はじめに
久しぶりに実務で重回帰分析を使ったのですが、多重共線性が問題になりそうなケースだったのでVIFを見ることに。VIFが偏回帰係数の推定の分散増加させるという話を聞いたことがあったので、実際どのように分散に効いてくるのか計算しました。
偏回帰係数の分散の導出
重回帰モデルは下記のような式で表される。
Y_i = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} + \varepsilon_i, (i=1,...,n)
ここで$x_{ij}$は$i$番目の観測値の$j$番目の説明変数を表す。行列表示をすると次のように書ける。
\boldsymbol{Y} = X\boldsymbol{\beta} + \boldsymbol{\varepsilon}
以下では$Y_i$の観測値を$y_i$で表すことにする。また、以下では$X^\top X$が正則であることを仮定する。
次の式で$y_i$の予測値$\hat y_i$を書くことにする。
\hat{\boldsymbol{y}} = X\hat{\boldsymbol{\beta}}
$\boldsymbol{\beta}$の最小二乗推定を行う。
S_e = (\boldsymbol{y} - \hat{\boldsymbol{y}})^2 = (\boldsymbol{y} - X\hat{\boldsymbol{\beta}} )^2
観測値との誤差の二乗が最小になるように、$S_e$を微分して$\hat{\boldsymbol{\beta}}$を求める。
\hat{\boldsymbol{\beta}} = (X^\top X)^{-1}X^\top \boldsymbol{y}
$\boldsymbol{y}$は平均$X\boldsymbol{\beta}$、分散$\mathrm{Var}[\boldsymbol{\varepsilon}]$の正規分布に従うから、その線形変換である$\hat{\boldsymbol{\beta}}$もまた正規分布に従う。
$\hat{\boldsymbol{\beta}}$の平均値と分散を求めたい。ここで更に以下を仮定する。
\begin{aligned}
E[\boldsymbol{\varepsilon}] &= 0\\
\mathrm{Var}[\boldsymbol{\varepsilon}] &= E[\boldsymbol{\varepsilon}\boldsymbol{\varepsilon}^\top] = \sigma^2 I
\end{aligned}
このとき$\hat{\boldsymbol{\beta}}$について以下が求まる。
\begin{aligned}
E[\hat{\boldsymbol{\beta}}] &= E[(X^\top X)^{-1}X^\top \boldsymbol{y}] \\
&= E[(X^\top X)^{-1}X^\top (X\boldsymbol{\beta} + \boldsymbol{\varepsilon})] \\
&= \boldsymbol{\beta} + (X^\top X)^{-1}X^\top E[\boldsymbol{\varepsilon}] \\
&= \boldsymbol{\beta}\\
\mathrm{Var}[\hat{\boldsymbol{\beta}}] &= \mathrm{Var}[(X^\top X)^{-1}X^\top \boldsymbol{y}] \\
&= (X^\top X)^{-1}X^\top\mathrm{Var}[\boldsymbol{y}] X(X^\top X)^{-1}\\
&= (X^\top X)^{-1}X^\top\mathrm{Var}[\boldsymbol{\varepsilon}] X(X^\top X)^{-1}\\
&= \sigma^2 (X^\top X)^{-1}X^\top X(X^\top X)^{-1}\\
&= \sigma^2 (X^\top X)^{-1}
\end{aligned}
以上より、$\hat{\boldsymbol{\beta}}$の分布が求められた。
\hat{\boldsymbol{\beta}} \sim \mathcal N\left(\boldsymbol{\beta}, \sigma^2 (X^\top X)^{-1}\right)
$\hat{\beta}_j$の分散を求めたい。$r=X^\top X$とおく。一般性を失うことなく、行と列を入れ替えて$r$の$jj$成分を$(1,1)$成分に置く。
\begin{aligned}
\tilde r = \begin{pmatrix}
