学習済 InceptionV3におけるTensorFlowによる転移学習「CIFAR-10」編
はじめに
前回投稿したコードを変更して、学習済モデルInceptionV3の転移学習を行ってみました。
- 「Kaggle cats and dogs」での確認結果はこちらに投稿を載せております。
条件
- オープンデータ:CIFAR-10 ※メモリ不足に陥った為、使用したデータは半分です。
- データ形状:32x32x3を75x75x3にリサイズ ※Kerasの条件に75×75ピクセル以上と記載あり
結果
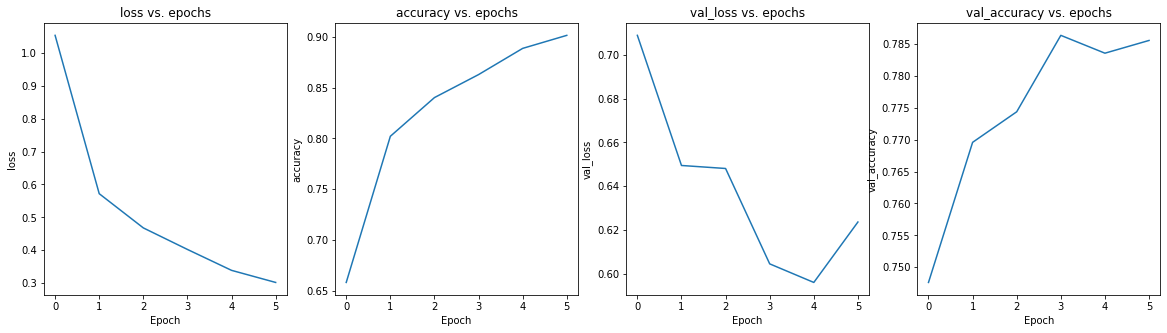
結果から先に申しますと精度は上がった物の期待するほどではありませんでした。
学習データを半分にした事とCIFAR-10の解像度も元々32×32と粗目の解像度である事が影響したかもしれません。
ただ、少ないデータでも精度が出た事から転移学習の目的は十分果たしているかと思います。
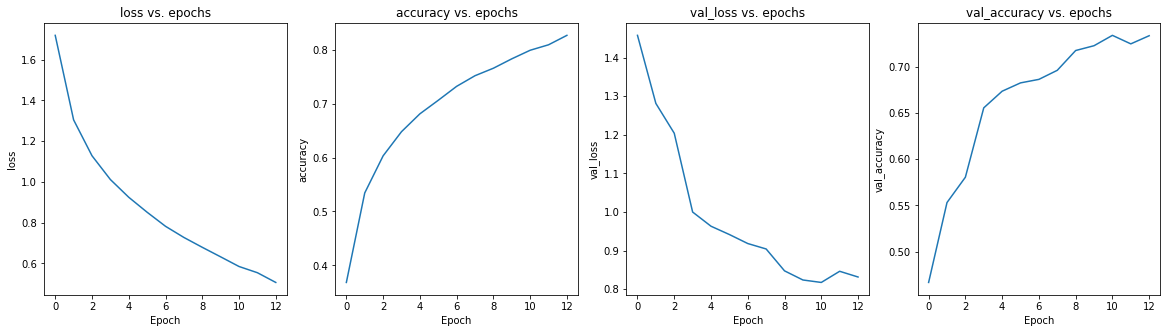
前回投稿したサンプルコードのTensorFlowのモデルではCIFAR-10の分類は73%位の汎化性能でしたが、本転移学習の結果は80%の結果でした。
ハイパーパラメータ、及び追加する層の場所を変更すればもっと良い結果がでるかもしれません。
- 前回投稿時のモデルの学習推移
- InceptionV3を使った転移学習の学習推移
コード詳細
詳細はコードにコメントを記載してありますので確認して下さい。
リンクからファイルをダウンロードして下さい。
- ファイル名:transfer_learning_cifar10.ipynb
※「アクセス権が必要です」と表示された場合はgoogleからログアウトして再度アクセスをして下さい。
https://drive.google.com/drive/folders/1SfD1fQdnfmcduJPqnsd82Ufx1EfmNH_R?usp=sharing
transfer_learning_cifar10.ipynb
# %%
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import random
import cv2
# %%
#学習時の定数設定
batch_size = 256 #バッチサイズ
epochs = 15 #エポック数
# %% [markdown]
# #### CIFAR-10 https://keras.io/ja/datasets/
# %%
#cifar10ダウンロード
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_data, y_data) = cifar10.load_data()
IMG_HEIGHT = 75 #画像データ高さ
IMG_WIDTH = 75 #画像データ幅
CATEGORY = 10 #カテゴリ数10
#画像データのリサイズ 32x32 ⇒ 75x75
img_data = []
for img in x_train:
img_data.append(cv2.resize(img, (75, 75)))
x_train = np.array(img_data)
img_data = []
for img in x_data:
img_data.append(cv2.resize(img, (75, 75)))
x_data = np.array(img_data)
#画像データの枚数を半分に減らす。※メモリ不足に陥った為データを減らしました。
x_train, _ = np.split(x_train, [int(len(x_train) * 0.5)])
x_data, _ = np.split(x_data, [int(len(x_data) * 0.5)])
y_train, _ = np.split(y_train, [int(len(y_train) * 0.5)])
y_data, _ = np.split(y_data, [int(len(y_data) * 0.5)])
# %% [markdown]
# #### 検証データとテストデータに分割
# %%
#検証データとテストデータに分割
x_val, x_test = np.split(x_data, [int(len(x_data) * 0.5)])
y_val, y_test = np.split(y_data, [int(len(y_data) * 0.5)])
#正規化
X_train = x_train / 255
X_val = x_val / 255
X_test = x_test / 255
# %% [markdown]
# #### データ形状確認 画像データ:(画像枚数、高さ、幅、色数)
# %%
#データ形状確認 画像データ:(枚数, 高さ, 幅, 色数)
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
print(y_train.shape)
print(y_val.shape)
print(y_test.shape)
# %% [markdown]
# #### 訓練データ、検証データ、テストデータをランダムに10枚プレビュー
# %%
#訓練データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_train.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_train[rnd])
ax[i].imshow(np.squeeze(X_train[rnd]))
# %%
#検証用データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_val.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_val[rnd])
ax[i].imshow(np.squeeze(X_val[rnd]))
# %%
#テスト用データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_test.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_test[rnd])
ax[i].imshow(np.squeeze(X_test[rnd]))
# %%
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, BatchNormalization, Dropout
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.optimizers import RMSprop
