機械学習における各種分類手法
今年の初めにオンライン学習のCOURSERAで機械学習のフレームワークである、TensorFlow、scikit-learnを習得したのですが、折角なので各種オープンデータを使った機械学習の各種分類手法の比較ができるコードを作成いたしました。
実際ある課題に対し実力を検証してみたので、どんなイメージの課題かも併せて紹介したいと思います。
- 転移学習についてはこちらに記事を投稿しております。
コード詳細
使用したデータセット
- CIFAR-10
- SVHN(Street View House Numbers)※別のプログラムで前処理しております。
- Fashion-MNINS
- MNIST
- Kaggle Cats & Dogs ※別のプログラムで前処理しております。
今回使用した手法
- TensorFlow(CNN)
- ロジスティック回帰
- サポートベクターマシン(SVM)
- 決定木
- ランダムフォレスト
コード
リンクからファイルとフォルダをダウンロードして下さい。
「アクセス権が必要です」と表示された場合はgoogleからログアウトしてから再度アクセスをして下さい。
https://drive.google.com/drive/folders/1SfD1fQdnfmcduJPqnsd82Ufx1EfmNH_R?usp=sharing
※データセットのダウンロードセルは任意のセルを実行したら
「これより共通処理」のセルに進んで実行して下さい。
machin-learning.ipynb
# %% [markdown]
# 各種ラベル付き画像データセットを機械学習の各種分類手法で試せるプログラムを作ってみました
# 尚、プログラムを共通化する為に一部のデータセットは他のデータ形状と同形状にした後のデータを使用しております。
# #### 使用したデータセット
# * CIFAR-10
# * SVHN(Street View House Numbers)※numpy配列への変換済データ
# * Fashion-MNINS
# * MNIST
# * Kaggle Cats & Dogs ※numpy配列への変換済データ
# #### 機械学習各種分類手法
# * DeepLearning TensorFlow
# * ロジスティック回帰
# * サポートベクターマシン(SVM)
# * 決定木
# * ランダムフォレスト
#
# %%
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import random
# %%
#学習時の定数設定
batch_size = 256 #バッチサイズ
epochs = 15 #エポック数
# %% [markdown]
# #### CIFAR-10 https://keras.io/ja/datasets/
# %%
#cifar10ダウンロード
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_data, y_data) = cifar10.load_data()
IMG_HEIGHT = 32 #画像データ高さ
IMG_WIDTH = 32 #画像データ幅
CATEGORY = 10 #カテゴリ数10
# %% [markdown]
# #### SVHN(Street View House Numbers) http://ufldl.stanford.edu/housenumbers/
# %%
#SVHN Dataset
x_train = np.load('./svhn_data/svhn_train_data.npy')
y_train = np.load('./svhn_data/svhn_train_label.npy')
x_data = np.load('./svhn_data/svhn_test_data.npy')
y_data = np.load('./svhn_data/svhn_test_label.npy')
IMG_HEIGHT = 32 #画像データ高さ
IMG_WIDTH = 32 #画像データ幅
CATEGORY = 10 #カテゴリ数10
# %% [markdown]
# #### kaggle dogs vs cats https://www.kaggle.com/c/dogs-vs-cats
# %%
#kaggle 犬猫 Dataset
x_train = np.load('./cat_dog_data/cat_dog_train_data.npy')
y_train = np.load('./cat_dog_data/cat_dog_train_label.npy')
x_data = np.load('./cat_dog_data/cat_dog_test_data.npy')
y_data = np.load('./cat_dog_data/cat_dog_test_label.npy')
IMG_HEIGHT = 150 #画像データ高さ
IMG_WIDTH = 150 #画像データ幅
CATEGORY = 2 #カテゴリ数2
# %% [markdown]
# #### Fashion-MNIST https://github.com/zalandoresearch/fashion-mnist
# %%
#Fashion Mnist Dataset
fashion_mnist = keras.datasets.fashion_mnist
(x_train, y_train), (x_data, y_data) = fashion_mnist.load_data()
x_train = np.expand_dims(x_train, axis=3) #画像データは3次元データを4次元にする
x_data = np.expand_dims(x_data, axis=3) #画像データは3次元データを4次元にする
y_train = np.expand_dims(y_train, axis=1) #ラベルデータは1次元データを2次元にする
y_data = np.expand_dims(y_data, axis=1) #ラベルデータは1次元データを2次元にする
IMG_HEIGHT = 28 #画像データ高さ
IMG_WIDTH = 28 #画像データ幅
CATEGORY = 10 #カテゴリ数10
# %% [markdown]
# #### MINIST 手書き文字 https://github.com/zalandoresearch/fashion-mnist
# %%
#mnist手書き数字
