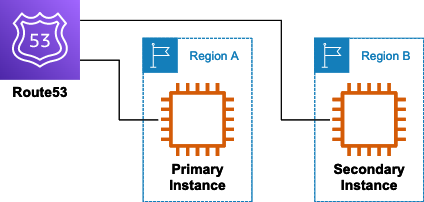
完成図
プライマリサーバが正常に動作しなくなった時、検知してリカバリサーバにルーティングを変更する構成。
リージョンを分けることで冗長化
やってないけど、Route 53 のヘルスチェック先とレコードを変更すれば S3 静的ホスティングとかでもいける、たぶん...
必要リソース
-
EC2インスタンス x2
- プライマリインスタンス
- セカンダリインスタンス(プライマリとは別のリージョンに作成)
-
Route53 ヘルスチェック x2
- プライマリ用
- セカンダリ用
-
Route53 レコード x2
- プライマリ用
- セカンダリ用
ホストゾーンの作成は割愛
-
CloudWatch アラーム x2
- プライマリ用(ヘルスチェック作成で自動作成)
- セカンダリ用(ヘルスチェック作成で自動作成)
-
SNS トピック x1
- プライマリ用(ヘルスチェック作成で自動作成)
構築手順
1. オリジンの作成
EC2インスタンス x2 を別々のリージョンに作成
(S3 静的ホスティングの場合は S3 x2)
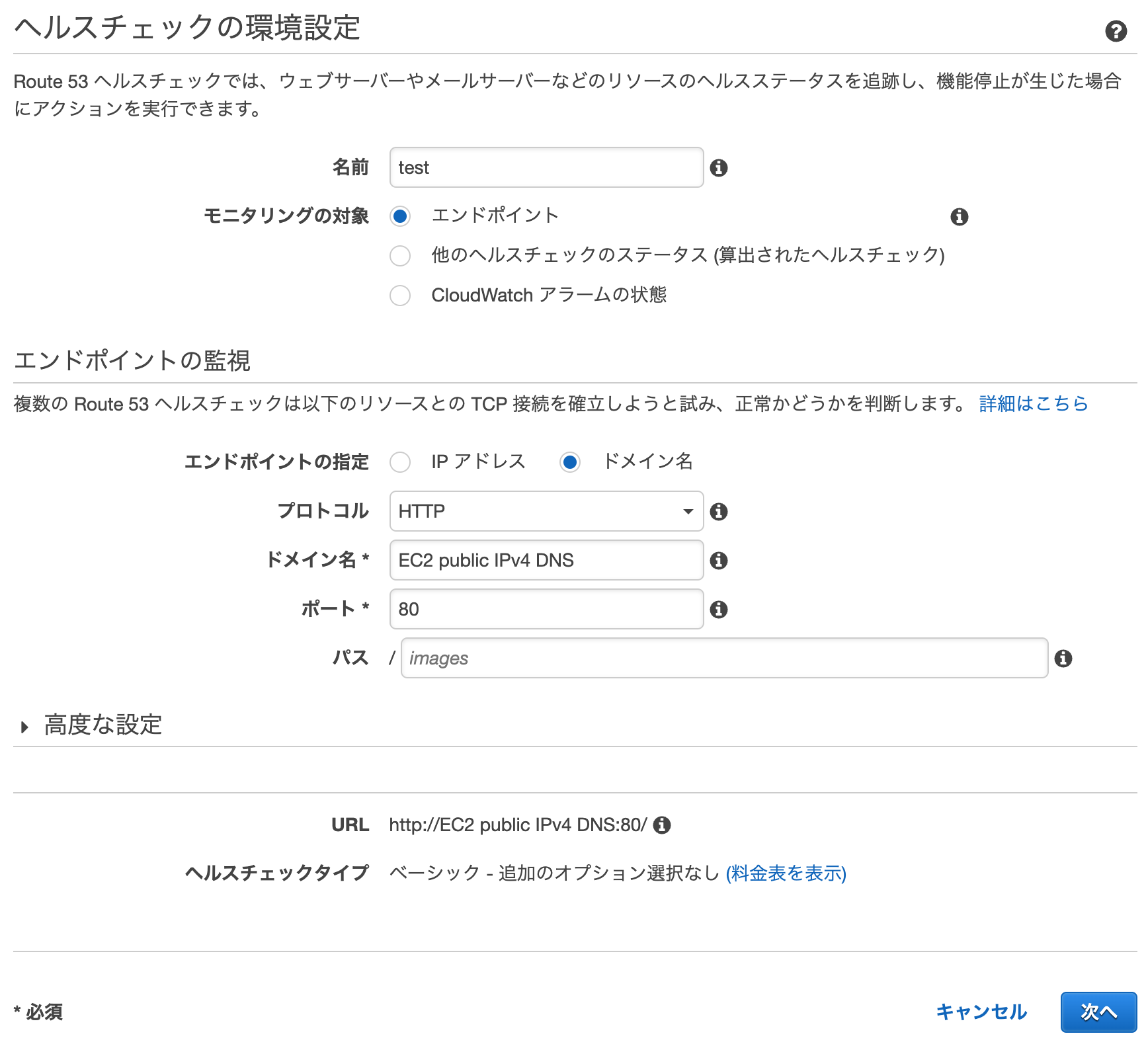
2. ヘルスチェックの作成
Route53 ヘルスチェックをプライマリ用、セカンダリ用それぞれ作成
ヘルスチェック作成時に CloudWatch アラーム、SNS トピックが自動的に作成される
作成された段階で SNS トピックから登録したメールアドレスに認証メールが来る、認証を完了しないと通知が来ないので注意
- 名前 : 適当
- モニタリング対象 : エンドポイント
- エンドポイント : ドメイン名
- プロトコル : HTTP
