この記事は、アイスタイル アドベントカレンダー2025 21日目の記事です。
はじめに
こんにちは、データ分析システム部のしばです。
突然ですが、みなさんは 「過去から学び、今日のために生き、未来に対して希望を持つ」 という言葉をどこかで聞いたことがありますか?
かの有名なアインシュタインが言ったとか言わないとか。私も詳しくは知らないので、興味がある人は調べてください。
さて、気がついたら2025年ももう残すところあとわずかになりましたね。みなさんにとって2025年はどんな一年だったでしょうか。
ということで、今日は年忘れの年末にふさわしく、過去を振り返ってアイスタイルのデータ基盤の技術変遷史を紹介しようと思います。
我々の過去の歴史が、みなさんの『今』や『未来』に少しでもお役に立てれば幸いです。
目次
0.全体像の紹介
1.オンプレミス主力時代
2.クラウドへの変遷
3.幻の「理想郷」への挑戦
4.これからの話
0.全体像の紹介
まずはこちらをご覧ください。
今回説明する我々の歩んできた歴史を超シンプルにまとめた図がこちらです。
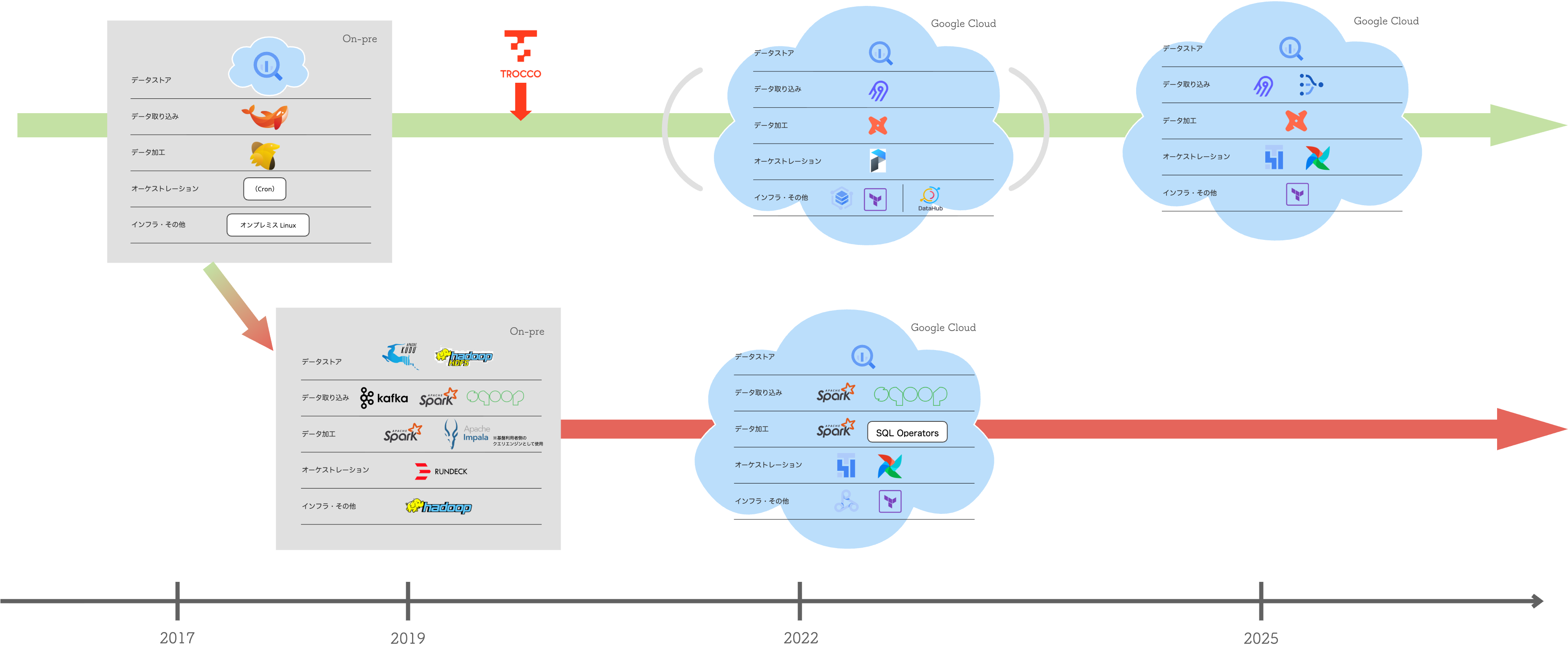
アイスタイルの中には、全社で幅広く利用される分析やレポートのためのデータ基盤と、Brand Officialというサービス提供用のデータ基盤があります。
複数ドメインにまたがってデータを利用しているシステムは他にも複数あるのですが、データ収集から加工や提供までを基盤内で一貫して担っているものは大きくこの2つになります。
その2つが辿ってきた歴史をこの記事で少しずつピックアップして紹介していきます。
それでは、時代を追って見ていきましょう。
1.オンプレミス主力時代
むかしむかし、というほどではありませんが、かなり遡って2017年〜2018年頃から始めます。
当時はまだ「クラウドネイティブ」という言葉が今ほど当たり前ではなく、アイスタイルでもオンプレミスサーバーが主力でした。
全社向けのデータ基盤:原点?
