こちらは アイスタイル Advent Calendar 2022 9日目の記事です。
こんにちは! アイスタイルのデータ分析システム部という部署でデータエンジニアをしている @grassy です。
みなさん、12月1日〜12月3日に開催された @cosme BEAUTY DAY 2022 ではほしいコスメを爆買いできましたか?
昨日発表されたばかりの @cosme ベストコスメアワード2022 はもうばっちりチェック済みですか?
@cosme を通じたコスメの販売やクチコミ・ブログなどの美容に関する総合情報サイトのイメージが強いアイスタイルですが、私たちの事業はそこだけに留まりません。
アイスタイルは、ユーザーの皆様の動向を分析してブランドに提供しその人にあった欲しい情報やコミュニケーションの仕方を理解できる、ブランドとユーザーが Win-Win の関係を築くためのマーケティングプラットフォームを展開しています。
それが、 SaaS 型マーケティング支援サービス【ブランドオフィシャル】です!
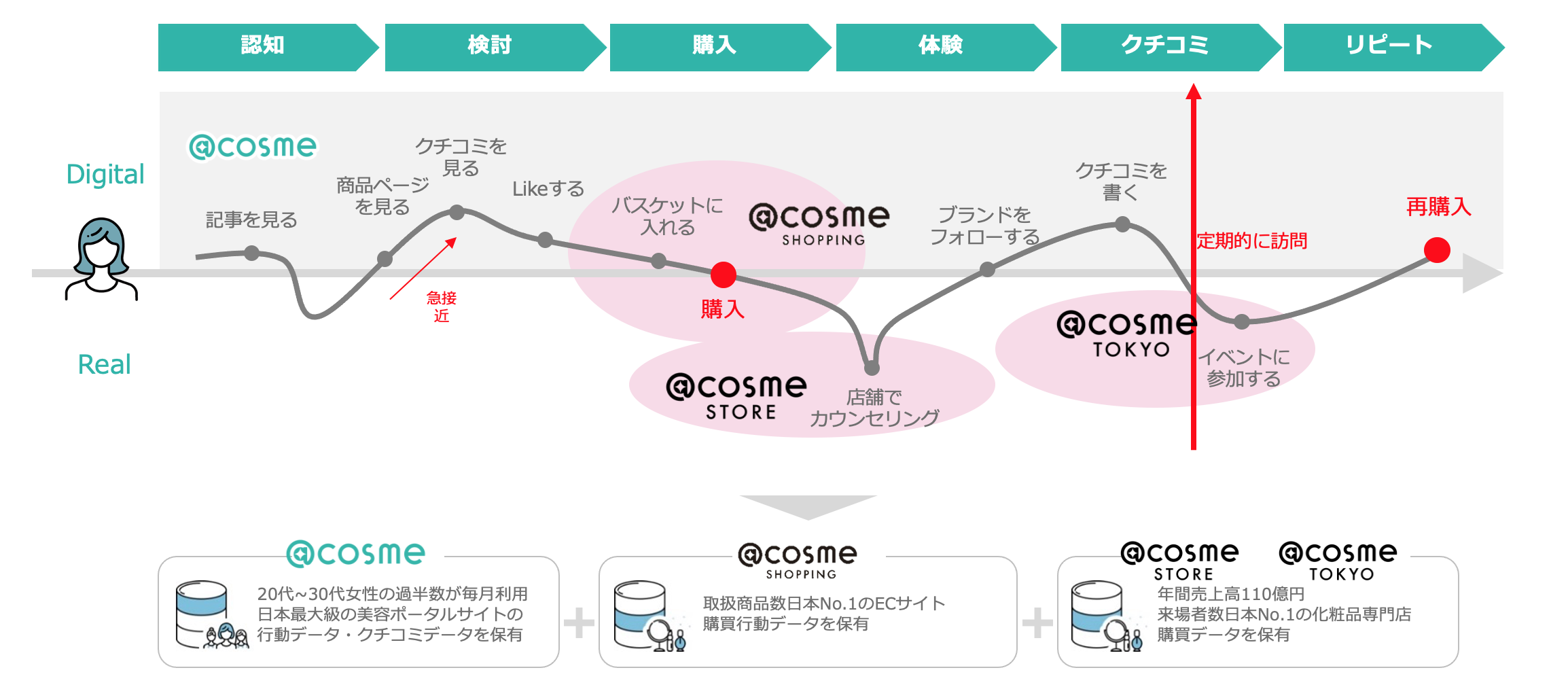
本日は、100億件を超えるユーザーデータを抱えて、ブランドオフィシャルを裏側で支えているデータ基盤についてをお届けします。
本題の前に
アイスタイルは約20年かけて美容に関する日本最大級のデータベースを構築してきました。アイスタイルの事業を語る上でデータの話は欠かせません。
そんなアイスタイルの事業の根幹ともいえるデータを幅広く収集し、データガバナンスに沿ったデータ管理、分析やサービスで利用するためのデータ提供などを行う部署……それが、我らがデータ分析システム部です。
データ品質を担保する堅牢な盾となり、データの価値を高めて利活用を促進し、事業の可能性を広げるための矛を研ぐ部署でもあります。
そんな私たちは今、社内に複数存在しているデータ基盤を統合するために、総力を上げて全社データ統合基盤を構築しています。
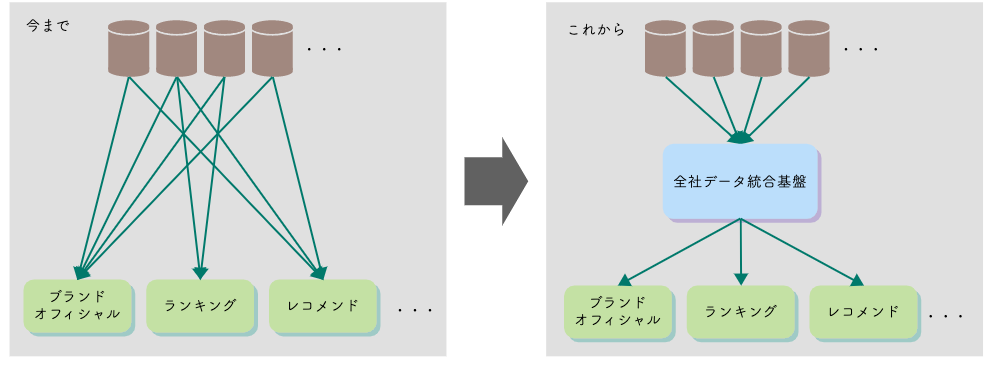
その中の最初の一歩として、ブランドオフィシャルのデータ基盤をオンプレミスの Hadoop 環境から Google Cloud へ移行した話をご紹介いたします。
