背景
- Web系の会社でデータサイエンティスト2年目をしている
- 評価指標入門を読んで、「KPIを改善するモデル」を良いモデルと判断する評価指標を選ぶこと、の重要性がなんとなくわかった
- 実際に評価指標がビジネスの意思決定に与える影響をシミュレーションすることで、評価指標の適切な選び方を体得したい
取り組み概要
ビジネス背景が異なる二値分類問題それぞれにおいて、どの評価指標によって選ばれたモデルがKPIを改善するかをシミュレーションする
- Precisionが重要・中程度の不均衡データ:スパムメールの検知
- Recallが重要・極度の不均衡データ:機械の故障の検知
取り組み詳細
検証1. Precisionが重要・中程度の不均衡データ
問題設定
- スパムのメールを迷惑フォルダに分類しつつ、できるだけ通常のメールは迷惑フォルダには流れないようにしたい
-
SMS Spam Collection Dataset
- スパムを含むSMSのテキストメッセージのデータ
- 目的変数:SMSがスパムかどうか
- 目的関数:logloss
- 評価指標:F-betaスコア
- KPI:スパム分類を導入した場合のユーザー体験の損失を定量化したもの
- 「スパムかどうか」「迷惑フォルダかどうか」の組み合わせは4つが考えられ、TPを大きくしたいが、FPは小さく抑える必要がある
- TP:スパムを迷惑フォルダに入れる
- FP:通常メッセージを迷惑フォルダに入れる→重要な情報を逃す可能性
- FN:スパムを通常フォルダに入れる→少し邪魔
- TN:通常メッセージを通常フォルダに入れる
- 仮定したコスト行列(未知として、テストデータへの予測精度の評価時にのみ用いる。単位は1円とする)

分析内容
- TFIDFでスパムのテキストを定量データに変換
- ロジスティック回帰でスパムかどうかを予測する二値分類モデルを作成
- F0.5スコアとF1スコアで評価した場合に選ばれたモデルそれぞれで、テストデータに対する予測をおこない、どちらがコストを小さくできるか比較する
- 今回は適合率重視なのでF0.5スコアが正しいと考えられるが、誤ってF1スコアを選ぶ場合に比べてどれだけ結果が変わるのかを確認したい
結果
-
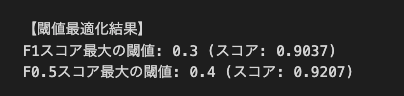
F1スコアだと閾値0.3、F0.5スコアだと閾値0.4が選択された
-
真のコスト行列を用いてコストを算出した結果、F0.5スコアで選ばれた閾値の方が、F1スコアで選ばれたナイーブベイズよりも優れていた
-
コストの分解(最も右)を見てみても、F1スコアモデルでは、FP(通常メッセージを迷惑フォルダに入れる)のコストが大きくなっている

検証2. Recallが重要・極度の不均衡データ:機械の故障の検知
対象データ
- Predictive Maintenance Dataset
- 各デバイスx各日における故障有無と、故障有無に関連すると思われる指標(匿名化済み)
- 目的変数:故障有無
- 目的関数:logloss
- 故障有無の各予測結果に対するコスト(万円)は下記を仮定する
- 検証するとその間の1日の粗利(100万)が失われる
- 故障すると修理に1億、10日間の営業停止で100,000万かかる
- TP,FP: 検査を実施し故障はなくなる:100万
- FN: 故障し営業停止にもなる: 101,000万
- TN: なし
- コスト行列(既知)

分析内容
- LightGBMで故障有無を予測するモデルを作成
- 時系列が逆転しないよう、train,valid,testを分ける
- optunaでパラメータは最適化
- 閾値を0.1,0.3,0.5,0.7,0.9と5つ試す。その中で、F2スコアが最も大きいものと、コスト行列をもとに算出した期待損失が最も小さいモデル2つを選ぶ
- 2つのモデルについて、testデータに対して分類を実施した上でコスト行列からコストを計算し比較する

結果
- F2スコアベースで選んだ閾値と、コスト行列から算出される期待損失でモデルを選んだ場合で比較すると、期待損失を使う方がtestにおける損失が小さくなった
- 期待損失が既知or推測可能であれば、織り込んだ方がよりKPIを直接モデリングできそう
- 今回は極度に不均衡なデータであったため、F2スコアでは足りずβを大きくしたほうがよい

まとめ
- F-betaスコアのbetaを適切に設定するかどうかで、結果に大きな影響が出ることもある
- コスト行列が推定可能であれば評価には使っていくべき
補足
- 今回は、アクションが0or1に分ける必要があるので、閾値によらない評価指標(ROC-AUCやPR-AUCなど)は用いなかった
- 閾値によらない評価指標が求められるのは、予測確率のグラデーションに合わせて施策が変わる(施策が2パターンではないとき)か
- 今回の1.2.では、正例にしか興味がない(負例のうちどれだけ当てられているかは興味がない)ので、PR-AUCがよさそう。ROC-AUCがよいのは、バランスよく評価したい場合、例えば、クラス0とクラス1で別の施策をおこない、リターンとコストが同等のときには、ROC-AUCが適切と考える