勉強したことをまとめた記事です。
ResNet とは
ResNet のすごさ
resnet は論文[ https://arxiv.org/abs/1512.03385 ]で提案されたモデルで、
2015年の画像コンペで以下のような圧倒的な成績を残しました。
- ImageNet classification: 1位
- ImageNet Detection: 1位 (16% better than 2nd)
- ImageNet Localization: 1位 (27% better than 2nd)
- COCO Detection: 1位 (11% better than 2nd)
- COCO Segmentation: 1位 (12% better than 2nd)
ResNet の特徴
ResNet がそれまでのモデルと大きく異なるのが、152層という層の深さです。
(2012年のAlexNetが8層、2014年のVGGが16層であることを思い出せばとても多い)
deep neural network の性質として、"Wide よりも Deep" というのがあります。
同じニューロン数なら、ネットワークの各層の幅をワイドにするよりも、階層の深さをよりディープにした方が性能が良いということだそうです。(なおこれは、経験則によるものでなぜそうなのか理論的にはよくわかっていません。)
なら"どんどん層を増やせばいいじゃないか"ということになりますが、これが難しかったのです。
なぜなら、従来のモデルのまま単純に層を増やしスフィルと勾配消失や勾配発散、過学習などによりうまく学習できないからです。(詳しくは他の記事を参照してもらえれば、)
ResNetはこの問題を、残渣学習(Residual learning)により改善しました。
これにより152層という従来と比べてとても多い層での学習を成功させました。
ResNetの使い方
事前学習済みのモデルが、PytorchやKerasで実装されていて簡単に使うことができます。
用途としては物体認識などの他に、特徴抽出として画像をベクトルに変換することが主です。
事前学習済みモデルは、物体認識のために学習されたモデルですが、特徴抽出器として他のタスクにも有効に使えることがいくつか確認されています(例えば画像キャプション生成 https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf )。
この記事に書いてあること
残渣学習の手法についての記事はいくつかあるようですが、
- ResNetの具体的なアーキテクチャ
- 特徴抽出のコード
ついての記事が日本語であまりなかったのでまとめます。
"残渣学習とはなんぞや"については、他の記事を参考にしてもらうということで触れないでおきます。
ここでは pytorch を使います。
ResNetのアーキテクチャ
先ほどは ResNet は152層のモデルと書きましたが、実は論文では18,34,50,101,152層のものが提案されています。
層の数が増えるにしたがって、精度は上がります。
各モデルの各層の詳細は次のようになっています(論文[ https://arxiv.org/abs/1512.03385 ]中の図)。

この図だけみても、各数字の意味がわからないと思いますが、例えば34層のものはつぎのような感じです
(論文[ https://arxiv.org/abs/1512.03385 ]中の図を一部改変)
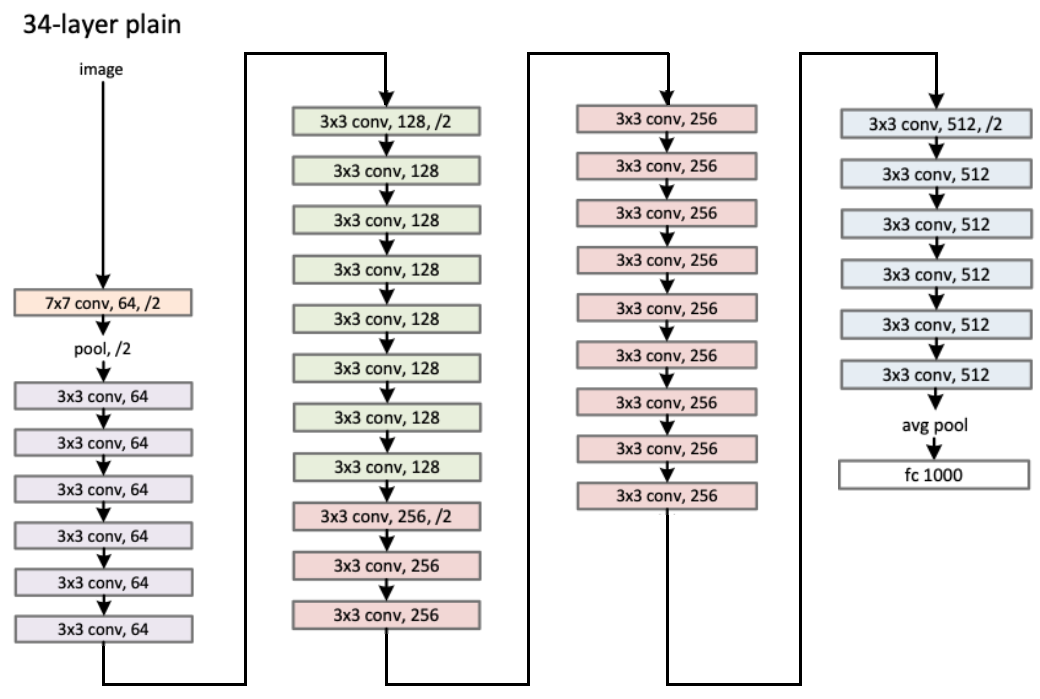
pytorch での実装は次のような感じになっていました。
https://pytorch.org/docs/stable/_modules/torchvision/models/resnet.html#resnet50
わかりやすいコードです。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
特徴抽出
特徴抽出では、モデルの隠れ層の出力を画像ベクトルとして取り出します。
CNNモデルでの特徴抽出ではどこの隠れ層の出力をとってくるか、という自由度があります。
一般的に、最終層に近いほど事前学習タスクに最適化されたベクトル、遠いほど画像の基礎的な部分(直線があるかなど)に注目したベクトルが得られると言われています。
今回は50層のモデルから、次の2つのベクトルを抽出したいと思います。
- 最後から2つ目のCNNレイヤーの出力 $v\in\mathbb{R}^{14\times14\times1024}$
- 最後のCNNレイヤーの出力を max pooling したもの $v\in\mathbb{R}^{2048}$
