はじめに
物体検出技術は、コンピュータビジョン分野において基本的かつ難解なタスクとして知られています。これまでの研究で多く使われてきた主流の検出器、たとえばFaster R-CNNやSSD、YOLOv2, v3などは、所定の「アンカーボックス」に依存しています。これらのアンカーベースの検出器は、非常に優れた結果を出してきましたが、いくつかの欠点が指摘されています。
しかし2018〜2019年頃、Fully Convolutional Network(FCN)が密な予測タスクで驚異的な成功を収めてきました。これを受けて、物体検出の分野でもFCNのアプローチが取り入れられるようになってきました。特にFCOS(Fully Convolutional One-Stage Object Detector)というアーキテクチャが提案され、これまでのアンカーベースのアプローチに代わる可能性を秘めていると注目されました。
FCNベースのフレームワークは、特定のドメインでの物体検出には一定の成果を上げてきましたが、複数の重なったバウンディングボックスを持つ一般的なオブジェクト検出には適していないとの認識がありました。ところが、FPNの採用や「Centerness」ブランチの導入などの手法を組み合わせることで、FCNベースの方法でも従来のアンカーベースの検出器と同等、あるいはそれ以上の精度を得ることができることが示されました。
本記事では、FCOSのアーキテクチャについて、論文とtorchvisionの実装をベースに解説していきます。FCOSの特徴は以下の通りです。
- 一段階の物体検出アプローチ
- 多段階の手法(例:Faster R-CNNが提案と検出の二段階を使用)とは異なり、FCOSは物体検出を一段階で行います。
- アンカーボックス不要のアーキテクチャ
- RetinaNet、SSD、YOLOv3、Faster R-CNNなどの多くの先進的なオブジェクト検出器は事前定義されたアンカーボックスに依存していますが、FCOSはこれを使用しません。
- 特徴マップ1グリッドにつき予測を出力するので、セマンティックセグメンテーションのように、画像上の各ピクセルで予測を行う方法になっています。
- アンカーボックスが不要になるので、アンカーボックスに関連する複雑な計算を完全に排除できます。
- アンカーボックスに関連するハイパーパラメータがないため、検出性能に敏感なこれらのパラメータの調整が不要になります。
- Centernessの導入
- Centernessを導入することで、物体の中心から離れた位置によって生成された多くの低品質の予測バウンディングボックスを排除します。
環境
- torchvision==0.14.1
torchvisionのソースコードはBSD 3-Clause "New" or "Revised" Licenseです。
FCOSのアーキテクチャ
まず、FCOSのネットワークアーキテクチャを下図に示します。
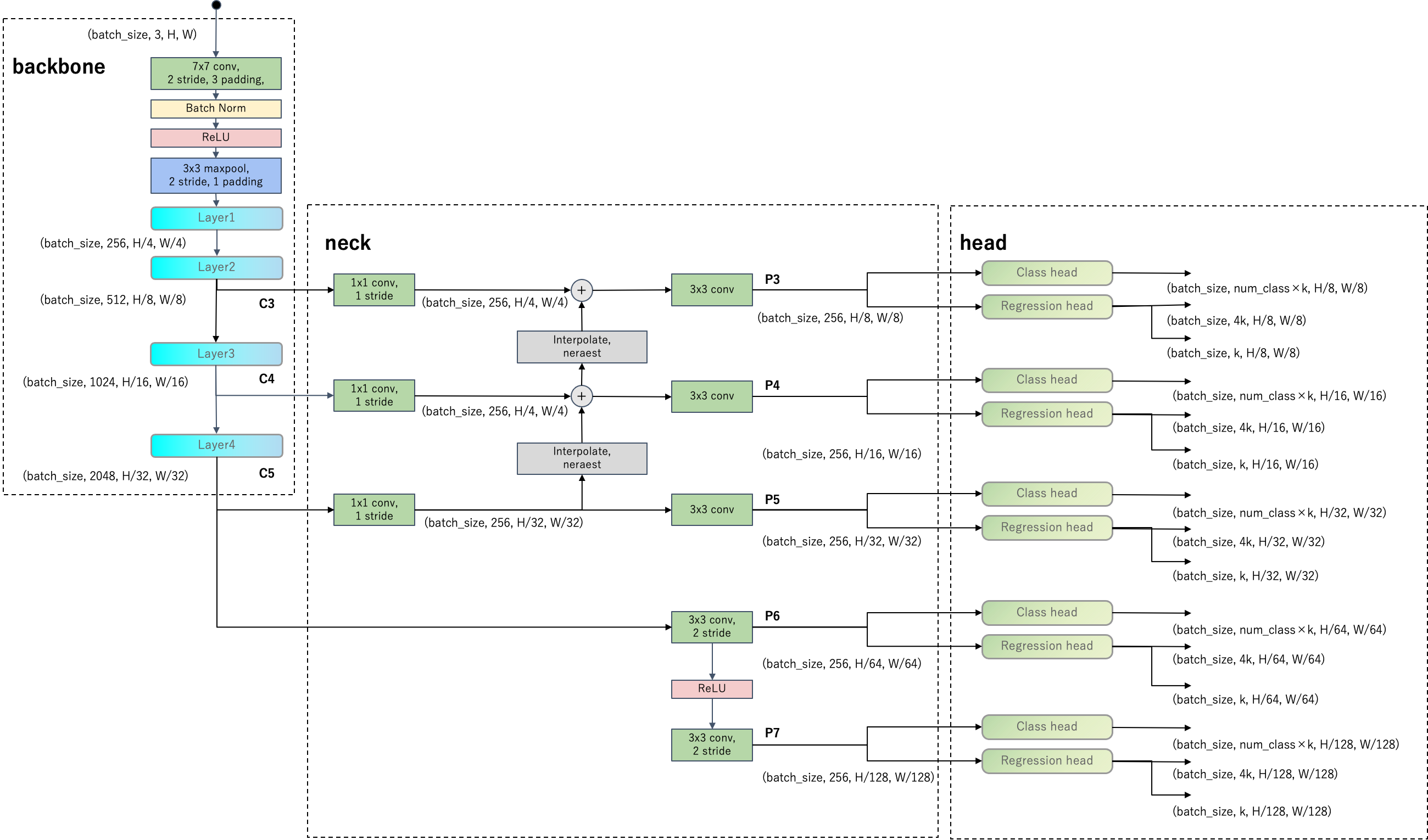

FCOSのネットワークはbackbone、neck、headで構成されています。headの点線部のClass headとRegression headは全て重み共有しています。backboneはResNet-50を想定しています。