r_{jj} & r_{j,-j} \\
r_{-j,j} & r_{-j, -j} \\
\end{pmatrix}
\end{aligned}
ここで、$r_{j,-j}$は元の$r$の$j$行目から$j$列目を除いた1行p列ベクトルである。他も同様である。
\begin{aligned}
r &= X^\top X \\
r_{jj} &= \sum_k (X^\top)_{jk} X_{kj} \equiv X_j^\top X_j \\
r_{j,-j} &= (X^\top X)_{j,-j} = \sum_k (X^\top)_{jk}X_{k,-j} \equiv X_j^\top X_{-j} \\
r_{-j,j} &= (X^\top X)_{-j,j} = \sum_k (X^\top)_{-j,k}X_{k,j} \equiv X_{-j}^\top X_{j} \\
r_{-j,-j} &= (X^\top X)_{-j,-j} = \sum_k (X^\top)_{-j,k}X_{k,-j} \equiv X_{-j}^\top X_{-j}
\end{aligned}
ここで、$X_j$は$X$の$j$列目を抜き出した$p$行$1$列ベクトル、$X_{-j}$は$X$から$j$列目を除いた$p$行$p$列の行列である。
シューアの補行列を用いて$\tilde r ^{-1}$の$(1,1)$成分を求める事ができる。
\begin{aligned}
(\tilde{r}^{-1})_{1,1}
&= \left( \tilde{r}_{1,1} - \tilde{r}_{1,-1}(\tilde{r}_{-1,-1})^{-1}\tilde{r}_{-1,1} \right) ^{-1} \\
&= \left( r_{j,j} - r_{j,-j}(r_{-j,-j})^{-1}r_{-j,j} \right) ^{-1} \\
&= \left( r_{j,j} - r_{j,-j}(r_{-j,-j})^{-1}r_{-j,j} \right) ^{-1}
\end{aligned}
ここで、カッコ内の二項目について、
\begin{aligned}
r_{j,-j}r_{-j,-j}^{-1}r_{-j,j}
&= r_{j,-j}(r_{-j,-j})^{-1}r_{-j,-j}(r_{-j,-j})^{-1}r_{-j,j}
\end{aligned}
とし、右から2つの変数に注目すると、
(r_{-j,-j})^{-1}r_{-j,j} = (X_{-j}^\top X_{-j} )^{-1}X_{-j}^\top X_{j}
となる。ところで、$X_{j}$ベクトルを目的変数、$X_{-j}$を説明変数の計画行列としたときの重回帰モデルを最小二乗法で解いたときの偏回帰係数は次のように書ける。
X_j = X_{-j}\hat{\boldsymbol{\beta}}_{\ast j} \xrightarrow{OLS} \hat{\boldsymbol{\beta}}_{\ast j} = (X_{-j}^\top X_{-j})^{-1}X_{-j}^\top X_{j}
これは先程の量と一致している。したがって次のようになる。
\begin{aligned}
r_{j,-j}r_{-j,-j}^{-1}r_{-j,j}
&= r_{j,-j}(r_{-j,-j})^{-1}r_{-j,-j}(r_{-j,-j})^{-1}r_{-j,j} \\
&= \hat{\boldsymbol{\beta}}_{\ast j}^\top r_{-j,-j}\hat{\boldsymbol{\beta}}_{\ast j} \\
&= \hat{\boldsymbol{\beta}}_{\ast j}^\top X_{-j}^\top X_{-j}
\hat{\boldsymbol{\beta}}_{\ast j}
\end{aligned}
したがって、
\begin{aligned}
r_{j,j} - r_{j,-j}(r_{-j,-j})^{-1}r_{-j,j}
&= X_j^\top X_j - \hat{\boldsymbol{\beta}}_{\ast j}^\top X_{-j}^\top X_{-j}
\hat{\boldsymbol{\beta}}_{\ast j}
\end{aligned}
これは$X_{j}$ベクトルを目的変数、$X_{-j}$を説明変数の計画行列としたときの重回帰モデルの残差平方和$\mathrm{RSS}_j$になっている。また、$\mathrm{RSS}_j$は目的変数の分散と決定係数を用いて次のように書ける。