mnist = keras.datasets.mnist
(x_train, y_train), (x_data, y_data) = mnist.load_data()
x_train = np.expand_dims(x_train, axis=3) #画像データは3次元データを4次元にする
x_data = np.expand_dims(x_data, axis=3) #画像データは3次元データを4次元にする
y_train = np.expand_dims(y_train, axis=1) #ラベルデータは1次元データを2次元にする
y_data = np.expand_dims(y_data, axis=1) #ラベルデータは1次元データを2次元にする
IMG_HEIGHT = 28 #画像データ高さ
IMG_WIDTH = 28 #画像データ幅
CATEGORY = 10 #カテゴリ数10
# %% [markdown]
# ## これより共通処理
# ### 1.データ前処理
# * テストデータを検証データ(バリデーションデータ)とテストデータに分割
# * 画像データは0~255のデータを0~1.0に正規化
# * データ形状確認。画像データの形状は(画像枚数、高さ、幅、色数)の4次元になります
# * 訓練データ画像、検証データ画像、テストデータ画像をランダムに10画像プレビュー
# ### 2.機械学習各種手法
# * TensorFlow
# * ロジスティック回帰
# * サポートベクターマシン
# * 決定木
# * ランダムフォレスト
# %% [markdown]
# #### 検証データとテストデータに分割
# %%
#検証データとテストデータに分割
x_val, x_test = np.split(x_data, [int(len(x_data) * 0.5)])
y_val, y_test = np.split(y_data, [int(len(y_data) * 0.5)])
#正規化
X_train = x_train / 255
X_val = x_val / 255
X_test = x_test / 255
# %% [markdown]
# #### データ形状確認 画像データ:(画像枚数、高さ、幅、色数)
# %%
#データ形状確認 画像データ:(枚数, 高さ, 幅, 色数)
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
print(y_train.shape)
print(y_val.shape)
print(y_test.shape)
# %% [markdown]
# #### 訓練データ、検証データ、テストデータをランダムに10枚プレビュー
# %%
#訓練データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_train.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_train[rnd])
ax[i].imshow(np.squeeze(X_train[rnd]))
# %%
#検証用データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_val.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_val[rnd])
ax[i].imshow(np.squeeze(X_val[rnd]))
# %%
#テスト用データの画像をランダム表示
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10):
rnd = random.randint(0, X_test.shape[0])
ax[i].set_axis_off()
ax[i].set_title(y_test[rnd])
ax[i].imshow(np.squeeze(X_test[rnd]))
# %%
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, BatchNormalization, Dropout
# %% [markdown]
# ### これよりCNNモデル評価
# %% [markdown]
# #### モデル生成
# %%
#CNNモデル生成
model = tf.keras.models.Sequential([
Conv2D(64, (3, 3), activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH, X_train.shape[3])),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(256, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(CATEGORY, activation='softmax') #カテゴリ数に応じてノード数変更
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) #softmax時
# %% [markdown]
# #### 生成モデルインフォ
# %%
#生成モデルインフォ
model.summary()
# %% [markdown]
# #### コールバック関数
# ###### ※この関数はオンライン講座 Cousera の「DeepLearning.AI TensorFlow Developer」で受講した際の手法となっております。
# 内容:エポック毎に呼び出される。監視したい下記データに対し条件を設定する
# 'loss':訓練データ時における損失関数 'accuracy':訓練データ時における精度
# 'val_loss':検証データ時における損失関数 'val_accuracy':検証データ時における精度
# %%
#コールバック関数
# 1エポック毎に訓練データの精度(accuracy)を確認し85%以上で終了
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>=0.85):
print("\nReached 85% accuracy so cancelling training!")