この頃から、全社のデータを集約するデータレイクとして BigQuery が利用され始め、データの転送にはオンプレミスサーバー上で動く Embulk の本格運用が始まりました。
実はこれより前の2015年頃から HDFS(Hadoop Distributed File System)にデータを流す検証などは行われていたようですが、本格的な運用として定着し、BigQueryへのデータ連携が増え始めたのがこの時期でした。
また、この頃のデータ加工には、こちらもオンプレミス上での Digdag が使われていました。
正直、私もこの時期はまだ深く関わっていなかったため、古くからいるメンバーに確認した限りの歴史ですが、ここが現在のデータ基盤の原点と言えるでしょう。
Brand Official データ基盤:独立の道へ
一方、2018年〜2019年頃には、ブランド向けマーケティングツールである『Brand Official』専用データ基盤の前身となる、内製トラッキングシステムの構想が動き出します。
ここでは @cosme 上のユーザーの行動データをトラッキングし、Apache Kafkaで収集して、オンプレミスのHDFSに蓄積していくという構成が取られました。
そして2019年の『Brand Official』のリニューアルに伴い、専用のApache Hadoop基盤が誕生しました。
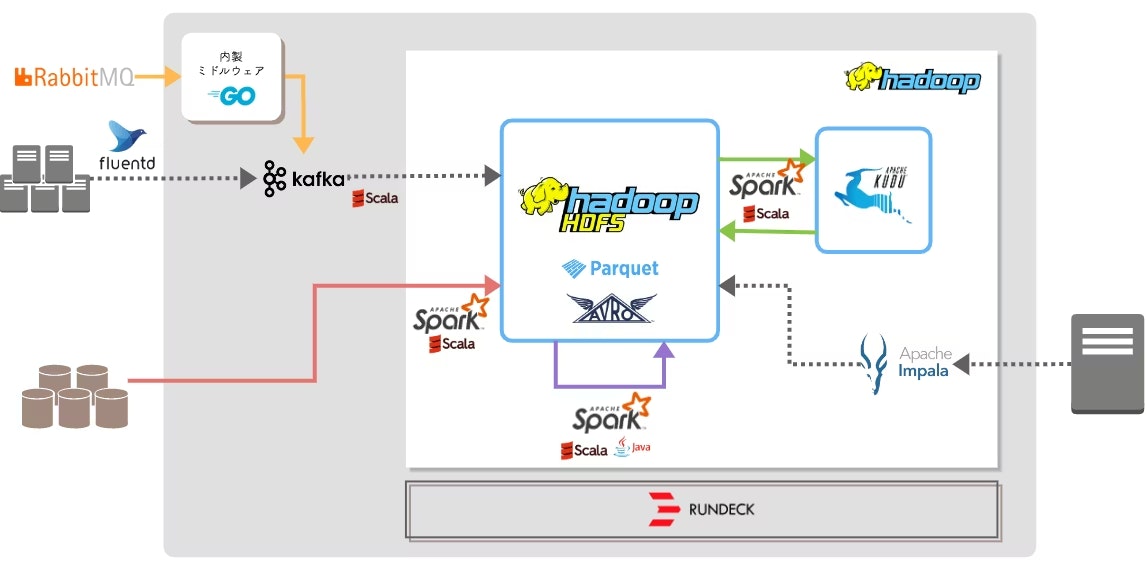
ここで Brand Official データ基盤は、完全に全社向けのデータ基盤と道を分かれます。
2.クラウドへの変遷
少し時代が進んで2020年頃、サービス成長に伴ってありがたいことに @cosme のユーザーがどんどん増え、もちろんデータ量もその分増大していきました。
2020年頃といえばデータシステムに限らず、世の中のトレンドがどんどんクラウドへとシフトしていった時期です。
全社向けデータ基盤:Embulkの利用拡大
社内のデータをBigQueryに集約する動きは加速し続け、どんどんテーブルの連携対象は増えていきました。
なんと驚くことに、初期から利用していたEmbulkは2025年末現在の今でも運用をし続けており、
