管理すれば良いため、大きな圧縮効果をもたらします。ただし、圧縮効果が大きいとその分精度は犠牲になります。
OpenSearch におけるベクトル量子化
OpenSearch のベクトル検索機能でも量子化に対応しています。当初は OpenSearch では直積量子化のみに対応しておりました。しかし、OpenSearch 2.9 で Lucene エンジンが byte ベクトルをサポートしてから、OpenSearch でスカラー量子化の対応が進んできています。OpenSearch でどのように量子化に対応しているかを現時点 (OpenSearch 2.18 が最新バージョン) の情報で説明します。
OpenSearch における直積量子化
OpenSearch では近似 k-NN のエンジンとして、Faiss、Nmslib、Lucene の 3 種類のエンジンが用意されています。その中で Faiss エンジンのみが直積量子化に対応しています。また、近似 k-NN のアルゴリズムとしては HNSW、IVF の 2 種類のアルゴリズムが用意されていますが、Faiss を使う場合そのどちらのアルゴリズムにおいても直積量子化が利用できます。
OpenSearch におけるスカラー量子化
スカラー量子化を利用する場合、量子化をどこで実行するかという部分において幾つかの方法が考えられます。一つは、OpenSearch上で実装された Quantizer を利用することです。また、量子化は OpenSearch の外、つまりアプリクライアント上で実行するという方法も考えられます。また、ベクトル化する埋め込みモデルが int8 や binary での出力に対応している場合もあります。
OpenSearch上で実装された Quantizer を利用する場合、現在は、Faiss エンジンでは SQfp16 Encoder (32 bit → 16 bit の Quantizer)、Lucene エンジンでは Lucene scalar quantizer (32 bit → 7bit の Quantizer) が利用可能です。これらの Quantizer はデータを投入する時やデータの検索をするときに入力のベクトルに対して適用されるもので、OpenSearch 内部では量子化されたベクトルのみが保存されます。
一方、OpenSearch 2.17 では on_disk モードという検索モードが Faiss エンジンで利用できるようになりました。この方式では、ストレージでは量子化前の元のベクトルを保持しておきながら、メモリでは量子化されたベクトルを保持します。on_disk モードでの検索では、2 ステップの処理が行われます。まず、メモリ上に展開された量子化済のベクトルを使ってベクトル検索を行います。そして、このステップで取得されたベクトルの元のベクトルをストレージから読み込み、スコアを再計算して並び替えを行います (正確に言うと、最初のステップでラフな精度で必要な個数よりも多めにデータを取得し、その後精度高く並び替えて必要な個数のデータを返却します)。これにより、メモリを節約しながらも量子化による精度の低下を抑えることが可能になります。これまでは大きな圧縮率を実現するには直積量子化を利用するしかありませんでしたが、そのためには学習が必要で若干扱いが難しいという問題がありました。しかし、on_disk モードでは、大きな圧縮率 (最大 32 倍) を実現できる上に学習が不要で、かつ精度の低下も抑えられるという利点があります。ただし、ストレージからの読み込みを含む多段の処理が行われるため、レイテンシーが通常の近似 k-NN よりも発生してしまうと言う欠点もあります。on_disk モードが導入された背景はこちらの [RFC] Optimized Disk-Based Vector Search を読むと分かりやすいです。
また、OpenSearch の外で量子化を実行する場合 (クライアント上 or モデルの出力)、byte 型 や、binary 型 が利用可能です。
量子化の効果を確認する
簡単な実験をして量子化の効果を確認してみます。今回は、量子化を利用することでどれくらいの省メモリ効果があるのか、また精度やレイテンシーにどの程度影響があるのかを調査します。検証では、OpenSearch Benchmark を使用しています。また、OpenSearch Benchmark には Workload という概念があり、ベンチマークのシナリオごとに検証することができます。opensearch-benchmark-workloads というレポジトリに、OpenSearch が公式に提供している Workload が公開されており、今回はその中の Vector Search Workload を使用します。データセットはこの Workload 経由でダウンロードできるものを利用し (参考)、cohere-1m を選択しました。これは Wikipedia のデータを Cohere の埋め込みモデルで埋め込んだベクトルデータ 100 万件のデータセットと思われます。検証環境は、OpenSearch Service においてデータノード r7g.large.search 3 台の構成として、OpenSearch のバージョンは 2.17 を利用して、ベンチマークツールは g6.xlarge の EC2 上で実行しました。(OpenSearch Benchmark で Sigv4 認証を利用する場合は Running OpenSearch Benchmark with AWS Signature Version 4 を参照すると良いです。)
今回は、以下の 3 つの設定を比較します。量子化なしとスカラー量子化の 2 パターンです。(直積量子化の効果については、OpenSearch における 10 億規模のユースケースに適した k-NN アルゴリズムの選定 を参照ください。)
- Float32 (量子化なし)
- Float16 (32 bit → 16 bit の量子化)
- Binary (on_disk モードを利用、32 bit → 1 bit の量子化)
OpenSearch Benchmark パラメータ設定
- Float32
{
"target_index_name": "faiss-fp32",
"target_field_name": "target_field",
"target_index_body": "indices/faiss-index.json",
"target_index_primary_shards": 3,
"target_index_dimension": 768,
"target_index_space_type": "innerproduct",
"target_index_bulk_size": 100,
"target_index_bulk_index_data_set_format": "hdf5",