self.model.stop_training = True
my_callback = myCallback()
# %% [markdown]
# #### コールバックの設定 https://keras.io/ja/callbacks/
# 内容:エポック毎に呼び出される。
# 'checkpoint_best':'val_accuracy'を監視し一番精度の良かったエポック時の重みパラメーターを保存する
# 'early_stopping':'val_accuracy'を監視し検証精度が停滞したら訓練を停止する
# %%
#コールバック
#checkpoint_best_path:バリデーション精度の最大時の重みデータを保存
#early_stoping:アーリーストッピング設定。バリデーション精度が停滞したら修了
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint_best_path = 'modelCNN_checkpoints_best/checkpoint'
checkpoint_best = ModelCheckpoint(filepath=checkpoint_best_path, save_weights_only=True, save_freq='epoch',
monitor='val_accuracy', save_best_only=True, verbose=1)
early_stopping = EarlyStopping(monitor='val_accuracy', patience=2)
# %% [markdown]
# #### 学習実行
# 'history'には各エポック毎の'loss'、'accuracy'、'val_loss'、'val_accuracy'の値が記憶される
# %%
# モデルフィット(学習)
callbacks = [checkpoint_best, early_stopping, my_callback]
history = model.fit(X_train, y_train, epochs=epochs, validation_data=(X_val, y_val), batch_size=batch_size, callbacks=callbacks)
# %% [markdown]
# #### 'history'に保存された学習時のエポック毎の訓練ロス、訓練精度、検証ロス、検証精度の可視化
# グラフを確認して過学習が起き始めるポイントでコールバック関数の監視条件を設定すれば良いです
# %%
#訓練ロス、訓練精度、検証ロス、検証精度の可視化
fig, ax = plt.subplots(1, 4, figsize=(20, 5))
ax[0].plot(history.history['loss'])
ax[0].set_title('loss vs. epochs')
ax[0].set_ylabel('loss')
ax[0].set_xlabel('Epoch')
ax[1].plot(history.history['accuracy'])
ax[1].set_title('accuracy vs. epochs')
ax[1].set_ylabel('accuracy')
ax[1].set_xlabel('Epoch')
ax[2].plot(history.history['val_loss'])
ax[2].set_title('val_loss vs. epochs')
ax[2].set_ylabel('val_loss')
ax[2].set_xlabel('Epoch')
ax[3].plot(history.history['val_accuracy'])
ax[3].set_title('val_accuracy vs. epochs')
ax[3].set_ylabel('val_accuracy')
ax[3].set_xlabel('Epoch')
# %% [markdown]
# #### テストデータを使ってモデルの汎化性能を確認
# %%
#テストデータでの精度確認
print("Evaluate on test data")
results = model.evaluate(X_test, y_test, verbose=0)#, batch_size=128)
print("test loss, test acc:", results)
# %% [markdown]
# ### これより scikit-learn 各種分類手法
# 画像データ(画像枚数、高さ、幅、色数)の(高さ、幅、色数)を1次元にし、標準化を行う
# %% [markdown]
# #### scikit-learn 用にデータ形状を変換
# %%
#scikit-learn用にデータ変換
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