6台のEmbulkサーバーで負荷計算のパズルをしながら1500を超えるテーブルを日々連携しています。
(ただし、Embulkは2025年11月には メンテナンスモードへの移行 の発表もあり、アイスタイルでも年明けのクローズに向けて動き始めております)
一方で、データ加工を担っていたオンプレミスのDigdagはその役目を終え、現在はその役割の一部をSaaSである TROCCO が担っています。ここでようやくのSaaS導入です。
Brand Official データ基盤:クラウドネイティブへの刷新
2020年を過ぎた頃、独立したおかげでフットワークの軽い(?)Brand Official データ基盤は、大きな転換点を迎えます。
最初は5台規模(データノード4台)だった Apache Hadoop クラスタを、一度、データ量の増加と処理速度の限界に伴い14台(データノード12台)へと拡張したのですが、それでもオンプレミスでの運用は限界を迎えます。
エンジニアとしての運用負荷も相当でした。つらい。
そして2022年、ついにBrand Official データ基盤は Google Cloudを中心としたクラウドネイティブな構成へフルリニューアル を行いました。
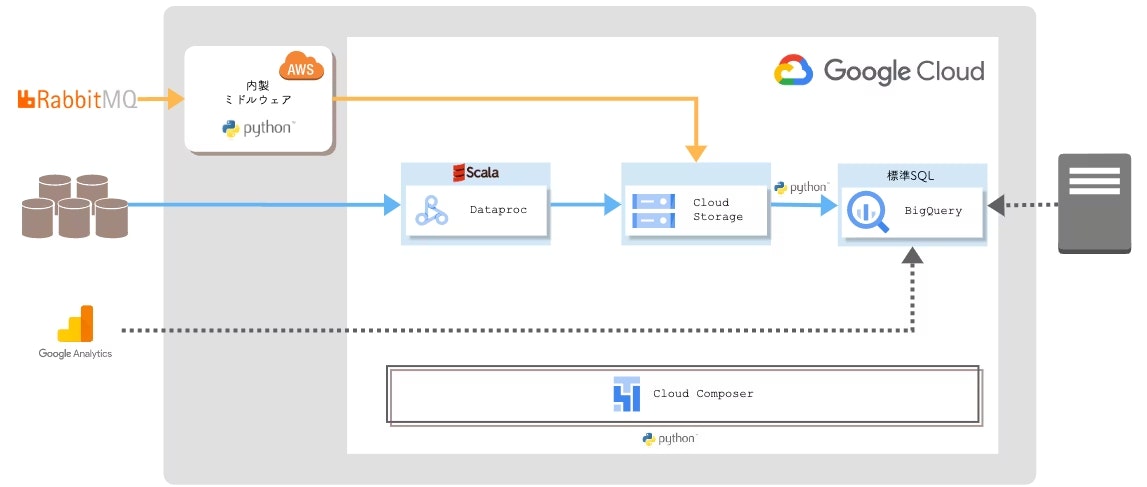
詳しくは過去に私が書いた こちら の記事に記載しております。
ポイントは、オンプレミスの Apache Hadoop の大変な運用から脱却し、マネージドサービスの活用により圧倒的な運用負荷軽減、処理速度の向上、安定性の向上を手に入れたという点です。
(この記事を書いてからもう3年……)
3.幻の「理想郷」への挑戦
さて、 Brand Official データ基盤がクラウド化により大成功を収めたように見える(結果的には……)、その裏で。
実はアイスタイルのデータ基盤の歴史には、大きな「挑戦と挫折」がありました。
2022年頃、未来のために全社のデータを統合した共通のデータ基盤を作ろうというプロジェクトが発足したのです。
目指したもの
まずは、目指したものの全体像がこちら。
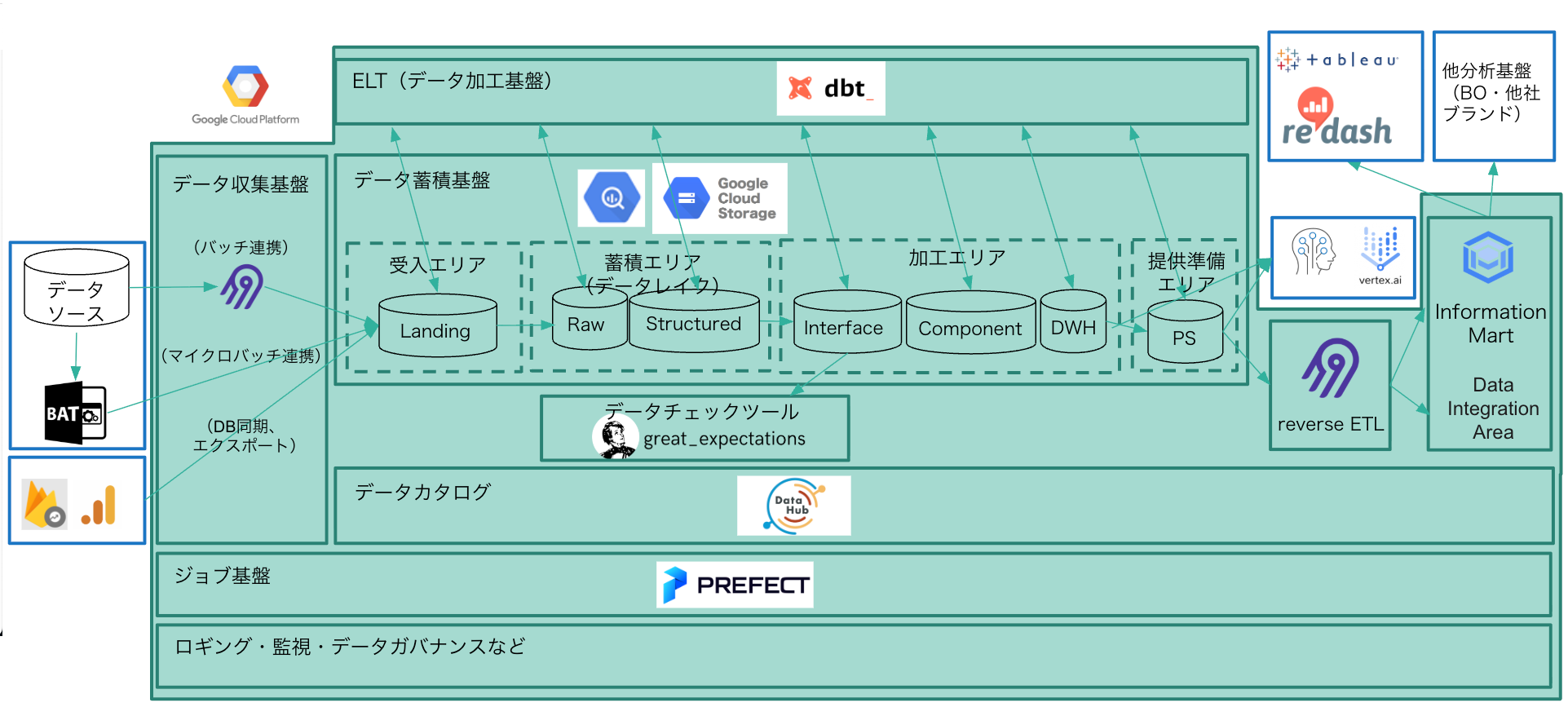
一言で言えば、モダンデータスタックをフル活用した、堅牢かつ柔軟な基盤でした。
