「Applibot Advent Calendar 2021」8日目の記事です。
ワードクラウドが面白そう
日経の記事にて、ワードクラウドを用いて所信表明を分析している記事があった。

引用元:首相所信表明、「分配」半減 キーワード分析
記事によると
キーワードの登場頻度や特異性などを文字の大きさで示す「ワードクラウド」の手法を使って演説の特徴を可視化した。ビッグデータ分析のユーザーローカルのテキスト分析ツールで調べた。
とのことで、記事ではユーザーローカルのツールを使って作っているらしい。
所信表明のワードクラウドを自前で作ったら面白いのではと思った。
この記事で目指すこと
- 岸田総理の所信表明のワードクラウドの画像を作成する
- 出来るだけルールベース(恣意的な単語の除外はしない)で、有用な情報が引き出せる
こととする。
進め方
軽く調べると、
- Pythonで割と簡単に出来る
- 日本語を対応するには追加で対応が必要
と分かった。
そこで、
- ①英語の文章からワードクラウド画像を生成する(環境構築)
- ②日本語対応
- ③アウトプットの精度向上
の順で対応する。
①英語の文章からワードクラウド画像を生成する(環境構築)
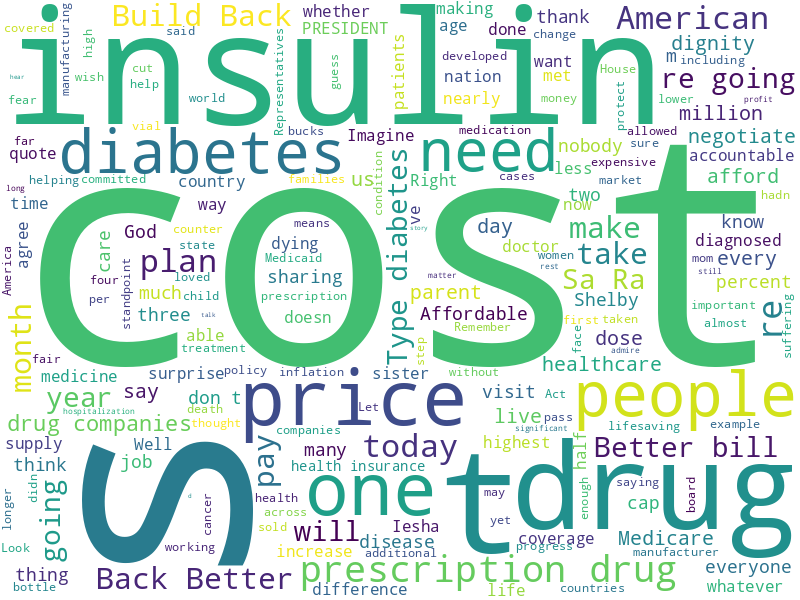
アウトプットがこちら。
Remarks by President Biden on Prescription Drug Costs
という、バイデン大統領の演説を用いた。
タイトル通り、Costが頻出であることがわかる。
環境構築
実際のコードはこちら。
https://github.com/growsic/word_cloud_japanese/tree/feature/english-only
wordcloudをimportするだけで、簡単に構築出来る。
実装はほとんど必要ない。
フォルダ構成(Docker × Python)
.
├── Dockerfile
├── docker-compose.yml
└── opt
├── sample.py ←実装箇所
├── speech.txt ←読み込ませるテキスト
└── wordcloud.png ←出力ファイル
sample.py
# 使用するモジュールをimport
import wordcloud, codecs
# テキストファイルを読み込み
file = codecs.open('opt/speech.txt', 'r', 'utf-8', 'ignore')
text = file.read()
# テキストからwordcloudを生成
wordc = wordcloud.WordCloud(background_color='white', width=800, height=600).generate(text)
# 画像ファイルとして保存
wordc.to_file('opt/wordcloud.png')
ただし日本語は扱えない
この状態で日本語を読ませると下記のように文字化けする。
理由は
- wordcloudが日本語を単語に分解(形態素解析)ができない
- 日本語のフォントに対応していない
から。
次にこの日本語問題を対応する。
②日本語対応
①で対応出来なかった日本語に対応する。
アウトプットはこちら。
助詞・助動詞などが多すぎて何も情報がない。しかし日本語が表示できるようになった。