- ドメイン名 : EC2のパブリック IPv4 DNS
- ポート : 80
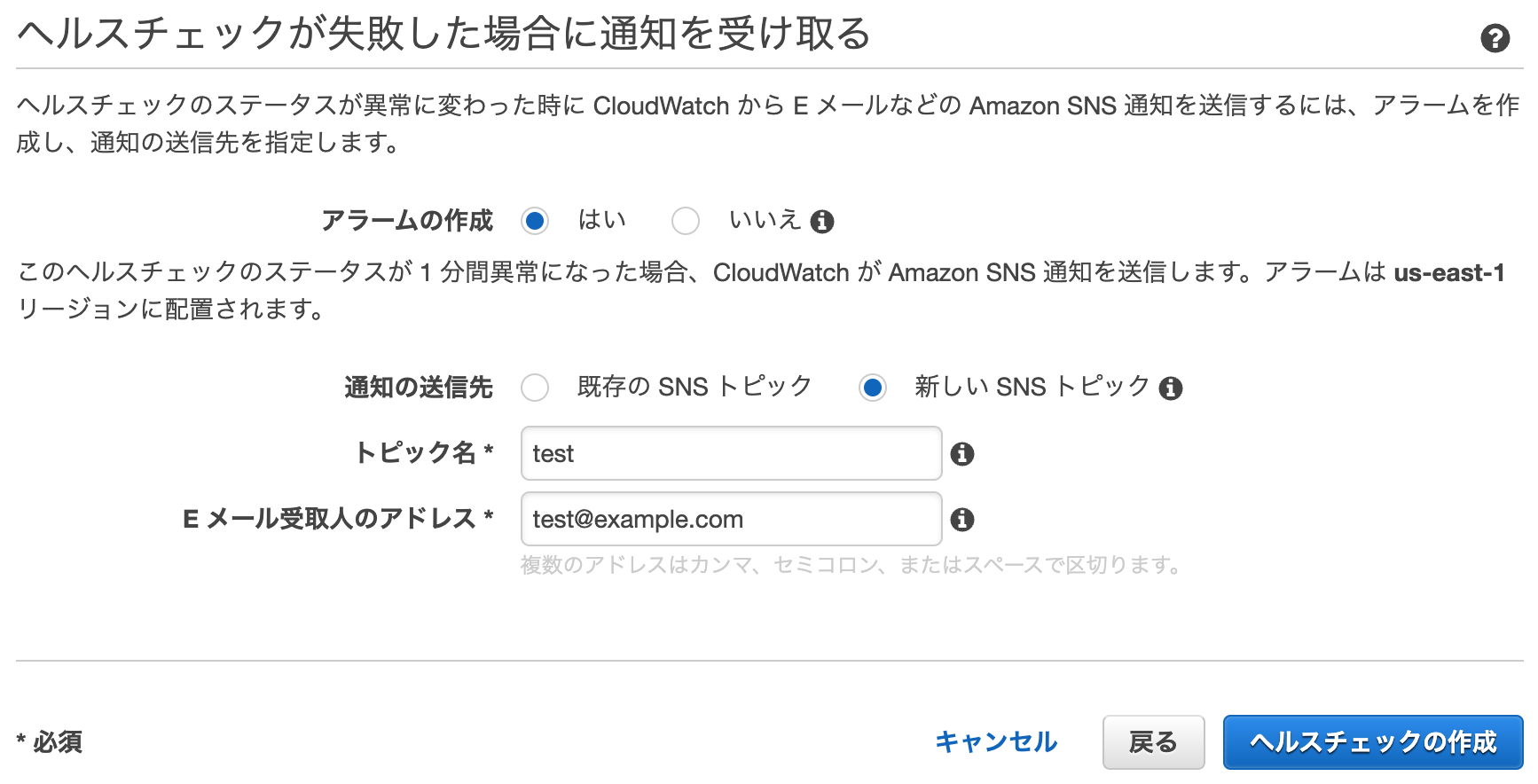
- アラームの作成 : はい
- 通知の送信先 : 新しいSNSトピック
- トピック名 : 適当
- Eメール受け取りのアドレス : 適当
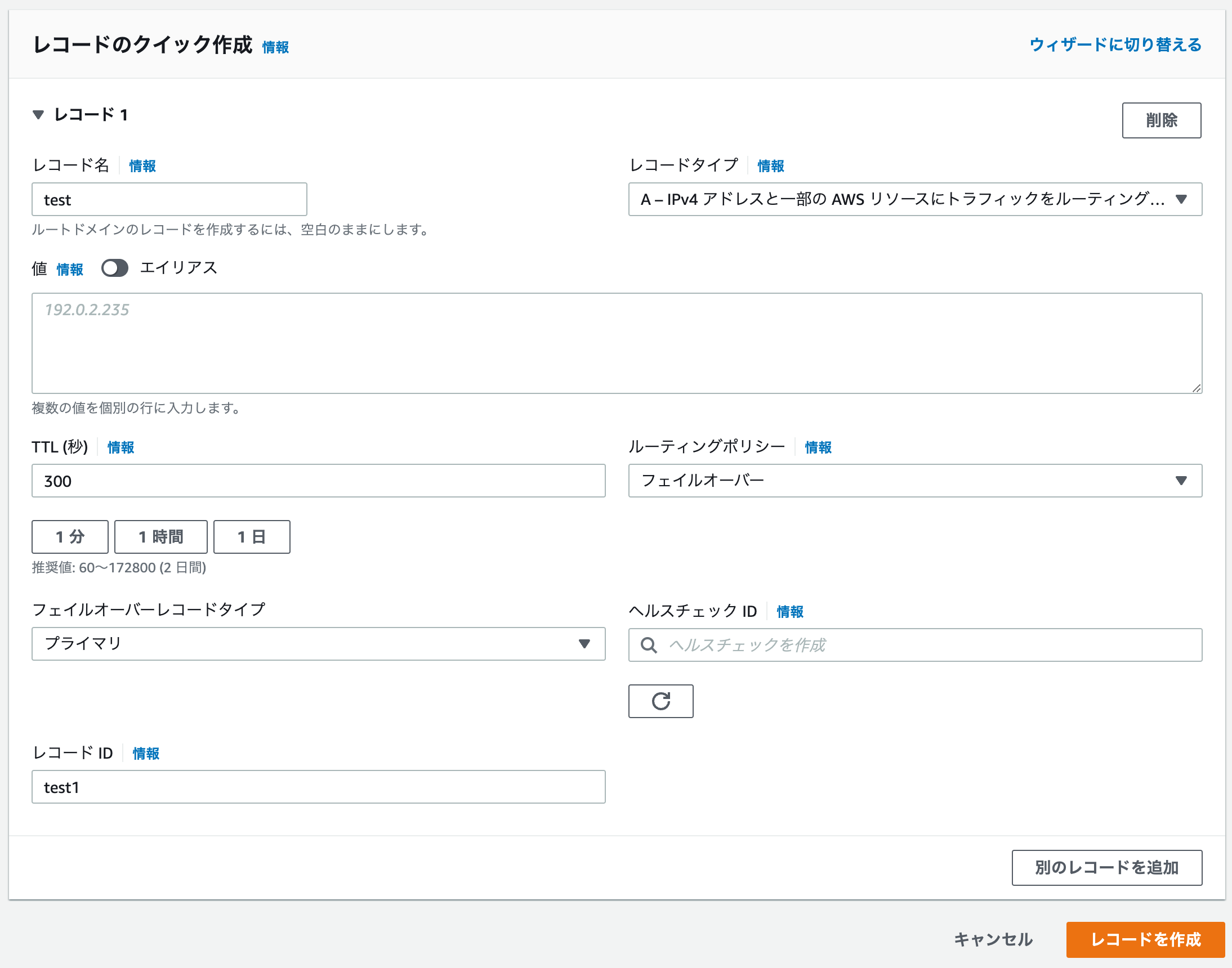
3. Route 53 レコードの作成
ホストゾーンの作成は割愛
Route53 レコードをプライマリ用、セカンダリ用それぞれ作成
- レコード名 : ドメイン
- レコードタイプ : AかAAAA
- 値 : EC2インスタンスを指定
- エイリアス : いいえ
- TTL : 用途に応じて
- ルーティングポリシー : Failover
- フェイルオーバーレコードタイプ : プライマリ、セカンダリ