大きな特徴としてはこちら。
- Data Vault 2.0の採用: 変更に強く、完璧な履歴管理ができるデータモデリング
- 高度なデータ品質管理: Great Expectationsを採用した品質担保
- 盤石なセキュリティ: PII要件に対応した高度なセキュリティ
いずれは Brand Official の基盤や機械学習用の基盤なども統合し、社内のデータの流れの中央ハブとなる……そんな理想のデータ基盤でした。
ぶち当たった「現実」
しかし、高い理想に対して現実は厳しく立ちはだかります。
これだけで一記事が書けそうなほどの課題や難しさはあったのですが、簡単にまとめるとこんな感じです。
-
ルールが複雑すぎた
- 開発・運用のルールが複雑化し、実運用に乗せるための学習コストと実装コストが増大し、エンジニアの疲弊の原因となる
-
運用コストの増大
- クラウド化したとはいえ、 GKE 上で Prefect を自前管理する構成は、インフラ運用コストとしては結果的に増加に繋がった
-
活用要件との足並みが揃っていない
- まだ今のアイスタイルは、『このデータ基盤でしか叶えられない』ような複雑かつ高度な要件が生まれるデータ活用フェーズではない(一番の要因)
結果として、このデータ基盤はアイスタイルのメインストリームにはならず、我々は多くの教訓を得ることになります。
4.これからの話
これまでの歴史を経て、今の私たちは新たな方針でデータ基盤の刷新に邁進しています。
0→1ではなく、今ある土台を活かす
データエンジニアの真の目的は、社内のデータ活用を促進するための土台を作ることであり、新しい技術を採用することでも、最強のデータ基盤を目指すことでもありません。
理想の基盤を0→1で作って完全なスイッチを目指すのではなく、長い歴史の中で課題が山積みである既存のデータ基盤と向き合い、少しずつ立て直していく道も選択肢のひとつです。
このあたりの「今」と「未来」については、 弊社の河野が書いた こちら の記事をご覧ください。
守りを固めながらレガシーな部分を少しずつモダナイズし、一歩ずつユーザー活用を促しながら本当に使いやすい形へと整地していく。それが今の我々の戦い方です。
「統合」か「分離」か