\begin{aligned}
\mathrm{RSS}_j &= nV_{j} (1-R_j^2) \\
V_j &= \mathrm{Var}_j[x_{ij}] = \frac{1}{n}\sum_i(x_{ij} - \bar x_{j})^2 \\
\end{aligned}
以上より、$\hat\beta_j$の分散は次のようになる。
\begin{aligned}
\mathrm{Var}[\hat\beta_j] &= \sigma^2 \left((X^\top X)^{-1}\right)_{jj} \\
&= \sigma^2 (\tilde r^{-1})_{1,1}\\
&= \frac{\sigma^2}{\mathrm{RSS}_j} \\
&= \frac{\sigma^2}{nV_{j}}\cdot \frac{1}{1-R_j^2}
\end{aligned}
もし、説明変数間に相関がなければ$1/(1-R_j^2)=1$となり、シンプルな形になる。$1/(1-R_j^2)$をVariance inflation factor(VIF)と呼び、多重共線性の指標として使われる。
\mathrm{VIF} = \frac{1}{1-R_j^2}
説明変数$x_j$が他の説明変数と相関を持っていると$\mathrm{VIF}$が大きくなり、推定値$\hat \beta_j$の分散が大きくなってしまう。
$\hat \beta_j$を標準化することで標準正規分布に従う統計量を作ることができる。
z = \frac{\hat \beta_j - \beta_j}{\sqrt{\mathrm{Var}[\hat\beta_j]}}
ただしこの統計量は分母に未知の母分散$\sigma^2$を含む。そこで$\sigma^2$を標本による不偏推定量$s^2$で置き換える。
\begin{aligned}
s^2 &= \frac{\sum_i (\hat y_i - y_i)^2}{n-p-1} \\
\widehat{\mathrm{Var}}[\hat \beta_j] &= \frac{s^2}{nV_{j}}\cdot \frac{1}{1-R_j^2}
\end{aligned}
ここで$\widehat{\mathrm{std}}$は標本標準偏差である。これによって$t$統計量が得られる。
t^{(\alpha/2, \nu)} = \frac{\hat \beta_j - \beta_j}{\sqrt{\widehat{\mathrm{Var}}[\hat \beta_j]}}
= \frac{\hat \beta_j - \beta_j}{\widehat{\mathrm{Std}}[\hat \beta_j]}
ここで$\widehat{\mathrm{std}}$は標本標準偏差である。自由度は$\nu=n-p-1$である。
Pythonで確認
statsmodelsを使って$\hat\beta_j$の標準偏差が計算されていることを確認する。
ライブラリ読み込み。
import numpy as np
import statsmodels.api as sm
from statsmodels.iolib.summary import Summary
from sklearn.linear_model import LinearRegression
データ生成。
_rand = np.random.RandomState(0)
size = 1000
mean = [0.0, 3.0]
s_x, s_y, rho = 1.5, 0.4, 0.9
cov = [[s_x**2, rho*s_x*s_y],
[rho*s_x*s_y, s_y**2]]
sigma = 1.0
X = _rand.multivariate_normal(mean, cov, size)
beta = (0.3, -0.7)
y = X@beta + _rand.normal(0, sigma, size)
回帰分析。
model = sm.OLS(y, sm.add_constant(X))
res = model.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.063
Model: OLS Adj. R-squared: 0.061
Method: Least Squares F-statistic: 33.65
Date: Wed, 13 Oct 2021 Prob (F-statistic): 7.21e-15
Time: 12:00:06 Log-Likelihood: -1371.6
No. Observations: 1000 AIC: 2749.
