何をしたいのか
- Shotcutをゆっくり実況ソフトのように使いたい。
- 具体的にはVOICEVOXと連携させたい。
- Shotcutのサブタイトルを音声変換できたらそれっぽくなりそう
- Shotcutで作られるmltファイルは中身はxmlファイルなのでPythonで取り扱える。
- サブタイトルを抜き出し→VOICEBOXへ入力→mltファイルに動画のパスを書き込みまでやりたい。
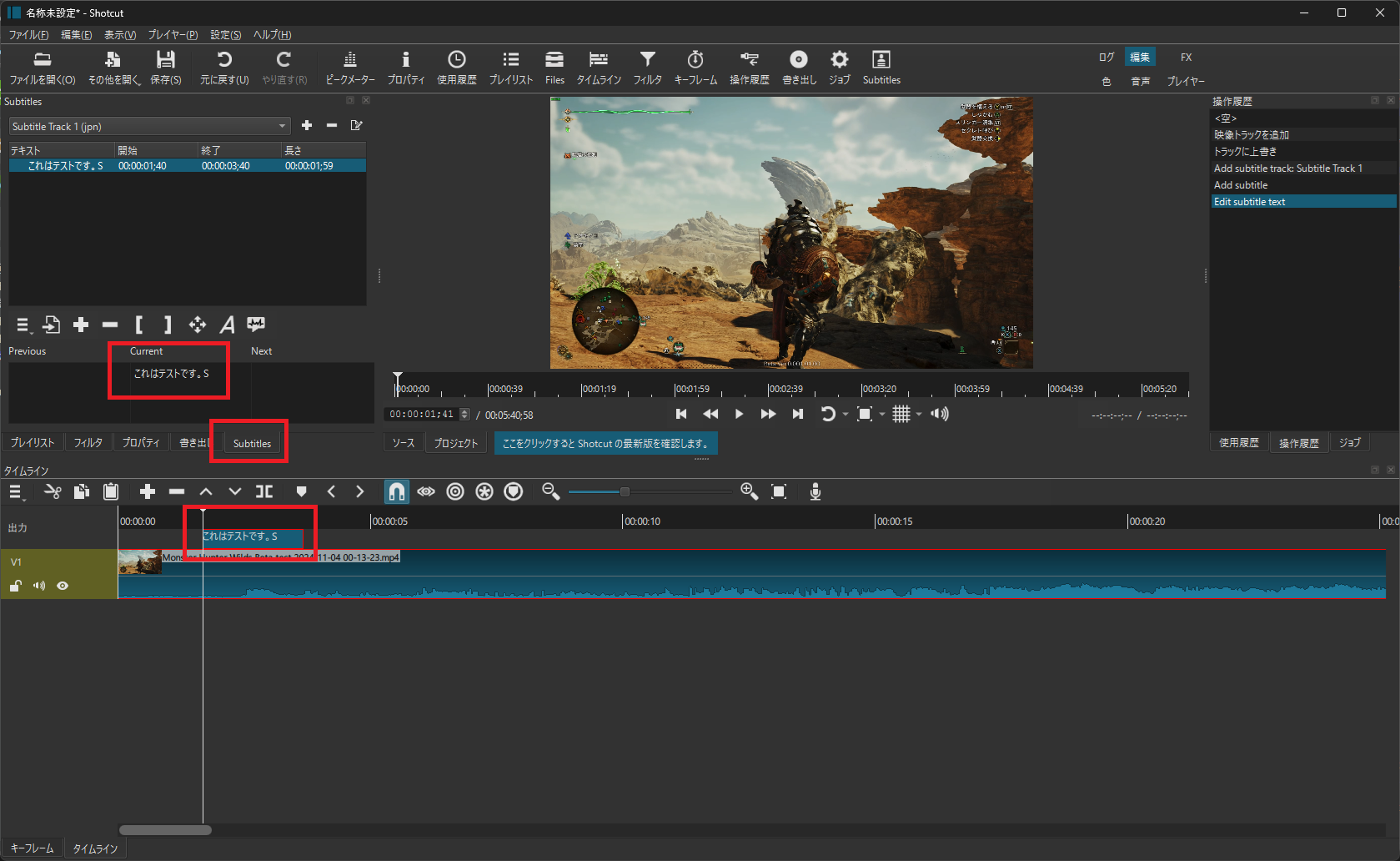
Subtitleとは
赤枠のところです。
mltファイル(xmlファイル)では
こんな感じ
<?xml version="1.0" standalone="no"?>
<mlt LC_NUMERIC="C" version="7.30.0" title="Shotcut version 25.01.25" producer="main_bin">
<profile description="PAL 4:3 DV or DVD" width="1920" height="1080" progressive="1" sample_aspect_num="1" sample_aspect_den="1" display_aspect_num="16" display_aspect_den="9" frame_rate_num="60000" frame_rate_den="1001" colorspace="709"/>
<playlist id="main_bin">
<property name="xml_retain">1</property>
</playlist>
~~~~~~~~~~~~~~~~~~
~~~~~~~~省略~~~~~~~~
~~~~~~~~~~~~~~~~~~
<filter id="filter0">
<property name="feed">Subtitle Track 1</property>
<property name="lang">jpn</property>
<property name="mlt_service">subtitle_feed</property>
<property name="shotcut:hidden">1</property>
<property name="text">1
00:00:00,000 --> 00:00:02,000
これはテストです
2
00:00:03,336 --> 00:00:04,904
テストだよ
</property>
</filter>
</tractor>
</mlt>
Pythonコード
import xml.etree.ElementTree as ET
def parse_subtitle_text(subtitle_text):
lines = subtitle_text.strip().split("\n\n")
results = []
for line in lines:
parts = line.strip().split("\n")
if len(parts) >= 3:
id_ = int(parts[0].strip())
time_range = parts[1].strip()
text = "\n".join(parts[2:]).strip()
start, end = time_range.split("-->")
start = start.strip()
end = end.strip()
results.append({
"id": id_,
"start": start,
"end": end,
"text": text
})
return results
def get_text_property_content(root, filter_id):
filter_element = root.find(f".//filter[@id='{filter_id}']")
if filter_element is not None:
text_property = filter_element.find("./property[@name='text']")
if text_property is not None:
return text_property.text.strip() if text_property.text else None
return None
# XMLファイルの読み込み例
path = r"test_.mlt"
tree = ET.parse(path)
root = tree.getroot()
filter_id = "filter0" #必ずfilter0ではない
print(parse_subtitle_text(get_text_property_content(root, filter_id)))
#[{'id': 1, 'start': '00:00:00,000', 'end': '00:00:02,000', 'text': 'これはテストです'},
# {'id': 2, 'start': '00:00:03,336', 'end': '00:00:04,904', 'text': 'テストだよ'}]
これをVOICEVOXに渡せば音声はできる。サブタイトル追加位置もstartとendでわかる。xmlファイルに動画のパスの追加までしたかたっがとりあえずここまで。