以下ではFCOSの主要な特徴に注目してFCOSの構造に迫ります。RetinaNetと比較して見ていきますので、前回記事も参考にしてください。
一段階の物体検出アプローチ
FCOSはRetinaNet同様一段階物体検出器です。アーキテクチャもRetinaNetとほぼ同じですが、アンカーの考え方が異なる、Centernessという出力がある点が異なります。
まず、図のレベルP3の部分のみ注目します。レベルP3から伸びるheadにはクラス分類とバウンディングボックスのオフセット回帰モジュールがあります。
また、オフセット回帰モジュールからはCenternessの予測値も出力されます。公式実装を確認すると、centerness_on_regでCenternessをクラス分類モジュールとオフセット回帰モジュールのどちらから出力するか選べるようになっていました。
これと同様なレベルがP3〜P7まであります。
アンカーボックス不要のアーキテクチャ
FCOSはアンカーボックスが無いアンカーフリーなモデルになっています。正確には、アンカーのサイズがグリッドのサイズと同じ1種類しかないアンカーモデルになっています$(k=1)$。
アンカーはグリッドにつき1つのみで、アンカーの大きさはグリッドの大きさと同じです。下図はアンカーのイメージです。

正解バウンディングボックスと照らし合わせてアンカーをラベルしますが、RetinaNetとは手順が異なります。各アンカーボックスに対して、次の操作を行います。
-
センターサンプリング
- 各アンカーボックスの中心と各正解バウンディングボックスの中心距離を計算し、各アンカーボックスに対して一定距離以内にある正解バウンディングボックスを記録します。
-
アンカーが正解バウンディングボックス内にあるか判定
- ペアワイズ距離と呼ばれる、アンカーボックスの中心から正解バウンディングボックスまでの距離を使用して、各アンカーボックスの中心を内部に含む正解バウンディングボックスのみ残します。

-
スケール範囲に基づくアンカーの紐づけ
- 各アンカーが紐づくべき正解バウンディングボックスのスケール範囲を決定し、そのスケールに収まらない正解バウンディングボックスを除きます。
- 最小はアンカーの辺の4倍、最大はアンカーの辺の8倍です。ただし、FPNの一番小さい特徴マップに対しては最小を0とし、FPNの一番大きい特徴マップに対しては最大をinfとします。
- アンカーの大きさをstrideと呼びます。stridesがFPNの各レベルで(8, 16, 32, 64, 128)なので、各アンカーサイズに対して紐付けるペアワイズ距離の範囲は([0, 64], [64, 128], [128, 256], [256, 512], [512, inf])となります。