旧データ基盤の紹介
まずは、旧データ基盤についてご紹介します。ユーザーの動向の数多くを集約しているブランドオフィシャルのデータ基盤には、様々なデータソースからデータを収集する必要があります。当然ながら、データを保持しているのは RDBMS だけではなく、各Webサーバーのアクセスログであったり、 RabbitMQ のようなキューイングシステムのデータも必要です。
旧データ基盤は、オンプレミス上に構築した Hadoop を中心とした構成となっています。
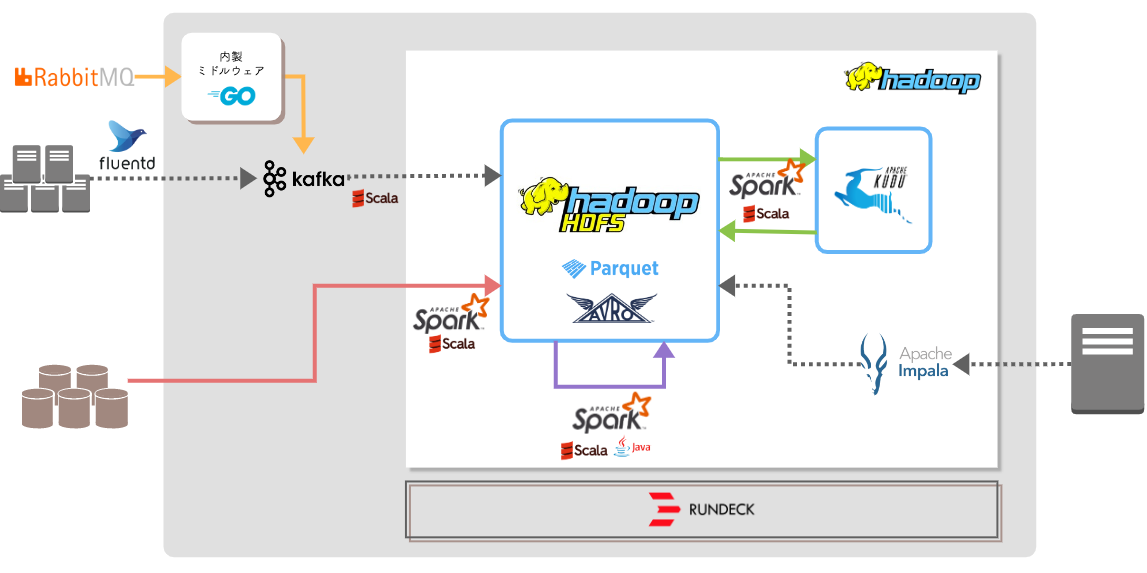
各 RDBMS のデータは Spark によって HDFS(Hadoop Distributed File System) に蓄積され、アクセスログや RabbitMQ のデータは Apache kafka を経由して同様に HDFS に蓄積されます。 HDFS に蓄積したデータは再び Spark によって加工され、時には HDFS に戻され、時には分散データストアである Kudu に保持されながら、ブランドオフィシャル用のデータマートを作成しています。これらのジョブはそれぞれが別の JAR ファイルとしてコンパイルされ、ジョブスケジューラである Rundeck でジョブフローを管理して実行されます。また、作成されたデータマートは HDFS 上に Parquet ファイルとなり、フロントアプリケーションからはクエリエンジンである Impala を経由して参照されます。
こちらの概略図はかなり省略して描いていますが、これだけでも様々な技術、言語、サブシステム(なんと実線のカラフルな矢印はそれぞれ別なソースコードで管理されています)が使われていることが伝わるかと思います。
旧データ基盤の課題
旧データ基盤は2年半ほど商用環境で運用されてきましたが、その間ずっと抱えられてきた課題は少なくありません。それらの課題を4つに分けてご紹介しますので、上の図と照らし合わせてご覧ください。
1. 基盤維持についての課題