# %% [markdown]
# ## これより転移学習モデル生成
# ### 概要
# #### Inception V3 インスタンス作成
# * インスタンス作成
# * 学習済パラメーター読み込み
# * 学習済レイヤーのパラメータ更新のロック
# * Inception V3 モデルのどの層の後ろに独自の層を追加するか設定
# #### Inception V3 の指定の層の後ろに独自の層を追加
# * 独自の層を追加
# * モデルのハイパーパラメータ設定
# %% [markdown]
#
# %% [markdown]
# #### InceptionV3のインスタンス作成
# * 'include_top=False':InceptionV3モデルの出力部に独自の層を追加できる
# * 'input_shape':入力のデータ形状を設定。'include_top=False'時に指定できる
# * 'input_shape'は75×75以上でなければならない
# %%
# Inception_V3のインスタンスを作成し、学習済パラメータをセットする
weights_file = './inception_v3/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
inception_v3_model = InceptionV3(input_shape = (IMG_HEIGHT, IMG_WIDTH, 3), include_top = False, weights = None) #Inception_V3に接続する層のinput_shapeは75x75ピクセル以上である事
# 学習済パラメーターを読み込む
inception_v3_model.load_weights(weights_file)
#Inceptio_V3の各層のパラメータは学習時更新させないようにロックする
for layer in inception_v3_model.layers:
layer.trainable = False
# 本コードではInceptionV3の'mixed6'の後ろに独自の層を追加する事になる
end_layer = inception_v3_model.get_layer('mixed6').output
# %% [markdown]
# #### Inception V3 の指定の層の後ろに独自の層を追加
# %%
# 独自の層を追加
add_layer = layers.Flatten()(end_layer)
add_layer = layers.Dense(128, activation='relu')(add_layer)
add_layer = layers.Dense (CATEGORY, activation='softmax')(add_layer)
model = Model(inception_v3_model.input, add_layer)
# ハイパーパラメータ設定
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# %% [markdown]
# #### 生成モデルインフォ
# %%
#生成モデルインフォ
model.summary()
# %% [markdown]
# #### コールバックの設定 https://keras.io/ja/callbacks/
# 内容:エポック毎に呼び出される。
# 'checkpoint_best':'val_accuracy'を監視し一番精度の良かったエポック時の重みパラメーターを保存する
# 'early_stopping':'val_accuracy'を監視し検証精度が停滞したら訓練を停止する
# %%
#コールバック
#checkpoint_best_path:バリデーション精度の最大時の重みデータを保存
#early_stoping:アーリーストッピング設定。バリデーション精度が停滞したら修了
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint_best_path = 'modelCNN_checkpoints_best/checkpoint'
checkpoint_best = ModelCheckpoint(filepath=checkpoint_best_path, save_weights_only=True, save_freq='epoch',
monitor='val_accuracy', save_best_only=True, verbose=1)
early_stopping = EarlyStopping(monitor='val_accuracy', patience=2)
# %%
# モデルフィット(学習)
callbacks = [checkpoint_best, early_stopping]
history = model.fit(X_train, y_train, epochs=epochs, validation_data=(X_val, y_val), batch_size=batch_size, callbacks=callbacks)
# %%
#訓練ロス、訓練精度、検証ロス、検証精度の可視化
fig, ax = plt.subplots(1, 4, figsize=(20, 5))
ax[0].plot(history.history['loss'])
ax[0].set_title('loss vs. epochs')
ax[0].set_ylabel('loss')
ax[0].set_xlabel('Epoch')
ax[1].plot(history.history['accuracy'])
ax[1].set_title('accuracy vs. epochs')
ax[1].set_ylabel('accuracy')
ax[1].set_xlabel('Epoch')
ax[2].plot(history.history['val_loss'])
ax[2].set_title('val_loss vs. epochs')
ax[2].set_ylabel('val_loss')
ax[2].set_xlabel('Epoch')
ax[3].plot(history.history['val_accuracy'])
ax[3].set_title('val_accuracy vs. epochs')
ax[3].set_ylabel('val_accuracy')
ax[3].set_xlabel('Epoch')
# %% [markdown]
# #### コールバックで保存された検証精度(val_accuracy)最大時のパラメータを読み込む
# %%
model.load_weights('modelCNN_checkpoints_best/checkpoint')
# %% [markdown]
# #### テストデータで汎化性能確認
# %%
#テストデータでの精度確認
print("Evaluate on test data")
results = model.evaluate(X_test, y_test, verbose=0)#, batch_size=128)
print("test loss, test acc:", results)