vision/torchvision/models/detection/fcos.py# 各アンカーを紐付けるべき物体の最小サイズと最大サイズを定義します。 # 最小はアンカーの辺の4倍、最大はアンカーの辺の8倍です。 lower_bound = anchor_sizes * 4 # FPNの一番小さい特徴マップに対しては最小を0とします。 lower_bound[: num_anchors_per_level[0]] = 0 upper_bound = anchor_sizes * 8 # FPNの一番大きい特徴マップに対しては最大をinfとします。 upper_bound[-num_anchors_per_level[-1] :] = float("inf") pairwise_dist = pairwise_dist.max(dim=2).values # 範囲に収まるもののみ残します。 pairwise_match &= (pairwise_dist > lower_bound[:, None]) & (pairwise_dist < upper_bound[:, None]) -
最小面積のGTボックスとのマッチング
- 以上の操作をしてアンカーに正解バウンディングボックスを紐づけた後、各アンカーに複数の正解バウンディングボックスが紐づいている場合は、複数の正解バウンディングボックスのうち最小面積のものを一つ選び、そのIDを記録します。
-
紐づきがないアンカーの処理
- 正解バウンディングボックスの紐づきがない場合はIDを-1として記録しておきます。
以上でアンカーをラベル付けすることができました。
Head部分はアンカーを元にクラス分類とバウンディングボックスのオフセットを出力します。
クラス分類は全てのアンカーに対して計算します。損失関数はSigmoid Focal Lossを使用します。
オフセットの予測は、正解バウンディングボックスの紐づけが存在するアンカーを元に予測した予測バウンディングボックスのみに対して損失が計算されます。また、オフセットの定義がRetinaNetとは異なり、次の式で表されます。$w_a,h_a$で割って正規化するかは実装によって異なります。torchvisionの場合はデフォルトで正規化されます。
\begin{align}
l^\ast = \frac{cx_a - x_{\text{min}}^\ast}{w_a} \\
t^\ast = \frac{cy_a - y_{\text{min}}^\ast}{h_a} \\
r^\ast = \frac{x_{\text{max}}^\ast - cx_a}{w_a} \\
b^\ast = \frac{y_{\text{max}}^\ast - cy_a}{h_a}
\end{align}
これを正解データとして、$(l, t, r, b)$をニューラルネットワークで予測します。
オフセットの損失関数はtorchvision.ops.generalized_box_iou_lossを使用します。このIoU損失は、2つのバウンディングボックスを囲む最小の箱の大きさに応じてスケーリングされ、予測されたバウンディングボックスが真のバウンディングボックスから大きく外れる場合、より大きなペナルティを受けることになります。さらに、バウンディングボックスが重ならない場合に非ゼロのペナルティが追加されます。
Centernessの導入
FCOSアーキテクチャとアンカーベースの検出器との間には性能のギャップが存在しました。原因は物体の中心から離れた位置によって生成された多くの低品質の予測バウンディングボックスでした。