2の方法では、最後のCNNレイヤーの出力は $v^\prime\in\mathbb{R}^{7\times7\times2048}$ であり、1つ目と2つ目の要素に対して平均をとる形になります。
1の手法と2の手法の大きな違いは、1の手法は空間的な情報を含んでいるが2の手法は含まないシンプルなベクトルになっているという点です。さらにコンパクトなベクトルとして、最後のソフトマックス層の入力 $v\in\mathbb{R}^{K}$ を取り出す手法も考えられます(事前学習データがImageNetの場合はK=1000)。
また、他の特徴抽出の手法として、物体認識をしてからその各物体の領域に対して特徴抽出するというものもあります。
コードはWMT17のマルチモーダル機械翻訳 shared task の、特徴抽出として公開されているコードを利用しました。
https://www.statmt.org/wmt17/multimodal-task.html
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
from pathlib import Path
import numpy as np
from PIL import Image
from torch.autograd import Variable
import torch.utils.data as data
from torchvision.models import resnet50
from torchvision import transforms
# This script uses the PyTorch's pre-trained ResNet-50 CNN to extract
# res4f_relu convolutional features of size 1024x14x14
# avgpool features of size 2048D
# We reproduced ImageNet val set Top1/Top5 accuracy of 76.1/92.8 %
# as reported in the following web page before extracting the features:
# http://pytorch.org/docs/master/torchvision/models.html
#
# We save the final files as 16-bit floating point tensors to reduce
# the size by 2x. We confirmed that this does not affect the above accuracy.
#
# Organization of the image folder:
# In order to extract features from an arbitrary set of images,
# you need to create a folder with a file called `index.txt` in it that
# lists the filenames of the raw images in an ordered way.
# -f /path/to/images/train --> train folder contains 29K images
# and an index.txt with 29K lines.
#
class ImageFolderDataset(data.Dataset):
"""A variant of torchvision.datasets.ImageFolder which drops support for
target loading, i.e. this only loads images not attached to any other
label.
Arguments:
root (str): The root folder which contains a folder per each split.
split (str): A subfolder that should exist under ``root`` containing
images for a specific split.
resize (int, optional): An optional integer to be given to
``torchvision.transforms.Resize``. Default: ``None``.
crop (int, optional): An optional integer to be given to
``torchvision.transforms.CenterCrop``. Default: ``None``.