"target_index_bulk_index_data_set_corpus": "cohere-1m",
"target_index_bulk_indexing_clients": 10,
"target_index_max_num_segments": 1,
"hnsw_ef_search": 256,
"hnsw_ef_construction": 256,
"query_k": 100,
"query_body": {
"docvalue_fields": [
"_id"
],
"stored_fields": "_none_"
},
"query_data_set_format": "hdf5",
"query_data_set_corpus": "cohere-1m",
"query_count": 10000
}
- Float16
{
"target_index_name": "faiss-fp16",
"target_field_name": "target_field",
"target_index_body": "indices/faiss-index.json",
"target_index_primary_shards": 3,
"target_index_dimension": 768,
"target_index_space_type": "innerproduct",
"target_index_bulk_size": 100,
"target_index_bulk_index_data_set_format": "hdf5",
"target_index_bulk_index_data_set_corpus": "cohere-1m",
"target_index_bulk_indexing_clients": 10,
"target_index_max_num_segments": 1,
"hnsw_ef_search": 256,
"hnsw_ef_construction": 256,
"query_k": 100,
"query_body": {
"docvalue_fields": [
"_id"
],
"stored_fields": "_none_"
},
"encoder": "sq",
"query_data_set_format": "hdf5",
"query_data_set_corpus": "cohere-1m",
"query_count": 10000
}
OpenSearch Benchmark Vector Search ワークロードの No Train Test モードが encoder パラメータに対応していたなかったので、fp16 の実証をする時は以下のように indices/faiss-index.json のコードを変えています。
{
"settings": {
"index": {
"knn": true
{%- if target_index_primary_shards is defined and target_index_primary_shards %}
,"number_of_shards": {{ target_index_primary_shards }}
{%- endif %}
{%- if target_index_replica_shards is defined %}
,"number_of_replicas": {{ target_index_replica_shards }}
{%- endif %}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
{% if id_field_name is defined and id_field_name != "_id" %}
"{{id_field_name}}": {
"type": "keyword"
},
{%- endif %}
"target_field": {
"type": "knn_vector",
"dimension": {{ target_index_dimension }},
{%- if mode is defined %}
"mode": "{{ mode }}",
{%- endif %}
{%- if compression_level is defined %}
"compression_level": "{{ compression_level }}",
{%- endif %}
{%- if train_model_id is defined %}
"model_id": "{{ train_model_id }}"
{%- else %}
"method": {
"name": "hnsw",
"space_type": "{{ target_index_space_type }}",
"engine": "faiss",
"parameters": {
{%- if hnsw_ef_search is defined and hnsw_ef_search %}
"ef_search": {{ hnsw_ef_search }}
{%- endif %}
{%- if hnsw_ef_construction is defined and hnsw_ef_construction %}
{%- if hnsw_ef_search is defined and hnsw_ef_search %}
,
{%- endif %}
"ef_construction": {{ hnsw_ef_construction }}
{%- endif %}
{%- if hnsw_m is defined and hnsw_m %}
{%- if hnsw_ef_construction is defined and hnsw_ef_construction %}
,
{%- endif %}
"m": {{ hnsw_m }}
{%- endif %}
{%- if encoder is defined and encoder %}
{%- if hnsw_m is defined and hnsw_m %}
,
{%- endif %}
"encoder": {
"name": "{{ encoder }}"
}
{%- endif %}
}
}
{%- endif %}
}
}
}
}
- Binary
{
"target_index_name": "faiss-ondisk-32x",
"target_field_name": "target_field",
"target_index_body": "indices/faiss-index.json",
"target_index_primary_shards": 3,
"target_index_dimension": 768,
"target_index_space_type": "innerproduct",