オンプレミスで構築した Hadoop 環境を維持するためには、ハードウェアレベルの保守が必須であり、複数のコンポーネント間でリソースが奪い合わないよう各ノードのリソース分配を常に監視する必要があります。また、増大していくデータに永久に対応するためには、大型ストレージを持つ物理的なデータノードを何台も追加していく必要もあります。
2. 収集機構の課題
各 Web サーバーのアクセスログは fluentd によって kafka を経由して収集しています。 fluentd は Web サーバー側にも設定が必要なため、複数のサービスにまたがって収集するには何台ものサーバーに設定を追加する必要があり、サービス側でサーバーのリプレイスなどのオペレーションが発生する時は、データ基盤としても常にアプリケーションエンジニアと連携を密に取る必要が発生します。各サービスに依存することで、データの品質にバラつきが発生し信頼性への低下にもつながります。
また、多種多様なデータソースからの収集に対応するためには、それぞれのデータソースに対して個別に収集方法を検討し、それに合わせた収集システムの構築が必要です。
3. バッチ実行時間、レスポンス速度の課題
旧データ基盤では、一日分の集計を行うのに13時間もかかっており、データマートがフロントへ提供されるまでにデータ発生から2〜3日を有していました。フロントアプリケーションから発行されるアドホックなクエリへのレスポンスも1分近くかかるときもあり、パフォーマンス面でも課題がありました。
4. 開発コストの課題
複数の言語やツールを使用して構築することは、開発者の管理を煩雑にし、新しくジョインするメンバーの学習コスト増大に繋がります。保守運用フェーズに入ってから数年経っても属人化解消には至れず、長年運用の多重化を進める弊害となっていました。
上に挙げてきた課題を解決するためには腰を据えた改善が必要ですが、改善にかけるだけの人的リソースがない……という悪循環を繰り返していました。
これらの課題の一部を解決するために、このデータ基盤をオンプレミスからクラウドへの引っ越しが決定しました。
新データ基盤の紹介
まずは構築された新データ基盤の全体像をお見せします。
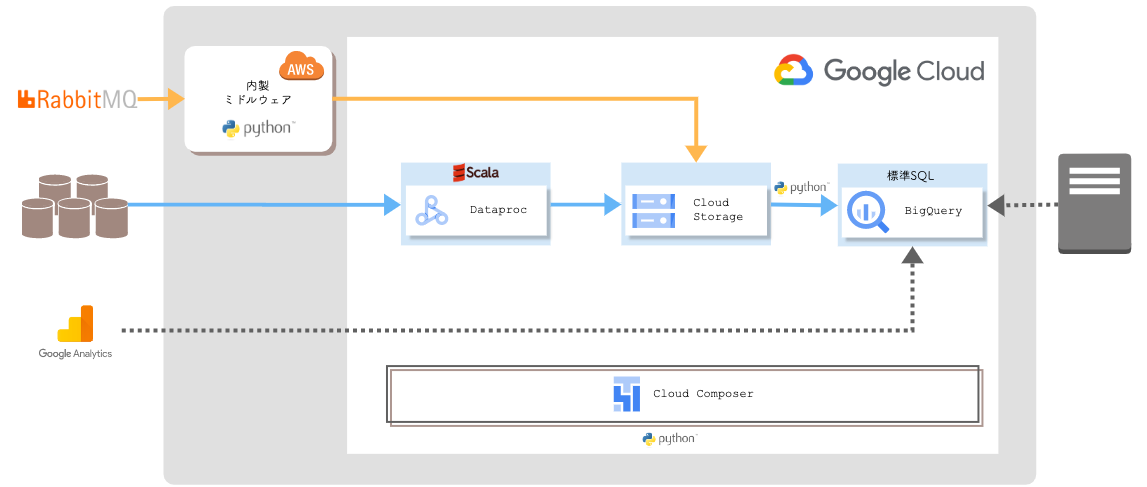
概略図からも、旧データ基盤に比べてとてもシンプルな構成となっていることが伝わるのではないでしょうか?