環境構築
実際のコードはこちら。
https://github.com/growsic/word_cloud_japanese/tree/feature/impl-for-japanese
[Mecab]日本語の形態素解析の対応
Mecabという形態素解析エンジンがあるのでこちらを利用する。
mecab-python3をpip installするだけでは足りず少々手間取った。
DockerFileへの追加
RUN apt install -y mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file swig
RUN apt-get install mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8
RUN pip install mecab-python3
使い方は簡単で、Mecabを初期化しテキストを渡すだけ。
下記ではsplittedが日本語を形態素解析してスペース区切りになった文字列になる。
これをwordcloudに渡すことで日本語で扱えるようになる。
m = MeCab.Tagger('')
parsed = m.parse(text)
splitted = ' '.join([x.split('\t')[0] for x in parsed.splitlines()[:-1]])
参考:
MecabをPythonで使うまで
Pythonでワードクラウド作り②日本語版
フォント対応
Mecabを入れただけではwordcloudが画像出力時に日本語を出力できない。
手動でフォントをダウンロード&配置をしている例も多かったが、Docker完結にしたかったためIPAexGothicを使うことにした。
RUN RUN apt install -y fonts-ipaexfont
fonts-ipaexfontを追加しフォントのパスを渡すことで表示できるようになる。
fpath = "/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf"
wordc = wordcloud.WordCloud(
font_path=fpath,
background_color='white',
width=800,
height=600).generate(splitted)
参考:IPAexGothicによるMatplotlibの日本語化【Python】
③アウトプットの精度向上
ワードクラウドの画像の精度を上げるべく、一つずつ試していく。
②の時点ではこちら。
助詞、助動詞を除外してみる
Mecabの形態素解析に単語の種別が取得できる。
そこで助詞/助動詞を除外してみる。
def is_target_word(word: str, word_type: str) -> bool:
if word_type in ['助詞', '助動詞']:
return False
return True
単語がかなり拾えるようになったが、「ため」「する」「こと」など、意味の薄い単語が残っている。

これは
こと 名詞
し 動詞
あり 動詞
など、名詞や動詞の単語があるからである。
ひらがなを正規表現で除外する
単語の種別による分解はやめ、
- ひらがなのみで構成される単語
- 1文字のみの単語
を除外するようにした。
def is_target_word(word: str, word_type: str) -> bool:
# ひらがなのみから構成される単語を除外
pattern = re.compile(r'[あ-ん]+')
if pattern.fullmatch(word):
return False
# # 1文字単語は除外
if len(word) == 1:
return False
return True

首相が頻繁に使いそうな経済、実現、成長、社会、世界などの単語が頻出単語になった。
マクロな分析としてはこれで良いのだが、**「首相が今回何について言及していたか」**については読み解けない。
何を語るにしても登場する「経済」や「実現」というワードが邪魔である。
頻出すぎる単語は除外する
単語を出現回数順にトップ100を並べると下記のようになっている。
ざっくり上位10-30件程度を除外すれば精度が上がりそうに見える。
[('経済', 27), ('実現', 18), ('進め', 17), ('成長', 17), ('社会', 16), ('対応', 16), ('世界', 15), ('デジタル', 15), ('強化', 15), ('向け', 13), ('資本 主義', 13), ('我が国', 12), ('新型 コロナ', 12), ('課題', 11), ('新た', 11), ('日本', 11), ('安全 保障', 11), ('国民', 10), ('時代', 10), ('規模', 10), ('支援', 10), ('行い', 10), ('投資', 10), ('新しい 資本', 10), ('目指し', 9), ('状況', 8), ('医療', 8), ('未来', 8), ('賃上げ', 8), ('取り組み', 7), ('含め', 7), ('確保', 7), ('活用', 7), ('進める', 7), ('取組', 7), ('分野', 7), ('企業', 7), ('我々', 6), ('ワクチン', 6), ('感染', 6), ('基づき', 6), ('全体', 6), ('行動', 6), ('連携', 6), ('整備', 6), ('分配', 6), ('推進', 6), ('地域', 6), ('重要', 6), ('国会', 6), ('国民 皆さん', 6), ('信頼', 5), ('協力', 5), ('対策', 5), ('大きく', 5), ('理解', 5), ('財政', 5), ('事業', 5), ('問題', 5), ('抜本', 5), ('自由', 5), ('大学', 5), ('研究', 5), ('会議', 5), ('国際', 5), ('全力 取り組み', 5), ('感染 危機', 5), ('受け', 4), ('新しい', 4), ('議員', 4), ('全て', 4), ('丁寧', 4), ('挑戦', 4), ('覚悟', 4), ('多く', 4), ('確認', 4), ('投入', 4), ('米国', 4), ('安心', 4), ('健康', 4), ('体制', 4), ('病床', 4), ('行う', 4), ('可能', 4), ('検査', 4), ('治療', 4), ('程度', 4), ('子育て', 4), ('に対し', 4), ('後押し', 4), ('世代', 4), ('戦略', 4), ('共に', 4), ('果たし', 4), ('大胆', 4), ('イノベーション', 4), ('積極', 4), ('解決', 4), ('教育', 4), ('行政', 4)]
wordcloudのwordc.process_text()というメソッドを使うと単語が出現回数とともに取得できる。
出現回数順にソートして上位N件を取り、表示
対象から除外する。
# 集計から除外する出現回数上位の順位閾値
HIGH_FREQUENCY_WORD_COUNT_THREHOULD = 30
# 出現頻度が高いワードを除外
tab_separated_str = ' '.join([x.split('\t')[0] for x in m.parse(text).splitlines()[:-1] if is_target_word(x.split('\t')[0], x.split('\t')[1].split(',')[0])])
frequency_dict = wordc.process_text(tab_separated_str)
# 出現上位の単語を頻度とともに出力
high_frequency_word_list = [x[0] for x in sorted(frequency_dict.items(), key=lambda item: item[1], reverse=True)[:HIGH_FREQUENCY_WORD_COUNT_THREHOULD]]
# 出現上位のワードを省きwordcloud用のタブ区切り文字列を生成
tab_separated_str = ' '.join([x.split('\t')[0] for x in m.parse(text).splitlines()[:-1] if x.split('\t')[0] not in high_frequency_word_list and is_target_word(x.split('\t')[0], x.split('\t')[1].split(',')[0])])
結果がこちら。