- ヘルスチェックID : Route53 ヘルスチェック
- レコードID : プライマリとセカンダリで別のID
4. CloudWatch アラームの設定変更
Route 53 ヘルスチェック時に自動的に CloudWatch アラームが作成される。
このままだとヘルスチェックのエラーは設定したメールに通知してくれるが、エラーが解除され正常に戻ったことは通知してくれない。
エラー状態の解除も通知するように設定を追加する。
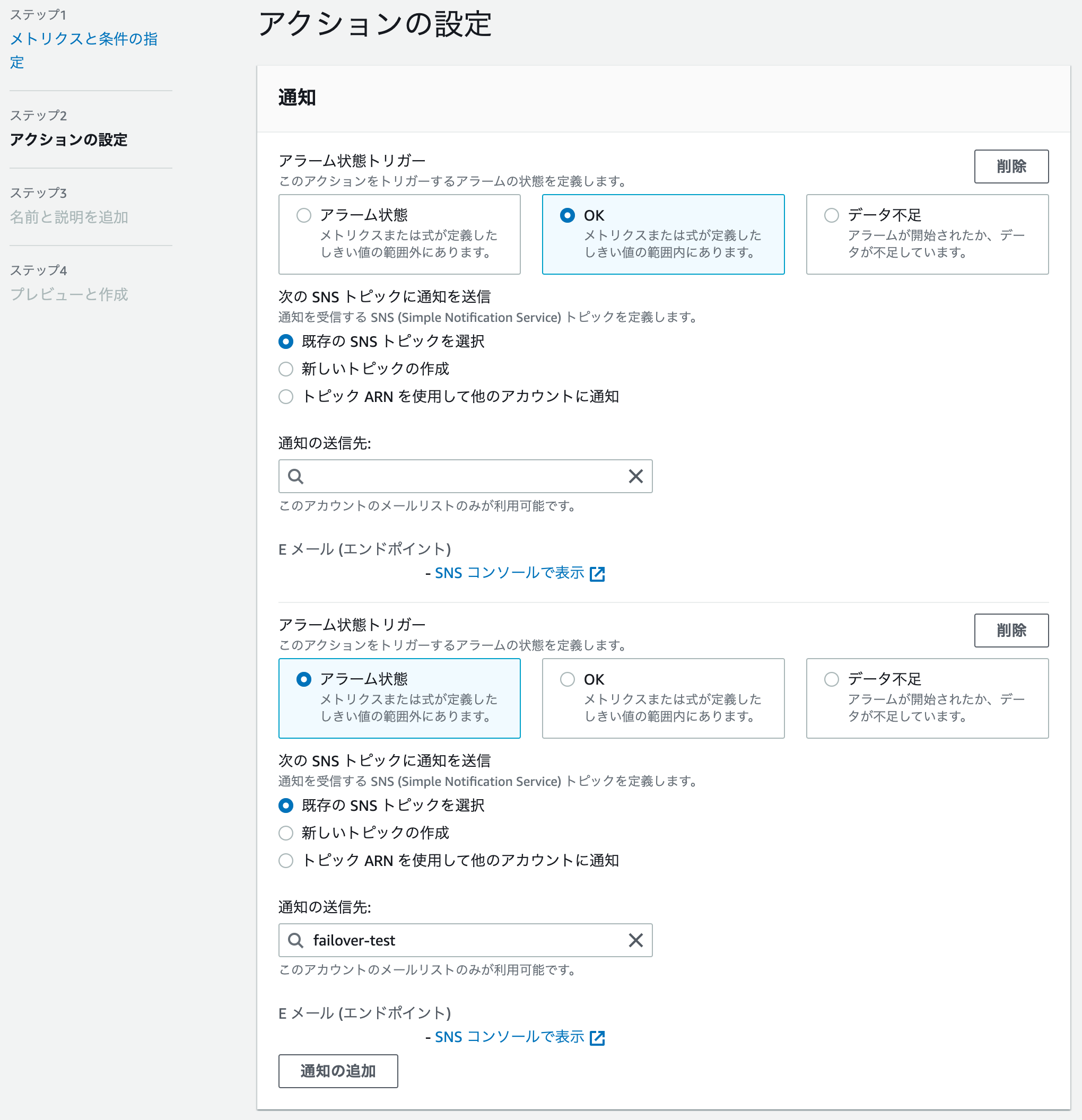
- 作成された CloudWatch アラームを Route 53 ヘルスチェクから確認
- アクションのプルダウンから編集を選択
- アクションの設定で通知の追加をクリック、以下のようにOKを選択
動作テスト
プライマリを手動で停止しセカンダリに切り替わること、再び起動したらプライマリに戻ることを確認する
動作テスト中は一時的にTTLを短くすると、プライマリを停止してからセカンダリ切り替わるまでが早い
参考までに TTL 10sec でのプライマリ停止後に切り替わるまでの時間は3分弱ほどだった
ターミナルで実行
>dig [レコード名] @1.1.1.1
~
;; ANSWER SECTION:
[レコード名]. 60 IN A [primary Elastic IP]
~
プライマリ停止
>dig [レコード名] @1.1.1.1
~
;; ANSWER SECTION:
[レコード名]. 60 IN A [secondary Elastic IP]
~
プライマリ起動
>dig [レコード名] @1.1.1.1
~
;; ANSWER SECTION:
[レコード名]. 60 IN A [primary Elastic IP]
参考文献