新データ基盤の移行先は Google Cloud に決定しました。Google Cloud を採用した理由は、データ分析への強さ(技術選定時)と、同じ Google 製のサービスである Google Analytics との親和性の高さのためです。新データ基盤では。それぞれのデータソースから収集したデータを BigQuery にロードし、複雑な加工処理は全て BigQuery 上で標準 SQL で記載する形となっています。 BigQuery にロードするためにファイルとして蓄積が必要な場合は、 Cloud Storage に集約しています。
全てのジョブは Cloud Composer で一括管理されています。まず、各 RDBMS のデータは Cloud Composer 上で起動した Dataproc で集約され Cloud Storage に蓄積されます。 RabbitMQ のデータは AWS に新規構築したミドルウェアを経由して同様に Cloud Storage に蓄積されるというマルチクラウド構成となっています(※こちらのミドルウェアはアドベントカレンダー17日目の @shirakih が詳細にご紹介する予定なのでお楽しみに^^)。 Cloud Storage に蓄積したデータは後続処理で BigQuery にロードされ、加工されてデータマートを作成しています。また、データマートとなる BigQuery テーブルは、フロントアプリケーションから Google API 経由で直接参照することが可能です。
運用が始まって数ヶ月(2022年8月、正式に商用環境へとリリースしました ![]() )、まだまだこれがベストな構成であるかは断言できませんが、この移行によって大きなメリットを得ることができたのは確かです。
)、まだまだこれがベストな構成であるかは断言できませんが、この移行によって大きなメリットを得ることができたのは確かです。
クラウド移行によって解決された課題
1. マネージドサービスの利用と使用技術の統一
システムの主要な機構は Google Cloud のマネージドサービスの採用を優先し、言語も標準 SQL と Python へと統一(一部 Scala が残っているのは、旧データ基盤の資産を流用しているためになります)、主要なビジネスロジックは一つのソースコードへと集約することで、システムの運用保守が楽になりました。その成果はひと月にかかる運用時間にも現れてます(下図)。システムの学習コストやコードの複雑性を軽減することができ、チームへのジョインのハードルを下げることにも繋がりました。
2. 社内標準の意思決定
今回の引っ越しにあわせて、ユーザーの閲覧行動を追跡するデータとして Web サーバーのアクセスログ収集は廃止して Google Analytics のデータを採用する意思決定を行いました。それぞれのページにタグを実装する必要はありますが、別なモジュールやミドルウェアを介する必要がなく BigQuery まで収集することができ、関心事を減らすことで保守の難易度を下げる事ができました。また、これまで社内で分析に使われていたものと同じデータソースを選択することにより、データの標準化にも繋がりました。
3. バッチ実行時間、レスポンス速度の改善
物理サーバーで構成されるオンプレミスの環境とは違い、オートスケール可能な Cloud Composer でジョブを実行することでバッチの実行時間も大幅に削減されました。そのおかげで、今まで13時間かかっていた日次の処理は3時間程度に収まり、蓄積した全データを一ヶ月単位で区分けして集約するという、以前であれば約10日ほどかかっていた処理も、移行後はなんと2日で完了するようになりました。また、フロントアプリケーションからの接続は BigQuery を直接参照することにしたため、従量課金によるコスト問題は浮上していますが、レスポンス速度に関してはほとんどのページで大きな改善が見られました(下図)。