"""
def __init__(self, root, split, resize=None, crop=None, index="index.txt"):
self.split = split
self.root = Path(root).expanduser().resolve() / self.split
# Image list in dataset order
self.index = self.root / index
print("index : {}".format(self.index))
_transforms = []
if resize is not None:
_transforms.append(transforms.Resize(resize))
if crop is not None:
_transforms.append(transforms.CenterCrop(crop))
_transforms.append(transforms.ToTensor())
_transforms.append(
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]))
self.transform = transforms.Compose(_transforms)
if not self.index.exists():
raise(RuntimeError(
"index.txt does not exist in {}".format(self.root)))
self.image_files = []
with self.index.open() as f:
for fname in f:
fname = self.root / fname.strip()
assert fname.exists(), "{} does not exist.".format(fname)
self.image_files.append(str(fname))
def read_image(self, fname):
with open(fname, 'rb') as f:
img = Image.open(f).convert('RGB')
return self.transform(img)
def __getitem__(self, idx):
return self.read_image(self.image_files[idx])
def __len__(self):
return len(self.image_files)
def resnet_forward(cnn, x):
x = cnn.conv1(x)
x = cnn.bn1(x)
x = cnn.relu(x)
x = cnn.maxpool(x)
x = cnn.layer1(x)
x = cnn.layer2(x)
res4f_relu = cnn.layer3(x)
res5e_relu = cnn.layer4(res4f_relu)
avgp = cnn.avgpool(res5e_relu)
avgp = avgp.view(avgp.size(0), -1)
return res4f_relu, avgp
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='extract-cnn-features')
parser.add_argument('-f', '--folder', type=str, required=True,
help='Folder to image files i.e. /images/train')
parser.add_argument('-b', '--batch-size', type=int, default=256,
help='Batch size for forward pass.')
parser.add_argument('-o', '--output', type=str, default='resnet50',
help='Output file prefix. Ex: resnet50')
parser.add_argument('-s', '--save_path', type=str, required=True,
help='save dilectory')
parser.add_argument('-id', '--id_file', type=str, default="index.txt",
help='index file')
# Parse arguments
args = parser.parse_args()
root = Path(args.folder)
split = root.name
# Create dataset
dataset = ImageFolderDataset(root.parent, split, resize=256, crop=224, index=args.id_file)
print('Root folder: {} (split: {}) ({} images)'.format(
root, split, len(dataset)))
loader = data.DataLoader(dataset, batch_size=args.batch_size)
print('Creating CNN instance.')
cnn = resnet50(pretrained=True)
# Remove final classifier layer
del cnn.fc
# Move to GPU and switch to evaluation mode
cnn.cuda()
cnn.train(False)
# Create placeholders
conv_feats = np.zeros((len(dataset), 1024, 14, 14), dtype='float32')
pool_feats = np.zeros((len(dataset), 2048), dtype='float32')
n_batches = int(np.ceil(len(dataset) / args.batch_size))
bs = args.batch_size
for bidx, batch in enumerate(loader):
x = Variable(batch, volatile=True).cuda()
res4f, avgpool = resnet_forward(cnn, x)
pool_feats[bidx * bs: (bidx + 1) * bs] = avgpool.data.cpu()
conv_feats[bidx * bs: (bidx + 1) * bs] = res4f.data.cpu()
print('{:3}/{:3} batches completed.'.format(
bidx + 1, n_batches), end='\r')
# Save the files
save_dir = Path(args.save_path)
output_avg = save_dir.joinpath(args.output+'-avgpool')
output_4relu = save_dir.joinpath(args.output+'-res4frelu')
np.save(output_avg, pool_feats.astype('float16'))
np.save(output_4relu, conv_feats.astype('float16'))
上のコードを次のようにして使います
# !/bin/bash
CUDA_VISIBLE_DEVICES=0 python feature-extractor \
-f /disk/n/object2words/object_relation_transformer/data/img/train2014/ \
-o missing_train_2014_coco-resnet50 \
-b 64 \
-s /disk/n/ms_COCO/resnet50_feature \
-id index.en.txt
参考にしたもの
object detection についてのまとめ(英語スライド)
http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
ResNetについて
http://terada-h.hatenablog.com/entry/2016/12/13/192940