また、一度は「理想郷」による全社のデータの流れの統合を目指しましたが、今は「サービス用の基盤となる Brand Official データ基盤は、本当に社内活用向けのデータ基盤と統合すべきなのか?」という点も、改めて考え直しています。
toBサービスとして高いサービスレベルが求められる基盤と、自由で柔軟な分析が求められる基盤。それぞれで必要な技術要件も、進化のスピードも異なります。
これまでの歴史からも見える通り、別々であるからこそ、それぞれの目的に対して最適な機能開発や技術採用ができる側面もあります。
変わらないもののために、変わり続ける
これはデータ基盤に限った話ではありませんが、システム開発に「完成」はありません。その時にベストだと思った技術選定も、1年後、2年後にはベストではなくなっていることなんて当然のようによくあります。
ただ、アイスタイルにおける『データ分析システム部』という組織が持つ、データの価値を引き出すために社内のデータ活用を促進していく、という存在意義が変わるわけではありません。
物事には変わるものと変わらないものがあるように、「変わらない目的」のために、手段や技術や求められる要件といった「変わっていくもの」にどう対応していくか。そのために、自分たち自身の組織をどう変えていくか。
それが、これからにとって最も大切なことだと私は思います。
おわりに
この変遷期の半ば、2021年にデータエンジニア組織として『データ分析システム部』が生まれました。
2025年になり、立ち上げ当初からこの部署の歴史の全てを知るメンバーも少なくなり、節目として今年はこんな記事を書いてみました。
あくまでこの記事でお伝えしたのは過去のことであり、今のデータ分析システム部が目指すものと直接的に繋がらない部分はたくさんあると思います。
ただ、こうして過去を知ることで、ぜひ未来に対しての学びを得て、今の選択へと活かせればいいなと願い、紹介いたしました。
未来への挑戦を続けているアイスタイルのデータ領域に興味がある方は、ぜひ一度ご連絡ください。
特にインフラ領域、モデリング領域に力を入れたい方、マネジメントの目線を持ってデータ領域でバリューを発揮したい方など、まずはカジュアルにお話させていただければ幸いです!