Df Residuals: 997 BIC: 2764.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.3844 0.530 0.726 0.468 -0.655 1.424
x1 0.3419 0.047 7.218 0.000 0.249 0.435
x2 -0.8454 0.176 -4.792 0.000 -1.192 -0.499
==============================================================================
Omnibus: 4.491 Durbin-Watson: 1.843
Prob(Omnibus): 0.106 Jarque-Bera (JB): 3.946
Skew: -0.084 Prob(JB): 0.139
Kurtosis: 2.742 Cond. No. 59.3
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
beta std err はbseメソッドで取り出せる。
print(res.bse) # [0.52980866 0.04736827 0.17641412]
scikit-learnのLinearRegressionを使って説明変数間の回帰分析を行って、$\hat\beta_j$の標準偏差を計算してみる。
clf = LinearRegression()
clf.fit(X[:, 1].reshape(-1, 1), X[:, 0])
R2_x = clf.score(X[:, 1].reshape(-1, 1), X[:, 0])
n = len(X)
var = np.std(res.resid)**2 / (n * np.var(X[:, 0]) * (1 - R2_x))
std_err = np.sqrt(var)
print(std_err) # 0.04729716648088632
clf = LinearRegression()
clf.fit(X[:, 0].reshape(-1, 1), X[:, 1])
R2_y = clf.score(X[:, 0].reshape(-1, 1), X[:, 1])
n = len(X)
var = np.std(res.resid)**2 / (n * np.var(X[:, 1]) * (1 - R2_y))
std_err = np.sqrt(var)
print(std_err) # 0.17614930098797998
多少の誤差はあるが、statsmodelsの結果と一致している。statsmodelsは説明変数間の相関の効果まで含めてstd err を計算してt値を表示していることがわかる。
もちろん、計画行列の$X^\top X$逆行列からも求められる。
X_ = sm.add_constant(X)
std_err = np.sqrt(np.std(res.resid)**2*np.diag(np.linalg.inv(X_.T@X_)))
print(std_err) # [0.52901335 0.04729717 0.1761493 ]
おまけ
信頼区間
予測したいデータを$X_\ast$とする。重回帰モデルの予測値は、推定値$\hat{\boldsymbol{y}}$の期待値を使用する。
\begin{aligned}
\boldsymbol{\mu} = E[\hat{\boldsymbol{y}}|X_\ast] = X_\ast E[\hat{\boldsymbol{\beta}}] = X_\ast\boldsymbol{\beta}
\end{aligned}
$\hat{\boldsymbol{y}}$の信頼区間を求める。$t$統計量は次のようになる。
\begin{aligned}
t_j^{(\alpha/2, \nu)}
&= \frac{\hat{y}_j - \mu_j}{\widehat{\mathrm{Std}}[\hat{y}_j]} \\
&= \frac{\hat{y}_j - \mu_j}{\sqrt{\widehat{\mathrm{Var}}[\hat{y}_j]}} \\
&= \frac{\hat{y}_j - \mu_j}{\sqrt{\widehat{\mathrm{Var}}[\hat{\boldsymbol{y}}]_{jj}}} \\
&= \frac{\hat{y}_j - \mu_j}{\sqrt{\left(X_\ast\widehat{\mathrm{Var}}[\hat{\boldsymbol{\beta}}]X_\ast^\top\right)_{jj}}} \\
&= \frac{\hat{y}_j - \mu_j}{\sqrt{s^2\left(X_\ast(X^\top X)^{-1}X_\ast^\top\right)_{jj}}}
\end{aligned}
したがって、$\mu_j$の信頼区間は次のようになる。
\hat{y}_j \pm t_j^{(\alpha/2, \nu)} \widehat{\mathrm{std}}(\hat{y}_j)
自由度は$\nu=n-p-1$である。
予測区間
新しいデータの真値は次のように書ける。
\begin{aligned}
& \boldsymbol{y} = X_\ast \boldsymbol{\beta} + \boldsymbol{\varepsilon}_\ast \\
\end{aligned}
真値$\boldsymbol{y}$と推定量$\hat{\boldsymbol{y}}$の差を正規化して$t$統計量をつくる。
\begin{aligned}
t_j^{(\alpha/2, \nu)}
&= \frac{y_j - \hat{y}_j - 0}{\widehat{\mathrm{Std}}[y_j - \hat{y}_j]} \\
&= \frac{y_j - \hat{y}_j}{\sqrt{\widehat{\mathrm{Var}}[y_j - \hat{y}_j]}} \\
&= \frac{y_j - \hat{y}_j}{\sqrt{\widehat{\mathrm{Var}}[ \boldsymbol{y} - \hat{\boldsymbol{y}}]_{jj}}} \\
&= \frac{y_j - \hat{y}_j}{\sqrt{\left(X_\ast\widehat{\mathrm{Var}}[ \widehat{\mathrm{Var}}[y]+\hat{\boldsymbol{\beta}}]X_\ast^\top \right)_{jj} - 2\widehat{\mathrm{Cov}}(\hat{{y}}_j, {y}_j)}} \\
&= \frac{y_j - \hat{y}_j}{\sqrt{\left(
s^2 + s^2 X_\ast(X^\top X)^{-1}X_\ast^\top \right)_{jj}- 2\widehat{\mathrm{Cov}}(\hat{{y}}_j, {y}_j)}}\\
&= \left\{
\begin{array}{ll}
\frac{y_j - \hat{y}_j}{\sqrt{\left(
s^2 + s^2 X_\ast(X^\top X)^{-1}X_\ast^\top \right)_{jj}}} & \mathrm{新データ} \\
\frac{y_j - \hat{y}_j}{\sqrt{\left(
s^2 - s^2 X(X^\top X)^{-1}X^\top \right)_{jj}}} & \mathrm{既存データ}
\end{array}
\right.