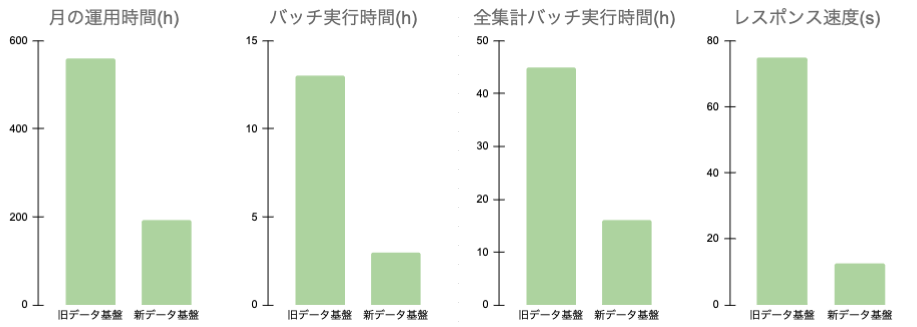
こうしてメリットを並べると、クラウド移行には素晴らしい結果しかないように見えますが、この移行を実現するためにはいくつかの壁を乗り越える必要がありました。
移行中にぶつかった壁
私は旧データ基盤の初期開発当初からこのチームのエンジニアでしたが、それでもこのシステムの全てを理解しているわけではありません。アイスタイルに蓄積されるユーザーのほとんどの行動を集約する目的で開発されたデータ基盤であり、その膨大なデータをブランドが分析に活かしやすい形で見せるためには、複雑で長大なデータ加工のロジックが必要でした。そのロジックの全てを理解している人は社内にも少なく、今回の移行に合わせて、要件を最初から見直すなど複雑なシステム構成の解読はとても骨の折れるものでした。
これまでのオンプレミスで構築したデータ基盤との大きな違いは、クラウドならではの従量課金制という課金体系にも現れました。ありがたいことに @cosme のユーザーは日々増加傾向にあり、設計時に計算したデータ量とリリース時のデータ量に予想以上に大きな差異が発生し、バッチ実行時に必要なリソースやスキャンサイズの見積もりが設計時とは大きく上振れしてしまうということもありました。ある程度はパーティション設計やクエリを見直すことで改善しましたが、今もまだ課題として残り、日々改善を行っています。
新データ基盤をリリースするためには、旧データ基盤との間で発生するデータ差異の原因解明も必要でした。今回の移行方針は、ビジネスロジックに関しては旧データ基盤の踏襲が基本となっており、データソースの変更を行ったもの以外は旧データ基盤からは大きな差異は発生しない想定で進められました。ですが、新しく開発したソースコードで実際に商用環境のデータを使って集計を行った際、一部では数%〜数十%の差異が発生し、その原因を特定するために非常に多くの時間を費やす結果となりました。その原因の多くは取得元のデータベースの状態が変わっていたことにありましたが、移行計画を立てる段階でのリスクヘッジ不足という反省にも繋がりました。
まとめ
クラウド移行はあくまで、課題を解決するための選択肢の一つであり、銀の弾丸ではありません。この記事に書いたとおり、私たちは大きな課題をいくつか解決することができましたが、それが全てのケースに当てはまるわけではありません。そして私たちも、残った課題や新たに浮上した課題や、今以上の運用保守や開発サイクルの改善をこれからも考え続ける必要があります。
ただ、たくさんの課題が解決して残った課題が浮き彫りになったことで、その中にある一つのプロダクトだけで考えるのではなく組織として広い視野を持って取り組むべき課題がなにかもはっきりしたように感じます。
最初にお話したとおり、私たちは今後もミッション実現のために統合データ基盤構築に邁進していきます。
今回のブランドオフィシャルのクラウド移行は、それにつながる大きな一歩となることでしょう。こうして100億件を超えるデータを保持するデータ基盤をクラウド移行できたことはチームとしての自信にもつながり、これから実現される統合データ基盤と新データ基盤との連携をよりスムーズにすることができるはず!です!!
本記事を読んでアイスタイルのデータ基盤開発に興味を抱いてくれた方は、ぜひ こちら からコンタクトをお待ちしております^^
まだまだアイスタイルのアドベントカレンダーは続きますので、明日からもどうぞ引き続きお楽しみください!!