そこで、この低品質な予測バウンディングボックスを抑制するために、新しいハイパーパラメータを導入することなく効果的な方法を導入しました。具体的には、物体の位置の「中心性(Centerness)」を予測するための単層ブランチを追加しました。
正解データは次のように作成します。
\text{Centerness} = \sqrt{\frac{\min(l^\ast, r^\ast)}{\max(l^\ast, r^\ast)}\frac{\min(t^\ast, b^\ast)}{\max(t^\ast, b^\ast)}}
ここで、平方根は中心性の減衰を遅くするために使用されます。中心性は0から1の範囲であり、バイナリクロスエントロピー損失で訓練されます。

画像引用元:https://arxiv.org/pdf/2006.09214
テスト時には、最終スコアは、予測されたCenternessと、分類スコアを掛け合わせて計算されます。
(\text{Score}) = (\text{Centerness}) \times (\text{Classification Score})
これにより、物体の中心から遠く離れたバウンディングボックスのスコアを低下させることができます。その結果、これらの低品質なバウンディングボックスは、最後のNMSによって高確率でフィルタリングされ、検出性能が著しく向上します。
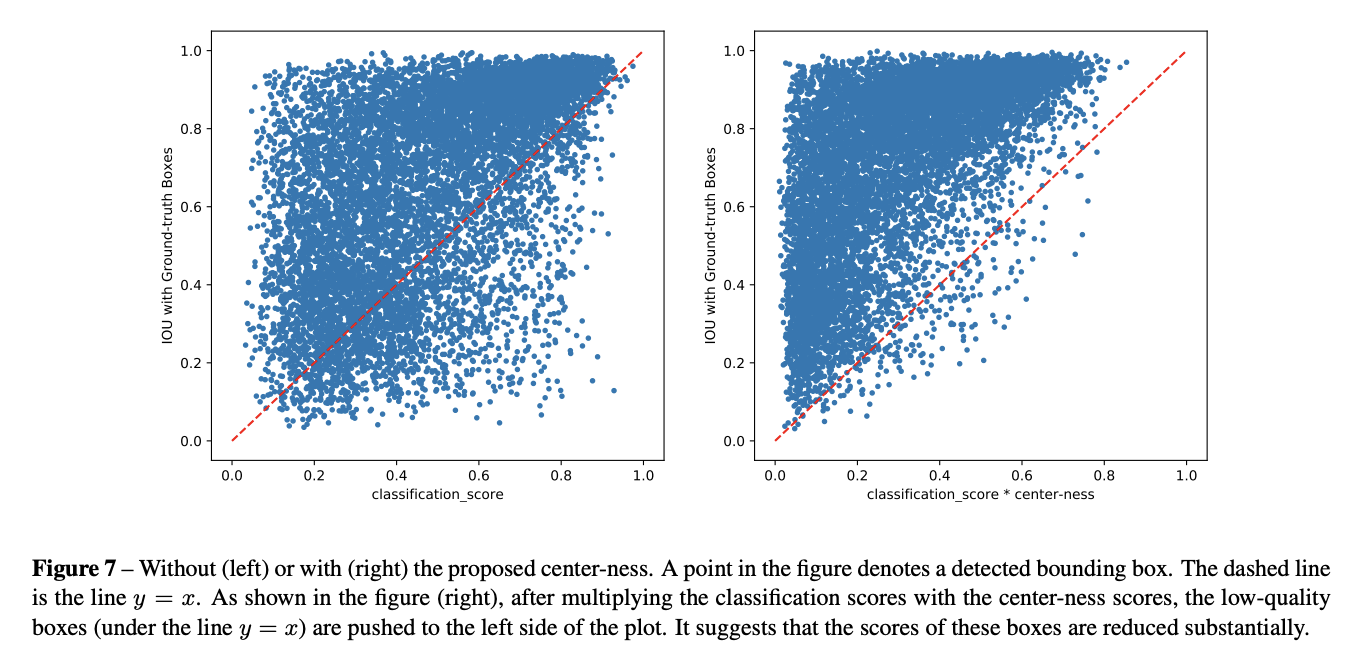
画像引用元:https://arxiv.org/pdf/2006.09214
Centernessは正解バウンディングボックスの紐づけが存在する(アンカーを元に予測した)予測バウンディングボックスのみに対して損失が計算されます。
最後に、テスト時の処理は以下のとおりです。
- 以下の処理を画像ごとに行います。
- 以下の処理をFPNのレベル別に行います。
-
score_thresh未満の予測を除外します。 - スコア順に
topk_candidatesだけ残します。 - アンカーとオフセットを使用して予測バウンディングボックスを計算します。
- 予測されたバウンディングボックスが画像内に収まるようにクリップします。
-
- 以上の処置の結果の予測バウンディングボックスを全てまとめます。
-
nms_threshでNMSを実行します。 - スコア順に
detections_per_imgだけ残します。
- 以下の処理をFPNのレベル別に行います。
参考文献
-
Zhi Tian, Chunhua Shen, Hao Chen, Tong He, "FCOS: Fully Convolutional One-Stage Object Detection," https://arxiv.org/abs/1904.01355
-
Zhi Tian, Chunhua Shen, Hao Chen, Tong He, "FCOS: A simple and strong anchor-free object detector," https://arxiv.org/abs/2006.09214