X_train_ckt = X_train.reshape(X_train.shape[0], -1) #訓練データの(高さ、幅、色数)を1次元にする
X_test_ckt = X_test.reshape(X_test.shape[0], -1) #テストデータの(高さ、幅、色数)を1次元にする
scaler = StandardScaler() #データの標準化処理
scaler.fit(X_train_ckt) #
X_train_std = scaler.transform(X_train_ckt) #
X_test_std = scaler.transform(X_test_ckt) #
print(X_train_std.shape)
print(X_test_std.shape)
# %% [markdown]
# #### ロジスティック回帰で分類
# %% [markdown]
# 学習実行
# %%
# ロジスティック回帰
from sklearn import linear_model
clf = linear_model.LogisticRegression()
clf.fit(X_train_std, y_train)
# %% [markdown]
# 汎化性能確認
# %%
#ロジスティック回帰 テストデータ精度
pre = clf.predict(X_test_std)
ac_score = metrics.accuracy_score(y_test, pre)
print(ac_score)
# %% [markdown]
# #### サポートベクターマシン(SVM)で分類
# ###### ※学習時間が長いので注意願います。
# %% [markdown]
# 学習実行
# %%
#サポートベクターマシン
from sklearn import svm
clf = svm.SVC()
clf.fit(X_train_std, y_train)
# %% [markdown]
# 汎化性能確認
# %%
#サポートベクターマシン テストデータ精度
pre = clf.predict(X_test_std)
ac_score = metrics.accuracy_score(y_test, pre)
print(ac_score)
# %% [markdown]
# #### 決定木で分類
# %% [markdown]
# 学習実行
# %%
#決定木
from sklearn import tree
clf = tree.DecisionTreeClassifier(max_depth=3)
clf = clf.fit(X_train_std, y_train)
# %% [markdown]
# 汎化性能確認
# %%
#決定木 テストデータ精度
pre = clf.predict(X_test_std)
ac_score = metrics.accuracy_score(y_test, pre)
print(ac_score)
# %% [markdown]
# #### ランダムフォレストで分類
# %% [markdown]
# 学習実行
# %%
#ランダムフォレスト
from sklearn import ensemble
clf = ensemble.RandomForestClassifier(random_state=1234)
clf.fit(X_train_std, y_train)
# %% [markdown]
# 汎化性能確認
# %%
#ランダムフォレスト テストデータ精度
pre = clf.predict(X_test_std)
ac_score = metrics.accuracy_score(y_test, pre)
print(ac_score)
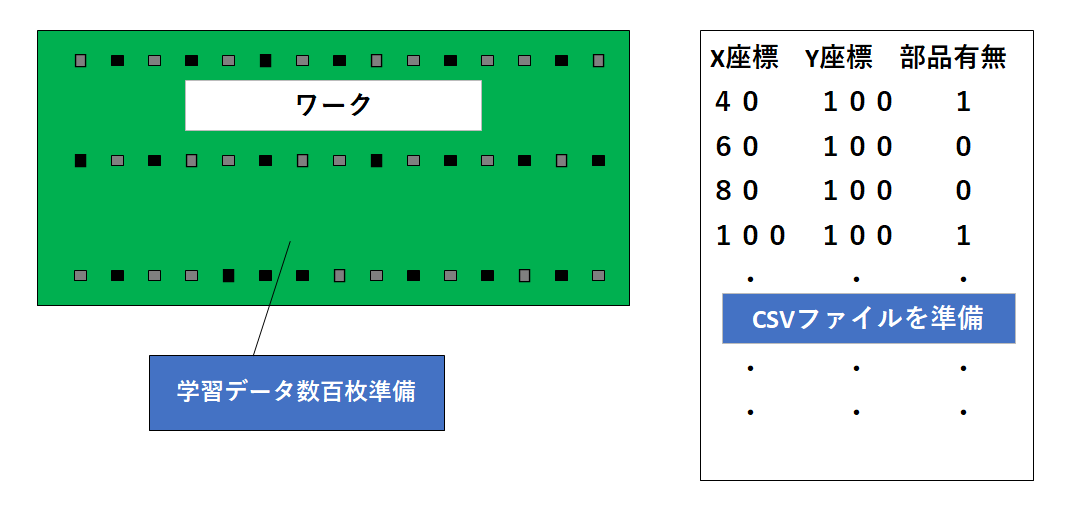
機械学習の実力検証
※イメージであり実際とは異なります
1.課題
ワーク上の所定の位置に部品が実装されているかを画像認識により合否判定する。
2.条件
- ワーク上の実装部品は全て同じ形状であるが向きが縦横方向存在する。
- 部品の実装座標は数十箇所あるが全てに実装されているわけではない。
- ワーク1枚の画像から実装部品各座標で40×40ピクセルでトリミングを行う事で、ワーク1枚の画像から数十箇所の部品有のトリミング画像、部品無しのトリミング画像が取得される。(100枚の写真で60箇所の場合はトリミング画像は6000枚)
3.アノテーションの自動化
①CSVファイルの座標値データから各部品座標値で40×40ピクセルでトリミング
②CSVファイルの部品有無情報から①のトリミング画像にラベル付けする
4.結果
今回使用した画像では簡単すぎて全ての手法で精度100%になりました。
実務で機械学習を適用するかは工程能力の算出等が必要になる為、別な話になりますが、今後、何らかの課題の中で機械学習の適用が増えてくるかと思っております。