(集計から除外する出現回数上位の順位閾値は30)
- 新型コロナ
- 新しい資本(主義)
- ワクチン
- 安全保障
など、何について語ったか分かる程度になった。
出現回数上位の除外件数の閾値によってアウトプットが変わってきてしまうが、簡易的に情報を引き出すには良いアプローチだったと言えそうだ。
最終的な実装はこちら
10月の演説と12月の演説の比較
日経の記事首相所信表明、「分配」半減 キーワード分析では10月と12月の演説の比較を行なっていたので同様に比較してみる。
集計から除外する出現回数上位の順位閾値は10で比較している。
(恣意的な調整になるが、30だと分配というワードが10月では12回で除外されてしまうため)
10月

12月

「分配」というキーワードが今回大きく減ったことが比較でわかる。
具体的な政策では19回登場した「デジタル」や8回の「賃上げ」が目立った。
一方で、日経記事内で言及されている「デジタル」は、除外の閾値内に入ったため除外されてしまった。
これを鑑みるに、
- 差分が小さい2点を比較するには、単語除外ロジックのチューニングが必要
- 上手くチューニングしないと、取れていたはずのマクロな情報まで抜け落ちてしまう
であり、wordcloudから自動で簡単に単語を引き出すのは難しいと言えそうである。
日経のWordCloudと今回のWordcloudを比較してみる
日経
今回
コロナや資本主義など、概ね主題は同じになっていると言える。
一方で人間の感覚として自然な「新型コロナウイルス」「新しい資本主義」などはMecabから見ると単語は別単語に分解されてしまっているが、日経版では1単語として扱われている。
ニュースとして一般的に使う単語の組み合わせは一単語として扱えるよう、何らかのチューニングをしているのかもしれない。
また、日経の記事では
10月は一度も使わなかった「改革」を2回用いた。
など、WordCloudには現れにくい出現頻度の低い単語に着目して執筆されている。
逆に言えばWordCloudではマクロな情報しか引き出せず、ミクロな差分情報を引き出すのは難しいと言えるのではないだろうか。
結論
WordCloudを使った単語の出現頻度可視化は比較的簡単
日本語対応するのに若干手間取るがあまり手間はかからない。
実際に使ってみたい方はこちらから。
https://github.com/growsic/word_cloud_japanese/tree/master
WordCloudはマクロな分析は簡単にできるが、有用な情報を引き出すのは難しい or チューニングが必要
WordCloudの環境構築が簡単にできる分、遊びどころがあって楽しいところでもある。