\end{aligned}
ここで、$\hat{{y}}_j$と${y}_j$の共分散は予測対象データが新データか、学習に使用した既存データかで異なることに注意。
\begin{aligned}
\widehat{\mathrm{Cov}}(\hat{{y}}_j, {y}_j)
&= \sum_k \left( X_\ast(X^\top X)^{-1}X^\top \right)_{jk} E[ \varepsilon_k \varepsilon_{\ast j} ] \\
&=
\left\{
\begin{array}{ll}
0 & \mathrm{新データ} \\
\sum_k s^2 \left( X(X^\top X)^{-1}X^\top \right)_{jk} \delta_{kj} = s^2\left( X(X^\top X)^{-1}X^\top \right)_{jj} & \mathrm{既存データ}
\end{array}
\right.
\end{aligned}
したがって、$Y_j$の予測区間は次のようになる。
\hat{y}_j \pm t_j^{(\alpha/2, \nu)} \widehat{\mathrm{std}}(\hat{y}_j - y_j)
自由度は$\nu=n-p-1$である。
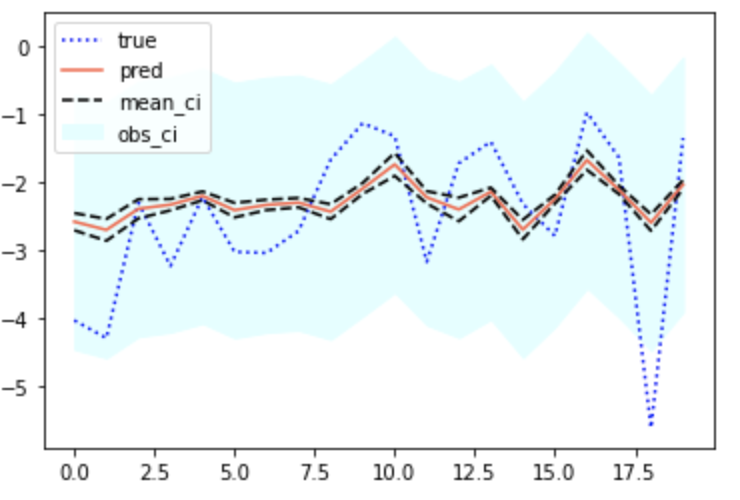
Pythonで確認しよう。statsmodelsの予測出力は新規データに対する予測区間を出力することに注意。
predictions = res.get_prediction(sm.add_constant(X))
summ_df = predictions.summary_frame(alpha=0.05)
summ_df.head()
# mean mean_se mean_ci_lower mean_ci_upper obs_ci_lower obs_ci_upper
# 0 -2.573610 0.064468 -2.700119 -2.447101 -4.452258 -0.694962
# 1 -2.694484 0.082042 -2.855478 -2.533490 -4.575769 -0.813199
# 2 -2.384156 0.071976 -2.525398 -2.242914 -4.263854 -0.504459
# 3 -2.322834 0.042842 -2.406904 -2.238764 -4.199102 -0.446566
# 4 -2.193372 0.032943 -2.258018 -2.128726 -4.068870 -0.317874
meanが予測値、mean_seが予測値の標準偏差(正確には標準誤差)、mean_ciが信頼区間、obs_ciが予測区間である。
import matplotlib.pyplot as plt
summ_df = summ_df[:20]
plt.plot(summ_df['mean'], 'red')
plt.plot(summ_df['mean_ci_upper'], '--', color='k')
plt.plot(summ_df['mean_ci_lower'], '--', color='k')
plt.fill_between(x=summ_df.index, y1=summ_df['obs_ci_upper'], y2=summ_df['obs_ci_lower'], color='skyblue')