"target_index_bulk_size": 100,
"target_index_bulk_index_data_set_format": "hdf5",
"target_index_bulk_index_data_set_corpus": "cohere-1m",
"target_index_bulk_indexing_clients": 10,
"target_index_max_num_segments": 1,
"hnsw_ef_search": 256,
"hnsw_ef_construction": 256,
"mode": "on_disk",
"query_k": 100,
"query_body": {
"docvalue_fields": [
"_id"
],
"stored_fields": "_none_"
},
"query_data_set_format": "hdf5",
"query_data_set_corpus": "cohere-1m",
"query_count": 10000
}
メモリ使用量の違い
まず、量子化の有無により、実際にメモリに展開されているベクトルデータのサイズにどの程度差が出るのか確認してみます。その際、メモリにベクトルデータを展開するため、あらかじめ warmup API を実行する必要があります。(OpenSearch Benchmark Vector Search ワークロードでは自動で warmup を実行してくれます。)
以下が実行結果です。これを見ると、Binary (faiss-ondisk-32x) の量子化では、量子化なしのインデックスに比べて大きく使用メモリを節約できていることがわかります。また、Float16 でも量子化なしと比べて半分近くメモリの使用量を抑えることができています。Binary の量子化でメモリ使用量が 1/32 になっていないのはベクトルデータ以外のデータ (HNSW の場合はグラフの接続情報など) もメモリ上に展開しているためと考えられます。
GET _plugins/_knn/stats/indices_in_cache
{
"_nodes": {
"total": 3,
"successful": 3,
"failed": 0
},
"cluster_name": "xxx",
"nodes": {
"ksJ6eGV3RquYB9_E1uWABQ": {
"indices_in_cache": {
"faiss-ondisk-32x": {
"graph_memory_usage_percentage": 3.5122137,
"graph_memory_usage": 161560,
"graph_count": 2
},
"faiss-fp32": {
"graph_memory_usage_percentage": 45.612495,
"graph_memory_usage": 2098151,
"graph_count": 2
},
"faiss-fp16": {
"graph_memory_usage_percentage": 23.883314,
"graph_memory_usage": 1098620,
"graph_count": 2
}
}
},
"o5wt-_mqTKWeKJBkWI-mxQ": {
"indices_in_cache": {
"faiss-ondisk-32x": {
"graph_memory_usage": 161708,
"graph_memory_usage_percentage": 3.515431,
"graph_count": 2
},
"faiss-fp32": {
"graph_memory_usage": 2100065,
"graph_memory_usage_percentage": 45.654102,
"graph_count": 2
},
"faiss-fp16": {
"graph_memory_usage": 1099622,
"graph_memory_usage_percentage": 23.905096,
"graph_count": 2
}
}
},
"Cv8InV-ER0OgcHp5vM2iXA": {
"indices_in_cache": {
"faiss-ondisk-32x": {
"graph_memory_usage": 161640,
"graph_memory_usage_percentage": 3.5139527,
"graph_count": 2
},
"faiss-fp32": {
"graph_memory_usage": 2099190,
"graph_memory_usage_percentage": 45.635082,
"graph_count": 2
},
"faiss-fp16": {
"graph_memory_usage": 1099164,
"graph_memory_usage_percentage": 23.89514,
"graph_count": 2
}
}
}
}
}
精度とレイテンシーの違い
以下にそれぞれの方法によるレイテンシーと精度 (Recall) を示します。この結果を見ると、32 bit から 16 bit への量子化では、レイテンシーや精度にほとんど影響がないことが確認できます。Binary への量子化では、大きく使用メモリを削減している分若干精度やレイテンシーへの影響があることが確認できます。
| Vector Type | p90 Latency (ms) | p99 Latency (ms) | p99.9 Latency (ms) | recall@100 | recall @1 |
|---|---|---|---|---|---|
| Float32 | 23.0 | 31.5 | 50.0 | 0.97 | 1.00 |
| Float16 | 23.3 | 30.9 | 51.5 | 0.97 | 0.99 |
| Binary (on_disk) | 23.4 | 74.2 | 140.8 | 0.67 | 0.92 |
今回の結果は、使用するアルゴリズムとそのパラメータであったり、また on_disk モードについてはディスクへのアクセスがどの程度発生するかなどによっても変わりうるもののため、あくまで参考値である点にはご留意ください。
まとめ
本記事では、OpenSearch が最近力を入れて取り組んでいる量子化についてまとめ、簡易な実験を通してその効果や影響を確認しました。以前よりサポートしていた直積量子化に加え、スカラー量子化の選択肢が増えてきたことで、よりユーザーの要件に合わせて柔軟に量子化を利用できるようになりました。OpenSearch Project Roadmap 2024–2025 においても、量子化を含むコスト最適化への取り組みを進めていくと述べられています。こうした発展により、大規模なベクトル検索ワークロードの実用化を進めやすい環境になるでしょう。